Le mot "agent" est déprimant, les modèles GPT-4 ne valent plus la peine d'être mentionnés, et les grands programmeurs font le point sur "The Big Model 2024".

Les experts s'accordent généralement à dire que 2024 sera l'année de l'AGI. C'est l'année où l'industrie de la modélisation changera à jamais :
Le GPT-4 de l'OpenAI n'est plus hors de portée ; les travaux sur les modèles de génération d'images et de vidéos deviennent de plus en plus réalistes ; des percées ont été réalisées dans les modèles multimodaux de langage étendu, les modèles d'inférence et les intelligences (agents) ; et les humains se soucient de plus en plus de l'IA. ......
Alors, pour un connaisseur chevronné du secteur, comment l'industrie des grands modèles a-t-elle évolué au cours de l'année ?
Il y a quelques jours, le célèbre programmeur indépendant, cofondateur de l'annuaire de conférences sociales Lanyrd et cocréateur du framework web Django Simon Willison dans le rapport intitulé Ce que nous avons appris sur les LLM en 2024 L'article examine en détail les Changements, surprises et lacunes dans l'industrie des grands modèles en 2024.

Certains de ces points sont présentés ci-dessous :
- En 2023, former un modèle classé GPT-4 est une grande affaire. Cependant, en 2024, ce n'est même pas une réalisation particulièrement remarquable.
- Au cours de l'année écoulée, nous avons réalisé d'incroyables gains de performance en matière de formation et d'inférence.
- La baisse des prix est due à deux facteurs : l'intensification de la concurrence et les gains d'efficacité.
- Ceux qui se plaignent de la lenteur des progrès du LLM ont tendance à ignorer les grandes avancées de la modélisation multimodale.
- La génération rapide d'applications est devenue une commodité.
- L'époque de l'accès gratuit aux modèles SOTA est révolue.
- Intelligentsia, toujours pas née.
- L'écriture de bonnes évaluations automatisées pour les systèmes pilotés par LLM est la compétence la plus nécessaire pour construire des applications utiles au-dessus de ces modèles.
- o1 Nouvelles approches pour les modèles étendus : résoudre des problèmes plus difficiles en consacrant plus de temps de calcul à l'inférence.
- La réglementation américaine sur les exportations de GPU chinoises semble avoir inspiré des optimisations de formation très efficaces.
- Au cours des dernières années, la consommation d'énergie et l'impact sur l'environnement du fonctionnement des prompteurs ont été considérablement réduits.
- Les contenus non sollicités et non censurés générés par l'intelligence artificielle sont des "déchets".
- La clé pour tirer le meilleur parti du LLM est d'apprendre à utiliser des techniques peu fiables mais puissantes.
- Le LLM a une valeur réelle, mais la réalisation de cette valeur n'est pas intuitive et nécessite des conseils.
Sans modifier l'orientation générale du texte original, le contenu global a été condensé comme suit :
Il se passe beaucoup de choses dans le domaine de la modélisation des langues en 2024. Voici un aperçu de ce que nous avons découvert dans ce domaine au cours des 12 derniers mois, ainsi que mes tentatives d'identifier les thèmes et les moments clés. En ce compris 19 Aspects :
1) Les douves du GPT-4 ont été "percées".
Dans ma critique de décembre 2023, j'ai écrit : "Nous ne savons pas encore comment construire le GPT-4.-- À l'époque, le GPT-4 était disponible depuis près d'un an, mais les autres laboratoires d'IA n'avaient pas encore réalisé de meilleur modèle... Que sait OpenAI que le reste d'entre nous ne sait pas ?
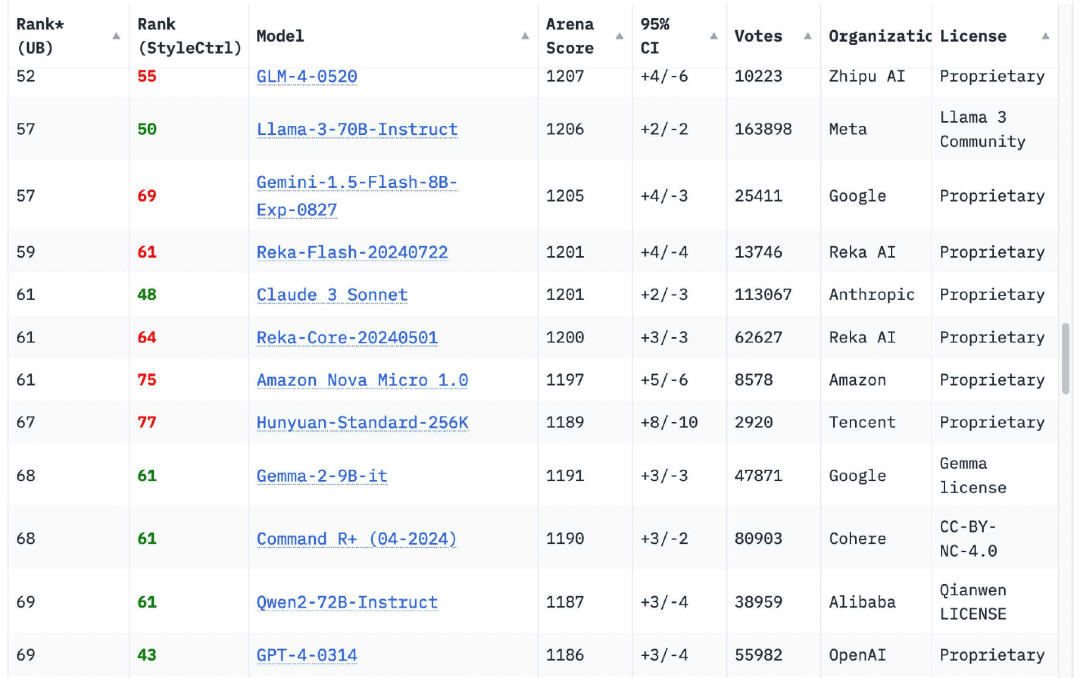
À mon grand soulagement, cela a complètement changé au cours des 12 derniers mois. Le classement de la Chatbot Arena comporte désormaisModèles de 18 organisationsPlus élevé que la version originale du GPT-4 (GPT-4-0314) publiée en mars 2023, ce nombre atteint 70
Le premier challenger a été Google, qui a publié en février 2024 le Gémeaux 1.5 Pro. En plus d'offrir une sortie de niveau GPT-4, il apporte plusieurs nouvelles caractéristiques dans le domaine, dont les suivantesLe plus remarquable est la longueur du contexte d'entrée de 1 million (plus tard 2 millions) de jetons, et la possibilité d'entrer des vidéos..
