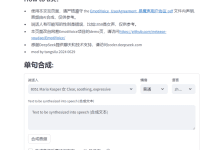
Comprehensive Introduction EmotiVoice is a text-to-speech (TTS) engine with multiple voices and emotional cue control developed by NetEaseYoudao. This open source TTS engine supports English and Chinese, has more than 2000 different voices, and has the emotion synthesis ability to create multiple voices with happy, excited, sad and angry...
General Introduction Listnr is a text-to-speech software with a generative AI engine that creates speech synthesis in 1,000+ different voices in 142+ languages, including cloning your own voice. The platform serves over 1 million users across short videos, YouTube videos, game characters, podcasts,...
Enable Builder Smart Programming Mode, unlimited use of DeepSeek-R1 and DeepSeek-V3, smoother experience than the overseas version. Just enter the Chinese commands, even a novice programmer can write his own apps with zero threshold.
General Introduction Uberduck AI is an innovative platform for creative agencies, music producers and programmers to synthesize singing and speaking voices with AI. Users can choose different musical rhythms, generate lyrics using AI or write their own, select specific sounds, and ultimately create rap songs in audio or video format...
General Introduction NotebookLM is a personalized AI collaboration tool from Google designed to help users use their minds to their full potential. Users can upload documents, and NotebookLM instantly masters the content of these sources, enabling users to easily read, record notes, and use the tool to optimize and...
Comprehensive Introduction Record Cafe is a one-stop audio/video processing platform that provides AI video dialog, AI subtitles and AI speech to text services. Features include recording screen, editing video, converting GIF/audio, etc., and supports cloud storage and sharing. The interface is intuitive and easy to use, and it also supports multi-screen recording and multi-language intelligent reading...
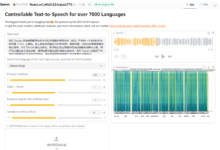
General Introduction IMS Toucan is a state-of-the-art text-to-speech (TTS) toolkit developed by the Institute for Natural Language Processing (IMS) at the University of Stuttgart, Germany. Supporting more than 7000 languages, the toolkit is fast, controllable and has low computational resource requirements.IMS Toucan is designed for research, teaching...
General Introduction ChatTTS is a generative speech model designed for conversational scenarios. It generates natural and expressive speech, supports multiple languages and multiple speakers, and is suitable for interactive conversations. The model goes beyond large by predicting and controlling fine-grained prosodic features such as laughter, pauses, and interjections...
FreeTTS General Description FreeTTS is a free online text-to-speech tool that allows users to convert text to natural sounding voice files. Supporting multiple languages and sound options, users can convert text to MP3, WAV, OGG and ACC formats.FreeTTS also provides voice transcription, sound...
General Introduction ElevenLabs is a startup based in New York, USA, specializing in the field of generative AI speech. The company offers a range of powerful services for text-generated speech, speech-generated speech, speech cloning, and speech recognition.ElevenLabs' strength lies in its strong multilingual support...
Comprehensive Introduction Easy-Voice-Toolkit is a multifunctional toolkit based on the Open Source Speech Project that provides a wide range of automated audio tools for speech recognition, speech transcription, speech conversion, dataset creation and model training. Users can use these tools selectively or sequentially as needed...
General Description Dupdub is a side-heavy podcast and video presentation creation platform that offers a range of AI tools to support user creativity. Features cover text to video creation, offering AI voice and video dubbing services, as well as video editing, transcription and subtitling. Dupdub again out of the gate launched...
General Introduction TTSMaker is a free online text-to-speech tool that supports more than 100 languages and 300 speech styles. Users can convert text to natural and smooth speech and download audio files for commercial use. The tool is suitable for video dubbing, audiobooks, education and training, and advertising and marketing...
General Description Vidnoz is a free AI video generation platform to quickly create AI videos in less than 1 minute. No cost, download or experience required. The platform offers 500+ AI avatars, 470+ realistic AI voiceovers and 500+ templates. With Vidnoz AI Video Generator, users can create videos faster,...
General Description MemoAI is a powerful video translation tool specialized in converting video and audio files to text, subtitles and notes. Whether it's a YouTube video, a podcast or a local file, MemoAI can handle it with ease. It supports transcription and translation in more than 90 languages such as Chinese, English, Japanese, etc.MemoAI...
Comprehensive Introduction Tencent Smart Shadow is an online intelligent video creation platform launched by Tencent, which can support text dubbing, digital human broadcasting, automatic subtitle recognition and other functions through powerful AI tools provided by cloud services.It integrates material search, video editing, rendering export and publishing, bringing users a convenient visual...
pyVideoTrans General Introduction pyvideotrans is a video translation dubbing tool. Users are able to translate video content from one language to another and add corresponding voiceovers and subtitles to the video. It is based on the openai-whisper offline model and supports a variety of translation and speech synthesis services, ex...
Comprehensive Introduction Himalaya Audio Editor is a comprehensive AI audio creation platform. It provides powerful features that support users to perform professional-grade podcast production, multi-track recording, audio editing, and can convert text to speech. The platform also contains multiple options for professional voice, helping users to efficiently produce...
General Introduction Parler-TTS is an open source text-to-speech (TTS) modeling library developed by Hugging Face, designed to generate high-quality, natural-sounding speech. The model is capable of generating speech with a specific speaker style (e.g. gender, pitch, speaking style, etc.) based on the input text.Parler-TTS ...