
La première liste des critères d'évaluation de "AI Search" a été publiée ! La marge d'avance de 4o est faible, et les grands modèles nationaux fonctionnent brillamment, avec un total de 5 bases, 11 scénarios et 14 modèles.


La publication de l'évaluation comparative du Chinese Big Model AI Search (SuperCLUE-AISearch) est une évaluation approfondie de la capacité du Big Model combiné à la recherche. L'évaluation se concentre non seulement sur les capacités de base du grand modèle, mais examine également ses performances dans des applications de scénario. L'évaluation couvre 5 capacités de base, telles que la recherche d'informations et l'acquisition d'informations actualisées, ainsi que 11 applications de scénario, telles que les actualités et les applications de la vie, afin de tester de manière exhaustive les performances du modèle en combinant la recherche dans différentes capacités de base et tâches d'application de scénario. Pour le schéma d'évaluation, voir : "AI Search" Benchmark Evaluation Scheme Release. Cette fois-ci, nous avons évalué les capacités de recherche en IA de 14 grands modèles représentatifs nationaux et internationaux, et voici le rapport d'évaluation détaillé.
Résumé de l'évaluation de la recherche d'IA
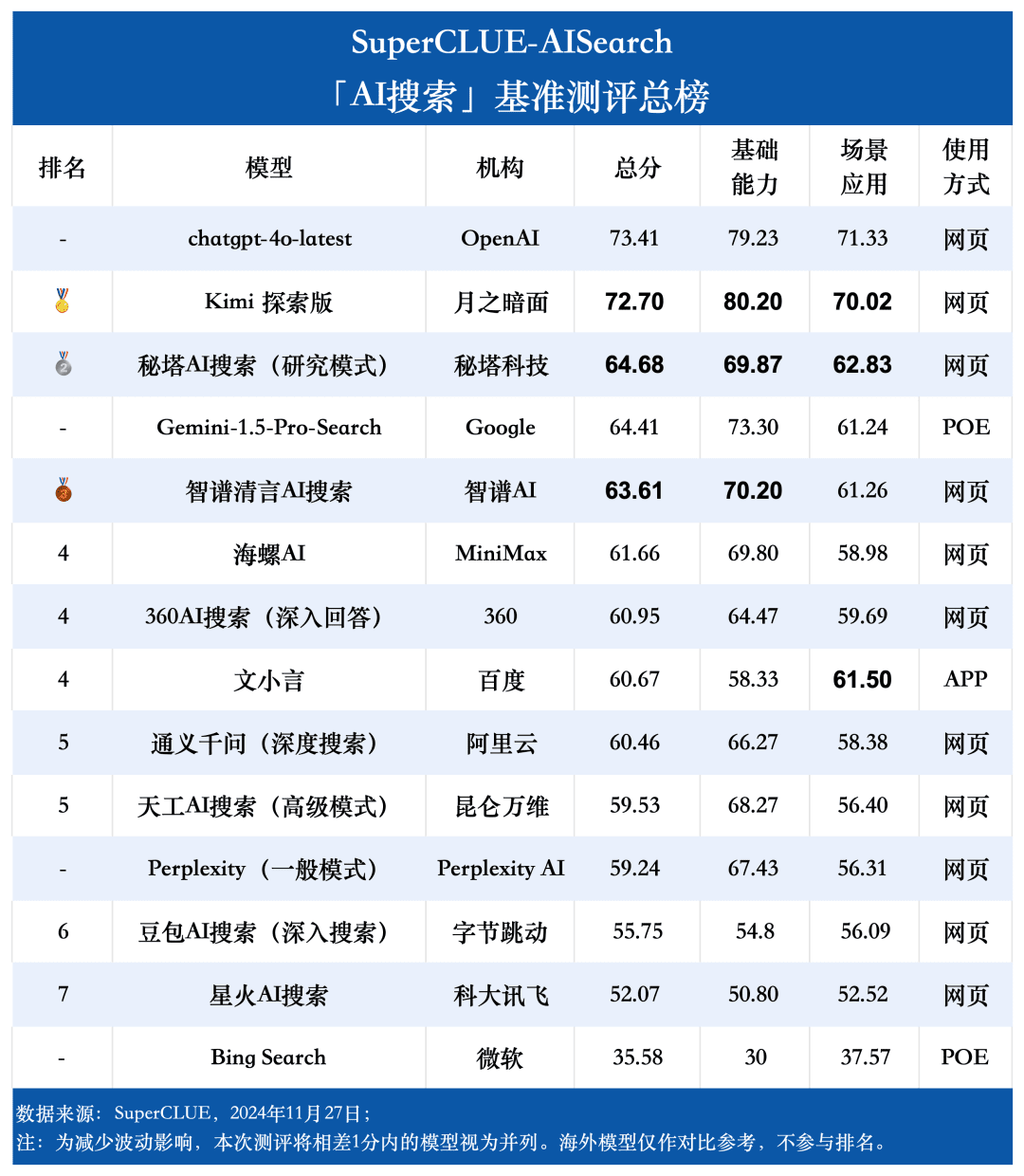
Point de mesure 1Dans cette évaluation, chatgpt-4o-latest a obtenu 73,41 points grâce à ses excellentes performances, devançant ainsi les autres modèles participants. Pendant ce temps, le grand modèle national Kimi Les performances de l'édition Explorer sont également remarquables, avec de bons résultats dans les domaines du shopping et de la culture dans l'application du scénario, démontrant de superbes capacités de recherche en IA, ainsi que d'excellentes performances globales dans de multiples dimensions.
Point de mesure 2D'après les résultats de l'évaluation, les grands modèles nationaux tels que Secret Tower AI Search (Research Mode), Wisdom Spectrum Clear Speech AI Search et Conch AI sont plus impressionnants en termes de performances globales, au même titre que le grand modèle étranger Gemini-1.5-Pro-Search. Par ailleurs, les performances de plusieurs grands modèles nationaux, tels que 360AI Search (réponse approfondie), Wen XiaoYin, Tongyi QianQi (recherche approfondie) et d'autres grands modèles, ne sont pas similaires et présentent une légère différence.
Point de mesure 3Les modèles présentent des degrés de performance différents selon les scénarios d'application. Dans l'évaluation de la recherche en IA, nous nous sommes également concentrés sur les performances de chaque grand modèle dans différents scénarios d'application. Les grands modèles nationaux ont obtenu des résultats relativement bons dans des scénarios tels que la science et la technologie, la culture, les affaires et les divertissements, démontrant d'excellentes capacités de recherche et d'intégration d'informations tout en saisissant l'actualité de l'information. Toutefois, les grands modèles nationaux peuvent encore s'améliorer dans des scénarios d'application tels que les actions et les sports.
