AlphaCodium : un nouveau domaine de génération de code, de l'ingénierie des indices à l'ingénierie des processus

Original : [Génération de code à la pointe de la technologie avec AlphaCodium - De l'ingénierie rapide à l'ingénierie des flux]
Par Tal Ridnik

AlphaCodium : un nouveau domaine de génération de code, de l'ingénierie des indices à l'ingénierie des processus
parcourir
Les défis de la génération de code sont différents de ceux du traitement ordinaire du langage naturel - ils impliquent de suivre strictement les règles syntaxiques du langage de programmation cible, d'identifier les cas normaux et les cas limites, de prêter attention à de nombreux détails dans la spécification du problème, et de faire face à d'autres problèmes et exigences spécifiques au code. Par conséquent, de nombreuses techniques d'optimisation couramment utilisées dans le domaine de la génération de langage naturel peuvent ne pas être applicables aux tâches de génération de code.
Dans cette étude, nous proposons une nouvelle méthode de génération de code appelée AlphaCodium -- Un processus de traitement itératif, basé sur des tests, échelonné et axé sur le code. Cette approche améliore considérablement la capacité du modèle linguistique étendu (LLM) à traiter les problèmes de code.
Nous avons testé AlphaCodium sur un ensemble de données de génération de code difficile, CodeContests, qui contient des sujets de programmation de concours provenant de plateformes telles que Codeforces. Notre approche permet d'obtenir des gains de performance significatifs lors de ces tests.
Par exemple, sur l'ensemble de données de validation, la précision (pass@5) de GPT-4 s'est améliorée de 19% à 44% avec un seul indice direct bien conçu après l'utilisation du processus AlphaCodium. AlphaCodium.
Nous pensons que bon nombre des principes et des meilleures pratiques développés dans ce travail sont généralement applicables à une grande variété de tâches dans la génération de code. Notre dernier projet open-source [AlphaCodiumNotre solution AlphaCodium pour les concours de code est partagée dans ], avec une évaluation complète des ensembles de données et des scripts d'analyse comparative pour une recherche et une exploration plus approfondies par la communauté.
CodeContests dataset parsing
[Concours de codesest un ensemble de données de programmation difficile provenant de Google Deepmind. Il s'appuie sur des données telles que [CodeforcesUne plateforme de programmation de concours telle que ] propose une sélection d'environ 10 000 sujets de programmation conçus pour former et évaluer de grands modèles de langage (tels que GPT ou DeepSeek) Capacité à résoudre des problèmes de programmation complexes.
Cette étude ne s'est pas concentrée sur le développement d'un modèle entièrement nouveau, mais plutôt sur la création d'un processus de programmation applicable à une variété de grands modèles de langage qui sont déjà capables de traiter des tâches de codage. C'est pourquoi nous nous concentrons sur les ensembles de validation et de test de CodeContests, qui consistent en 107 et 165 problèmes de programmation. La figure 1 montre un exemple de problème typique de l'ensemble de données :

Figure 1 : Un problème standard dans les concours de code.
Chaque problème comprend une description du problème et des données de test accessibles au public qui peuvent être utilisées directement comme données d'entrée du modèle. Le défi consiste à écrire une procédure qui donne la bonne réponse pour toute entrée légitime. En outre, un ensemble de tests, qui n'est pas accessible au public, est utilisé pour évaluer l'exactitude des procédures soumises.
Pourquoi les concours de code constituent-ils un ensemble de données idéal pour tester la puissance de programmation des grands modèles linguistiques ? Premièrement, contrairement à d'autres ensembles de données de concours de programmation, CodeContests contient une grande quantité de données de test privées (environ 200 cas de test par problème) afin de garantir la précision de l'évaluation. Deuxièmement, les grands modèles de langage ne sont généralement pas très bons pour remarquer les détails dans les descriptions de problèmes qui sont souvent critiques pour trouver la bonne solution. Les descriptions de problèmes dans CodeContests sont généralement à la fois complexes et détaillées, pleines de nuances qui affectent la solution (un exemple typique est illustré dans la Figure 1). Cette conception simule la complexité des problèmes du monde réel, obligeant le modèle à prendre en compte de multiples facteurs, ce qui contraste avec certains ensembles de données plus simples et plus directs (par exemple [HumanEval) est un contraste saisissant. Un problème de programmation typique de HumanEval est illustré à l'annexe 1.
