
Rapid Deployment of the RAG 3-Pack for Dify with GPUStack

GPUStack It is an open source big model-as-a-service platform that can efficiently integrate and utilize various heterogeneous GPU/NPU resources such as Nvidia, Apple Metal, Huawei Rise, and Moore Threads to provide local private deployment of big model solutions.
GPUStack can support RAG The three key models needed in the system: the Chat dialog model (a large language model), the Embedding text embedding model and the Rerank reordering model are a three-piece suite of very simple and foolproof operations to deploy the local private models needed in the RAG system.
Here's how to install GPUStack and Dify with the Dify to interface with the dialog model, Embedding model and Reranker model deployed by GPUStack.
Installing GPUStack
Install it online on Linux or macOS with the following commands, a sudo password is required during the installation process: curl -sfL https://get.gpustack.ai | sh -
If your environment can't connect to GitHub and you can't download some binaries, use the following commands to install them, using the --tools-download-base-url The parameter specifies to download from Tencent Cloud Object Storage:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Run Powershell as administrator on Windows and install it online with the following command:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
If your environment can't connect to GitHub and you can't download some binaries, use the following commands to install them, using the --tools-download-base-url The parameter specifies to download from Tencent Cloud Object Storage:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
When you see the following output, the GPUStack has been successfully deployed and started:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
Next, follow the instructions in the script output to get the initial password for logging into GPUStack and execute the following command:
on Linux or macOS:cat /var/lib/gpustack/initial_admin_password
On Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
Access the GPUStack UI in a browser with the username admin and the password as the initial password obtained above.
After resetting the password, enter GPUStack: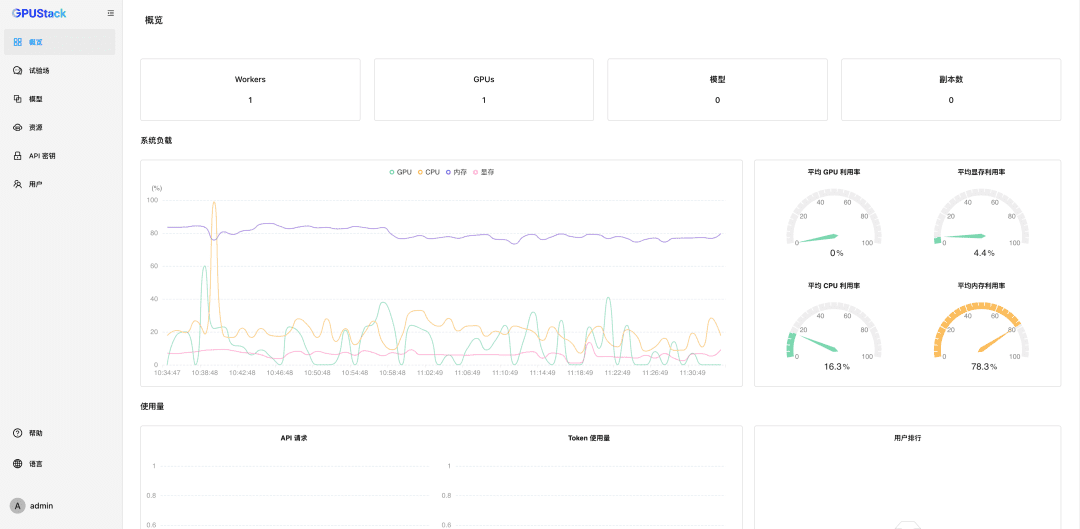
Nanomanagement GPU resources
GPUStack supports GPU resources for Linux, Windows, and macOS devices, and manages these GPU resources by following these steps.
Other nodes need to be authenticated Token Join the GPUStack cluster and execute the following command at the GPUStack Server node to obtain a Token:
on Linux or macOS:cat /var/lib/gpustack/token
On Windows:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
Once you have the Token, run the following command on the other nodes to add the Worker to the GPUStack, and nanomanage the GPUs on those nodes (replace http://YOUR_IP_ADDRESS with your GPUStack access address, and YOUR_TOKEN with the Authentication Token used to add the Worker):
on Linux or macOS:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
On Windows:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
With the above steps, we have created a GPUStack environment and managed multiple GPU nodes, which can then be used to deploy private big models.
