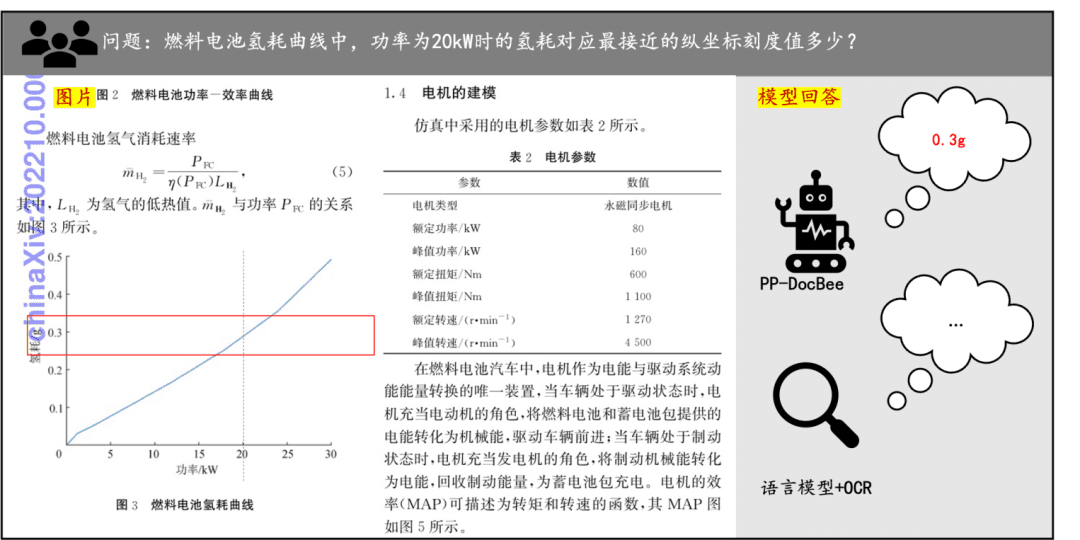
Tendances des données d'entreprise et de l'IA 2025 : Intelligentsia, plateformes et perspectives d'avenir.

Il est notoirement difficile de faire des prédictions, en particulier dans un domaine qui évolue rapidement comme celui des données et de l'IA. Néanmoins, nous.Rajesh Parikh répondre en chantant Sanjeev MohanL'année dernière, nous avons publié notre Projections de tendances pour 2024. Alors que 2024 touche à sa fin, nous sommes heureux de confirmer que nos prédictions étaient justes. Ce succès est d'autant plus remarquable que l'IA évolue à un rythme sans précédent, ce qui est rare dans le domaine des technologies de l'information.
Dans nos quatre premières prédictions, nous avons souligné la montée en puissance des plateformes de données intelligentes et des intelligences de l'IA. Bien que ces tendances soient moins évidentes en 2023, l'élan derrière les intelligences de l'IA est maintenant indéniable, annonçant une nouvelle accélération. la généralisation de l'IA et des intelligences de l'IA se poursuit.
En ce qui concerne les plateformes de données, nous observons une forte évolution vers des plateformes intelligentes et unifiées, motivée par la nécessité de simplifier l'expérience utilisateur et d'accélérer le développement de produits de données et d'IA. Cette tendance devrait s'intensifier à mesure que de nouveaux fournisseurs entrent sur le marché et élargissent la gamme d'options disponibles pour les entreprises.
Attentes pour 2025
À l'approche de 2025, le paysage des données d'entreprise et de l'IA connaîtra une transformation majeure, remodelant les industries et redéfinissant la manière dont les humains interagissent avec la technologie. Plutôt que de parler de prédiction, nous souhaitons utiliser ce document pour explorer ces tendances transformatrices qui, selon nous, requièrent une attention particulière de la part des dirigeants d'entreprise et des responsables technologiques. Les lecteurs devraient donc l'utiliser comme un guide pour fixer des priorités et préparer leurs organisations à choisir la bonne direction.
Sans plus attendre, plongeons dans les tendances qui, selon nous, sont susceptibles de dominer le paysage des données d'entreprise et de l'IA. La figure 1 illustre les tendances classées en IA appliquée, données et opérations, et programme lunaire.

Figure 1 : Le paysage des données et de l'IA de 2025 se caractérise par la montée des intelligences, l'évolution des plateformes de données et la poursuite de plans ambitieux pour atterrir sur la lune, qui ont le potentiel de transformer le monde qui nous entoure.
- IA appliquéeCes tendances auront un impact significatif sur la manière dont les organisations exploitent les modèles d'IA pour se transformer, en particulier en ce qui concerne la manière dont les intelligences automatisent les tâches et les fonctions quotidiennes. À mesure que les modèles continuent de progresser dans leurs capacités de raisonnement, ces intelligences évolueront pour gérer des tâches de plus en plus complexes et collaborer de manière transparente.