Gemini 1.5 Pro déclenche l'un des thèmes clés de 2024 : l'augmentation de la longueur du contexte.En 2023, la plupart des modèles ne pourront accepter que 4096 ou 8192 jetons.Jamahiriya arabe libyenne Claude L'exception est le modèle 2.1, qui accepte 200 000 jetons. Aujourd'hui, tous les fournisseurs de modèles ont un modèle qui accepte plus de 100 000 jetons. jeton la série Gemini de Google peut accepter jusqu'à 2 millions de jetons.
Des entrées plus longues augmentent considérablement la gamme de problèmes pouvant être résolus à l'aide de LLM : vous pouvez maintenant saisir un livre entier et poser des questions sur son contenu, mais plus important encore, vous pouvez saisir une grande quantité d'exemples de code pour aider le modèle à résoudre correctement le problème de codage. Pour moi, les cas d'utilisation du LLM impliquant de longues entrées sont beaucoup plus intéressants que les invites courtes qui reposent uniquement sur des informations relatives aux poids du modèle. Nombre de mes outils sont construits à l'aide de ce modèle.
Passons aux modèles qui ont "battu" le GPT-4 : la série Claude 3 d'Anthropic a été lancée en mars, et le Claude 3 Opus est rapidement devenu mon modèle préféré. en juin, ils ont suivi avec le Claude 3.5 Sonnet - et six mois plus tard, c'est toujours mon préféré ! Six mois plus tard, c'est toujours mon modèle préféré.
Bien sûr, il y en a d'autres. Si vous parcourez le classement du Chatbot Arena aujourd'hui, vous verrez que leGPT-4-0314 est tombé à la 70ème place.. Les 18 organisations ayant obtenu des scores élevés sont Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, Zero One Thing, Amazon, Cohere, DeepSeek, NVIDIA, Mistral, NexusFlow, Smart Spectrum, xAI, AI21 Labs, l'université de Princeton et Tencent.
Former un modèle de niveau GPT-4 en 2023 n'est pas une mince affaire. Cependant, lesEn 2024, ce n'est même pas une réalisation particulièrement remarquableMais personnellement, je continue à me réjouir chaque fois qu'une nouvelle organisation s'ajoute à la liste.
2. ordinateur portable, prêt à exécuter des modèles de niveau GPT-4
Mon ordinateur portable personnel est un MacBook Pro 2023 64GB M2. C'est une machine puissante, mais elle a aussi presque deux ans - et plus important encore, c'est le même ordinateur portable que j'utilise depuis mars 2023, lorsque j'ai lancé le LLM sur mon propre ordinateur.
En mars 2023, cet ordinateur portable ne pourra toujours faire tourner qu'un seul modèle de niveau GPT-3Le modèle GPT-4 est désormais capable d'exécuter plusieurs modèles de niveau GPT-4 !
Cela me surprend encore. Je pensais qu'il faudrait un ou plusieurs serveurs de niveau centre de données avec des GPU à plus de 40 000 dollars pour atteindre la fonctionnalité et la qualité de sortie du GPT-4.
Les modèles occupent 64 Go de ma mémoire, c'est pourquoi je ne les utilise pas très souvent, car ils ne laissent pas beaucoup de place pour autre chose.
Le fait qu'ils fonctionnent témoigne des incroyables gains de performance en matière de formation et d'inférence que nous avons réalisés au cours de l'année écoulée. Il s'avère que nous avons récolté beaucoup de fruits visibles en termes d'efficacité des modèles. J'espère qu'il y en aura d'autres à l'avenir.
Les modèles de la série Llama 3.2 de Meta méritent une mention spéciale. Ils ne sont peut-être pas classés GPT-4, mais dans les tailles 1B et 3B, ils donnent des résultats qui dépassent les attentes.
3. les prix de l'apprentissage tout au long de la vie ont considérablement baissé grâce à la concurrence et aux gains d'efficacité
Au cours des douze derniers mois, le coût de l'utilisation du LLM a considérablement baissé.
Décembre 2023, OpenAI facture un jeton d'entrée de 30 millions de dollars pour GPT-4(mTok) coûtsEn outre, une taxe de 10 USD/mTok a été prélevée pour le GPT-4 Turbo, alors nouvellement introduit, et de 1 USD/mTok pour le GPT-3.5 Turbo.
Aujourd'hui, le modèle o1 le plus cher d'OpenAI est disponible pour 30 $/mTok !Le GPT-4o coûte 2,50 dollars (12 fois moins cher que le GPT-4), et le GPT-4o mini coûte 0,15 dollar/mTok, soit près de sept fois moins cher que le GPT-3.5 et plus puissant.