Deployment of private large models
Visit GPUStack and deploy models in the Models menu. GPUStack supports deploying models from HuggingFace, Ollama Library, ModelScope, and private model repositories; ModelScope is recommended for domestic networks.
GPUStack Support vLLM and llama-box reasoning backends, vLLM is optimized for production reasoning and is better suited to production needs in terms of concurrency and performance, but vLLM only supports Linux systems. llama-box is a flexible, multi-platform compatible reasoning engine that is llama.cpp It supports Linux, Windows, and macOS systems, and supports not only various GPU environments, but also running large models in CPU environments, making it more suitable for scenarios that require multi-platform compatibility.
GPUStack automatically selects the appropriate inference backend based on the type of model file when deploying the model. GPUStack uses llama-box as the backend to run the model service if the model is in GGUF format, and vLLM as the backend to run the model service if it is in a non-GGUF format.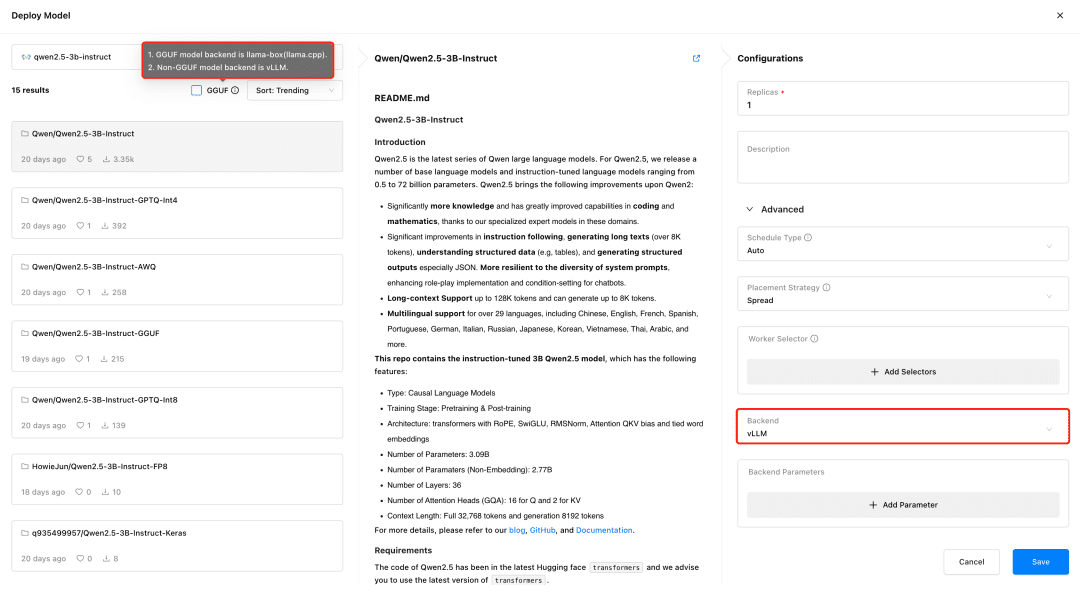
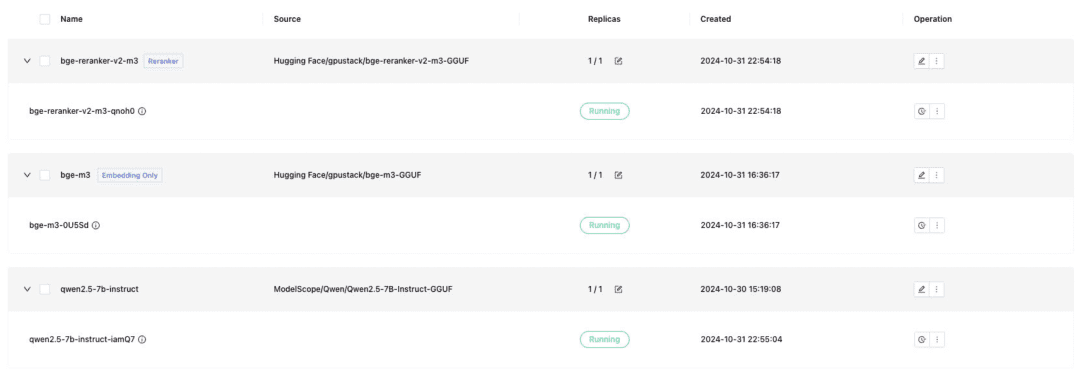
Deploy the text dialog model, Embedding text embedding model, and Reranker model needed for Dify docking, and remember to check the GGUF format when deploying:
