General Introduction Parsio is an AI-based document and email data extraction tool that automatically extracts structured data from PDFs, emails and other documents. The platform provides a powerful PDF parser and OCR functionality, and supports a wide range of document types, including invoices, business cards and IDs...
Comprehensive Introduction Chonkie is a lightweight and efficient RAG (Retrieval-Augmented Generation) text chunking library designed to help developers quickly and easily chunk text. The library supports a variety of chunking methods, including chunking based on tags, words, sentences and semantic similarity...
Enable Builder Smart Programming Mode, unlimited use of DeepSeek-R1 and DeepSeek-V3, smoother experience than the overseas version. Just enter the Chinese commands, even a novice programmer can write his own apps with zero threshold.
Comprehensive introduction TextIn is a professional PDF to Markdown tool designed to help users efficiently convert PDF documents to Markdown format. The tool supports a variety of file formats, easy to operate, fast conversion speed, the ability to retain the original PDF format and content, to enhance the efficiency of document processing. Whether it is a ...
General Description Text Extraction API (text-extract-api) is a powerful tool designed to extract and parse content from a variety of document formats (e.g. PDF, Word, PPTX, etc.). The API utilizes state-of-the-art Optical Character Recognition (OCR) technology and Ollama-supported models to be able to take any document or image...
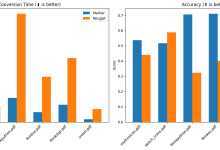
Comprehensive Introduction Datalab offers a range of advanced AI models focused on OCR, layout analysis, PDF to Markdown, and more. These models are not only high performing, but also easy to use and open source. The Marker models on the platform can quickly and accurately convert PDF to Markdown, including tables...
Comprehensive Introduction MinerU is an open source data extraction tool developed by the OpenDataLab team at the Shanghai Artificial Intelligence Laboratory, focusing on efficiently extracting content from complex PDF documents, web pages, and eBooks. It can convert multimodal PDF documents containing images, formulas, tables and other elements into easy-to-analyze M...
General Introduction Marker is a deep learning based document processing tool designed to convert PDF files to Markdown format quickly and accurately. It supports a wide range of document types and is especially optimized for conversion of books and scientific papers.Marker is able to remove redundant content such as headers and footers, format tables and...
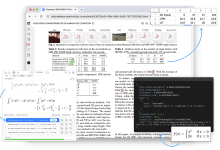
General Description Mathpix is a powerful AI-driven document automation tool designed for researchers, developers, and businesses. It quickly and accurately converts PDFs and images into searchable, exportable, and machine-readable text.Mathpix offers a wide range of features, including mathematical formula recognition, LaT...
Comprehensive Introduction Unstructured-IO provides a range of open source components for processing and preprocessing images and text documents such as PDF, HTML, Word documents, etc. Its main goal is to simplify and optimize data processing workflow , especially for large language model (LLM) applications to provide support.Unstructured...
Comprehensive introduction Jina AI's Reader project is an open source tool (Reader open source address), can be any URL by adding the prefix https://r.jina.ai/转换成适合大型语言模型 (Large Language Models, LLM) input format, support for dynamic streaming mode and image reading...