D'autres fournisseurs de modèles facturent encore moins, avec le Claude 3 Haiku d'Anthropic à 0,25 $/mTok, le Gemini 1.5 Flash de Google à 0,075 $/mTok, et le Gemini 1.5 Flash 8B à 0,0375 $/mTok, soit 27 fois moins cher que le GPT-3.5 Turbo en 2023. Turbo en 2023.
La baisse des prix est due à deux facteurs : une concurrence accrue et des gains d'efficacité. Les améliorations de l'efficacité sont importantes pour tous ceux qui se préoccupent de l'impact environnemental du LLM. Ces réductions de prix sont directement liées à l'énergie consommée pour faire fonctionner l'appareil.
L'impact environnemental de la construction des centres de données d'IA reste préoccupant, mais les inquiétudes concernant les coûts énergétiques des différentes invites ne sont plus crédibles.
Faisons un calcul intéressant : combien cela coûterait-il de générer des descriptions courtes pour chacune des 68 000 photos de ma photothèque personnelle en utilisant la version la moins chère de Google, Gemini 1.5 Flash 8B ?
Chaque photo nécessite 260 jetons d'entrée et environ 100 jetons de sortie.
260 * 68000 = 17680000 Entrer le jeton
17680000 * 0,0375 $/million = 0,66 $.
100 * 68000 = 6800 000 Jeton de sortie
6800000 * 0,15 $/million = 1,02
Le coût total du traitement de 68 000 images est de 1,68 $.. C'était tellement bon marché que j'ai même fait les calculs trois fois pour m'assurer que j'avais bien compris.
Quelle est la qualité de ces descriptions ? J'ai obtenu les informations de cette commande :
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
Cette photo d'un papillon provient de l'Académie des sciences de Californie :

Sur la photo, il y a un plat rouge peu profond qui pourrait être une mangeoire pour colibris ou papillons. L'assiette contient des tranches de fruits orange.
Il y a deux papillons dans la mangeoire, l'un est brun foncé/noir avec des marques blanches/crèmes. L'autre est un papillon brun plus grand avec des marques brun clair, beige et noir, y compris des ocelles proéminents. Ce papillon brun plus grand semble manger des fruits dans une assiette.
260 jetons d'entrée, 92 jetons de sortie, pour un coût d'environ 0,0024 cent (moins de 400e de cent).
L'amélioration de l'efficacité et la baisse des prix sont mes tendances préférées pour 2024.Je veux l'utilité du LLM pour une fraction du coût de l'énergie, et c'est exactement ce que nous faisons.
4. la vision multimodale est devenue courante, l'audio et la vidéo commencent à émerger
Mon exemple de papillon ci-dessus illustre également une autre tendance clé pour 2024 : la montée en puissance du modèle multimodal à langage étendu (MLLM).
La vision GPT-4, publiée il y a un an lors du DevDay de l'OpenAI en novembre 2023, en est l'exemple le plus notable. Google, quant à lui, a publié la version multimodale Gemini 1.0 le 7 décembre 2023.
En 2024, presque tous les fournisseurs de modèles ont publié des modèles multimodaux.Nous l'avons vu en mars. Anthropique La série Claude 3 a été présentée en avril avec le Gemini 1.5 Pro (image, audio et vidéo) et en septembre avec le Gemini 1.5 Pro (image, audio et vidéo). Mistral Pixtral 12B, et les modèles visuels Llama 3.2 11B et 90B de Meta. Nous avons obtenu des entrées et sorties audio d'OpenAI en octobre, SmolVLM de Hugging Face en novembre, et des modèles d'images et de vidéos d'Amazon Nova en décembre.
C'est ce que je pense.Ceux qui se plaignent de la lenteur des progrès du LLM ont tendance à ignorer les grandes avancées de ces modèles multimodaux. La possibilité de lancer des messages-guides à partir d'images (ainsi que de fichiers audio et vidéo) est une nouvelle façon fascinante d'appliquer ces modèles.
5. des modes vocaux et vidéo en temps réel pour faire de la science-fiction une réalité
Les modèles audio et vidéo en temps réel commencent à émerger.
avec ChatGPT La fonction de dialogue débute en septembre 2023, mais il s'agit en grande partie d'une illusion : OpenAI utilise ses excellentes capacités d'analyse de l'information et d'analyse de l'information. Chuchotement et un nouveau modèle de synthèse vocale (appelé tts-1) pour permettre le dialogue avec ChatGPT, mais le modèle actuel ne peut voir que du texte.
GPT-4o d'OpenAI, publié le 13 mai, comprend une démonstration d'un nouveau modèle vocal, le modèle véritablement multimodal GPT-4o ("o" pour "omni") qui peut prendre des entrées audio et produire des discours incroyablement réalistes sans qu'il soit nécessaire de recourir à un modèle TTS ou STT distinct. incroyablement réaliste sans qu'il soit nécessaire de recourir à un modèle TTS ou STT distinct.
Lorsque le mode vocal avancé de ChatGPT a finalement été introduit, les résultats ont été étonnants.J'utilise souvent ce mode lorsque je promène mon chien et le son s'est tellement amélioré que c'est incroyable !. J'ai également eu beaucoup de plaisir à utiliser l'API audio OpenAI.
OpenAI n'est pas la seule équipe à disposer d'un modèle audio multimodal. Gemini de Google accepte également les entrées audio et peut aussi parler à la manière de ChatGPT. Amazon a également annoncé un modèle vocal pour Amazon Nova plus tôt que prévu, mais ce modèle ne sera disponible qu'au premier trimestre 2025.
Google NotebookLM Lancé en septembre, il a porté la sortie audio à un niveau supérieur, avec deux "hôtes de podcast" qui peuvent avoir des conversations réalistes sur tout ce que vous tapez, et a ajouté plus tard des commandes personnalisées.