Aperçu de la liste
Introduction à SuperCLUE-AISearch
SuperCLUE-AISearch est un ensemble complet d'évaluation de modèles de recherche d'IA chinois, visant à fournir une référence pour évaluer la capacité des modèles de recherche d'IA dans le domaine chinois.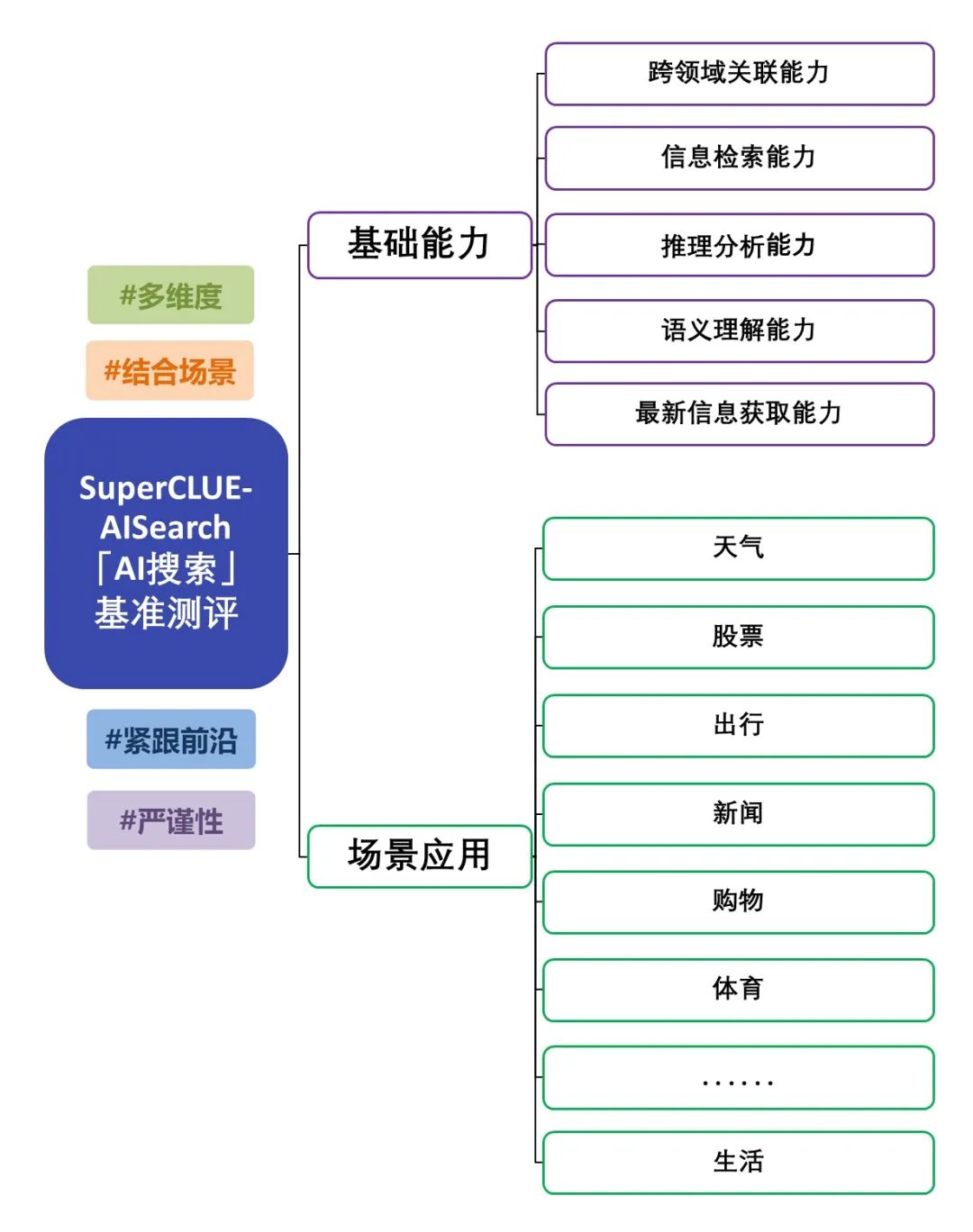
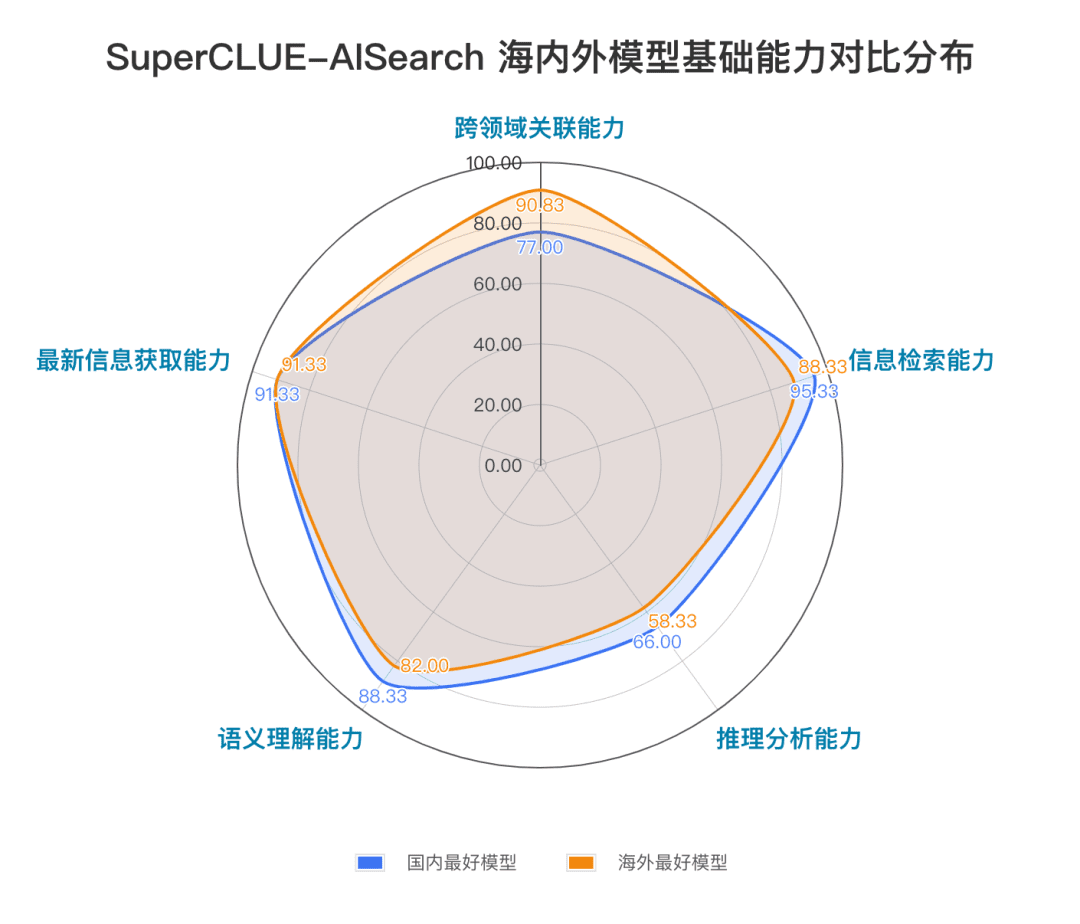
Les capacités fondamentales comprennent cinq capacités requises dans les tâches de recherche de l'IA : pertinence interdomaines, recherche d'informations, compréhension sémantique, acquisition d'informations actualisées et raisonnement.
Les applications de scénario comprennent 11 scénarios communs aux tâches de recherche d'IA : météo, actions, voyages, actualités, achats, sports, divertissements, éducation, voyages, affaires, culture, technologie, soins de santé et vie.
Méthodologie
En se référant à l'approche d'évaluation fine de SuperCLUE, un ensemble dédié de mesures est construit, et chaque dimension est évaluée à un niveau fin et un retour d'information détaillé peut être fourni.
1) Construction d'un ensemble de mesures
Processus de construction du questionnaire chinois : 1. référence à un questionnaire existant ---> 2. rédaction du questionnaire chinois ---> 3. test ---> 4. modification et finalisation du questionnaire chinois ; création d'un ensemble d'évaluation dédié à chaque dimension.
2) Méthode de notation
Le processus d'évaluation commence par l'interaction du modèle avec l'ensemble de données, qu'il faut comprendre et auquel il faut répondre sur la base des questions fournies.
Les critères d'évaluation couvrent les dimensions du processus de réflexion, du processus de résolution de problèmes, de la réflexion et de l'ajustement.
Les règles de notation combinent la notation quantitative automatisée et l'examen par des experts afin de noter efficacement tout en garantissant que l'évaluation est scientifique et équitable.
3) Critères de notation
Pour évaluer la qualité des réponses de chaque macromodèle aux tâches d'évaluation, deux critères d'évaluation ont été utilisés pour évaluer respectivement les questions subjectives et objectives de l'ensemble d'évaluation. Ces critères ont été pondérés différemment dans l'évaluation afin de refléter pleinement la performance des grands modèles dans la tâche de recherche d'IA.
