Comprehensive Introduction llmstxt-generator is a professional web content extraction and integration tool specialized in preparing high-quality textual datasets for training and inference in Large Language Models (LLMs). Developed by Mendable AI, the tool uses web crawling technology provided by @firecrawl_dev and GPT-4-mini ...
Comprehensive introduction Doc2X is a powerful document image formula recognition and conversion tools, is committed to providing efficient and intelligent document processing solutions. Whether it is an academic research paper, textbooks, corporate documents or financial reports, Doc2X can accurately recognize the tables and formulas in PDF and convert them with one key...
Enable Builder Smart Programming Mode, unlimited use of DeepSeek-R1 and DeepSeek-V3, smoother experience than the overseas version. Just enter the Chinese commands, even a novice programmer can write his own apps with zero threshold.
Comprehensive Introduction ExtractThinker is a flexible document intelligence tool that utilizes Large Language Models (LLMs) to extract and classify structured data from documents, providing a seamless ORM-like document processing workflow. It supports multiple document loaders, including Tesseract OCR, Azure Form Recog...
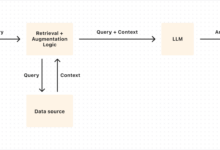
Comprehensive Introduction HtmlRAG is an innovative open source project focused on improving the processing of HTML documents in Retrieval Augmented Generation (RAG) systems. The project presents a novel approach that argues that using HTML formatting in RAG systems is more efficient than plain text. The project encompasses a complete data processing flow from the cha...
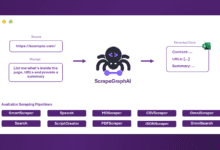
Comprehensive Introduction ScrapeGraphAI is an innovative Python web scraping library that cleverly combines Large Language Modeling (LLM) and Direct Graph Logic to create a scraping pipeline for websites and local documents. The uniqueness of this tool lies in its perfect balance of simplicity and power: the user simply describes what he/she wants to mention...
Comprehensive Introduction Vision Parse is a revolutionary document processing tool that cleverly combines state-of-the-art Visual Language Models (Vision Language Models) technology to intelligently convert PDF documents into high-quality Markdown format content. The tool supports a wide range of top-notch visual language models, including o...
Comprehensive Introduction Outlines is an open source library developed by dottxt-ai to enhance the application of Large Language Models (LLMs) through structured text generation. The library supports a wide range of model integrations, including OpenAI, transformers, llama.cpp, etc. It provides simple but powerful cue primitives,...
General Introduction MarkItDown is a Python tool developed by Microsoft designed to convert various files and office documents to Markdown format. The tool supports a wide range of file types, including PDF, PowerPoint, Word, Excel, images (EXIF metadata and OCR), audio (EXIF metadata and language...
Comprehensive Introduction Chunkr is a self-hosted API specialized in converting PDF, PPTX, DOCX, and Excel files into data suitable for use in RAG (Retrieval Augmented Generation) and LLM (Large Language Modeling). It was developed by Lumina AI Inc. and utilizes advanced visual models for document ingest...
General Introduction GitIngest is an open source tool designed to transform GitHub code repositories into text suitable for Large Language Model (LLM) hints. With a simple operation, users can extract and format the content of any GitHub repository into text suitable for LLM use. The tool provides one-click analysis...
General Introduction E2M (Everything to Markdown) is an open source Python library designed to convert multiple file formats to Markdown format. The tool supports a wide range of file types including doc, docx, epub, html, htm, url, pdf, ppt, pptx, mp3 and m4a.E2M uses...
Comprehensive Introduction Docling is a powerful document parsing and exporting tool that supports a wide range of document formats including PDF, DOCX, PPTX, XLSX, Image, HTML, AsciiDoc and Markdown.It parses and exports these documents to HTML, Markdown, and JSON formats, with support for embedding and...
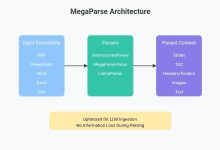
Comprehensive Introduction MegaParse is a powerful and versatile document parsing tool designed to optimize data processing for the Large Language Model (LLM). Whether you are working with text, PDF, PowerPoint presentations or Word documents, MegaParse makes it easy and ensures that the parsing process is not...
Comprehensive Introduction ViTLP (Visually Guided Generative Text-Layout Pre-training for Document Intelligence) is an open source project that aims to enhance document intelligence processing through visually guided generative text layout pre-training models. The project was developed by Veason-silverbul...
General Introduction Trieve is an all-inclusive infrastructure developed by Devflow, Inc. designed for search, recommendations, RAG (retrieval augmentation generation) and analytics. The platform is served via an API, supports self-hosting, and is available for environments such as AWS, GCP, Kubernetes, and Docker Compose....
Comprehensive introduction pdf2htmlEX is an open source tool designed to convert PDF files to HTML format , by analyzing the content of PDF files and use HTML + CSS to accurately restore its visual effect , PDF documents into a browser can be viewed directly on the web page . The tool is particularly suitable for containing a large number of ...
Comprehensive Introduction Maxun is an open source no-code web data extraction platform that allows users to train robots in minutes to automatically crawl web data and convert it into APIs or spreadsheets. The platform supports paging and scrolling, can adapt to changes in website layout, provides powerful data crawling features for...
Comprehensive Introduction OmniParse is a powerful data parsing and optimization platform designed to transform any unstructured data into structured, actionable data optimized for the GenAI (Generative Artificial Intelligence) framework. Whether you are working with documents, tables, images, videos, audio files or web content,...
General Introduction Parsio is an AI-based document and email data extraction tool that automatically extracts structured data from PDFs, emails and other documents. The platform provides a powerful PDF parser and OCR functionality, and supports a wide range of document types, including invoices, business cards and IDs...