- Tendances en matière de données et de plateformes :Les plans de données et de métadonnées convergents qui prennent en charge les données structurées et non structurées seront le moteur de l'IA et serviront de base aux applications de l'intelligentsia et de l'IA. Un certain nombre de tendances clés convergent pour soutenir cette vision, notamment les progrès dans la gestion des plateformes de données et le développement d'intergiciels robustes pour les applications de l'organisme intelligent.
- Programme d'alunissage :Ces tentatives ambitieuses et à haut risque repoussent les limites de la technologie actuelle et explorent des domaines qui peuvent sembler avant-gardistes aujourd'hui. Bien que le risque d'échec soit élevé, les percées dans ces domaines ont le potentiel de révolutionner l'industrie et de redéfinir l'interaction entre l'homme et l'ordinateur.
IA appliquée
2025IA appliquée Les tendances sont centrées sur les applications pratiques et l'adoption générale des intelligences. Comme le montre la figure 2, nous avons identifié quatre sous-thèmes clés qui devraient avoir l'impact le plus important dans cette catégorie.

Figure 2 : Comme pour l'apprentissage automatique, la démocratisation de l'IA se fera par le biais d'un écosystème florissant d'intelligences capables de relever une variété de tâches et de défis spécifiques à un domaine.
Ensuite, examinons les tendances pour chaque application de l'IA/IA.
Les corps intelligents sont partout
En 2025, nous entrerons dans l'ère de l'IA du corps intelligent.
Voici des extraits des tendances de l'année dernière sur les intelligences de l'IA et nos conseils aux entreprises.
Nous considérons les intelligences informées par l'IA comme une tendance qui pourrait prendre des années à se concrétiser ; cependant, compte tenu de sa promesse, nous prévoyons que 2024 sera une année de progrès significatifs dans l'infrastructure/l'outillage des intelligences, ainsi que d'adoption précoce. Il convient de noter qu'une grande partie de notre compréhension du potentiel des architectures d'IA actuelles à prendre en charge des tâches plus complexes est encore largement potentielle, et qu'il existe de nombreuses questions non résolues.
Cela dit, les organisations doivent adopter une approche pragmatique de la création d'applications corporelles intelligentes et, dans une certaine mesure, s'attendre à ce que l'écart entre les technologies d'IA actuelles et la prise en charge d'une automatisation de plus en plus complexe se réduise d'année en année. Elles doivent également examiner dans quelle mesure l'automatisation peut être réalisée au cas par cas au cours des 12 prochains mois. Le parcours évolutif de ces projets pourrait s'avérer plus fructueux.
En 2025, l'adoption des intelligences autonomes dans les entreprises devrait s'accélérer en raison du besoin croissant d'automatiser les tâches répétitives et d'améliorer l'expérience client. Ces intelligences augmenteront les capacités humaines et nous permettront de nous concentrer sur des tâches créatives, stratégiques et complexes.
Elles étendent l'automatisation aux tâches qui requièrent un niveau élevé de réflexion, de raisonnement et de résolution de problèmes - des tâches qui nécessitent actuellement une participation humaine importante. Par exemple, les intelligences peuvent mener des études de marché, analyser des données ou répondre à des demandes d'assistance à la clientèle. Elles peuvent également automatiser des flux de travail complexes, à plusieurs étapes, qui étaient auparavant considérés comme irréalisables en raison de leur complexité, de leur coût, ou des deux.
Une intelligence artificielle est un programme ou un système qui perçoit son environnement, raisonne, décompose une tâche donnée en une série d'étapes, prend des décisions et agit pour accomplir ces tâches de manière autonome, tout comme un travailleur humain.
Nous assistons actuellement à l'émergence d'outils pilotés par l'IA, tels que les co-pilotes de développeurs qui peuvent être utilisés pour environ 20 dollars par mois, et d'outils tels que le Devin Les intelligences de niveau 2 sont celles qui peuvent effectuer certaines tâches de manière autonome, mais qui nécessitent encore une supervision et une intervention humaines significatives.
Cependant, en 2025, nous nous attendons à voir des intelligences plus avancées avec des prix plus élevés pour refléter la valeur qu'elles apportent. Par exemple, un corps intelligent spécialisé capable de surpasser un spécialiste du marketing débutant dans l'élaboration de la stratégie de marketing entrant et sortant d'un département pourrait coûter jusqu'à 20 000 dollars.
système multi-intelligence
Systèmes de multi-intelligence (MASCette spécialisation au sein de la MAS permet à chaque intelligence de se concentrer sur son domaine d'expertise, augmentant ainsi l'efficacité globale du système puisque les intelligences apportent leurs compétences et connaissances uniques pour résoudre des problèmes complexes. Ces intelligences interagissent les unes avec les autres, souvent en utilisant différents modes et canaux de communication, pour atteindre leurs objectifs individuels ou les objectifs globaux du système.