La dernière nouveauté, qui date également de décembre, est la vidéo en temps réel. Le mode ChatGPT Voice offre désormais la possibilité de partager des séquences de caméra avec des modèles et de parler de ce que vous voyez en temps réel. Gemini de Google a également lancé une version préliminaire avec les mêmes fonctionnalités.
6. la génération rapide d'applications, qui est devenue un produit de base
Le GPT-4 peut déjà atteindre cet objectif en 2023, mais sa valeur ne devient apparente qu'en 2024.
LLM est réputé pour son incroyable talent en matière d'écriture de code. Si vous pouvez écrire une invite correctement, ils peuvent vous construire une application interactive complète en utilisant HTML, CSS et JavaScript, souvent en une seule invite.
Anthropic a porté cette idée à un niveau supérieur avec la sortie de Claude ArtifactsArtifacts est une nouvelle fonctionnalité révolutionnaire. Avec Artifacts, Claude peut écrire pour vous une application interactive à la demande et vous permettre de l'utiliser directement dans l'interface de Claude.
Il s'agit d'une application permettant d'extraire des URL, entièrement générée par Claude :
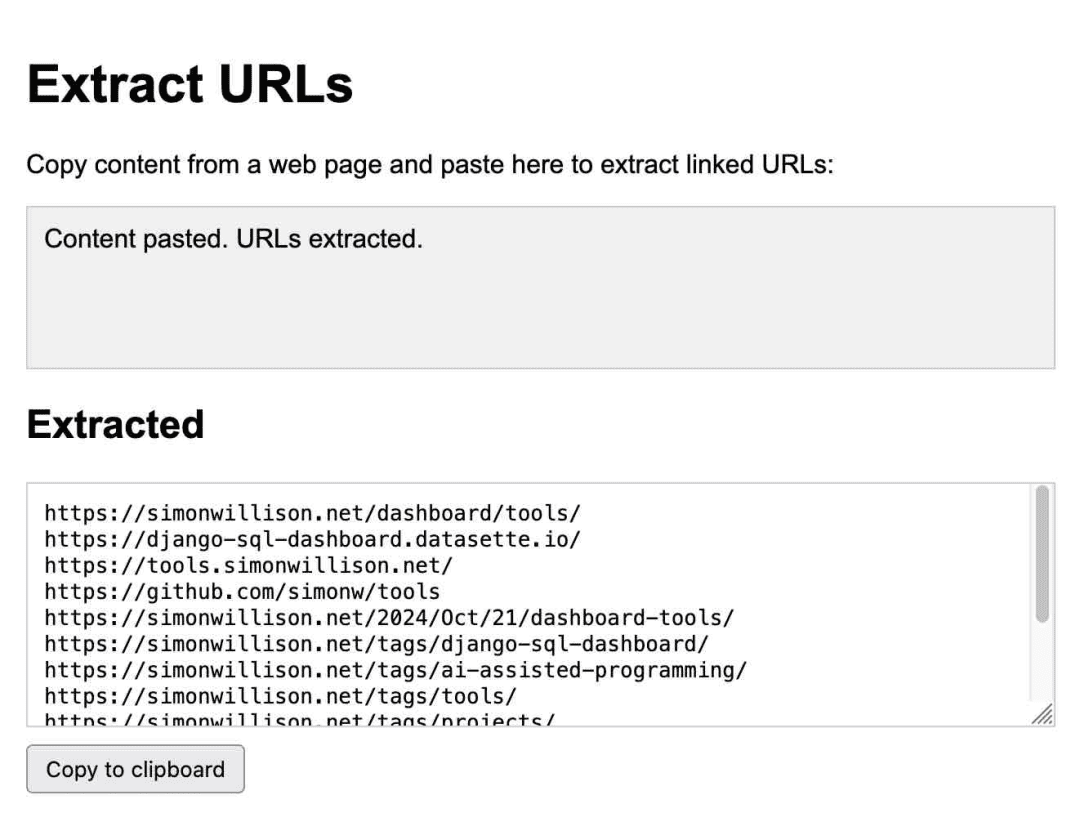
Je l'utilise régulièrement. J'ai remarqué en octobre à quel point je m'en remettais à lui, leJ'ai créé 14 gadgets en sept jours en utilisant Artifacts !.

En octobre, GitHub a publié sa version, GitHub Spark, et en novembre, Mistral Chat l'a ajouté en tant que fonction appelée Canvas.
Steve Krause de Val Town a répondu à Cérébras Une version a été construite pour montrer comment LLM avec 2000 tokens par seconde peut itérer l'application et voir les changements en moins d'une seconde.
En décembre, l'équipe de Chatbot Arena a lancé un tout nouveau classement pour cette fonctionnalité, où les utilisateurs construisent deux fois la même application interactive en utilisant deux modèles différents et votent pour les réponses. Il serait difficile d'avancer un argument plus convaincant que cette fonctionnalité est désormais un produit de base qui peut effectivement rivaliser avec tous les modèles de pointe.
J'ai réfléchi à cette version pour mon projet Datasette, dans le but de permettre aux utilisateurs d'utiliser prompt pour construire et itérer sur des gadgets personnalisés et visualiser des données basées sur leurs propres données. J'ai également trouvé un modèle similaire pour écrire des programmes Python ponctuels via uv.
Ce type d'interface personnalisée pilotée par des invites est tellement puissant et facile à construire (une fois que l'on a compris les subtilités du sandboxing du navigateur) que je m'attends à ce qu'il apparaisse comme une fonctionnalité dans une variété de produits d'ici 2025.
