Thin-Plate-Spline-Motion-Model: Static Portrait Map Reference Video Portrait Motion Generation Video

General Introduction
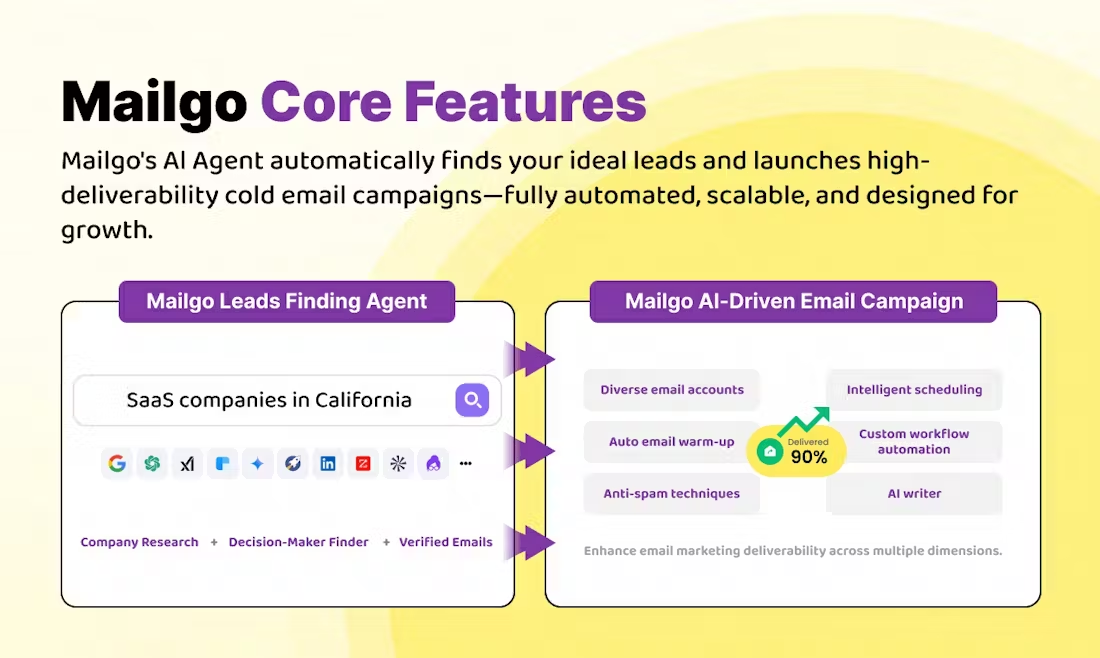
Thin-Plate-Spline-Motion-Model is a groundbreaking image animation generation project presented at CVPR 2022. The project is based on the theory of Thin Plate Spline Transform, and is able to realize high-quality animation effects from static images based on driving videos. The project adopts an end-to-end unsupervised learning framework, which is particularly good at dealing with situations where there are large pose differences between the source image and the driving video. Through the innovative introduction of thin spline motion estimation and multi-resolution masking, the model can generate more natural and smooth animation effects. The project not only open-sources the complete code implementation, but also provides a pre-trained model and an online demo, enabling researchers and developers to easily reproduce and apply the technique.
What if the public image spokesperson leaves? You can keep the spokesperson image picture and then have someone else record a video so that the spokesperson picture mimics the movements of the recorded video to generate the video, similar to face-swapping technology.

Function List
- Static image animation generation
- Supports training on multiple datasets (VoxCeleb, TaiChi-HD, TED-talks, etc.)
- Provide pre-trained models for download
- Support for web-based online presentations (Hugging Face Spaces integration)
- Support for Google Colab running online
- Supports multi-GPU training
- Provide AVD (Advanced Video Decoder) network training function
- Video reconstruction evaluation function
- Support for Python API calls
- Docker Environment Support
Using Help
1. Environmental configuration
The project requires a Python 3.x environment (Python 3.9 is recommended), and the installation steps are as follows:
- Cloning Project Warehouse:
git clone https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model.git
cd Thin-Plate-Spline-Motion-Model
- Install the dependencies:
pip install -r requirements.txt
2. Data preparation
The project supports multiple datasets:
- MGif dataset: refer to the Monkey-Net project to get it
- TaiChiHD and VoxCeleb datasets: processing by video-preprocessing guidelines
- TED-talks dataset: following MRAA program guidelines
Preprocessing dataset download (VoxCeleb as an example):
# 下载后合并解压
cat vox.tar.* > vox.tar
tar xvf vox.tar
3. Model training
Basic training orders:
CUDA_VISIBLE_DEVICES=0,1 python run.py --config config/dataset_name.yaml --device_ids 0,1
AVD network training:
CUDA_VISIBLE_DEVICES=0 python run.py --mode train_avd --checkpoint '{checkpoint_folder}/checkpoint.pth.tar' --config config/dataset_name.yaml
4. Video reconstruction assessment
CUDA_VISIBLE_DEVICES=0 python run.py --mode reconstruction --config config/dataset_name.yaml --checkpoint '{checkpoint_folder}/checkpoint.pth.tar'
5. Graphic animation presentations
Offers a variety of ways to use it:
- Jupyter Notebook: Using demo.ipynb
- Python command line:
CUDA_VISIBLE_DEVICES=0 python demo.py --config config/vox-256.yaml --checkpoint checkpoints/vox.pth.tar --source_image ./source.jpg --driving_video ./driving.mp4
- Web Demo:
- interviewsHugging Face SpacesOnline Demo
- utilizationReplicateWeb demo of the platform
- pass (a bill or inspection etc)Google Colab(of a computer) run
6. Pre-training model acquisition
Multiple download sources are provided:
- Google Drive
- Yandex Disk
- Baidu.com (Extract code: 1234)
7. Caveats
- It is recommended to train with more data and longer training cycles for better results
- Ensure sufficient GPU memory
- It is recommended to use the preprocessed dataset for training
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...