La figure 3 illustre la manière dont les intelligences multiples peuvent collaborer pour améliorer la production de contenu au sein d'une organisation.

Figure 3 : Un système multi-intelligence composé de trois intelligences qui se concentrent sur les tâches de recherche, de création et de distribution de contenu, et qui travaillent en collaboration pour répondre aux besoins du département marketing.
Les MAS peuvent présenter différents niveaux de contrôle et différents modèles architecturaux pour la communication et la coordination par le biais de modèles architecturaux communs :
- Équipes multicouches :Ce type de SMA fait généralement appel à un gestionnaire central ou à un délégateur de tâches pour assurer la médiation de la communication. Les intelligences des travailleurs au sein du système ne communiquent que par l'intermédiaire de cette intelligence centrale, ce qui empêche toute communication directe entre les intelligences.
- Parité :Dans les SMA d'égal à égal, les intelligences communiquent directement entre elles sans dépendre d'un organisme centralisé.
- Collaboration de groupe :Ce type de MAS est similaire aux chats de groupe (par exemple, Slack, Microsoft Teams) dans lesquels les intelligences s'abonnent à des canaux pertinents et sont coordonnées par le biais d'une architecture de publication et d'abonnement.
Contrairement aux systèmes à corps intelligent unique, dans lesquels un seul corps intelligent joue plusieurs rôles, les MAS permettent une spécialisation efficace, qui améliore les performances d'un large éventail d'applications. Les MAS sont essentiels pour la mise à l'échelle de l'automatisation des corps intelligents complexes ; le fait de charger trop de tâches dans un seul corps intelligent introduit des problèmes de complexité et d'évolutivité/fiabilité.
Nous prévoyons que les entreprises auront tendance à développer des intelligences plus spécialisées. Ces intelligences doivent fonctionner en équipe, collaborer et se coordonner pour permettre des flux de travail plus importants et plus complexes. Par conséquent, le MAS jouera un rôle clé dans le succès global des initiatives d'automatisation des flux de travail basées sur l'intelligence.
Système de gestion intelligente du corps humain (IBMS)
Un système de gestion de l'intelligence (AMS) facilite le développement, l'évaluation, le déploiement et le suivi post-déploiement des intelligences IA. En simplifiant la création et le perfectionnement de ces intelligences, l'AMS permet une itération plus rapide et simplifie la gestion du cycle de vie. Il garantit également que les intelligences répondent aux attentes grâce à des tests complets avant le déploiement et à une surveillance continue de la production.
La figure 4 montre les composants d'un AMS représentatif.

Figure 4 : Composants d'un système intelligent représentatif de gestion de la carrosserie (AMS)
Un AMS représentatif contient les éléments suivants :
- Un culturiste intelligent :Les constructeurs de corps intelligents, souvent appelés cadres de corps intelligents, aident à créer rapidement de nouveaux corps intelligents et à améliorer de manière itérative les corps existants.
- Registre du corps intelligent :Le registre Intelligentsia tient à jour un catalogue des Intelligentsia disponibles et facilite le contrôle d'accès et la gouvernance, ce qui englobe le versionnage afin de garantir un accès approprié au public cible.
- Terrain de jeu du corps intelligent :L'aire de jeu du corps intelligent pour actionné manuellement Le test des performances des intelligences dans une variété de tâches et de requêtes d'utilisateurs fournit une interface conviviale prête à l'emploi. Cet environnement permet une évaluation rapide des performances des intelligences.
- Expériences sur le corps intelligent :Support expérimental Smart Body l'automatisation Effectuer une évaluation des intelligences avant le déploiement. Cette approche structurée permet d'évaluer les performances des intelligences en définissant l'ensemble de données, en sélectionnant les mesures appropriées, en configurant l'environnement, en analysant les résultats et en produisant un rapport d'évaluation. Les journaux des expériences précédentes sont souvent disponibles.
- Déploiement et surveillance :Le déploiement d'un corps intelligent consiste à configurer les ressources nécessaires pour le corps intelligent dans un environnement d'essai ou de production, tout en surveillant les paramètres d'exécution pertinents. Cela permet de garantir la fiabilité et l'efficacité des corps intelligents.
- Chat UI :L'interface utilisateur de chat fournit l'interface utilisateur nécessaire pour interagir avec les intelligences déployées dans un environnement de production.