7) En quelques mois, des modèles puissants ont été popularisés
Dans quelques mois, en 2024, des modèles puissants seront disponibles gratuitement dans la plupart des pays du monde.
OpenAI a rendu GPT-4o gratuit pour tous les utilisateurs en mai, tandis que Claude 3.5 Sonnet a été rendu gratuit avec son lancement en juin. Il s'agit d'un changement important, car l'année dernière, les utilisateurs gratuits n'ont pu utiliser que des modèles au niveau GPT-3.5, ce qui, dans le passé, aurait conduit à un manque de clarté pour les nouveaux utilisateurs quant aux capacités réelles du LLM.
Avec le lancement de ChatGPT Pro par OpenAI, l'époque semble révolue, très probablement de façon permanente !Cet abonnement de 200 $/mois est le seul moyen d'accéder à son modèle le plus puissant, le o1 Pro. Ce service d'abonnement à 200 $/mois est le seul moyen d'accéder à son modèle le plus puissant, l'o1 Pro.
La clé de la série o1 (et des futurs modèles qui l'inspireront sans doute) est de passer plus de temps de calcul pour obtenir de meilleurs résultats. A ce titre, je pense que l'époque de l'accès gratuit aux modèles SOTA est révolue.
8. les corps intelligents, pas encore vraiment nés
A mon avis personnel.Le mot "agent" est très frustrant.. Il n'a pas de signification unique, claire et largement comprise ...... Mais ceux qui utilisent ce terme ne semblent jamais le reconnaître.
Si vous me dites que vous construisez un "agent", vous ne me communiquez rien. Sans lire dans vos pensées, je n'ai aucun moyen de savoir de laquelle des dizaines de définitions possibles vous parlez.
Je vois deux types de personnesUn groupe considère qu'un agent est manifestement quelque chose qui agit en votre nom - un agent de voyage - et l'autre considère qu'un agent est un LLM ayant accès à des outils qui peuvent être exécutés en boucle dans le cadre d'un problème. Le terme "autonomie" est également souvent utilisé, mais là encore, il n'y a pas de définition claire. (Il y a quelques mois, j'ai même tweeté une collection de 211 définitions d'agent, et j'ai demandé à gemini-exp-1206 d'essayer de les résumer).
Quel que soit le sens de ce terme.Agent, il y a toujours un sentiment de "bientôt" perpétuel.. Terminologie mise à part.Je reste sceptique quant à leur praticitéIl s'agit d'un défi basé sur la crédulité : les LLM croiront tout ce que vous leur direz. Tout système qui tente de prendre des décisions significatives en votre nom se heurte au même obstacle : quelle est l'utilité d'un agent de voyage, d'un assistant numérique ou même d'un outil de recherche s'il ne peut pas faire la différence entre ce qui est vrai et ce qui est faux ?
Il y a quelques jours, une recherche Google a permis de trouver une description complètement fausse du film Encanto 2, qui n'existe pas.
L'injection en temps utile est une conséquence naturelle de cette crédulité. Je vois très peu de progrès en 2024 dans le traitement de cette question, dont nous discutons depuis septembre 2022
Les attaques par injection rapide sont une conséquence naturelle de cette "crédulité". Je vois peu de progrès dans l'industrie en 2024 pour résoudre ce problème, dont nous discutons depuis septembre 2022.
Je commence à penser que le concept d'agent le plus populaire s'appuiera sur l'AGI.Rendre les modèles résistants à la "crédulité" n'est pas une mince affaire !.
9. évaluation, très important
Amanda Askell de Anthropic (pour Claude's). Caractère (qui est à l'origine de la plupart des travaux) avait déclaré :
Il y a un secret ennuyeux mais essentiel derrière une bonne invite système, et c'est le développement piloté par les tests. Vous n'écrivez pas une invite système pour ensuite trouver comment la tester. Vous écrivez des tests, puis vous trouvez une invite système qui passe ces tests.
Au cours de l'année 2024, il est devenu tout à fait clair que laÉcrire d'excellentes auto-évaluations pour les systèmes pilotés par LLMLa compétence la plus nécessaire pour créer des applications utiles à partir de ces modèles est l'évaluation. Si vous disposez d'une suite d'évaluation solide, vous pouvez adopter de nouveaux modèles plus rapidement que vos concurrents, procéder à de meilleures itérations et créer des fonctionnalités de produits plus fiables et plus utiles.
Malte Ubl, directeur de la technologie chez Vercel, est d'accord :
Lorsque la v0 (un agent de développement web) a été introduite pour la première fois, nous étions paranoïaques à l'idée de protéger les invites avec toutes sortes de prétraitements et de post-traitements complexes.
Nous nous sommes complètement tournés vers la liberté d'action. L'absence d'évaluation, de modélisation et, surtout, d'invites UX équivaut à une machine ASML cassée sans instructions.
J'essaie toujours de trouver un meilleur modèle pour mon propre travail. Tout le monde sait que les évaluations sont importantes, mais pour leIl n'y a toujours pas de bonnes orientations sur la meilleure façon de réaliser l'évaluation..
10. Apple Intelligence, c'est nul, mais MLX, c'est génial !
En tant qu'utilisateur de Mac, je me sens beaucoup plus à l'aise avec la plate-forme que j'ai choisie.
En 2023, j'ai l'impression de ne pas avoir de machine Linux/Windows avec un GPU NVIDIA, ce qui est un énorme désavantage pour moi pour essayer de nouveaux modèles.
En théorie, un Mac de 64 Go devrait être une bonne machine pour exécuter des modèles, car le CPU et le GPU peuvent partager la même quantité de mémoire. Dans la pratique, de nombreux modèles sont publiés sous forme de poids et de bibliothèques de modèles, la plate-forme CUDA de NVIDIA étant privilégiée par rapport à d'autres plates-formes.
llama.cpp L'écosystème a beaucoup aidé, mais la véritable avancée a été la bibliothèque MLX d'Apple, qui est fantastique.
