
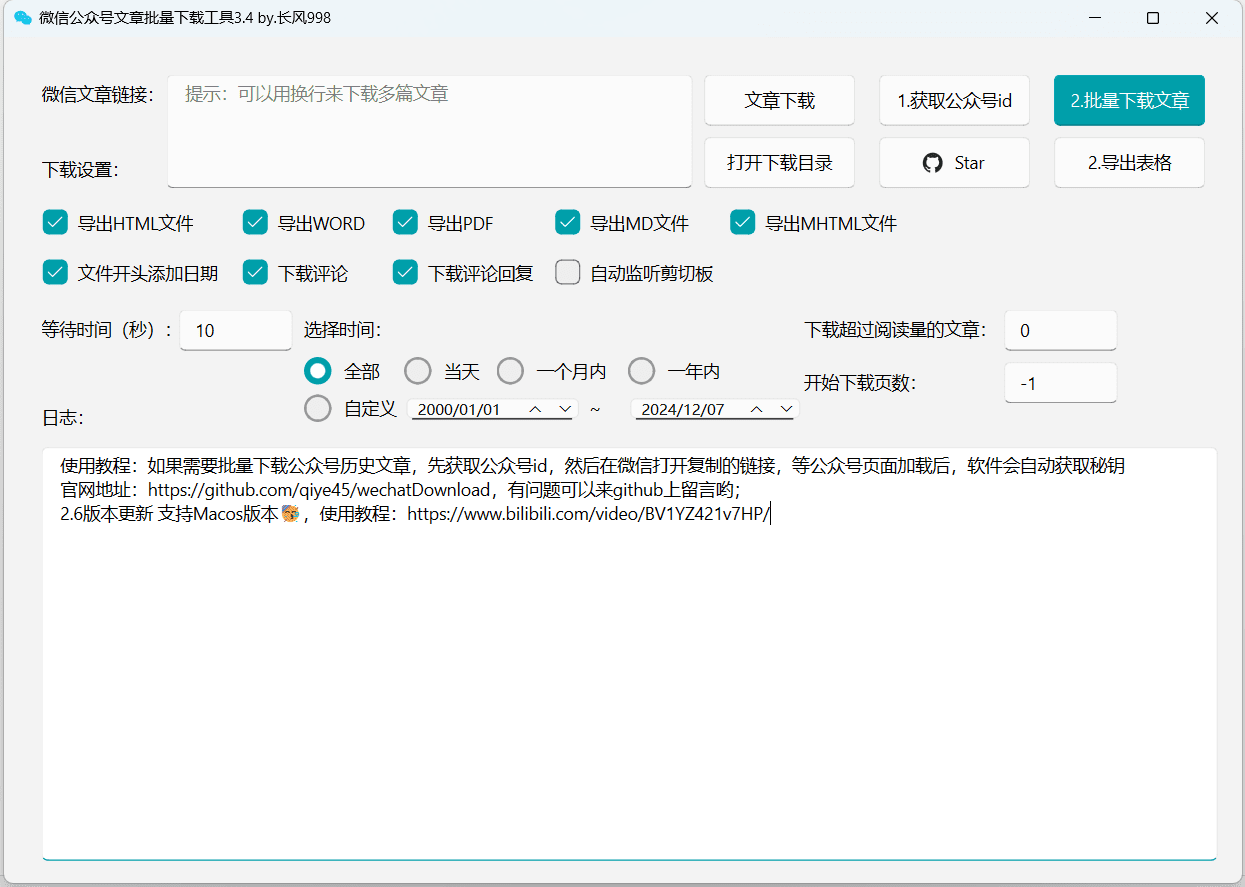
Together: a cloud platform to build and run generative AI model training platforms

General Introduction
Together AI is a platform focused on generative AI models, providing a full range of services from model training and fine-tuning to inference. Users can utilize Together AI's highly efficient inference engine and GPU clusters to rapidly deploy and run various open source models. The platform supports multiple model architectures to meet different AI application requirements.

Large model chat demo interface
Function List
- Inference API: Supports reasoning on more than 100 open-source models and provides both serverless and dedicated instance models.
- fine tuning function: Allow users to fine-tune generative AI models using their own data, maintaining data ownership.
- GPU Cluster: Provides cutting-edge clusters of 16 to 1000+ GPUs to support large-scale model training.