L'AMS jouera un rôle clé en aidant les organisations à créer, déployer et gérer ces intelligences tout au long de leur cycle de vie, pour aboutir à l'entreprise dotée d'un corps intelligent.
modèle spécifique à une tâche
(aller de l'avant et le faire) sans hésiter Anthropique Claude, la famille GPT de l'OpenAI, l'équipe de Google, le groupe de travail sur la sécurité des données, le groupe de travail sur la sécurité des données. Gémeaux et les modèles de pointe tels que Nova d'AWS domineront en 2024, mais il existe des tendances notables dans le développement de modèles spécifiques à des tâches et à des domaines qui sont particulièrement pertinents pour les cas d'utilisation des entreprises.
La figure 5 illustre les étapes de ce processus de création de modèle. Ce processus est communément appelé l'alignement post-formation.

Figure 5 : Techniques utilisées pour créer le modèle de domaine
1. la mise au point supervisée
Le réglage fin supervisé (SFT) implique la formation d'un modèle de base (généralement un modèle de base pré-entraîné ou une variante réglée par commande) à l'aide d'un ensemble de données de préférence. Dans le chaîne de pensée (CoT), chaque enregistrement de cet ensemble de données contient généralement un triple (invite, CoT, résultat) où le CoT fait explicitement référence à la spécification de sécurité concernée.
Le processus d'affinage contextuel crée un ensemble de données, en commençant par un modèle formé uniquement pour l'utilité et en l'incitant avec une spécification de sécurité et des conseils pertinents. Le résultat de ce processus est Modèle SFT.
2. l'amélioration du réglage fin de l'apprentissage
La deuxième phase fait appel à l'apprentissage par renforcement (RL) à haut niveau de calcul. Cette phase utilise l'apprentissage par renforcement du jugement pour récompenser les signaux basés sur l'adhésion du modèle aux spécifications de sécurité, améliorant ainsi la capacité du modèle à raisonner en toute sécurité. L'ensemble du processus nécessite une intervention humaine minimale au-delà de la création des spécifications initiales et de l'évaluation de haut niveau.
Le raisonnement CoT permet au LLM d'exprimer explicitement son processus de raisonnement, ce qui rend ses décisions plus transparentes et interprétables. Dans l'alignement de la phase RL, le CoT inclut des références aux spécifications de sécurité qui illustrent la manière dont le modèle est parvenu à sa réponse. Cela permet au modèle d'examiner attentivement les questions liées à la sécurité avant de générer une réponse. L'inclusion du CoT dans les données d'apprentissage permet au modèle d'apprendre à utiliser cette forme de raisonnement pour obtenir une réponse plus sûre, améliorant ainsi la sécurité et l'interprétabilité. Le résultat de cette phase est souvent appelé "Modèles de raisonnement
3. un réglage fin continu
L'affinage continu permet aux ingénieurs en IA et aux scientifiques des données d'adapter les modèles à des cas d'utilisation spécifiques. Les ingénieurs en apprentissage profond et les scientifiques des données peuvent désormais affiner les modèles de pointe et les modèles open-source en utilisant de 10 à 1 000 exemples, ce qui améliore considérablement la qualité des modèles pour des applications ciblées. Ceci est essentiel pour les organisations qui cherchent à améliorer la fiabilité de leurs modèles spécifiques à des cas d'utilisation sans avoir à investir dans une infrastructure post-entraînement étendue.
La plupart des modèles de pointe offrent désormais des API de réglage fin continu pour le réglage des préférences et le réglage fin de l'apprentissage par renforcement (RLFT), ce qui abaisse le seuil de création de modèles spécifiques à une tâche ou à un domaine.
Le résultat de cette étape peut être appelé "Modélisation spécifique à une tâche ou à un domaine".
Les cadres de réglage fin open source (par exemple Hugging Face Transformers Reinforcement Learning (TRL), Unsloth, etc.) offrent des capacités de réglage continu similaires pour les modèles OSS. Par exemple, les premiers utilisateurs du modèle Llama l'ont affiné plus de 85 000 fois depuis sa sortie.
Alors que nous continuons à déployer l'adoption de l'IA dans les entreprises, nous observons deux tendances distinctes :
- Les organisations disposant d'importantes ressources en capital (que nous appelons "Frontières") peuvent adopter une stratégie de modèles open source post-formation, en les adaptant largement à des domaines et des cas d'utilisation spécifiques grâce à une mise au point continue.
- Pour ceux qui disposent d'un budget limité mais qui accordent une grande importance à la fiabilité des cas d'utilisationEntreprises en devenirUne stratégie rentable consiste à choisir des LLM prêts à l'emploi et à donner la priorité à l'alignement spécifique à la tâche par le biais d'une mise au point continue.
