méso (chimie)Xiaomi-MiMo-Audio - Le premier modèle natif de Speech Big de bout en bout de Xiaomi Open Source
Xiaomi-MiMo-Audio est le macromodèle vocal de bout en bout à source ouverte de 7 milliards de paramètres de Xiaomi, doté de puissantes fonctionnalités telles que le dialogue multilingue, la poursuite de la parole, la généralisation à partir de moins d'échantillons et la compréhension audio. Il est capable d'atteindre le niveau SOTA en matière d'intelligence vocale et de compréhension audio, surpassant ainsi Google Gemi...
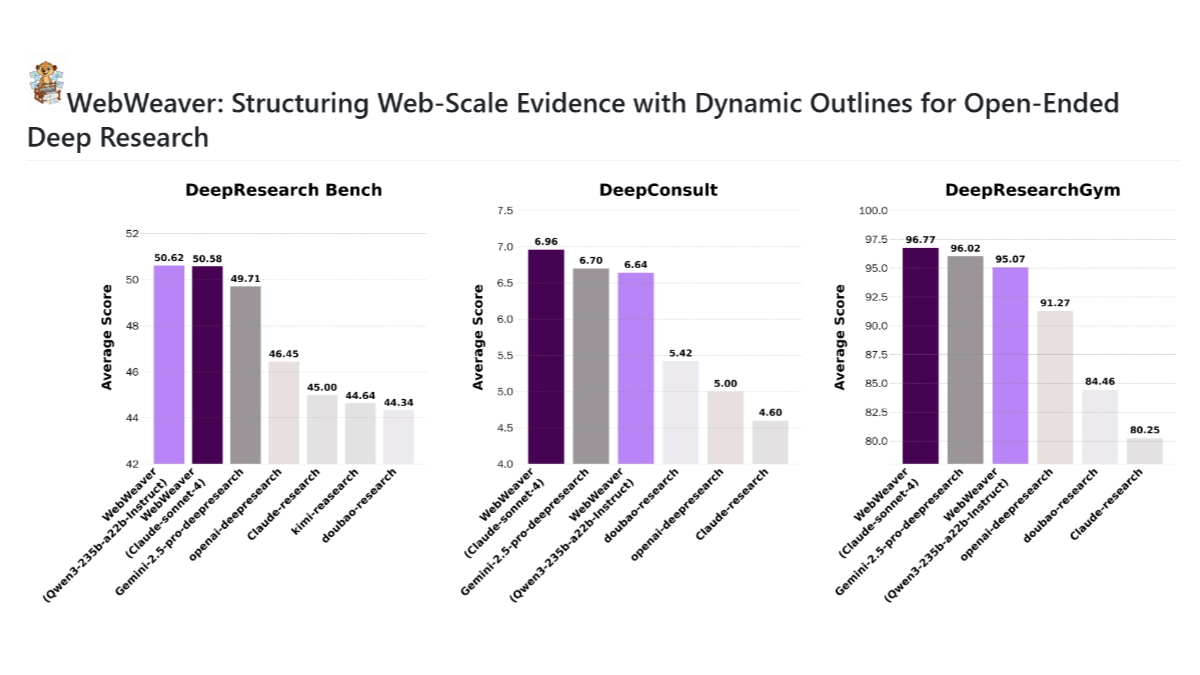
méso (chimie)WebWeaver - Ali Tongyi ouvre le code source d'un nouveau cadre corporel à double intelligence
WebWeaver est une nouvelle structure à double intelligence introduite par l'équipe d'Alibaba Tongyi, qui est principalement utilisée dans la recherche approfondie ouverte et peut simuler le processus de recherche humain, qui est divisé en deux intelligences : la planification et l'écriture.
méso (chimie)MCP Registry - La plateforme officielle de gestion des serveurs MCP de GitHub.
MCP Registry est une plateforme centralisée de GitHub qui aide les développeurs à découvrir et à installer plus facilement les serveurs MCP.
méso (chimie)Tongyi DeepResearch - Ali Tongyi Open Source Deep Research Intelligence Body
Tongyi DeepResearch (Tongyi DeepResearch) est un organisme intelligent open source lancé par Alibaba, conçu pour la recherche d'informations en profondeur et le raisonnement sur des tâches complexes, avec 30 milliards de paramètres, prenant en charge de multiples modes de raisonnement, y compris le mode ReAct et le mode Profondeur...