Le système d'évaluation SuperCLUE-AISearch est conçu pour noter les questions subjectives sur 5 points, qui sont évaluées à partir des dimensions de l'utilité de l'information, de la précision analytique et de la clarté de l'expression, dont l'utilité de l'information représente 60%, la précision analytique représente 20% et la clarté de l'expression représente 20%.Les critères de notation des questions objectives sont notés sur 5 points, qui sont évalués à partir des dimensions de la précision de l'information et de la clarté de l'expression, dont la précision de l'information représente 80% et la clarté de l'expression représente 20%. Les questions objectives sont notées sur 5 points et évaluées selon deux dimensions : la précision de l'information et la clarté de l'expression, la précision de l'information comptant pour 80% et la clarté de l'expression comptant pour 20%. 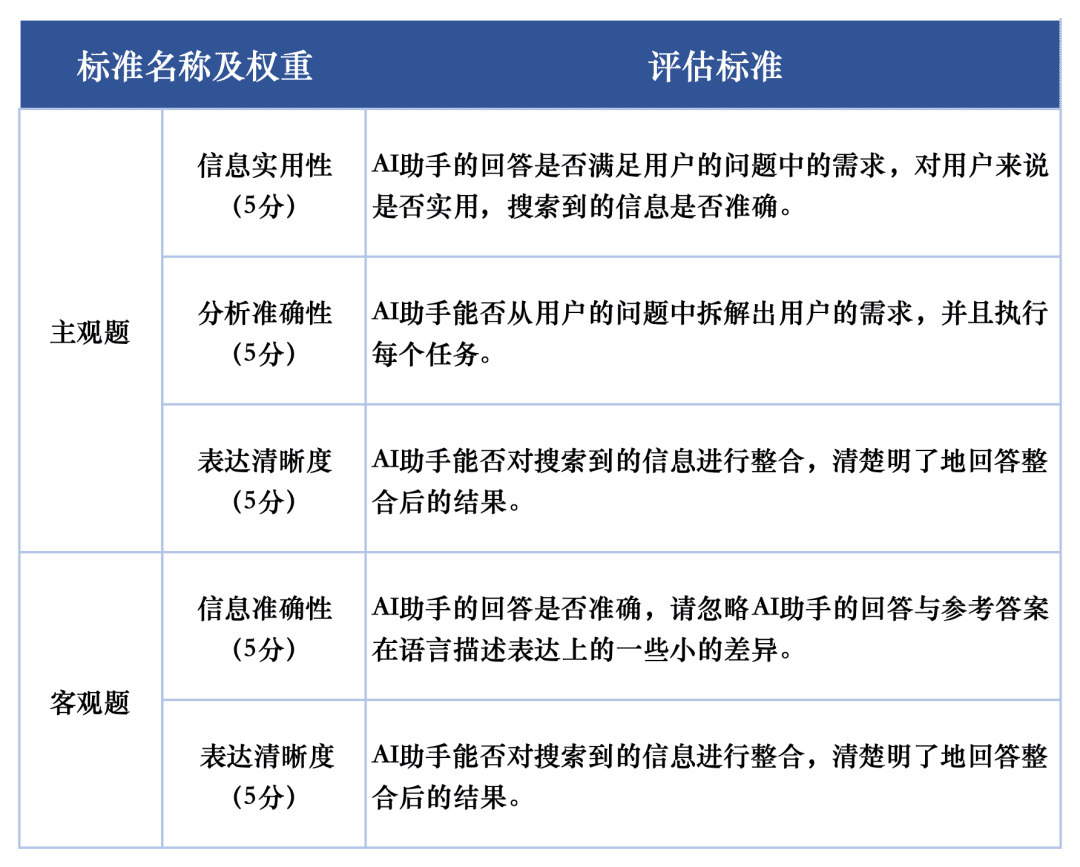
Exemple d'évaluation
Question à choix multiples Question à choix multiples : quand et où le vaisseau spatial habité Shenzhou 19 a-t-il été lancé et qui étaient les astronautes à cette occasion ?
Réponse : Aux premières heures du 30 octobre, le lancement du vaisseau spatial habité Shenzhou XIX depuis le centre de lancement de satellites de Jiuquan a été un succès total. L'équipage de la mission habitée Shenzhou-19 était composé de trois astronautes, Cai Xuzhe, Song Lingdong et Wang Haize.
Modèle de réponse :
Supermodel (chatgpt-4o-latest) arbitre :
Évaluez cette réponse comme suit :
La réponse de l'assistant d'IA a indiqué avec précision l'heure et le lieu de lancement du vaisseau spatial habité Shenzhou XIX, ainsi que la liste des astronautes. Cependant, la réponse ne mentionnait pas les principaux objectifs et le contenu de la mission, ce qui n'a pas permis de satisfaire pleinement le besoin de l'utilisateur de connaître les détails de la mission. En outre, la section sur les profils personnels des astronautes, bien que détaillée, a peut-être dépassé le champ d'intérêt des utilisateurs. Il est donc recommandé d'ajouter à la réponse une brève description des objectifs et des principales tâches de la mission afin de mieux répondre aux besoins des utilisateurs.1 Utilité de l'information (5 points) :
L'assistant d'IA a fourni l'heure de lancement, le lieu et la liste des astronautes de Shenzhou XIX, répondant ainsi au besoin de l'utilisateur de disposer de ces informations de base. Cependant, les principaux objectifs de la mission et son contenu n'ont pas été mentionnés, ce qui n'a pas permis de satisfaire pleinement le besoin de l'utilisateur de connaître les détails de la mission. Par conséquent, la note attribuée à l'utilité de l'information est de 4.
Score : 4/52 Précision de l'analyse (5 points) :
L'assistant d'IA a extrait avec précision des informations clés telles que l'heure de lancement, le lieu et la liste des astronautes à partir de la question de l'utilisateur et a fourni un profil personnel détaillé. Cependant, il n'a pas abordé les objectifs et le contenu principal de la mission, et n'a pas réussi à répondre pleinement aux besoins de l'utilisateur. La précision de l'analyse a donc été de 4.
Score : 4/53. clarté de l'expression (5 points) :
Les réponses de l'assistant d'intelligence artificielle sont clairement structurées, avec des informations bien organisées et faciles à comprendre. La section relative au profil personnel est détaillée, ce qui permet aux utilisateurs de comprendre facilement les antécédents de l'astronaute. Par conséquent, la clarté de l'expression est notée 5.
Score : 5/5 score composite = 4*0,6 + 4*0,2 + 5*0,2 = 4,2 En combinant les éléments ci-dessus, le score composite de la réponse de l'assistant IA est de 4,2. (sur 5 points)
Modèles participants
Afin de mesurer de manière exhaustive le niveau de développement actuel des grands modèles nationaux et internationaux en matière de capacité de recherche d'IA, 4 modèles étrangers et 10 modèles nationaux représentatifs ont été sélectionnés pour cette évaluation.