Tendances en matière de données, d'exploitation et de maintenance
Les données sont essentielles à la réussite de la mise en œuvre de l'IA et requièrent des pratiques exemplaires en matière de gestion des données. La figure 6 illustre les principales tendances en matière de données et de F&E pour 2025.

Figure 6 : Données clés et tendances en matière d'exploitation et de maintenance
Examinons chaque tendance.
Plate-forme de données intelligente
Pour accélérer l'innovation en matière de données et d'IA et réduire les frais généraux opérationnels, nous proposons une plateforme intelligente de données et d'IA unifiée (IDP) en 2024. Cet effort d'unification et de simplification a gagné une traction significative parmi les principaux fournisseurs de logiciels, ce qui a donné lieu à l'architecture présentée à la figure 7.

Figure 7 : Architecture de la plate-forme de données intelligentes
L'IDP rationalise l'intégration du cycle de vie des données (stockage, traitement, analyse et apprentissage automatique), réduisant ainsi le besoin d'outils et de main-d'œuvre fragmentés. Il fournit également un cadre centralisé pour la stratégie et l'exécution de la gouvernance des données.
Alors que les principales offres des entreprises technologiques établies et des startups continuent d'améliorer les fonctionnalités en 2024, l'adoption généralisée des données et des plateformes d'intelligence artificielle pour les intelligences artificielles est encore un travail en cours.
En 2025, les fournisseurs de plateformes de données continueront à intégrer leurs services pour créer une base critique pour les intelligences IA et les systèmes multi-intelligences, en fournissant à ces applications les informations dont elles ont besoin pour fonctionner et prendre des décisions. Ces plateformes extraient trois fonctions clés :
- Harmonisation des plans de données :Le plan de données unifié prend en charge le chargement, le stockage, la gestion et la gouvernance d'une variété de formats de données, y compris le texte (par exemple, PDF), les images (par exemple, PNG, JPEG) et l'audio/vidéo (par exemple, MP3). L'adoption de formats de tableaux ouverts tels qu'Apache Iceberg, Delta Lake et Apache Hudi constitue une tendance secondaire clé de ce plan de données unifié.
- Plan de métadonnées unifié :Les métadonnées fournissent aux applications d'IA des informations contextuelles de base sur les données qu'elles traitent. Par exemple, si les données contiennent un document sur la politique des ressources humaines, les métadonnées pertinentes peuvent inclure le numéro de version du document, la date de la dernière révision et l'auteur. Sans métadonnées riches fournissant ces nuances, il sera difficile pour les intelligences d'établir un contexte suffisant et de fournir les fonctionnalités prévues.
- Orchestrateur multi-moteurs :IDP fournit également une couche d'orchestration extensible conçue pour gérer et orchestrer divers moteurs de calcul, notamment ceux utilisés pour le traitement analytique, la transformation des données et l'exécution de modèles d'IA.
- Plan de gouvernanceL'IDP joue également le rôle d'intergiciel de contrôle d'accès, de gouvernance et de personnalisation, permettant aux intelligences de mieux comprendre les rôles des utilisateurs (y compris les rôles, l'accès aux données et l'historique des requêtes) et de personnaliser les réponses.
ETL pour l'IA
L'ETL (Extract, Transform and Load) est un processus clé d'intégration des données utilisé pour préparer les données brutes pour l'IA et les modèles d'apprentissage automatique. Ce processus consiste à extraire des données de diverses sources, à les transformer en les nettoyant et en les formatant, puis à les charger dans un système de gestion ou de stockage des données, tel qu'un PDI, un entrepôt de données ou un magasin vectoriel, comme nous l'avons décrit précédemment.
Alors que les organisations sont déjà familiarisées avec l'ETL pour les données structurées (extraction, transformation et chargement des données des bases de données opérationnelles vers des entrepôts ou des lacs de données), l'ETL pour l'IA étend ce processus à un large éventail de formats de données, y compris le texte (.pdf, .md, .docx), l'audio/vidéo (mp3, mpeg) et les images (jpeg, png).
Ces sources de données non structurées peuvent inclure une variété de référentiels de contenu, d'applications et de ressources Web utilisées par l'entreprise. En fait, le processus ETL lui-même peut tirer parti de l'IA pour les tâches d'extraction, telles que l'extraction d'entités (images, tableaux et entités nommées) à partir de PDF à l'aide de modèles multimodaux de grands langages (LLM) ou de modèles de reconnaissance optique de caractères (OCR).