La figure 2 illustre la manière dont le modèle analyse en profondeur le problème de la figure 1. En analysant le problème en profondeur, celui-ci devient plus clair et plus structuré, ce qui souligne l'importance d'une compréhension plus approfondie du problème au cours du processus de programmation.

Figure 2 : Réflexion personnelle générée par l'IA pour le problème décrit dans la figure 1.
Méthodologie proposée
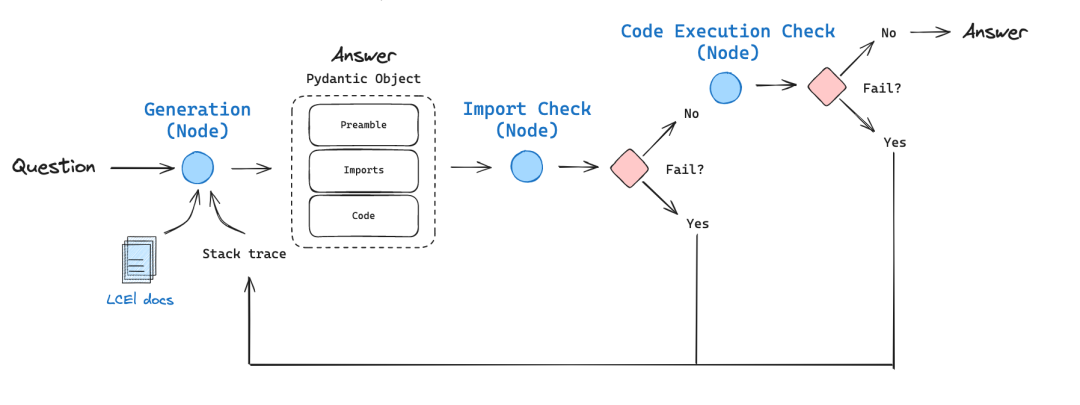
Face aux défis complexes de la génération de code, nous avons constaté que ni l'optimisation à partir d'un seul message, ni les messages de réflexion continue n'ont amélioré de manière significative l'efficacité de résolution des problèmes des grands modèles de langage (LLM) dans le cadre de CodeContest. En effet, le modèle a souvent du mal à comprendre pleinement le problème, générant ainsi de manière répétée un code incorrect ou incapable de faire face à de nouveaux cas de test. Les approches applicables au traitement général du langage naturel peuvent ne pas être idéales pour les tâches de génération de code. Ces tâches cachent un grand potentiel, comme l'exécution répétée du code généré et sa validation par rapport à des exemples connus. Contrairement aux techniques d'optimisation des indices dans le traitement normal du langage naturel, nous constatons que la résolution du problème de CodeContest par la génération de code et les tests spécifiquement pour le programmeflux de travailplus efficace. Le processus s'articule autour deitération (math.)Le processus se déroule, c'est-à-dire que nous exécutons et modifions continuellement le code généré afin qu'il réussisse les tests d'entrée-sortie. Les deux aspects clés de ce processus spécifique au code sont les suivants :
(a) générer des données supplémentaires dans la phase de prétraitement, par exemple l'autoréflexion et le raisonnement pour les cas de test ouverts, afin de soutenir le processus itératif, et (b) augmenter les cas de test ouverts avec des cas de test supplémentaires générés par l'IA. La figure 3 illustre le processus que nous avons conçu pour résoudre le problème de la programmation des courses :

Figure 3 : Le processus AlphaCodium proposé.

