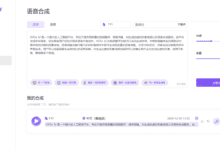
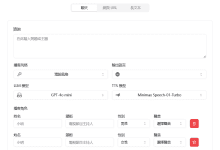
Comprehensive Introduction ViiTor AI is a powerful artificial intelligence platform focused on providing high-quality video translation, voice cloning, AI-generated avatar videos, and speech synthesis services. The platform supports multiple languages and is designed to help users easily realize multilingual content creation.ViiTor AI's video translation...
Comprehensive Introduction Wondercraft is a revolutionary AI-driven audio/video creation platform that provides content creators with a one-stop audio/video production solution. The platform utilizes advanced AI technology to convert textual content into natural and smooth speech, supports more than 20 languages, and offers more than 200 AI...
Enable Builder Smart Programming Mode, unlimited use of DeepSeek-R1 and DeepSeek-V3, smoother experience than the overseas version. Just enter the Chinese commands, even a novice programmer can write his own apps with zero threshold.
General Introduction NotebookLM Podcast is an innovative platform that utilizes artificial intelligence technology to transform any textual content into dynamic, engaging audio podcasts. Whether you're a student, educator, content creator, or busy professional, NotebookLM Podcast provides personalized...
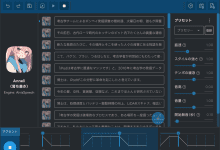
General Introduction AivisSpeech is a Japanese speech synthesizer based on the VOICEVOX editor UI. It integrates the AivisSpeech Engine, which makes it easy to generate emotionally rich speech.AivisSpeech supports a wide range of sound synthesis models, allowing users to generate high-quality...
Comprehensive Introduction PlayAI is an artificial intelligence platform focused on speech generation and speech cloning. It provides a wide range of speech models capable of generating smooth and emotional dialog. Users can use the platform to create personalized voice agents to enhance the interactive experience.PlayAI's technology is suitable for a variety of applications...
Comprehensive Introduction GizAI is a one-stop platform with integrated AI generation, note-taking and cloud storage capabilities. Users can generate images, videos, audios, texts, characters, stories and games with GizAI, and can take collaborative notes and cloud storage on the platform.GizAI provides a wide range of AI tools to help use...
Comprehensive Introduction OuteTTS is an experimental text-to-speech (TTS) model that uses a pure language modeling approach to generate high-quality speech. Unlike traditional TTS systems, OuteTTS does not require external adapters or complex architectures. The model is based on the LLaMa architecture and supports a speech cloning feature that can generate...
General Introduction PodLM is a state-of-the-art AI podcast generation platform designed to help users quickly convert text, documents or URL content into high-quality podcast audio. By utilizing cutting-edge AI technology, PodLM is able to automatically generate structured and engaging podcast scripts and convert them into professional-quality...
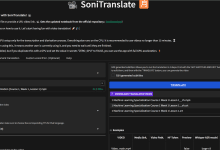
General Description SoniTranslate is a powerful and user-friendly video multilingual dubbing tool designed to provide a solution for video translation and synchronized audio. It uses advanced speech recognition and machine translation technologies to translate video content into multiple languages and keep the audio synchronized. The program is based on Gradi...
Comprehensive Introduction Tease Dubbing is a popular AI dubbing software with over 5 million users. The software utilizes advanced AI intelligent dubbing technology to provide professional and realistic dubbing effects, which is suitable for short videos, advertisement production, education and training and other scenarios. Teaser Dubbing is committed to providing users with fast and convenient...
General Introduction YouTube Dubbing is an intelligent dubbing platform that specializes in multilingual dubbing for video creators and viewers. Through AI technology, the platform is able to automatically translate and generate dubs from YouTube videos, supporting multiple languages and voice styles. Users can simply install the plugin and watch the video...
General Introduction Podcastfy is an open source Python package that utilizes Generative Artificial Intelligence (GenAI) technology to convert web content, PDF files, text, images, youtube videos, and many other sources into engaging multi-language audio conversations. Unlike traditional user interface-based...
Comprehensive Introduction QuickPiperAudiobook is an open source project designed to convert various text formats (e.g. epub, mobi, txt, PDF, HTML, etc.) into natural-sounding audiobooks with one simple command. The tool uses the Piper model for conversion and manages the installation of Piper and ph...
General Introduction PDF2Audio is an open source project designed to convert PDF files into audio content such as podcasts, lectures and summaries. The tool utilizes OpenAI's GPT model for text generation and text-to-speech conversion. Users can upload multiple PDF files, choose different instruction templates (e.g. podcast...
Comprehensive Introduction Seaweed AI is an intelligent dubbing product that can convert text into voice online, powered by the Yun Zhisheng AI open platform. Users can self-help realize voice cloning, and provide AI pronouncers of different genders, accents and languages, and directly dub the voice after inputting text. It can quickly dub short videos...
General Introduction edge-tts is an open source Python module that allows users to use Microsoft Edge's online text-to-speech service in Python code without the need for a Microsoft Edge browser, Windows operating system, or API key. Provides direct use of edge-tts from the command line and edge-...
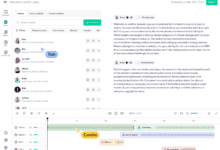
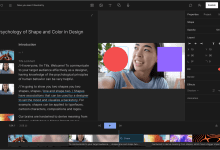
Descript General Description Descript is a powerful yet easy to use video and podcast editing tool. It has industry-leading transcription accuracy and speed and powerful correction tools, as well as the ability to transcribe video to text and edit video by editing text through AI technology. On top of that, Descript...
Comprehensive Introduction Murf AI is a powerful online artificial intelligence voice generation tool that converts text into near-life-like speech. It offers up to 120+ AI voice options, supports 20+ languages, and is suitable for a variety of occasions such as podcasts, videos, professional presentations, etc.Murf AI also features audio...
Comprehensive Introduction Resemble AI is an artificial intelligence speech synthesis platform designed for the enterprise. The platform provides cutting-edge AI voice generator technology and deep forged audio detection for future information security. Features include voice cloning, real-time deep fake audio detection, AI watermarking technology, rich emotion...