Étant donné que de nombreux modèles à grande échelle, dans le pays et à l'étranger, proposent généralement deux versions ou plus, dont une version ordinaire et une version d'exploration approfondie, nous adoptons un critère unifié dans ce processus de sélection des modèles : si un modèle est équipé d'une version de recherche ou d'analyse plus approfondie, nous sélectionnons la version ayant la plus forte capacité de recherche pour l'évaluation complète. 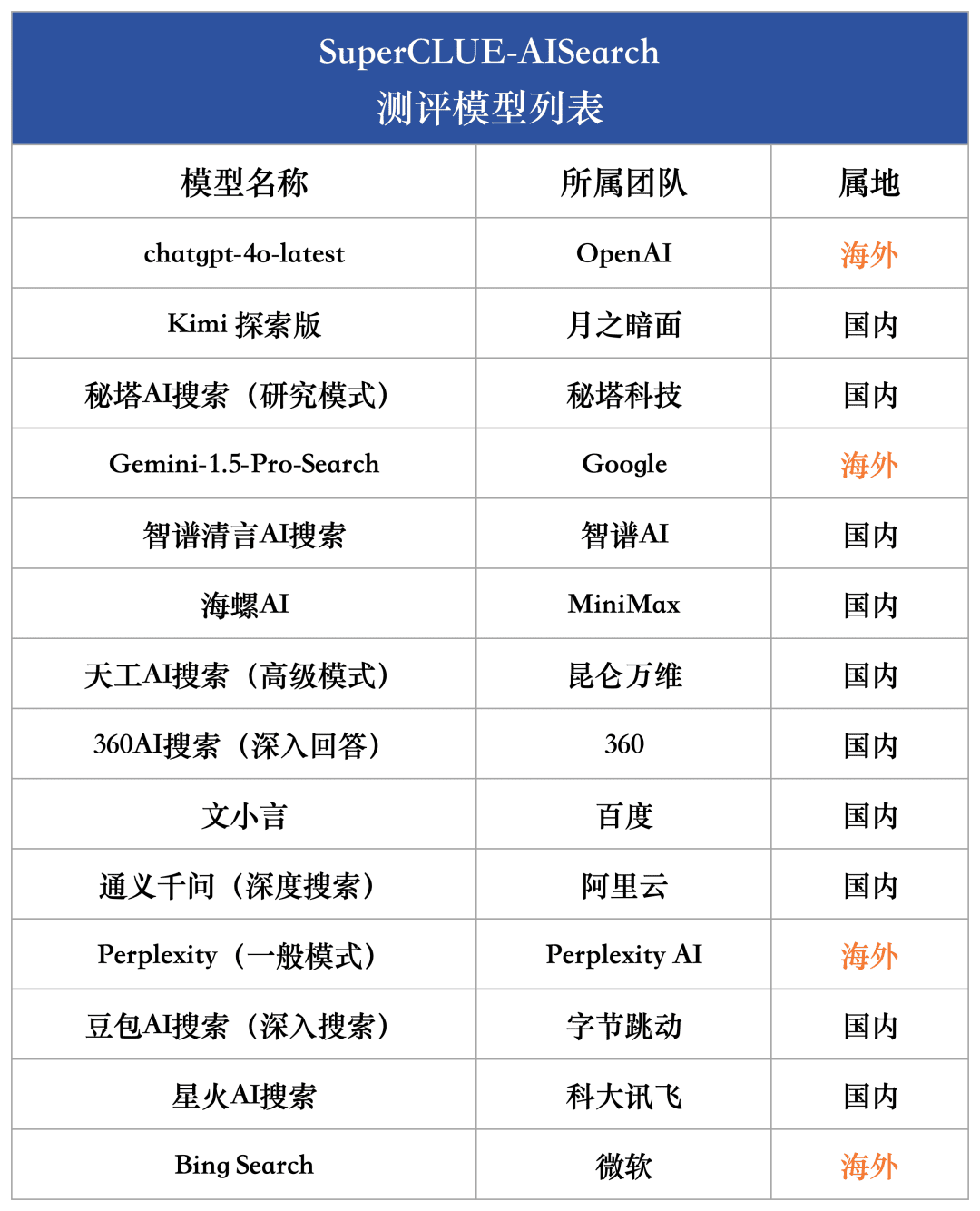
Résultats de l'évaluation
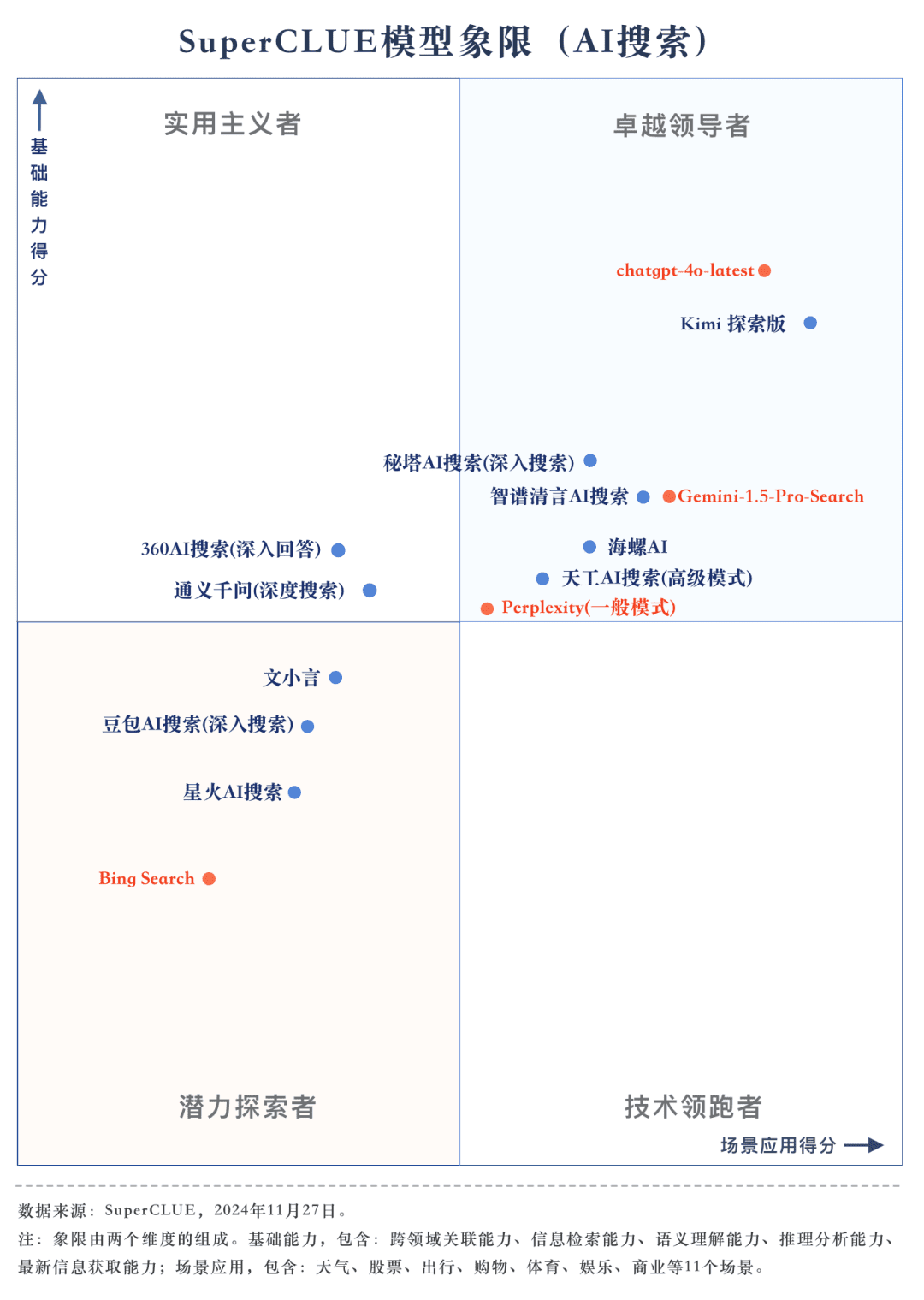
liste globale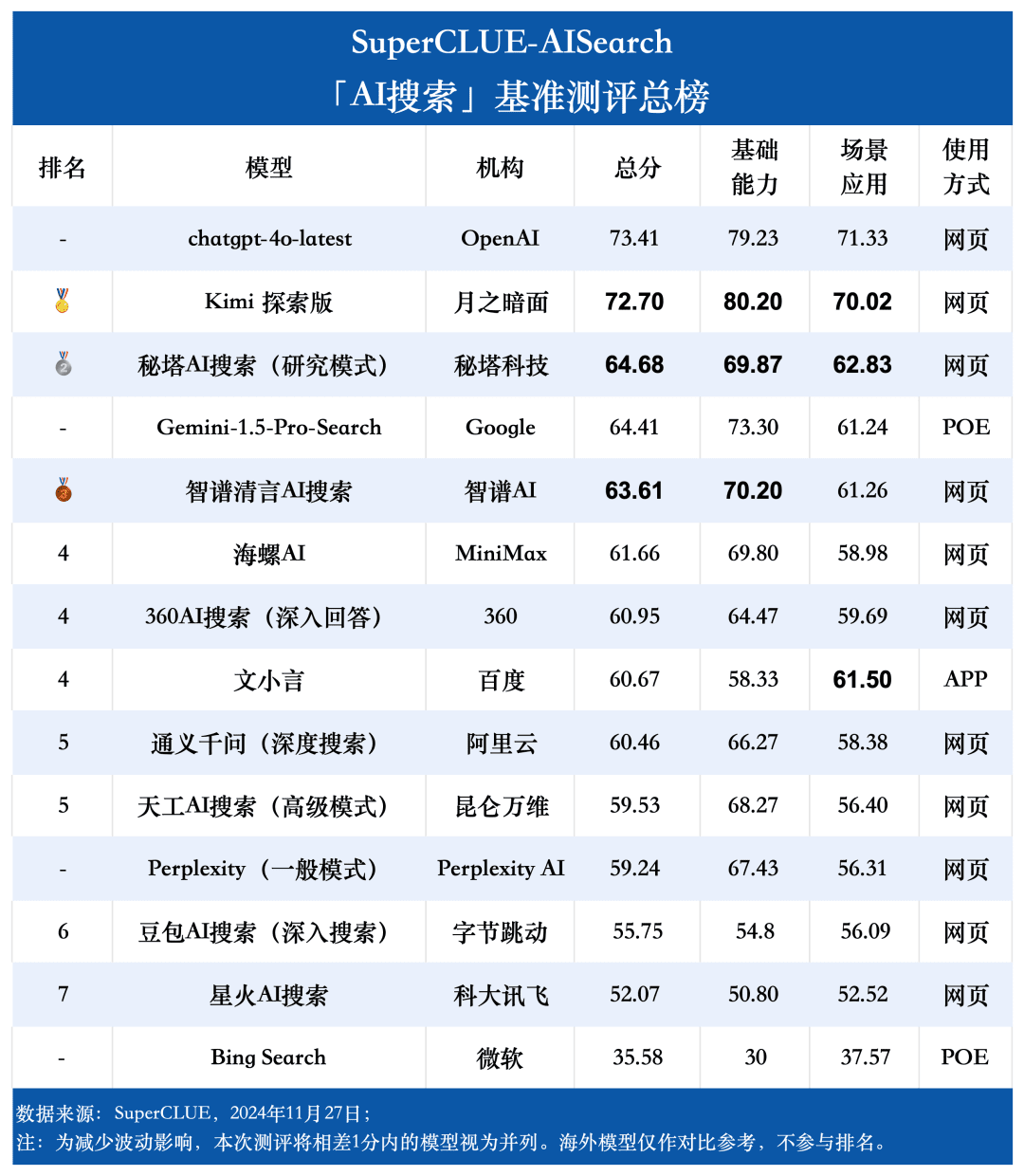
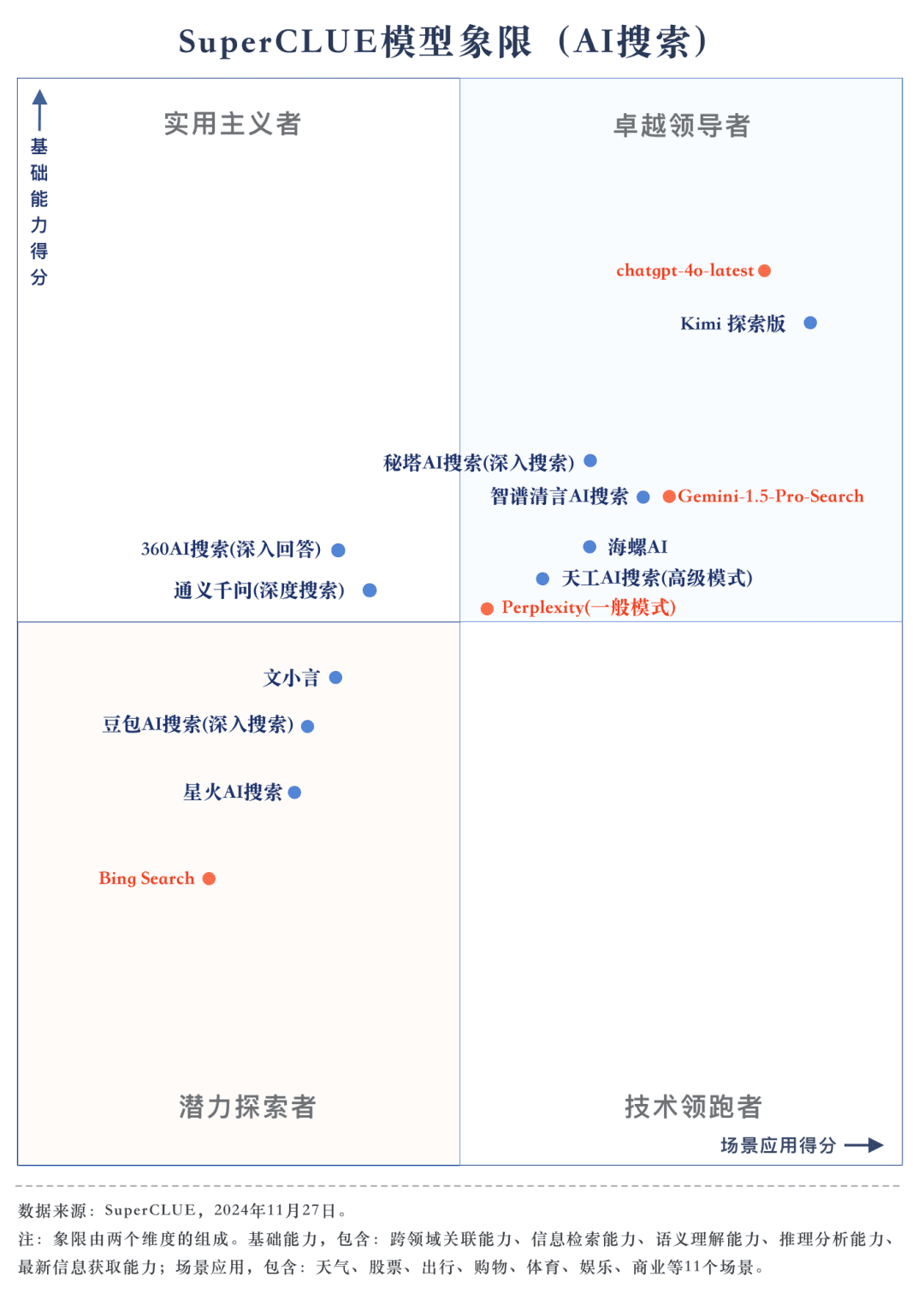
Liste des capacités de base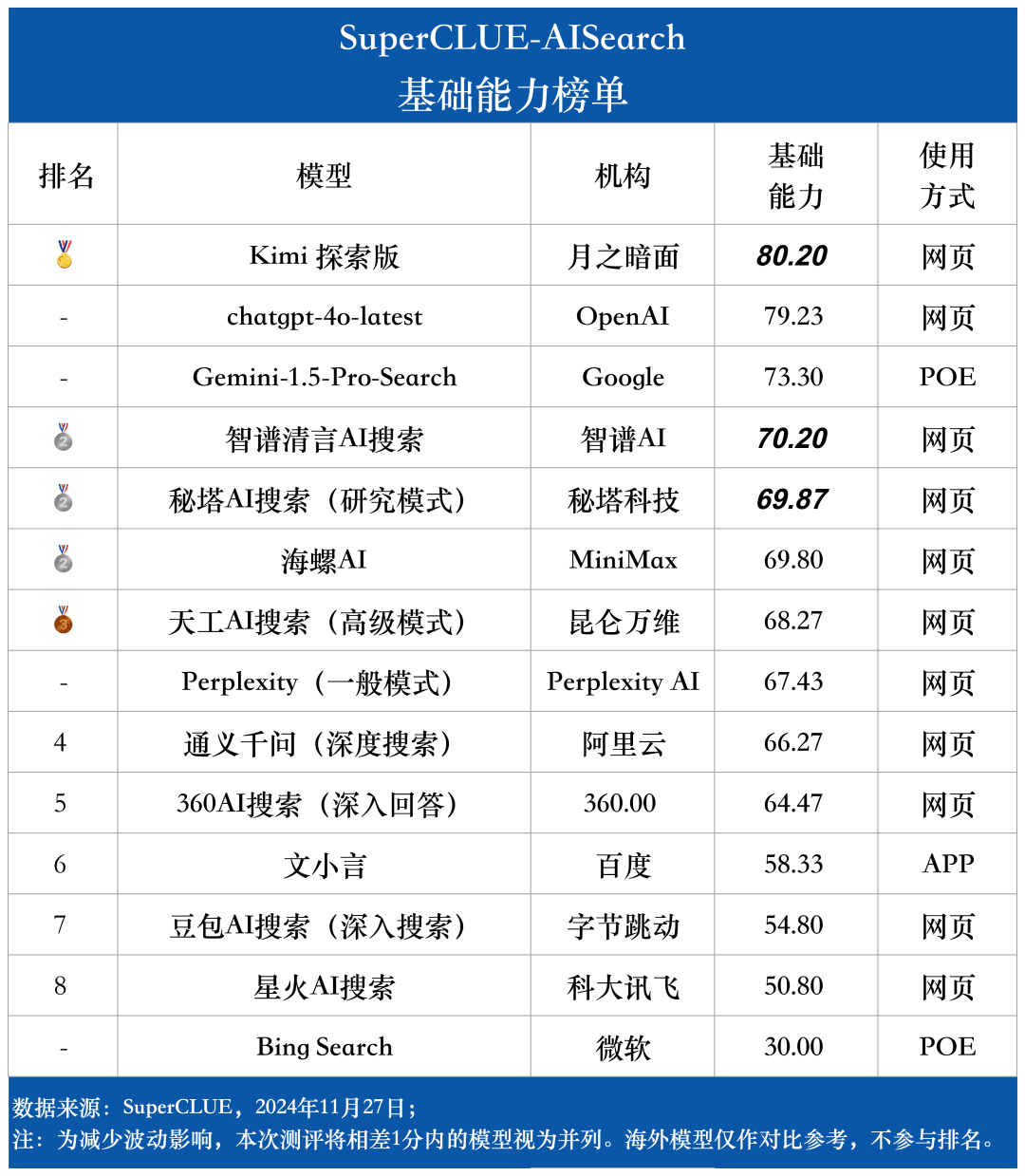
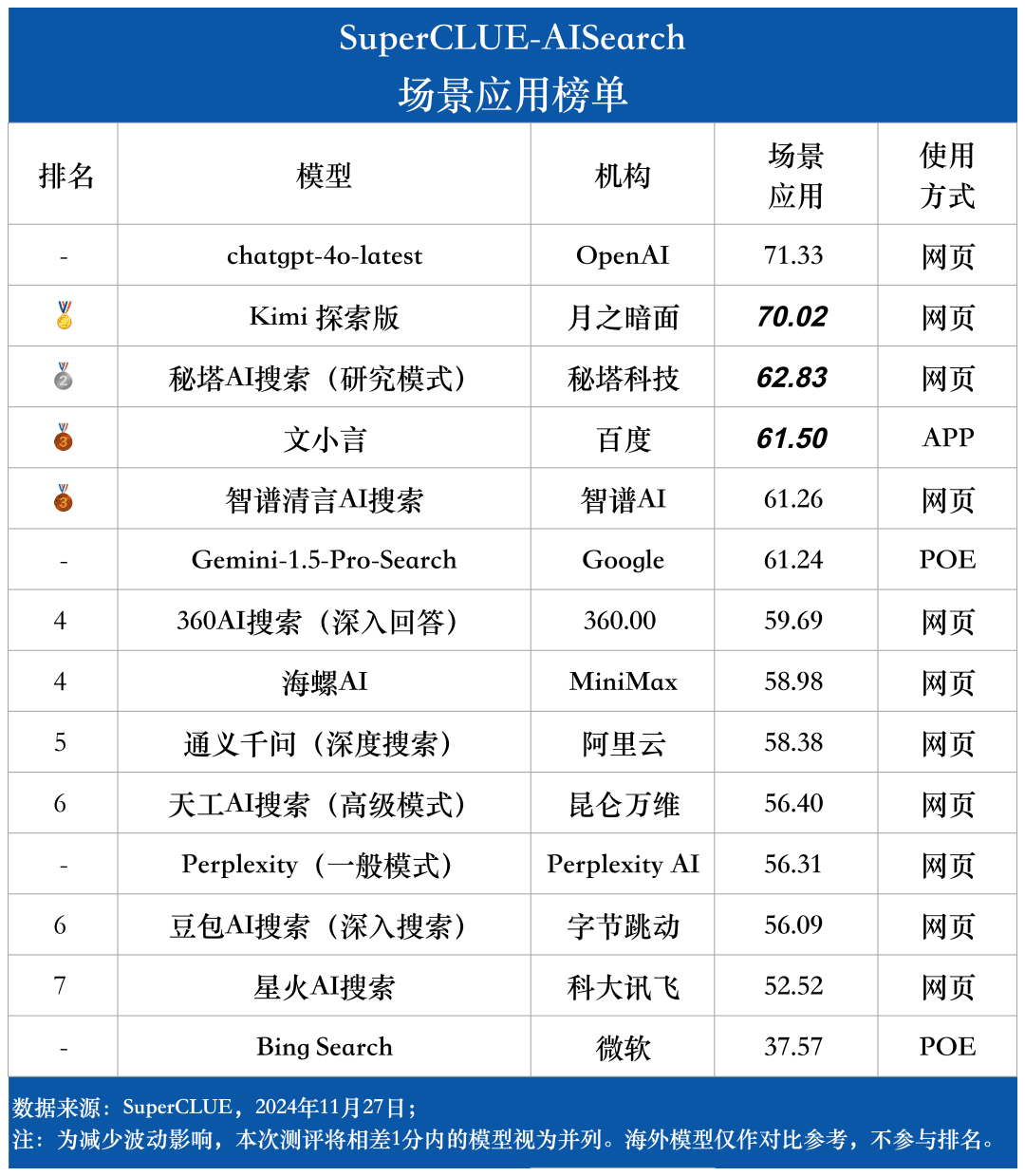
Liste des applications du scénario
Liste des questions subjectives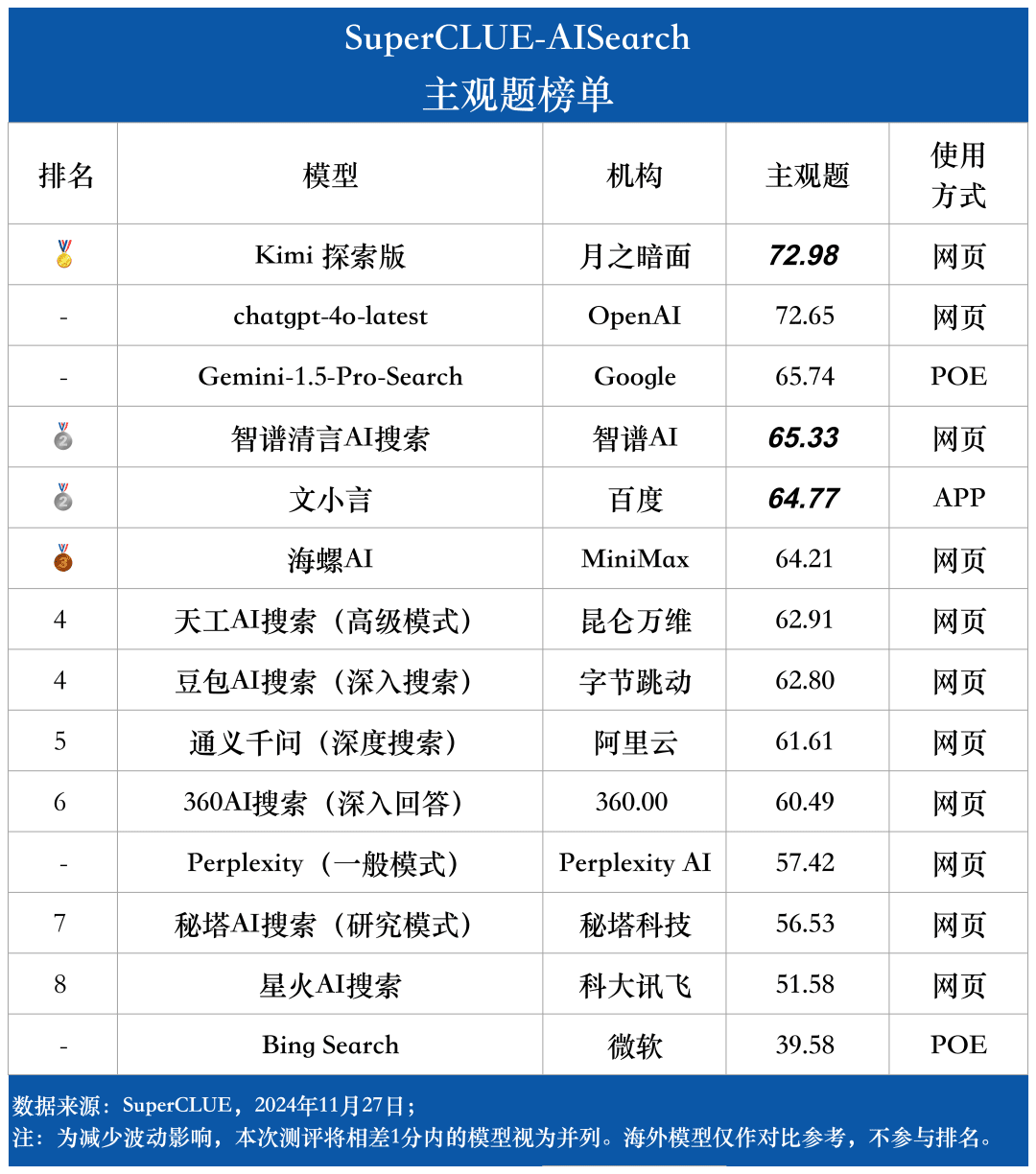
Liste des questions objectives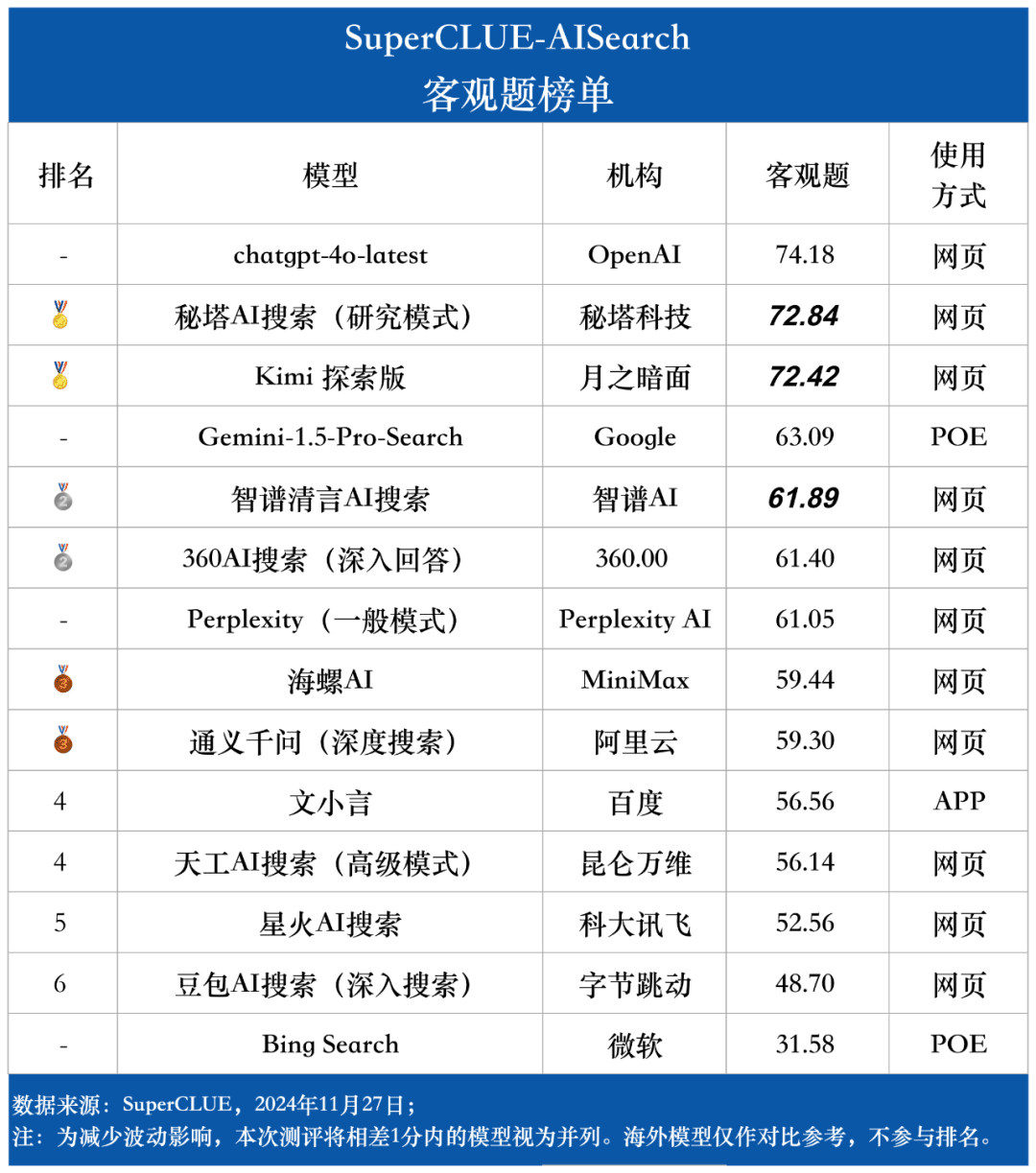