Figure 3 Flux de prétraitement de la construction et d'itération du code
Le processus décrit dans la figure 3 est divisé en deux étapes principales :
- prétraitement nous raisonnons sur le problème en utilisant le langage naturel, ce qui est un processus linéaire.
- Itération du code La phase d'évaluation comprend de multiples sessions itératives au cours desquelles nous générons, exécutons et corrigeons le code pour différents tests.
Le tableau 1 présente ces différentes étapes en détail :
| Nom de scène | déclaration de mission |
| Réflexion sur le problème | Résumez le problème sous forme de puces succinctes couvrant les objectifs du problème, les entrées, les sorties, les règles, les contraintes et d'autres détails importants. |
| Analyse logique des cas de test ouverts | Décrire comment les entrées de chaque scénario de test conduisent à une sortie particulière. |
| Concevoir des solutions possibles | Proposez 2 ou 3 solutions possibles et décrivez-les en termes simples. |
| Évaluation de la solution | Évaluer les différentes solutions possibles et choisir la meilleure, en tenant compte de son exactitude, de sa simplicité et de sa robustesse. (Il n'est pas nécessaire de se limiter à l'option la plus efficace). |
| Tests supplémentaires de l'IA | Compléter le problème avec 6 à 8 types différents de tests d'entrée-sortie qui tentent de couvrir des situations et des aspects qui ne sont pas couverts par les cas de test ouverts initiaux. |
| Programme de code initial | L'objectif de cette phase est de former un premier code de solution au problème. Il est important que ce code soit aussi proche que possible de la bonne réponse, afin qu'il ait plus de chances de réussir dans le processus de correction qui suit. Le processus de fonctionnement est le suivant : - Sélectionnez un scénario possible, écrivez le code approprié et essayez-le dans des cas de test publics et des tests d'intelligence artificielle sélectionnés. - Répétez ce processus jusqu'à ce que le test soit réussi ou que le nombre maximum de tentatives soit atteint. - Le premier code qui réussit le test, ou le code dont la sortie est la plus proche de la bonne réponse, sera utilisé comme code de base pour les étapes suivantes. |
| Optimisation itérative des cas de test ouverts | Prenez le code de base comme point de départ, exécutez-le un par un dans des cas de test ouverts et optimisez-le. Si le code pose un problème dans l'un des tests, essayez de le résoudre en vous basant sur le message d'erreur. |
| Optimisation itérative pour les tests d'IA | Poursuivre l'optimisation itérative des tests générés par l'IA. Appliquer les "ancres de test" (une technique permettant de fixer des éléments spécifiques dans les tests afin de déboguer et d'améliorer le code avec plus de précision). |
Tableau 1 : Caractérisation des phases AlphaCodium.
En explorant le processus proposé, nous avons acquis une intuition et une compréhension profondes.
tout d'abordconnaissances cumulativesLes étapes du processus : nous commençons par des tâches simples et nous nous attaquons progressivement à des problèmes plus complexes. Par exemple, au cours de la première étape du processus, _Réflexion sur soi_, nous apprenons des connaissances qui peuvent être utilisées au cours des étapes suivantes, plus difficiles, telles queGénérer des solutions possibles. La phase de prétraitement du processus produit des résultats qui alimentent la partie la plus difficile et la plus critique du processus : l'itération du code, au cours de laquelle nous essayons réellement d'écrire un code qui résout le problème correctement.
Suivant.Il est plus facile de générer des tests d'intelligence artificielle supplémentaires que de générer un ensemble complet de codes de solution. -- Ce processus repose en grande partie sur la compréhension du problème et la résolution par force brute ou le raisonnement logique, sans avoir à résoudre complètement le problème pour générer des paires de tests d'entrée-sortie utiles. Ce processus est différent de l'écriture d'un code de solution complet et correct, qui exige que nous trouvions une solution algorithmique complète capable de répondre correctement à n'importe quelle paire de tests d'entrée-sortie. Par conséquent, nous pouvons créer davantage de tests d'IA et les utiliser pour optimiser la phase de création du code, comme le montre la figure 4. Nous améliorons également l'efficacité de ces tests supplémentaires en demandant au modèle de se concentrer sur ce qui n'est pas couvert par les cas de test publics initiaux, tels que le traitement de grandes entrées, les cas limites, etc.