- Qwen/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
GPUStack also supports VLM multimodal models, the deployment of which requires the use of a vLLM inference backend:
Qwen2-VL-2B-Instruct 

Once the models are deployed, RAG systems or other generative AI applications can interface with the GPUStack deployed models through the OpenAI / Jina compatible API provided by GPUStack, followed by Dify to interface with the GPUStack deployed models.
Dify Integrates GPUStack Models
Install Dify
To run Dify using Docker, you need to prepare a Docker environment, and be careful to avoid conflict between Dify and GPUStack's port 80, use another host or modify the port. Execute the following command to install Dify:git clone -b 0.10.1 https://github.com/langgenius/dify.gitVisit Dify's UI interface at http://localhost to initialize the administrator account and log in.
cd dify/docker/
cp .env.example .env
docker compose up -d
To integrate a GPUStack model first add a Chat dialog model, in the top right corner of Dify select "Settings - Model Providers", find the GPUStack type in the list and select Add Model:
Fill in the name of the LLM model deployed on the GPUStack (e.g., qwen2.5-7b-instruct), the GPUStack's access address (e.g., http://192.168.0.111) and generated API Key, and the context lengths of the model settings 8192 and max tokens 2048: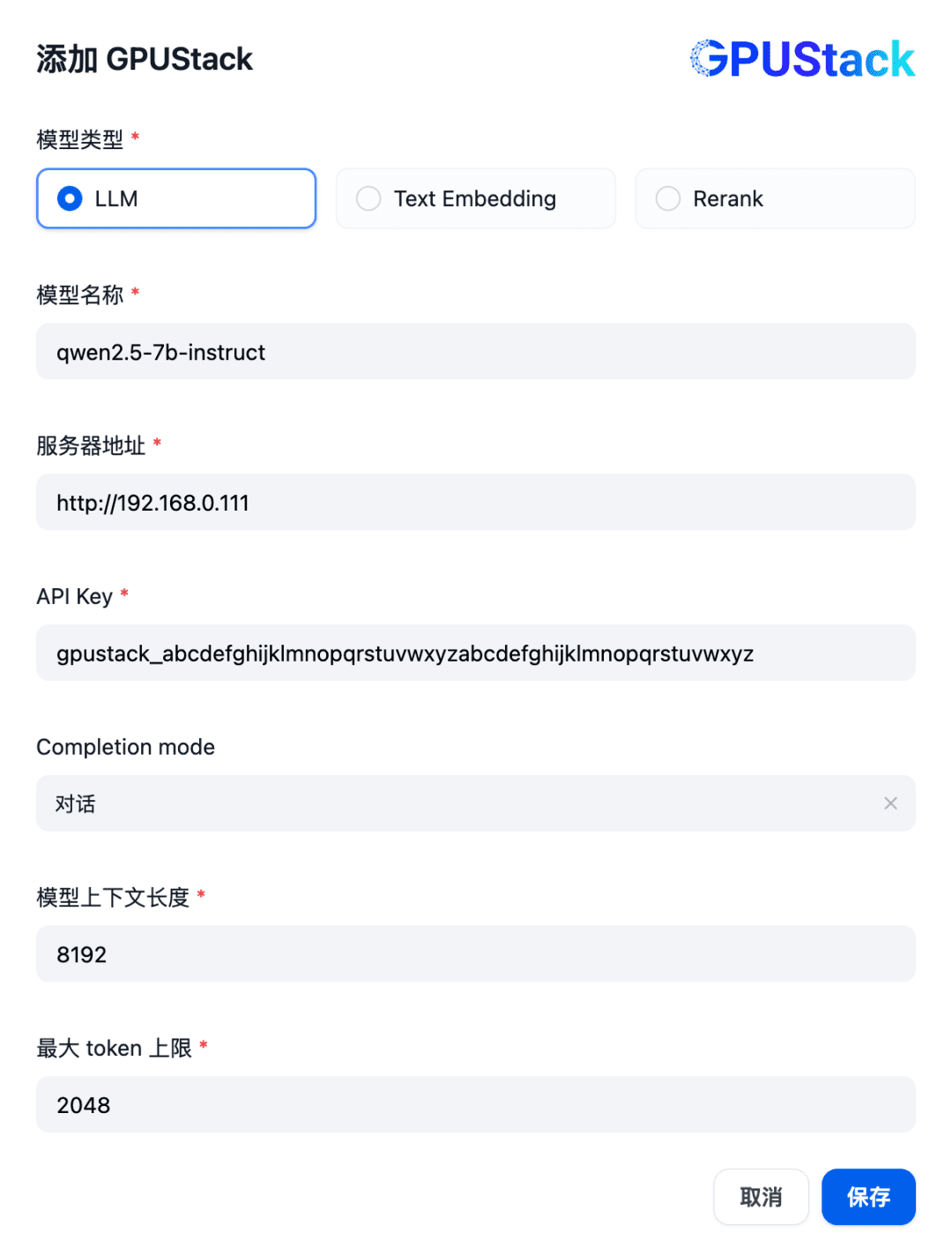
Next, to add an Embedding model, go ahead and select the GPUStack type at the top of the Model Provider and select Add Model: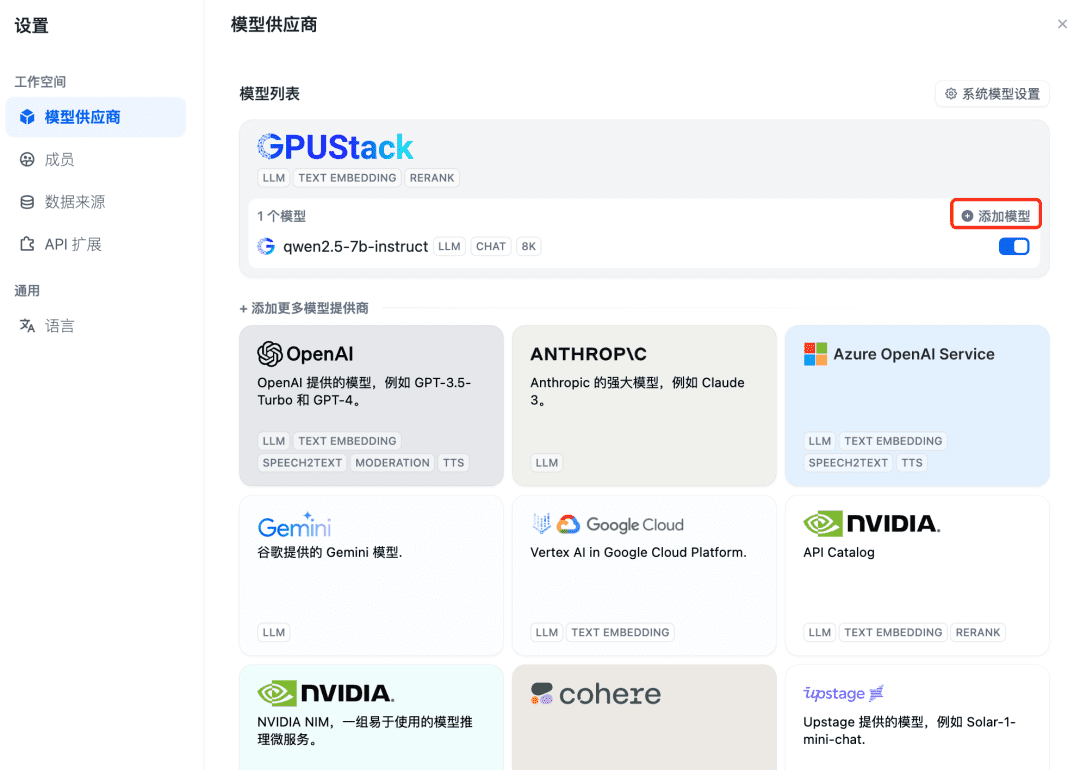
Add a model of type Text Embedding, filling in the name of the Embedding model deployed on the GPUStack (e.g., bge-m3), the GPUStack's access address (e.g., http://192.168.0.111) and generated API Key, and a context length of 8192 for the model settings: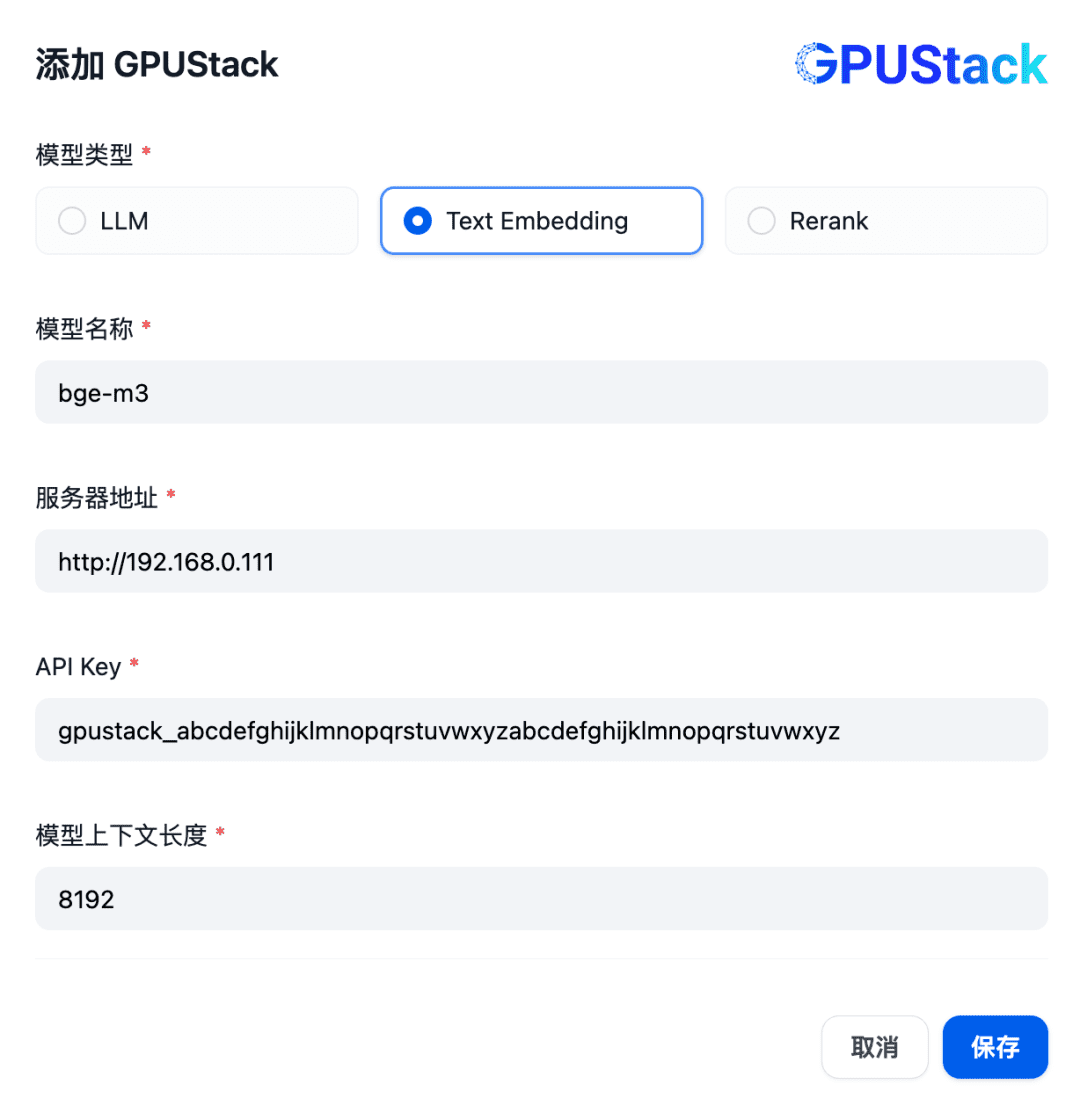