Le support Python mlx-lm d'Apple fait tourner une variété de modèles compatibles mlx sur mon Mac avec d'excellentes performances. La communauté mlx sur Hugging Face fournit plus de 1000 modèles qui ont été convertis aux formats nécessaires. Le projet mlx-vlm de Prince Canuma est excellent et progresse rapidement, et apporte également des LLM visuels à Apple. Le projet mlx-vlm de Prince Canuma est excellent et progresse rapidement, et a également apporté des LLM visuels à Apple Silicon.
Si MLX a changé la donne, les fonctionnalités de l'Apple Intelligence d'Apple ont été pour la plupart décevantes. J'ai écrit un article sur leur lancement en juin dernier, et à l'époque j'étais optimiste sur le fait qu'Apple s'était concentré sur la protection de la vie privée des utilisateurs et sur la réduction du nombre d'utilisateurs induits en erreur par les applications LLM.
Maintenant que ces fonctions sont disponibles, elles sont encore relativement inefficaces. En tant que grand utilisateur de LLM, je sais de quoi ces modèles sont capables, et les fonctions LLM d'Apple ne sont qu'une pâle imitation des fonctions LLM de pointe. Au lieu de cela, nous obtenons des résumés de notifications qui faussent les titres de l'actualité, et je ne pense même pas que l'outil d'aide à la rédaction soit utile du tout. Malgré tout, Genmoji est assez amusant.
11. la mise à l'échelle de l'inférence, la montée des modèles de "raisonnement
Le développement le plus intéressant du dernier trimestre 2024 a été l'émergence d'une nouvelle morphologie LLM, illustrée par les modèles o1 d'OpenAI - o1-preview et o1-mini ont été publiés le 12 septembre. Ces modèles peuvent être considérés comme une extension de la technique de la chaîne de pensée.
L'astuce consiste principalement àSi vous amenez un modèle à réfléchir sérieusement (à voix haute) au problème qu'il est en train de résoudre, vous obtiendrez généralement un résultat que le modèle n'aurait pas été en mesure d'obtenir autrement.
o1 intègre ce processus dans le modèle. Les détails sont un peu flous : le modèle o1 dépense des "jetons de raisonnement" pour réfléchir au problème, que l'utilisateur ne peut pas voir directement (bien que l'interface utilisateur de ChatGPT affiche un résumé), et produit ensuite le résultat final.
La plus grande innovation est qu'elle ouvre une nouvelle voie d'extension du modèle : les modèles peuvent désormais résoudre des problèmes plus difficiles en consacrant davantage d'efforts de calcul à l'inférence, à l'analyse des données et à l'analyse des résultats.Au lieu d'améliorer les performances du modèle uniquement en augmentant la quantité de calculs au moment de la formation.
Le successeur d'o1, o3, a été publié le 20 décembre et a obtenu des résultats impressionnants dans les tests de référence ARC-AGI, malgré le fait que le coût du temps de calcul ait pu atteindre plus d'un million de dollars !
o3 devrait sortir en janvier. Je doute qu'il y ait beaucoup de personnes ayant des problèmes réels qui bénéficieraient d'un tel niveau de dépenses informatiques, en tout cas moi je n'en ai pas ! Mais il semble qu'il s'agisse d'une nouvelle étape dans l'architecture LLM pour résoudre des problèmes plus difficiles.
OpenAI n'est pas le seul acteur dans ce domaine. Le 19 décembre, Google a publié son premier produit dans ce domaine : gemini-2.0-flash-thinking-exp.
L'équipe Qwen d'Alibaba a publié le modèle QwQ le 28 novembre sous la licence Apache 2.0. Elle a ensuite publié un modèle d'inférence visuelle appelé QvQ le 24 décembre.
DeepSeek Le modèle DeepSeek-R1-Lite-Preview a été mis à disposition pour essai via l'interface de chat le 20 novembre.
Note de l'éditeur : Wisdom Spectrum a également été publié le dernier jour de l'année 2024.Modèles de raisonnement profond GLM-Zéro.
Anthropic et Meta n'ont pas encore progressé, mais je serais très surpris qu'ils n'aient pas leur propre modèle d'extension d'inférence.
12. le meilleur LLM est-il actuellement formé en Chine ??
Pas exactement, mais presque ! Il s'agit d'un excellent titre qui attire l'attention.
DeepSeek v3 est un modèle paramétrique massif de 685B - l'un des plus grands modèles sous licence publique disponible, et beaucoup plus grand que le plus grand modèle de la famille Llama de Meta, Llama 3.1 405B.
Les benchmarks montrent qu'il est au même niveau que le Claude 3.5 Sonnet, et les benchmarks Vibe le classent actuellement en 7ème position, derrière les modèles Gemini 2.0 et OpenAI 4o/o1. Il s'agit du modèle sous licence publique le mieux classé à ce jour.
Ce qui est vraiment impressionnant, c'est queDeepSeek v3Coûts de formationLe modèle a été entraîné sur 2788000 heures de GPU H800 pour un coût estimé à $5576000. Le modèle a été entraîné en 2788000 heures de GPU H800 pour un coût estimé à 5576000 $.Llama 3.1 405B a été entraîné en 30840000 heures de GPU, soit 11 fois plus que DeepSeek v3, mais les performances de base du modèle étaient un peu moins bonnes.
La réglementation américaine sur les exportations de GPU chinoises semble avoir inspiré des optimisations de formation très efficaces.
13) Amélioration de l'impact environnemental des messages d'aide à l'exploitation.