Enfin.Plusieurs étapes peuvent être combinées en un seul appel au grand modèle linguistique (LLM). -- Le processus illustré à la figure 3 est une démonstration conceptuelle qui met en évidence les principales étapes du processus. Dans la pratique, en structurant les résultats (voir la section suivante), nous pouvons combiner plusieurs étapes en un seul appel à un grand modèle linguistique afin de conserver les ressources ou d'améliorer les performances du modèle lorsqu'il traite des tâches spécifiques en même temps.

La figure 4 montre les améliorations apportées par l'application du processus AlphaCodium.
Les modèles se heurtent souvent à des difficultés lorsqu'ils résolvent des problèmes de code en se basant uniquement sur des indications directes. L'itération sur des cas de test publiquement disponibles stabilise et améliore la solution, mais laisse des "angles morts" parce que les cas de test publiquement disponibles ne sont pas assez complets. Lorsque nous utilisons l'ensemble du processus AlphaCodium, y compris la phase de prétraitement et l'itération sur des tests publics et générés par l'IA, nous pouvons encore améliorer la qualité de la solution et augmenter de manière significative le taux de réussite de la résolution de problèmes.
Concepts de conception pour le code
Dans cette section, nous présentons quelques concepts de conception, techniques et meilleures pratiques que nous avons trouvés utiles pour résoudre les problèmes de génération de code. Le processus AlphaCodium que nous présentons dans la figure 3 utilise largement ces concepts de conception :
Sortie structurée YAML : Un élément clé du processus que nous proposons est l'utilisation d'un résultat structuré, qui exige du modèle qu'il génère un résultat au format YAML équivalent à une classe pydantique spécifique. En voici un exemple :
...
Votre objectif est de trouver des solutions possibles.
Veiller à ce que les objectifs, les règles et les contraintes du problème soient pleinement pris en compte dans chaque programme.
La sortie est un objet YAML correspondant au type $PossibleSolutions, conformément à la définition pydantique suivante :
classe Solution(BaseModel).
name : str = Field(description="Nom de la solution")
content : str = Field(description=Description de la solution")
why_it_works : str = Field(description="Pourquoi cette solution fonctionne. Doit être spécifiquement détaillé pour les règles et les objectifs du problème.")
complexity : str = Field(description="La complexité de la solution")
classe PossibleSolutions(BaseModel).
possible_solutions : List[Solution] = Field(max_items=3, description="Une liste de solutions possibles au problème. Veillez à ce que chaque solution tienne pleinement compte des règles et des objectifs du problème et ait un temps d'exécution raisonnable sur un ordinateur moderne - pas plus de trois secondes pour les contraintes de problèmes comportant un grand nombre d'entrées.)
Tableau 2 : Exemples d'invites de sortie structurées (phase de génération de solutions possibles).
La sortie structurée réduit la complexité de l'"ingénierie des indices" et le besoin de piratage, et présente les tâches complexes de manière directe, sous forme de code. Elle permet également d'obtenir des réponses complexes comportant plusieurs étapes, reflétant des processus de pensée logiques et organisés.
Bien que la nouvelle version de GPT prenne en charge [Style JSONmais nous pensons que, en particulier pour les tâches de génération de code, la sortie YAML est plus appropriée, comme indiqué dans l'annexe.
Analyse des points à puces - Lorsqu'on demande à un modèle de langage étendu (LLM) d'analyser un problème, on obtient généralement de meilleurs résultats en demandant que les résultats soient présentés sous forme de points à puces. Les puces favorisent une compréhension plus profonde du problème et obligent le modèle à diviser le résultat en régions sémantiques logiques, améliorant ainsi la qualité des résultats. Par exemple, dans le cas du problème d'autoréflexion à puces (voir figure 2), chaque puce représente une compréhension sémantique d'une partie différente du problème - description générale, objectifs et règles, structure d'entrée et structure de sortie.