ETL pour les données non structurées Prise en charge de divers cas d'utilisation en aval :
- Des informations basées sur l'IA :Génération améliorée par la recherche (RAG) permet aux applications de faciliter l'interaction des utilisateurs avec les documents, d'extraire des résumés clés et de prendre en charge des cas d'utilisation similaires. L'extraction et la transformation des données à partir de sources aussi diverses que SharePoint, Dropbox, Notion et divers référentiels et applications dans le nuage seront un élément clé de l'élaboration d'informations fondées sur l'IA. Nous prévoyons que les fournisseurs continueront à extraire les RAG et à les intégrer en tant que fonction facilement accessible dans les plateformes unifiées de données, d'analyse et d'IA.
- Recherche d'IALes recherches par mots-clés sont plus accessibles et plus intelligentes que les recherches traditionnelles.
- Automatisation pilotée par l'IALes données non structurées sont utilisées pour fournir la couche de connaissances nécessaire aux intelligences afin de leur fournir des informations contextuelles de base.
- Alignement post-formation et mise au point continueFaciliter la disponibilité de données nouvelles et actualisées afin de permettre une personnalisation continue et transparente des modèles pour une variété de cas d'utilisation au sein des départements.
Préparation des données pour l'IA
La préparation des données est fondamentale pour la mise en œuvre réussie de modèles spécifiques aux tâches et d'intelligences IA.
C'est la clé du succès de ces programmes"condition préalable".
Afin de mettre les données à la disposition de l'IA, elles doivent être préparées de manière exhaustive dans de multiples dimensions. Bien que l'IA puisse consommer la quasi-totalité des données disponibles d'une organisation, la bonne approche consiste à dériver les exigences en matière de préparation des données à partir des cas d'utilisation prioritaires.
La figure 8 illustre certaines des dimensions clés de la préparation des données pour l'IA

Figure 8 : Préparation des données pour l'IA
Qualité des données et observabilité
Ces données satisfont-elles aux indicateurs de qualité établis ? Cela peut signifier une ou plusieurs des choses suivantes :
- confiance
- fraîcheur
- exactitude
- Intégrité des métadonnées
- descentes
- Légalité/déviation
- pertinence
- versionnement
Comment les mesures ci-dessus sont-elles gérées, suivies et présentées en temps réel ?
- Données d'observabilité
- Lignée de données
- l'historique des révisions (d'un document, d'une page web, etc.)
Produits de données pour l'IA
Les produits de données sont essentiels à la réussite des modèles spécifiques aux tâches, à l'évaluation comparative et à l'essai des modèles d'IA et des applications intelligentes. Parmi les produits de données importants en matière d'IA, on peut citer
1. les ensembles de données disponibles pour la formationLes données étiquetées deviennent un produit de données précieux qui peut être utilisé immédiatement pour l'apprentissage de l'IA.
2. l'ensemble de données Chain (CoT) :Contrairement aux ensembles de données traditionnels, qui fournissent généralement des entrées et des sorties pour la formation, les ensembles de données CoT comprennent également des étapes d'inférence intermédiaires qui expliquent comment les réponses ont été obtenues. Cette approche progressive du raisonnement est étroitement liée à la manière dont les humains résolvent des problèmes complexes, ce qui rend les ensembles de données CoT précieux pour l'entraînement des modèles d'IA à l'exécution de tâches qui nécessitent un raisonnement logique, une planification et une capacité d'interprétation.
3. l'ensemble de données affiné :Fournit un sous-ensemble représentatif plus petit de l'ensemble de données qui capture la diversité et la variabilité de l'ensemble de données complet. Voici quelques exemples d'ensembles de données distillées :
a. Un sous-ensemble d'avis de clients présentant différents niveaux de sentiment et différentes catégories de produits.
b. Des ensembles de données de haute qualité spécifiques à une tâche, créés pour entraîner des modèles plus petits (modèles d'étudiants) à imiter les performances de modèles plus grands et plus complexes (modèles d'enseignants).
c. Un sous-ensemble de la documentation technique affiné pour peaufiner le modèle de questions-réponses techniques.
4. les ensembles de données synthétiques :Données affinées utilisées pour générer des ensembles de données synthétiques qui imitent les principaux attributs de l'ensemble de données original. Elles sont souvent utilisées pour augmenter les ensembles de données réels lorsque les données sont rares ou déséquilibrées. En générant des variantes, les modèles peuvent être formés sur des ensembles de données plus diversifiés.
5. les ensembles de données de cartographie des connaissances :Les produits de données alimentés par GraphRAG exploitent les capacités d'extraction et de génération de données basées sur les graphes. Par exemple, les ensembles de données de graphes de connaissances sur les soins de santé reliant la terminologie médicale, le diagnostic, le traitement et les résultats pour les patients peuvent être utilisés pour fournir des conseils médicaux personnalisés, suggérer des options de traitement possibles et aider les médecins à prendre des décisions fondées sur des données.