Qu'il s'agisse d'un modèle hébergé ou d'un modèle que je gère localement, l'un des résultats positifs de l'amélioration de l'efficacité est que la consommation d'énergie et l'impact sur l'environnement de l'exploitation d'un prompt ont été considérablement réduits au cours des dernières années.
Les frais d'intervention d'OpenAI sont 100 fois inférieurs à ceux de GPT-3 à l'époque.Je sais de source sûre que ni Google Gemini ni Amazon Nova (les deux fournisseurs de modèles les moins chers) ne fonctionnent rapidement à perte.
Cela signifie qu'en tant qu'utilisateurs individuels, nous n'avons pas à nous sentir coupables de l'énergie consommée par la grande majorité des messages-guides. Comparé au fait de conduire dans la rue, ou même de regarder une vidéo sur YouTube, l'impact peut être négligeable.
Il en va de même pour la formation. La formation de deepSeek v3 coûte moins de 6 millions de dollars, ce qui est un très bon signe que les coûts de formation peuvent et doivent continuer à baisser.
14. les nouveaux centres de données sont-ils encore nécessaires ?
Plus important encore, il y aura une forte pression concurrentielle pour construire l'infrastructure dont ces modèles auront besoin à l'avenir.
Des entreprises telles que Google, Meta, Microsoft et Amazon dépensent des milliards de dollars pour construire de nouveaux centres de données, ce qui a un impact considérable sur le réseau électrique et l'environnement. Il est même question de construire de nouvelles centrales nucléaires, mais cela prendra des décennies.
Cette infrastructure est-elle nécessaire ? Les 6 millions de dollars que coûte la formation à DeepSeek v3 et la réduction continue des prix du LLM peuvent suffire à le démontrer. Mais aimeriez-vous être le dirigeant d'une grande entreprise technologique qui s'est opposé à cette infrastructure et qui s'est avéré avoir tort quelques années plus tard ?
Le développement des chemins de fer dans le monde au 19e siècle offre un contraste intéressant. La construction de ces chemins de fer a nécessité d'énormes investissements, a eu un impact considérable sur l'environnement et de nombreuses lignes construites se sont révélées inutiles.
Les bulles qui en ont résulté ont conduit à plusieurs effondrements financiers et nous ont laissé un grand nombre d'infrastructures utiles, ainsi qu'un grand nombre de faillites et de destructions environnementales.
15.2024, l'année du "slop"
2024 est l'année où le mot "slop" devient un terme d'art. a écrit @deepfates sur twitter :
Tout comme "spam" est devenu le nom propre du courrier électronique indésirable, "slop" apparaîtra dans le dictionnaire comme le nom propre du contenu indésirable généré par l'IA.
J'ai écrit un billet en mai dernier qui développe un peu plus cette définition :
Le terme "Slop" désigne le contenu non sollicité et non censuré généré par l'intelligence artificielle.
J'aime bien le mot "slop" parce qu'il résume succinctement l'une des façons dont nous ne devrions pas utiliser l'IA générative !
16. données d'entraînement synthétiques, très efficaces
Il est surprenant de constater que la notion d'"effondrement du modèle" - c'est-à-dire le fait que les modèles d'IA s'effondrent lorsqu'ils sont formés sur des données générées de manière récursive - semble être profondément ancrée dans la conscience du public. .
L'idée est séduisante : à mesure que les "déchets" générés par l'IA inondent l'Internet, les modèles eux-mêmes se dégradent, se nourrissant de leur propre production et conduisant à leur inévitable disparition !
Il est évident que cela ne s'est pas produit. Au contraire, les laboratoires d'IA s'entraînent de plus en plus sur des contenus synthétiques, en créant des données artificielles qui aident à orienter leurs modèles dans la bonne direction.
L'une des meilleures descriptions que j'ai vues provient du rapport technique Phi-4Voici quelques-uns des éléments du programme :
Les données synthétiques deviennent de plus en plus courantes et constituent un élément important du préapprentissage, et la famille de modèles Phi a toujours mis l'accent sur l'importance des données synthétiques. Au lieu d'être une alternative bon marché aux données réelles, les données synthétiques présentent plusieurs avantages directs par rapport aux données réelles.
Apprentissage progressif structuré. Dans les ensembles de données réels, les relations entre les jetons sont souvent complexes et indirectes. De nombreuses étapes d'inférence peuvent être nécessaires pour associer le jeton actuel au jeton suivant, ce qui rend difficile l'apprentissage efficace du modèle à partir de la prédiction du jeton suivant. En revanche, chaque mot généré par un modèle de langage est prédit par le mot précédent, ce qui permet au modèle de suivre plus facilement le modèle d'inférence qui en résulte.
Une autre technique courante consiste à utiliser des modèles plus importants pour créer des données d'entraînement pour des modèles plus petits et moins coûteux, et de plus en plus de laboratoires utilisent cette technique.
DeepSeek v3 utilise Profondeur de l'eau-R1 Le réglage fin du Llama 3.3 70B de Meta utilise plus de 25 millions d'exemples générés synthétiquement.
Une conception minutieuse des données d'entraînement utilisées pour le LLM semble être la clé de la création de ces modèles. Il est loin le temps où l'on récupérait toutes les données du web et où l'on les introduisait sans discernement dans les cycles d'entraînement.
17. il n'est pas facile d'utiliser correctement le LLM !
J'ai toujours insisté sur le fait que les LLM sont des outils puissants pour les utilisateurs - ce sont des tronçonneuses déguisées en hachoirs. Ils semblent faciles à utiliser - comment est-il difficile d'entrer des informations dans un chatbot ? Mais en réalité.Pour en tirer le meilleur parti et éviter leurs nombreux pièges, vous devez les comprendre en profondeur et avoir beaucoup d'expérience à leur sujet.