Les grands modèles de langage sont plus efficaces pour générer du code modulaire - Lorsque nous laissons le modèle de langage étendu (LLM) travailler à l'écriture d'un long bloc de fonctions individuelles, nous rencontrons souvent des problèmes : le code comporte souvent des erreurs ou des trous logiques. Pire encore, ces gros blocs de code monolithiques peuvent interférer avec les itérations ultérieures visant à les corriger. Même lorsque des informations sur les erreurs sont fournies, il est difficile pour le modèle de localiser et de résoudre le problème. Toutefois, si nous demandons explicitement au modèle de "_Séparer le code généré en plusieurs petits modules sous-fonctionnels et leur donner des noms significatifs_", les résultats seront bien meilleurs, avec moins d'erreurs dans le code généré et un taux de réussite plus élevé dans la phase de correction itérative.
L'importance d'une prise de décision flexible et d'une double validation - Les grands modèles de langage sont souvent confrontés à des tâches de codage qui nécessitent des déductions réfléchies et rationnelles et la capacité de prendre des décisions sérieuses et non routinières. Par exemple, lors de la génération de tests supplémentaires pour un problème, les tests générés par le modèle contiennent souvent des erreurs. Pour résoudre ce problème, nous introduisons le processus de double validation. Dans ce processus, après avoir généré la sortie initiale, on demande au modèle de générer à nouveau la même sortie et de la corriger si nécessaire. Par exemple, après avoir reçu en entrée les tests d'IA qu'il a lui-même générés, le modèle doit régénérer ces tests et corriger les erreurs qu'ils contiennent (le cas échéant) en temps voulu. Nous avons constaté que cette double étape de validation n'incite pas seulement le modèle à penser et à raisonner de manière critique, mais qu'elle est également plus efficace que de poser des questions directes de type oui/non, telles que "Ce test est-il correct ? comme les questions oui/non.
Retarder la prise de décision, éviter les questions directes, laisser de l'espace pour l'exploration - Lorsque nous posons des questions complexes directement au modèle, nous obtenons souvent des réponses erronées ou irréalistes. Nous avons donc adopté une approche similaire à celle décrite par Karpathy dans le tweet ci-dessous, en accumulant des données de manière incrémentale et en passant progressivement des tâches simples aux tâches complexes :
- Commencer par les tâches les plus simples, c'est-à-dire l'autoréflexion sur le problème et le raisonnement sur les cas de test ouverts.
- Passez ensuite à la génération de tests d'IA supplémentaires et de solutions possibles au problème.
- Ce n'est qu'après avoir obtenu les réponses du modèle aux tâches susmentionnées que nous passons au processus itératif de génération de code et d'exécution des corrections.

Karpathy : Cela correspond parfaitement au "besoin d'un grand modèle linguistique (LLM)". Jeton L'idée de "penser". Dans certains cas, la chaîne de pensée peut simplement servir à fournir une réserve supplémentaire d'informations, plutôt que de jouer d'autres rôles plus importants.
Autre exemple, au lieu de choisir une solution algorithmique unique, nous évaluons et classons plusieurs solutions possibles, en donnant la priorité à celles qui sont les mieux classées pour l'écriture du code initial. Comme les modèles peuvent mal tourner, nous préférons éviter de prendre des décisions irréversibles et laisser la place à l'exploration et aux itérations de code qui essaient différentes solutions possibles.
Test des techniques d'ancrage - Bien qu'ils aient été validés deux fois, certains tests générés par l'IA peuvent encore être erronés. Cela pose un problème : lorsqu'un test échoue, comment savoir s'il s'agit d'un problème avec le code ou d'une erreur dans le test lui-même ? En interrogeant directement le modèle pour savoir "ce qui ne va pas", nous obtenons souvent des réponses irréalistes, ce qui conduit parfois à une modification incorrecte du code. Pour relever ce défi, nous avons introduit une approche appelée "ancres de test" :
- L'itération porte d'abord sur les tests qui sont accessibles au public et dont on sait qu'ils sont corrects. Une fois cette étape terminée, tous les tests réussis sont désignés comme des tests de référence (tests d'ancrage).