Exemple de comparaison de modèles
Exemple 1 Compétences de base - capacités de raisonnement et d'analyse
Invitation : "Pourquoi la structure du modèle GPT-1 est-elle utilisée ? Transformateur Au lieu de LSTM ?"
Comparaison des réponses des modèles (sur 5) :
[Kimi Explorer] : 4 points 
[chatgpt-4o-latest] : 3,9 points 
[Skyworks AI Search (Mode avancé)] : 3,4 points 
Exemple 2 Compétences de base - liens transversaux
PromptPrompt : "Aidez-moi à trouver toutes les applications de la technologie de vision par ordinateur dans l'agriculture, choisissez-en trois et décrivez brièvement chacune d'entre elles."
Comparaison des réponses des modèles (sur 5) :
[Recherche AI de la tour secrète (mode recherche)] : 4 points 
[Wen Xiaoyan] : 3,4 points 
[Recherche de l'IA de Starfire] : 3 points 
Exemple 3 Scénario d'application - Actions
Invitation : "Veuillez m'indiquer plusieurs marchés haussiers importants des actions A au cours des dernières années et les données correspondantes (par exemple, date de début, durée, taux d'augmentation, points les plus élevés et les plus bas, etc.) Comparaison des réponses des modèles (sur 5 points) : [Gemini-1.5-Pro-Search] : 3,2 points 
[Smart Spectrum Clear Speech AI Search] : 3,3 points 
Bing Search] : 2,6 points 
Exemple 4 Scène Application-Life
Invitation : "De janvier à octobre de cette année, la production et les ventes d'automobiles en Chine ont atteint respectivement combien de millions d'unités, et de quel pourcentage ont-elles augmenté par rapport à la même période de l'année dernière ?"
Comparaison des réponses des modèles (sur 5) :
[Tongyi Mille questions (recherche approfondie)] : 4,2 points 
[Recherche 360AI (réponse approfondie)] : 3,8 points 
Évaluation de la cohérence humaine
Pour garantir la validité scientifique de l'évaluation automatisée des grands modèles, nous avons évalué la cohérence humaine du GPT-4o-0513 dans la tâche d'évaluation de la recherche d'IA.
La méthode d'exploitation spécifique est la suivante : cinq modèles sont sélectionnés et chaque modèle est noté indépendamment par une personne, respectivement, pour les différentes dimensions des questions subjectives et objectives, puis pondéré pour l'établissement de la moyenne en fonction des critères de notation. Nous calculons la différence entre les notes humaines et les notes du modèle pour chaque question, puis nous faisons la somme et la moyenne pour obtenir l'écart moyen pour chaque question en tant que résultat de l'évaluation de la cohérence humaine.
Les résultats moyens finaux obtenus sont les suivants : Le résultat moyen de l'écart est de (en pourcentage) : 5,1 points.
En raison de la grande fiabilité de cette évaluation automatisée.
Analyse de l'évaluation et conclusion
1. la capacité de recherche de l'IA, chatgpt-4o-latest, reste à la pointe.