- Custom Model Training: Train cutting-edge models from scratch and support multiple model architectures.
- multimodal model: Supports image recognition, image inference, image generation, etc.
- Efficient inference engine: Integrate the latest inference technologies such as FlashAttention-3 and Flash-Decoding to provide fast and accurate inference services.
Using Help
Installation and use
- Register & Login::
- Visit the Together AI website (https://www.together.ai/) and click the "Start Building" button to register.
- Once registration is complete, log in to your account and go to the User Control Panel.
- Select Service::
- In the control panel, select the service module you need to use, such as the inference API, fine-tuning functions, or GPU clustering.
- Select serverless or dedicated instance mode as required.
- Inference API Usage::
- Select the open source model you need to run, such as Llama-3, RedPajama, etc.
- Integrate the model into your application through the API interface provided by Together AI.
- Build your own RAG application using Together AI's embedded endpoints.
- fine tuning function::
- Upload your dataset and select the models that need to be fine-tuned.
- Configure the fine-tuning parameters to start the fine-tuning process.
- Once the fine-tuning is complete, download the fine-tuned model and deploy it.
- GPU Cluster Usage::
- Select the desired GPU cluster size and configure the hardware parameters.
- Upload training data and model code to start training.
- Once training is complete, the trained model is downloaded for inference or further fine-tuning.
- Custom Model Training::
- Select the Custom Model Training module to configure the model architecture and training parameters.
- Upload the dataset and start the training process.
- Once training is complete, the model is downloaded for deployment and inference.
workflow
- Accessing the Control Panel: After logging in, go to the control panel and select the desired service module.
- Configuration parameters: Configure inference, fine-tuning or training parameters as required.
- Upload data: Upload the required dataset or model code.
- Commencement of mission: Initiate reasoning, fine-tuning or training tasks and monitor task progress in real time.
- Download results: After the task is completed, the model or inference results are downloaded for application integration.
common problems
- How to choose the right model?
- Select the appropriate open source model based on the application scenario, such as text generation, image recognition, etc.
- What should I do if I encounter an error during the fine-tuning process?
- Check the dataset format and parameter configurations and refer to the official documentation for adjustments.
- Poor performance during GPU cluster usage?
- Confirm that the hardware configuration meets the requirements and adjust the training parameters to improve efficiency.
usable model
| Serverless Endpoints | Author | Type | Pricing (per 1M) tokens) | |
|---|---|---|---|---|
| Meta Llama 3.2 11B Vision Instruct Turbo | ||||
| Meta | chat | $0.18 | ||
| Meta Llama 3.2 90B Vision Instruct Turbo | ||||
| Meta | chat | $1.20 | ||
| Qwen2.5 7B Instruct Turbo | ||||
| Qwen | chat | $0.30 | ||
| Qwen2.5 72B Instruct Turbo | ||||
| Qwen | chat | $1.20 | ||
| FLUX.1 [schnell] | ||||
| Black Forest Labs | image | See pricing | ||
| FLUX 1.1 [pro] | ||||
| Black Forest Labs | image | See pricing | ||
| FLUX.1 [pro] | ||||
| Black Forest Labs | image | See pricing | ||
| FLUX.1 [schnell] Free | ||||
| Black Forest Labs | image | See pricing | ||
| Meta Llama 3.2 3B Instruct Turbo | ||||
| Meta | chat | $0.06 | ||
| Meta Llama Vision Free | ||||
| Meta | chat | Free | ||
| Meta Llama Guard 3 11B Vision Turbo | ||||