- Commencez ensuite à vérifier les tests générés par l'IA un par un.
- Ceux qui réussissent le test sont ajoutés à la liste des tests d'ancrage.
- Si le test échoue, le code est considéré par défaut comme incorrect et une tentative de correction est effectuée. Il est important de noter que le code corrigé doit également réussir tous les tests d'ancrage existants.
De cette manière, les tests de points d'ancrage agissent comme une protection contre la correction incorrecte de notre code au fur et à mesure que nous le corrigeons. En outre, une autre amélioration des tests de points d'ancrage consiste à classer les tests générés par l'IA par ordre de difficulté. Les tests d'ancrage sont ainsi plus facilement disponibles au début du processus itératif et fournissent des garanties supplémentaires pour les tests d'IA plus complexes, en particulier pour les tests d'IA les plus susceptibles de produire des résultats incorrects. Cette stratégie renforce efficacement la stabilité et la fiabilité du processus de test, en particulier lorsqu'il s'agit de tests complexes et exigeants générés par l'IA.
en fin de compte
Comparaison des pointes directes avec l'AlphaCodium
Dans la figure 5, nous comparons les résultats d'AlphaCodium avec ceux d'une seule méthode d'indication directe bien conçue. Le critère d'évaluation est pass@k (taux de réussite dans la résolution du problème), c'est-à-dire la proportion de solutions générées par l'utilisation de k pour chaque problème.

Figure 5 : Comparaison de la méthode AlphaCodium avec la méthode de repérage direct sur différents modèles.
On peut constater que l'approche AlphaCodium améliore de manière significative et constante la performance des grands modèles de langage (LLM) dans la résolution de problèmes de programmation avec CodeContests. Cette conclusion s'applique à la fois aux modèles à source ouverte (par exemple, DeepSeek) et aux modèles à source fermée (par exemple, GPT), à la fois sur les ensembles de validation et de test.
Comparaison avec d'autres études :
Dans le tableau 3, nous montrons les résultats d'AlphaCodium comparés à d'autres méthodes dans la littérature.
| modélisation | ensemble de données | les méthodologies | score |
| GPT-3.5 | ensemble de validation | AlphaCodium (pass@5) | 25% |
| GPT-3.5 | ensemble de validation | Chaîne de code (pass@5) | 17% |
| GPT-3.5 | ensemble de tests | AlphaCodium (pass@5) | 17% |
| GPT-3.5 | ensemble de tests | Chaîne de code (pass@5) | 14% |
| GPT-4 | ensemble de validation | AlphaCodium (pass@5) | 44% |
| DeepMind : une mise au point | ensemble de validation | AlphaCode (passe@10@1K) | 17% |
| DeepMind : une mise au point | AlphaCode (pass@10@100K) | 24% | |
| GPT-4 | ensemble de tests | AlphaCodium (pass@5) | 29% |
| DeepMind : une mise au point | ensemble de tests | AlphaCode (passe@10@1K) | 16% |
| DeepMind : une mise au point | ensemble de tests | AlphaCode (pass@10@100K) | 28% |
| Gemini-pro | AlphaCode2 : Les résultats de la comparaison pour AlphaCode2 ne sont pas rapportés dans les versions existantes de CodeContests. D'après le Rapport technique sur AlphaCode2Les chercheurs ont comparé les résultats d'AlphaCode avec ceux d'AlphaCode2 sur un ensemble de données non publié et ont constaté une réduction significative du nombre d'appels au grand modèle de langage (LLM) (@100), AlphaCode2 obtient des résultats comparables à ceux d'AlphaCode, tous deux étant des 29%, pass@10. |
Tableau 3 : Comparaison d'AlphaCodium avec d'autres travaux de recherche dans la littérature

Figure 6 : Comparaison de l'efficacité.