6. les données de l'utilisateur :Les données de l'utilisateur sont essentielles pour créer des applications d'IA plus intelligentes et personnalisées. Ces données comprennent généralement toutes les informations relatives au rôle de l'utilisateur et aux interactions ou entrées de l'utilisateur que l'intelligence ou l'application d'IA utilise pour comprendre le rôle de l'utilisateur (que l'intelligence peut utiliser pour fournir des sorties ou des réponses significatives). Voici quelques exemples de données utilisateur :
a. Les intelligences des analystes de données qui disposent de rôles d'utilisateurs et d'informations sur l'historique des interactions entre l'ensemble de données, les requêtes et le tableau de bord peuvent personnaliser les réponses aux requêtes en filtrant et en sélectionnant l'historique d'accès à l'ensemble de données et les requêtes appropriées.
b. Les intelligences du support client qui comprennent le statut de client d'un utilisateur (par exemple, Premium ou Normal) et la nature des demandes de support antérieures peuvent utiliser les ordres de travail, les problèmes et les solutions antérieurs pour hiérarchiser les réponses, fournir des solutions plus rapides ou recommander des articles spécifiques de la base de connaissances.
c. En analysant l'historique des communications et les modèles d'engagement avec les prospects et les clients, les intelligences commerciales peuvent personnaliser les stratégies de suivi, recommander des produits ou des services spécifiques et classer les prospects par ordre de priorité en fonction de leur comportement historique.
projet d'aller sur la lune
Les programmes d'alunissage sont des tentatives exploratoires ambitieuses visant à résoudre des problèmes majeurs grâce à des solutions révolutionnaires. Ces projets repoussent généralement les limites de la technologie actuelle et sont à la pointe de l'innovation. Bien qu'ils comportent intrinsèquement un risque élevé d'échec, le potentiel de transformation est énorme.
Bien que cette section soit un espace d'exploration créative, nous aimerions explorer les concepts plus spéculatifs mis en évidence dans la figure 9.

Figure 9 : Programme d'alunissage
agent cognitif
Les intelligences cognitives tirent des leçons de leurs expériences de manière intensive et continue, et s'adaptent et s'améliorent. La figure 10 présente les caractéristiques des intelligences cognitives.

Figure 10 : Cinq caractéristiques clés des intelligences cognitives : l'apprentissage, la mémoire, la conscience de soi, l'amélioration de soi et l'escalade.
Outre les capacités génériques des intelligences IA, les intelligences cognitives possèdent généralement plusieurs autres capacités :
1. la rétention de la mémoire
Une capacité de rétention de la mémoire plus longue est l'une des principales caractéristiques des intelligences cognitives. La capacité de rétention de la mémoire permet aux intelligences de se souvenir de conversations antérieures, souvent d'événements spécifiques, y compris le moment et le lieu où ils se sont produits, et souvent d'en tirer des enseignements.
Ainsi, les intelligences cognitives ont des architectures de mémoire complexes qui comprennent le stockage à long terme pour la rétention et des formes spécifiques de mémoire (par exemple, la mémoire situationnelle), qui permettent aux intelligences de se rappeler et de se remémorer des événements spécifiques dans le temps, y compris le moment et le lieu où ils se sont produits.
Un exemple d'utilisation de la mémoire situationnelle pourrait être le rappel des étapes suivies pour mener à bien une tâche lors d'un événement antérieur. Si le corps intelligent est à nouveau confronté à la même tâche, il peut se rappeler les étapes exactes suivies lors de la précédente réussite et effectuer cette tâche plus efficacement cette fois-ci.
2. tirer les leçons des interactions passées
Ces intelligences tirent des enseignements des interactions passées et les utilisent pour prendre de meilleures décisions à l'avenir.
3. la conscience de soi
Ces intelligences peuvent également être conscientes des détails et des fonctions de leur propre construction.
Ils peuvent potentiellement apprendre des interactions avec les utilisateurs et mettre à jour leur base de connaissances pour y ajouter de nouveaux contenus d'apprentissage.
4. l'auto-guérison
L'autorégénération permet à l'intelligence d'étendre ses fonctionnalités en ajoutant de nouvelles fonctions, telles que des outils permettant de créer des ensembles de données de préférence à partir d'interactions récentes et de déclencher le prochain travail de mise au point. Elle peut également poursuivre l'évaluation de nouveaux modèles et enregistrer de nouvelles révisions de modèles dans le registre des modèles, ainsi que générer des rapports détaillés sur les modèles à l'intention des ingénieurs en intelligence artificielle.