Comme le montrent les résultats de l'évaluation, chatgpt-4o-latest (73,41 points) a une excellente capacité globale et domine le benchmark SuperCLUE-AISearch. Il n'a que 0,71 point de plus que le meilleur modèle national, Kimi Explorer.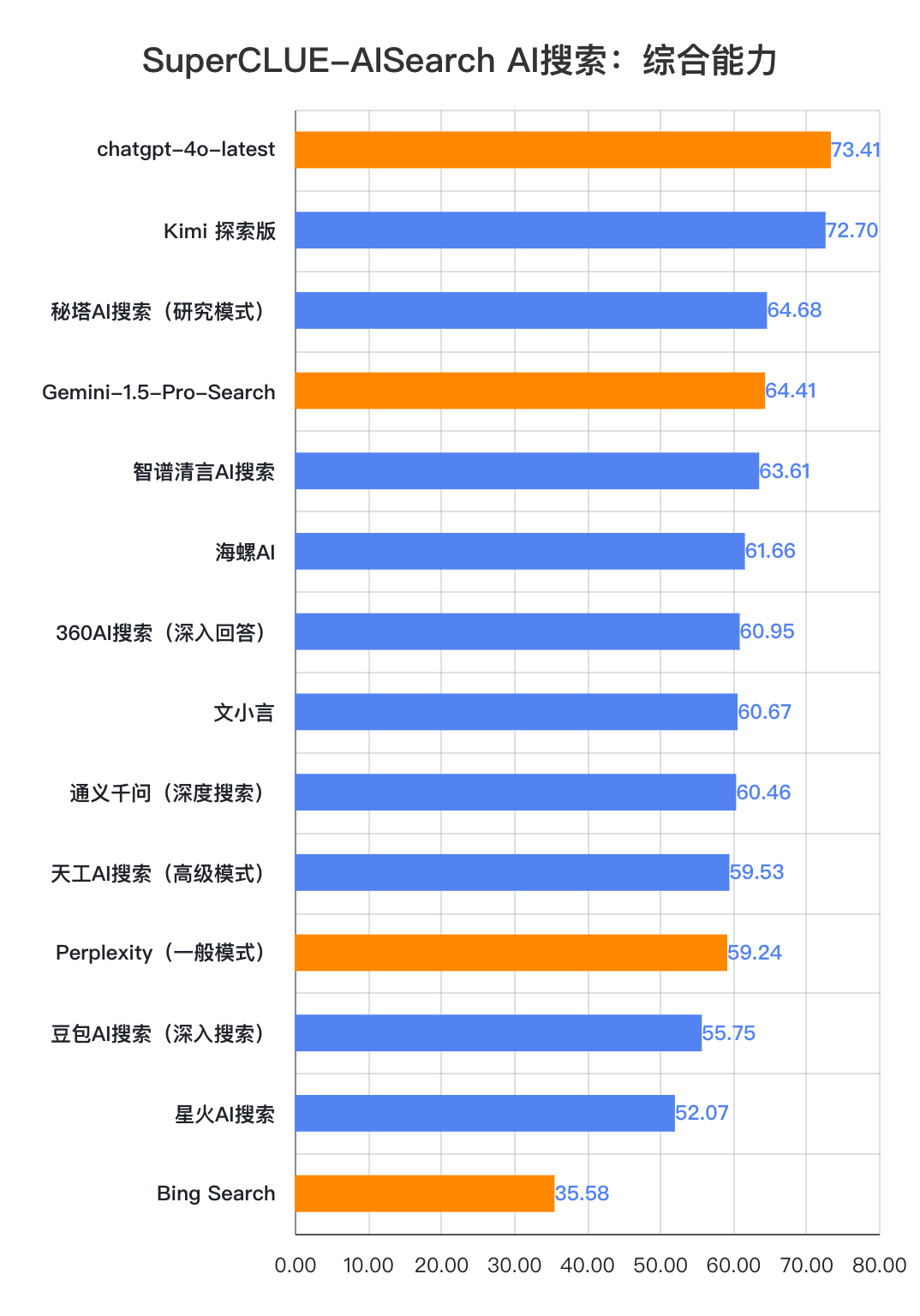
2. les performances globales des grands modèles domestiques sont assez impressionnantes, avec des différences relativement faibles entre les modèles
D'après les résultats de l'évaluation, les modèles nationaux tels que Secret Tower AI Search (modèle de recherche), Wisdom Spectrum Clear Speech AI Search et Conch AI affichent des performances relativement bonnes en termes de capacités de base et sont en mesure de rattraper le grand modèle étranger Gemini-1.5-Pro-Search. Dans l'ensemble, les performances de plusieurs modèles nationaux situés au milieu des résultats globaux, tels que Conch AI, Wen Xiaoyin et Tongyi Qianqian (recherche approfondie), ne sont pas comparables entre les modèles et présentent une faible différence.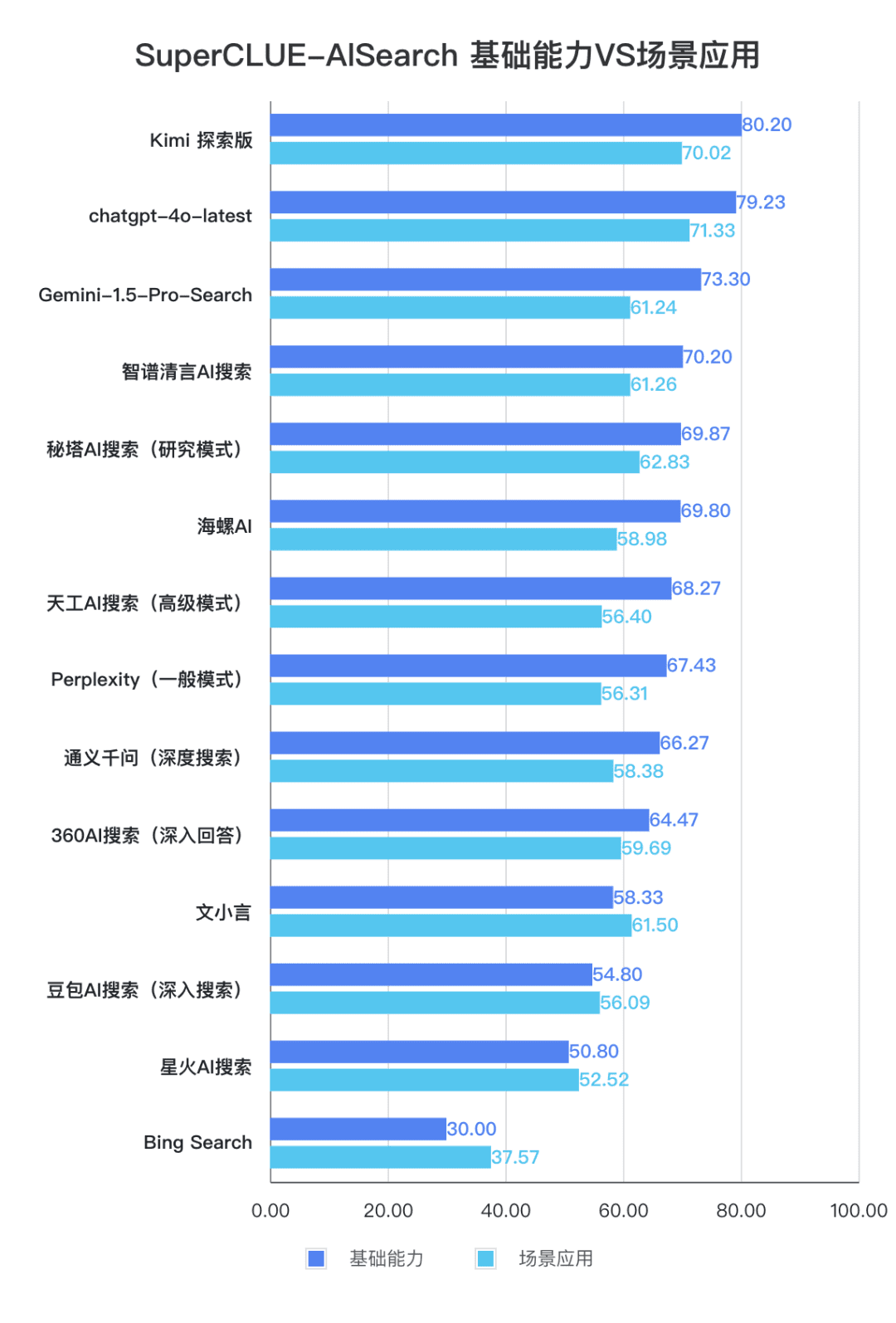
3. le modèle présente différents niveaux de performance dans différents scénarios d'application.
Dans le cadre de l'examen de la recherche par l'IA, nous nous sommes concentrés sur les performances des modèles dans différents scénarios d'application. Le grand modèle national obtient de bons résultats dans les domaines de la science et de la technologie, de la culture, des affaires et du divertissement, et fait preuve d'une bonne capacité à récupérer et à intégrer des informations tout en saisissant avec précision l'actualité de l'information. Cependant, dans les scénarios boursiers et sportifs, les grands modèles nationaux ont encore une marge d'amélioration évidente.
Par exemple, dans le processus de recherche d'IA, le modèle doit désassembler avec précision les besoins de recherche de l'utilisateur, rechercher les pages web pertinentes avec des informations temporelles précises, et enfin intégrer les informations pour former une copie des résultats de la réponse qui sont pratiques pour l'utilisateur. D'après les observations actuelles, les grands modèles nationaux sont parfois incapables d'analyser avec précision les besoins de recherche et se réfèrent parfois à des contenus web non pertinents lors du processus d'intégration des informations, ce qui conduit à des performances médiocres des grands modèles nationaux dans certains scénarios.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...