La figure montre que l'approche d'AlphaCodium démontre d'excellentes performances pour une variété de modèles et de critères d'évaluation, en particulier lorsqu'il s'agit de résoudre des défis de programmation à l'aide d'un grand modèle de langage. Ces résultats comparatifs démontrent non seulement l'innovation technique d'AlphaCodium, mais soulignent également son efficacité et son applicabilité dans le monde réel.
Dans l'ensemble, AlphaCodium démontre son potentiel remarquable dans le domaine de la programmation intelligente, notamment en améliorant la capacité des grands modèles de langage à traiter des problèmes de programmation complexes. Ces résultats fournissent des indications importantes pour la recherche et le développement futurs, ainsi que des références précieuses pour la poursuite du développement et de l'optimisation des grands modèles de langage.
Figure 6 : Comparaison de l'efficacité. Voici comment AlphaCodium se compare à d'autres solutions en termes de précision par rapport au nombre d'appels au Large Language Model (LLM). Comparé à AlphaCode, AlphaCodium nécessite des milliers de fois moins d'appels au LLM pour atteindre une précision similaire.
Lorsque nous comparons AlphaCodium avec le même modèle GPT-3.5 et le critère "5 tentatives réussies" [Chaîne de codePar rapport à [ ], il est clair qu'AlphaCodium est plus performant. Par rapport à [AlphaCodeLorsque l'on compare les méthodes d'[AlphaCode], il est important de noter qu'AlphaCode utilise une stratégie de génération de code différente : il optimise un modèle spécifique pour résoudre le problème de codage, génère un grand nombre de scénarios de codage, les classe et sélectionne finalement un certain nombre de scénarios à soumettre à partir des principales classifications. Par exemple, "10 tentatives réussies sur 100 000 solutions" signifie qu'il génère 100 000 solutions, les classe et en sélectionne 10 à soumettre. AlphaCode utilise un modèle spécialement optimisé qui utilise un plus grand nombre d'appels LLM, similaire à une stratégie exhaustive. AlphaCode utilise un modèle spécialement optimisé qui utilise un plus grand nombre d'appels LLM, similaire à une stratégie exhaustive. Néanmoins, AlphaCodium a obtenu de meilleurs résultats.
Il convient également de mentionner que ni AlphaCode ni CodeChain ne fournissent de solutions reproductibles, y compris des scripts d'évaluation complets de bout en bout. De nombreux détails doivent être pris en compte lors de l'évaluation des résultats, tels que le traitement de sujets à solutions multiples, les mécanismes de tolérance aux pannes, les problèmes de délai d'attente, etc. Notre comparaison est basée sur les données rapportées dans leurs articles, mais pour la fiabilité et la reproductibilité des comparaisons futures, nous fournissons un ensemble complet de code et de scripts d'évaluation reproductibles.
Comparaison de la puissance de calcul : AlphaCode vs AlphaCode2
Dans le processus d'AlphaCodium, la résolution de chaque problème nécessite environ 15 à 20 appels au Large Language Model (LLM), ce qui signifie qu'au cours de cinq tentatives, environ 100 appels au LLM sont nécessaires.
Et AlphaCode n'indique pas explicitement combien d'appels au grand modèle de langage sont nécessaires par problème. Si nous supposons qu'il est appelé une fois par tentative (ce qui est encore inconnu et peut en fait être plus), alors pour chacune des 10 tentatives, filtrées à partir des 100 000 solutions, il faudrait appeler le grand modèle de langage 1 million de fois, ce qui est quatre ordres de grandeur de plus qu'AlphaCodium. Cependant, d'après les résultats obtenus, AlphaCodium est bien plus performant, comme le montre clairement la figure 3.