| Meta | moderation | $0.18 | ||
| Meta Llama 3.1 8B Instruct Turbo | ||||
| Meta | chat | $0.18 | ||
| Mixtral-8x22B Instruct v0.1 | ||||
| mistralai | chat | $1.20 | ||
| Stable Diffusion XL 1.0 | ||||
| Stability AI | image | See pricing | ||
| Meta Llama 3.1 70B Instruct Turbo | ||||
| Meta | chat | $0.88 | ||
| Meta Llama 3.1 405B Instruct Turbo | ||||
| Meta | chat | $3.50 | ||
| Gryphe MythoMax L2 Lite (13B) | ||||
| Gryphe | chat | $0.10 | ||
| Salesforce Llama Rank V1 (8B) | ||||
| salesforce | rerank | $0.10 | ||
| Meta Llama Guard 3 8B | ||||
| Meta | moderation | $0.20 | ||
| Meta Llama 3 70B Instruct Turbo | ||||
| Meta | chat | $0.88 | ||
| Meta Llama 3 70B Instruct Lite | ||||
| Meta | chat | $0.54 | ||
| Meta Llama 3 8B Instruct Lite | ||||
| Meta | chat | $0.10 | ||
| Meta Llama 3 8B Instruct Turbo | ||||
| Meta | chat | $0.18 | ||
| Meta Llama 3 70B Instruct Reference | ||||
| Meta | chat | $0.90 | ||
| Meta Llama 3 8B Instruct Reference | ||||
| Meta | chat | $0.20 | ||
| Qwen 2 Instruct (72B) | ||||
| Qwen | chat | $0.90 | ||
| Gemma-2 Instruct (27B) | ||||
| Google Internet company | chat | $0.80 | ||
| Gemma-2 Instruct (9B) | ||||
| chat | $0.30 | |||
| Mistral (7B) Instruct v0.3 | ||||
| mistralai | chat | $0.20 | ||
| Qwen 1.5 Chat (110B) | ||||
| Qwen | chat | $1.80 | ||
| Meta Llama Guard 2 8B | ||||
| Meta | moderation | $0.20 | ||
| WizardLM-2 (8x22B) | ||||
| microsoft | chat | $1.20 | ||
| DBRX Instruct | ||||
| Databricks | chat | $1.20 | ||
| DeepSeek LLM Chat (67B) | ||||
| DeepSeek | chat | $0.90 | ||
| Gemma Instruct (2B) | ||||
| Google Internet company | chat | $0.10 | ||
| Mistral (7B) Instruct v0.2 | ||||
| mistralai | chat | $0.20 | ||
| Mixtral-8x7B Instruct v0.1 | ||||
| mistralai | chat | $0.60 | ||
| Mixtral-8x7B v0.1 | ||||
| mistralai | language | $0.60 | ||
| Qwen 1.5 Chat (72B) | ||||
| Qwen | chat | $0.90 | ||
| Llama Guard (7B) | ||||
| Meta | moderation | $0.20 | ||
| Nous Hermes 2 - Mixtral 8x7B-DPO | ||||
| NousResearch | chat | $0.60 | ||
| Mistral (7B) Instruct | ||||
| mistralai | chat | $0.20 | ||
| Mistral (7B) | ||||
| mistralai | language | $0.20 | ||
| LLaMA-2 Chat (13B) | ||||
| Meta | chat | $0.22 | ||
| LLaMA-2 Chat (7B) | ||||
| Meta | chat | $0.20 | ||
| LLaMA-2 (70B) | ||||
| Meta | language | $0.90 | ||
| Code Llama Instruct (34B) | ||||
| Meta | chat | $0.78 | ||
| Upstage SOLAR Instruct v1 (11B) | ||||
| upstage | chat | $0.30 | ||
| M2-BERT-Retrieval-32k | ||||
| Together | embedding | $0.01 | ||
| M2-BERT-Retrieval-8k | ||||
| Together | embedding | $0.01 | ||
| M2-BERT-Retrieval-2K | ||||
| Together | embedding | $0.01 | ||
| UAE-Large-V1 | ||||
| WhereIsAI | embedding | $0.02 | ||
| BAAI-Bge-Large-1p5 | ||||
| BAAI | embedding | $0.02 | ||
| BAAI-Bge-Base-1p5 | ||||
| BAAI | embedding | $0.01 | ||
| MythoMax-L2 (13B) | ||||
| Gryphe | chat | $0.30 |
usage example
Example of model reasoning
import os
import requests
url = "https://api.together.xyz/v1/chat/completions"
payload = {
"model": "mistralai/Mixtral-8x7B-Instruct-v0.1",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.7,
"top_k": 50,
"repetition_penalty": 1
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"Authorization": "Bearer TOGETHER_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)
Example of model fine-tuning
import os
import requests
url = "https://api.together.xyz/v1/fine-tune"
payload = {
"model": "togethercomputer/llama-2-70b-chat",
"data": "path/to/your/data",
"epochs": 3,
"batch_size": 8
}
headers = {
"accept": "application/json",
"content-type": "application/json",
"Authorization": "Bearer TOGETHER_API_KEY"
}
response = requests.post(url, json=payload, headers=headers)
print(response.text)© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...