Ce problème s'aggrave encore en 2024.
Nous avons construit des systèmes informatiques auxquels on peut s'adresser en langage humain, qui peuvent répondre à vos questions, et qui ont généralement raison ! ...... Cela dépend de la nature de la question, de la manière dont elle est posée et de la possibilité de la refléter avec précision dans un ensemble d'apprentissage secret non enregistré.
Aujourd'hui, le nombre de systèmes disponibles prolifère. Les différents systèmes disposent de différents outils qui peuvent être utilisés pour résoudre votre problème, tels que Python, JavaScript, la recherche sur le web, la génération d'images et même les requêtes de base de données ....... Il est donc préférable de comprendre ce que sont ces outils, ce qu'ils peuvent faire et comment savoir si le LLM les utilise.
Saviez-vous que ChatGPT a maintenant deux façons complètement différentes d'exécuter Python ?
Si vous voulez construire un artefact Claude qui communique avec une API externe, c'est une bonne idée d'apprendre à connaître les en-têtes HTTP CSP et CORS.
Les capacités de ces modèles peuvent s'être améliorées, mais la plupart des limitations demeurent. o1 d'OpenAI peut enfin être capable (en grande partie) de calculer le "r" dans fraise, mais ses capacités sont toujours limitées par sa nature de LLM et par ses harnais d'exécution. o1 ne peut pas faire de recherches sur le web ou utiliser un interpréteur de code, mais GPT-4o le peut - les deux se trouvent dans la même interface ChatGPT UI. GPT-4o peut le faire - les deux sont dans la même interface ChatGPT.
Qu'avons-nous fait à ce sujet ? Rien. La plupart des utilisateurs sont des "débutants". L'interface de chat par défaut de LLM revient à lancer de nouveaux utilisateurs d'ordinateurs dans un terminal Linux et à s'attendre à ce qu'ils soient capables de tout faire eux-mêmes.
Dans le même temps, il est de plus en plus fréquent que les utilisateurs finaux développent des modèles mentaux inexacts sur le fonctionnement de ces appareils. J'ai vu de nombreux exemples de cela, avec des personnes qui tentent de gagner des arguments avec des captures d'écran de ChatGPT - ce qui est une proposition intrinsèquement ridicule, étant donné le manque de fiabilité inhérent à ces modèles, couplé au fait que vous pouvez leur faire dire n'importe quoi si vous leur donnez le bon message.
Il y a un revers à la médaille : de nombreux "anciens" ont complètement abandonné le LLM parce qu'ils ne voient pas comment quelqu'un pourrait tirer profit d'un outil qui a tant de défauts. La clé pour tirer le meilleur parti du LLM est d'apprendre à utiliser cette technique peu fiable mais puissante. Ce n'est manifestement pas une compétence évidente !
Alors qu'il existe tant de contenus éducatifs utiles, nous devons faire mieux que de les confier à des spécialistes de l'IA qui tweetent et fulminent à leur sujet.
18. mauvaise cognition, toujours présente
Aujourd'hui.La plupart des gens ont entendu parler de ChatGPT, mais combien ont entendu parler de Claude ?
Entre ceux qui se préoccupent activement de ces questions et ceux qui ne s'en préoccupent pas, il y a un fossé entre les deux.La grande fracture de la connaissance.
Le mois dernier, nous avons constaté la popularité des interfaces en temps réel qui permettent de pointer la caméra de son téléphone sur un objet et d'en parler avec sa voix. ...... Il est également possible de faire semblant d'être le Père Noël. La plupart des personnes qui se certifient elles-mêmes (sic "nerd") ne l'ont pas encore essayé.
Compte tenu de l'impact continu (et potentiel) de cette technologie sur la société, je pense que l'actuelleCe fossé est malsain. Je souhaiterais que davantage d'efforts soient déployés pour améliorer la situation.
19.LLM, une meilleure critique est nécessaire
Beaucoup de gens détestent vraiment le LLM. Sur certains des sites que je fréquente, le simple fait de suggérer que "le LLM est très utile" suffit à déclencher une guerre.
Je comprends. Il y a de nombreuses raisons pour lesquelles les gens n'aiment pas cette technologie - impact environnemental, manque de fiabilité des données de formation, applications non positives, impact potentiel sur l'emploi.
LLM mérite certainement des critiques.Nous devons discuter de ces questions, trouver des moyens de les atténuer et aider les gens à apprendre à utiliser ces outils de manière responsable afin que leurs applications positives l'emportent sur leurs effets négatifs.
J'aime les gens qui sont sceptiques à l'égard de cette technologie. Depuis plus de deux ans, le battage médiatique a pris de l'ampleur et de nombreuses informations erronées ont été diffusées sur les ondes. Beaucoup de mauvaises décisions ont été prises sur la base de ce battage médiatique.La critique est une vertu.
Si nous voulons que les personnes ayant un pouvoir de décision prennent les bonnes décisions sur la manière d'appliquer ces outils, nous devons d'abord reconnaître qu'il existe effectivement de bonnes applications, puis aider à expliquer comment les mettre en pratique, tout en évitant de nombreux écueils non pratiques.
C'est ce que je pense.Dire aux gens que l'ensemble du secteur est une machine à plagier désastreuse pour l'environnement qui invente constamment des choses, quelle que soit la part de vérité que cela représente, est un mauvais service rendu à ces personnes.. Il y a là une valeur réelle, mais la réalisation de cette valeur n'est pas intuitive et nécessite des conseils.
Ceux d'entre nous qui comprennent ces choses ont la responsabilité d'aider les autres à les comprendre.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes




Pas de commentaires...