Une étude récemment publiée, appelée AlphaCode2 ([...Rapport technique]) dans laquelle les chercheurs ont évalué un modèle appelé Gemini-Pro adapté aux problèmes de programmation. L'étude a également exploré l'analyse comparative de CodeContests, mais en utilisant une version mise à jour non publiée. Selon le rapport d'AlphaCode2, avec seulement une centaine d'échantillons, AlphaCode2 atteint le niveau de performance qu'AlphaCode atteint avec des millions d'échantillons, ce qui le rend plus de 10 000 fois plus efficace en termes d'échantillons qu'AlphaCode. Par conséquent, AlphaCode2 et AlphaCodium sont tous deux beaucoup plus efficaces qu'AlphaCode en termes de nombre d'appels au modèle de langage de grande taille.
Cependant, AlphaCode2 utilise un système élaboré spécialement conçu pour les concours CodeContests.réglage finLe modèle AlphaCodium est basé sur un modèle de base moderne, alors qu'AlphaCodium utilise un modèle générique non modifié. Malgré cela, AlphaCodium améliore les performances du modèle sans données supplémentaires et sans phases d'entraînement coûteuses.
annexe
1) Exemple d'évaluation manuelle d'un problème de code :
/*
Dans un ensemble de nombres, vérifie s'il existe deux nombres dont la distance entre eux est inférieure à un seuil numérique spécifique. >>>
has_close_elements({1.0, 2.0, 3.0}, 0.5) false >>>
has_close_elements({1.0, 2.8, 3.0, 4.0, 5.0, 2.0}, 0.3) true
*/
#include
#include
#include
using namespace std ;
bool has_close_elements(vector numbers, float threshold){
Tableau 4.Le problème est relativement intuitif et simple, sans beaucoup de détails ou de subtilités sur lesquels le modèle peut raisonner.
2) Pourquoi la sortie YAML est mieux adaptée aux tâches de génération de code que la sortie JSON ?
Bien que la nouvelle version de GPT ait [support natifmais nous pensons que pour la génération de code, la sortie YAML est plus appropriée. En effet, le code généré contient souvent des guillemets simples, des guillemets doubles et des caractères spéciaux. Au format JSON, il est difficile pour LLM de placer ces caractères correctement car la sortie JSON doit être entourée de guillemets doubles. La sortie YAML, en revanche, [Adoption de scalaires en blocIl suffit de suivre les règles d'indentation et tout texte ou code correctement indenté est légal. En outre, la sortie YAML contient moins de tokens, ce qui permet de réduire les coûts et d'accélérer les temps d'inférence, ainsi que d'améliorer la qualité car le modèle a moins de tokens non critiques sur lesquels se concentrer. Voici un exemple de comparaison entre les sorties JSON et YAML (en utilisant [https://platform.openai.com/tokenizer] généré) :
import json
import yaml
s1 = 'print("double quote string")'
s2 = "print('single quote string')"
s3 = 'print("""chaîne de trois guillemets"")'
s4 = f"{s1}\n{s2}\n{s3}"
# Créer un dictionnaire dont les clés sont des noms de variables et les valeurs des chaînes de caractères.
data = {'s1' : s1, 's2' : s2, 's3' : s3, 's4' : s4}
# Convertir un dictionnaire en chaîne au format JSON
json_data = json.dumps(data, indent=2)
print(json_data)
# Convertir un dictionnaire en chaîne au format YAML dans un style scalaire en bloc
yaml_data = yaml.dump(data, indent=2, default_style='|')
print(yaml_data)
Sortie.
Tableau 5.
Sortie JSON :

Figure 7 : Exemple de comptage de jetons à l'aide de la sortie JSON.
Un exemple de sortie YAML est présenté ci-dessous :

Figure 8 : Exemple de comptage de jetons à l'aide de la sortie YAML.
Il est évident que la génération d'un code qui ne conserve qu'une indentation correcte est non seulement plus concise et plus claire, mais aussi plus efficace pour réduire le nombre d'erreurs.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes



Pas de commentaires...