Guide PDF de l'OpenAI pour rester en tête à l'ère de l'IA - avec liens de téléchargement
Staying ahead in the age of AI est un guide de leadership de l'OpenAI qui aide les chefs d'entreprise à conserver un avantage concurrentiel à l'ère de l'IA. Le guide souligne la croissance rapide de l'IA, avec des versions de modèles plus rapides, des coûts plus bas et une adoption plus rapide par les entreprises...

PDF gratuit de Fundamentals of Large Models de l'Université de Zhejiang - avec lien de téléchargement
Fundamentals of Large Models fournit une analyse approfondie des technologies de base et des voies pratiques des grands modèles de langage (LLM). Partant de la théorie fondamentale de la modélisation linguistique, il explique systématiquement les principes de la conception de modèles basés sur des architectures statistiques, de réseaux neuronaux récurrents (RNN) et de transformateurs, en se concentrant sur les trois principaux grands modèles...
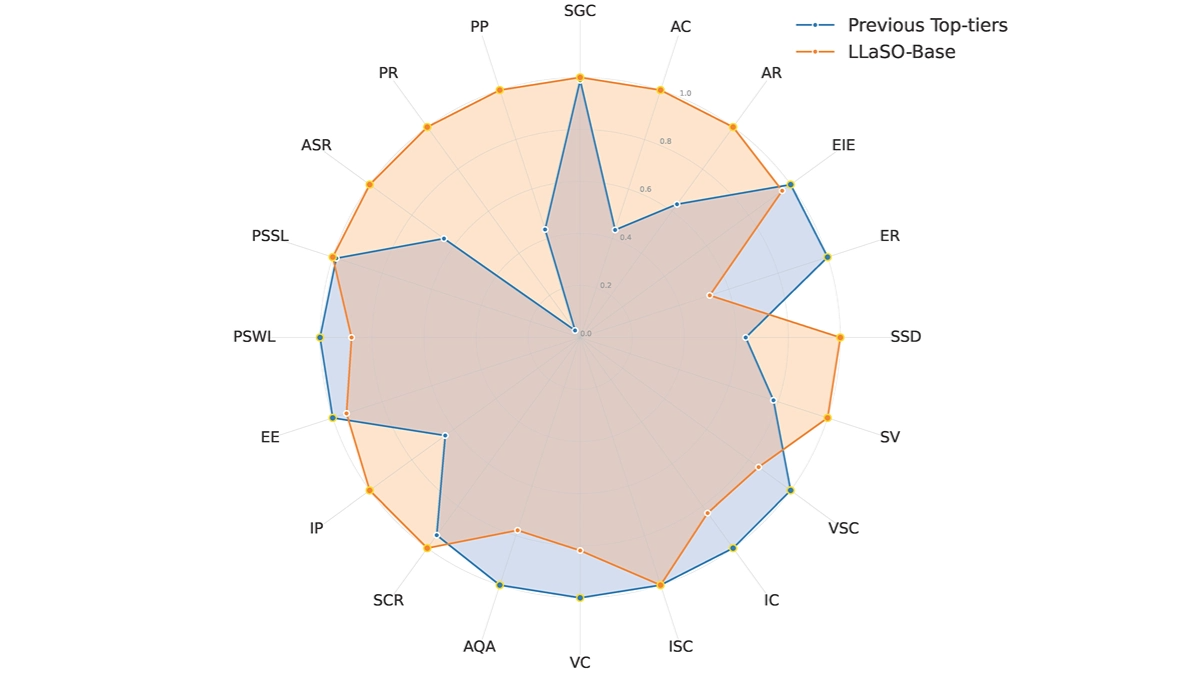
LLaSO - Le premier modèle vocal entièrement open source de Logic Intelligence
LLaSO est un modèle vocal open source lancé par Beijing Depth Logic Intelligence Technology Co. Ltd, qui résout les problèmes de dispersion des données et de couverture insuffisante des tâches dans le domaine de la modélisation du langage vocal à grande échelle en intégrant des données vocales et textuelles et en fournissant des ensembles de données d'alignement, des ensembles de données de mise au point des commandes et des points de référence pour l'évaluation.