5. l'auto-escalade
(Facultatif) Intelligentsia peut s'auto-modifier vers la nouvelle révision de modèle créée ci-dessus.
l'intelligence incarnée
Les intelligences incarnées sont des types d'intelligence artificielle qui ont une présence physique (par exemple, les robots). Cette "incarnation" est essentielle car elle permet à l'intelligence de percevoir et d'agir sur le monde physique comme le ferait un humain, ce qui lui permet d'apprendre et d'exécuter des tâches qui exigent qu'elle développe une compréhension approfondie de l'espace physique et qu'elle exécute les tâches qui lui sont assignées. L'IA générative devrait révolutionner la robotique en allant au-delà de la programmation traditionnelle basée sur des règles pour fonctionner dans des environnements plus complexes et plus dynamiques.
La figure 11 montre comment les organisations peuvent utiliser ces nouvelles intelligences pour une variété d'applications.

Figure 11 : Exemple d'une entreprise utilisant les intelligences intégrées.
Voyons comment les banques utilisent les intelligences incarnées. Dans leurs agences, les intelligences incarnées d'assistance à la clientèle peuvent initier la première interaction avec un client qui se présente, fournir des conseils financiers personnalisés et aider à traiter les transactions.
Dans le commerce de détail, les intelligences incarnées peuvent prendre la forme d'assistants d'achat en magasin qui fournissent des informations sur les produits et guident les clients dans le magasin. Dans l'industrie manufacturière, ces intelligences peuvent prendre en charge des tâches nécessitant une mobilité et une dextérité dangereuses pour la sécurité humaine.
réseau intelligent
La communication efficace entre plusieurs intelligences artificielles pour atteindre des objectifs communs ou résoudre des problèmes complexes est actuellement entravée par l'absence de formats de messages, de protocoles et de mécanismes de résolution des conflits normalisés. Les futures approches de mise en réseau doivent être évolutives, à faible latence et sécurisées, afin d'instaurer la confiance entre les intelligences et de protéger les réseaux de communication contre les attaques malveillantes.
Cela nous amène à la dernière tendance attendue concernant l'amélioration des réseaux de corps intelligents.
Des réseaux efficaces d'intelligentsia peuvent révolutionner la manière dont les intelligentsia communiquent, collaborent, coordonnent, accomplissent leur travail et apprennent, tant à l'intérieur qu'à l'extérieur de l'entreprise. Cette tendance est similaire aux débuts de l'internet et à la normalisation des protocoles internet, ainsi qu'à l'évolution des communautés et des forums à l'ère du web 2.0. Ces tendances ont considérablement amélioré la collaboration entre les personnes au-delà des frontières physiques.
La figure 12 présente quatre options pour construire un réseau d'intelligences efficace.

Figure 12 : Exemples de normes possibles pour les réseaux de corps intelligents
Les avantages de toutes les tendances du programme d'alunissage sont énormes. Les intelligences cognitives peuvent apprendre grâce à ces interactions en analysant les données échangées, en mettant à jour leurs propres bases de connaissances, en analysant les données échangées, en améliorant la communication de type humain et en accélérant l'innovation dans les limites de l'entreprise.
rendre un verdict
En résumé, la tendance Applied AI est celle qui accélère l'adoption significative des intelligences et des applications de l'IA dans l'entreprise, tandis que les tendances Data et Ops fournissent une base solide pour soutenir et accélérer ces applications intelligentes. En outre, le programme "Moon Landing" couvre des sujets qui peuvent sembler radicaux aujourd'hui, mais qui pourraient avoir le prochain impact transformateur.
Comme d'habitude, l'objectif de cette recherche est de se concentrer sur les solutions technologiques plutôt que sur les impacts organisationnels. Les intelligences autonomes suscitent naturellement des inquiétudes quant aux pertes d'emplois, car les intelligences artificielles sont censées prendre en charge des tâches répétitives. Les organisations doivent redécouvrir la synergie/coordination entre les personnes et les intelligences artificielles en redéfinissant de manière critique les rôles professionnels et en en créant de nouveaux autour de la création, de la gestion et de la collaboration avec l'IA. Cette transformation crée donc une autre tâche importante, car la plupart des organisations devront améliorer et recycler leur main-d'œuvre de manière critique, parallèlement à la transformation de l'IA.
Enfin, toute avancée dans l'architecture du modèle LLM, toute solution permettant d'introduire l'injection de connaissances adaptatives de manière rentable ou toute amélioration significative des capacités de compréhension et de raisonnement peut avoir un impact supplémentaire sur la réalité potentielle des applications de l'IA.
© déclaration de droits d'auteur
Article copyright Cercle de partage de l'IA Tous, prière de ne pas reproduire sans autorisation.
Articles connexes


Pas de commentaires...