Hybrid 3D 3.0 - Modèles générés en 3D par Tencent avec prise en charge de la modélisation UHD
Hybrid 3D 3.0 est un modèle de génération 3D avancé de Tencent, basé sur la technologie de sculpture hiérarchique 3D-DiT, avec une résolution géométrique allant jusqu'à 1536³, capable de générer des modèles 3D ultra-haute définition et riches en détails, et d'exceller dans la modélisation de personnages, avec la capacité de modeler avec précision les cinq sens et la forme du corps.
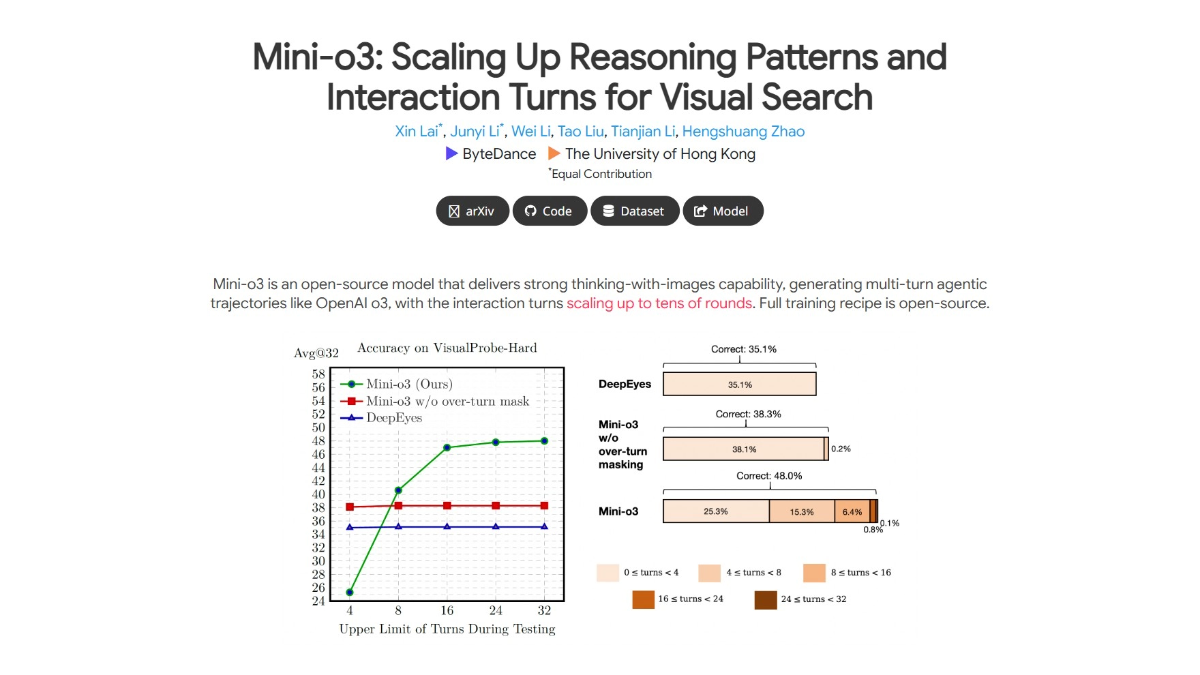
Mini-o3 - Bytes, Modèle de raisonnement visuel Open Source commun à HKU
Mini-o3 est un modèle open source lancé conjointement par ByteDance et l'Université de Hong Kong, qui se concentre sur la résolution de problèmes de recherche visuelle complexes. Le modèle dispose d'une puissante capacité de raisonnement interactif à plusieurs tours et peut localiser une cible par une exploration approfondie et des essais-erreurs.
GPT-5-Codex - le modèle de programmation le plus solide introduit par l'OpenAI
GPT-5-Codex est un puissant modèle d'optimisation de la programmation d'OpenAI, amélioré par GPT-5 et conçu pour les ingénieurs en logiciel. Le modèle génère rapidement un code de haute qualité, prend en charge plusieurs langages de programmation et optimise le code existant pour en améliorer les performances.