Next, to add a Rerank model, continue to select the GPUStack type, select Add Model, add a model of type Rerank, fill in the name of the Rerank model deployed on the GPUStack (e.g., bge-reranker-v2-m3), the access address of the GPUStack (e.g., http://192.168. 0.111) and the generated API Key, as well as the context length 8192 for the model settings: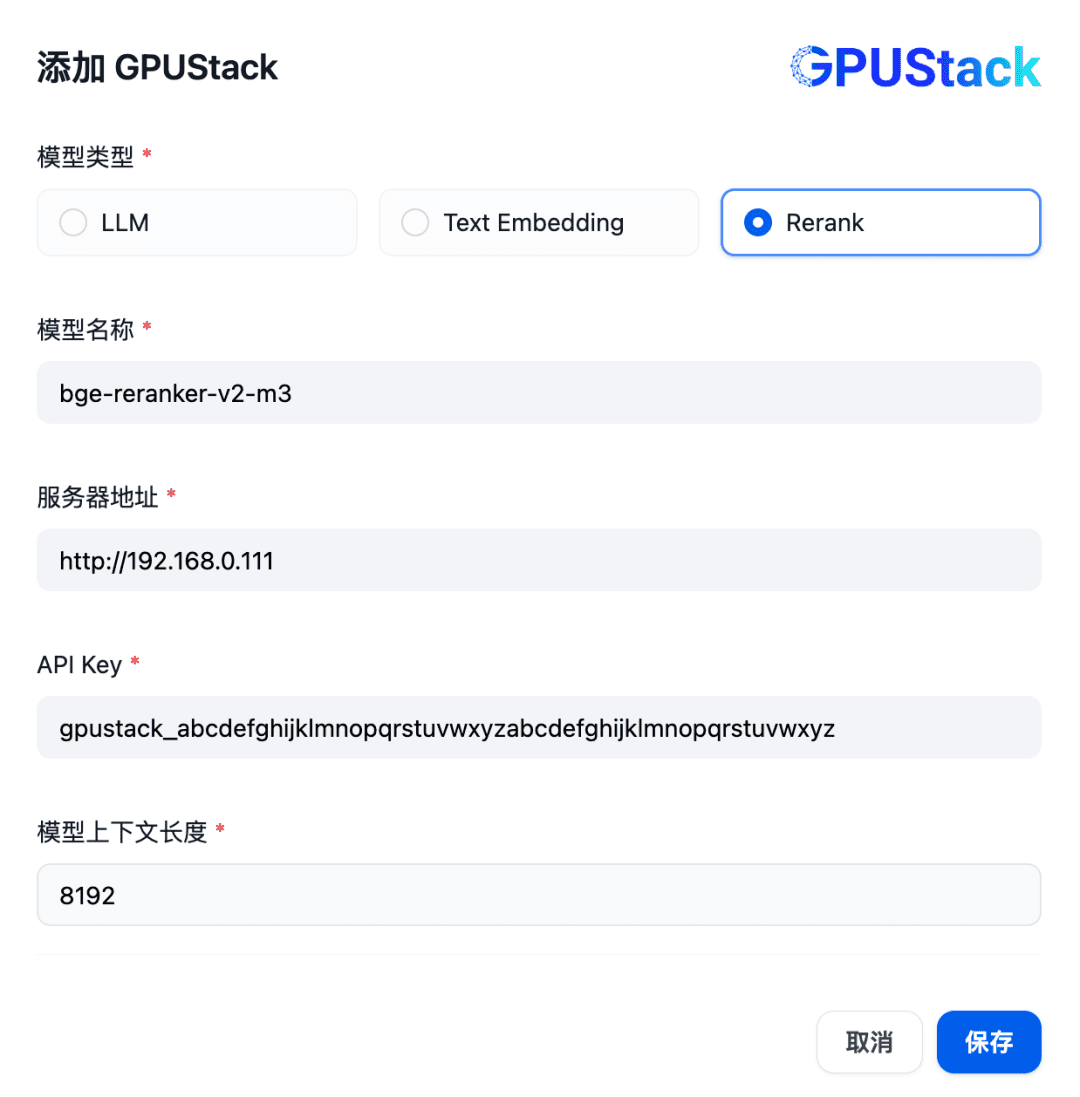
Refresh after adding and then confirm at the Model Provider that the system models are configured for the three models added above: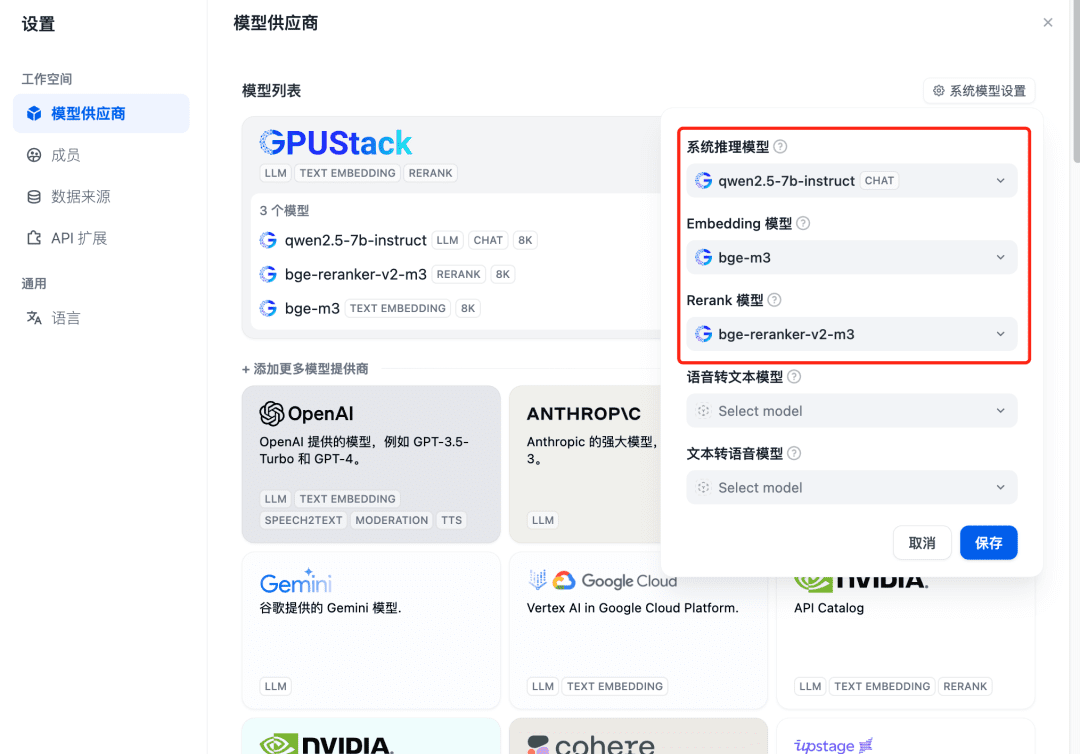
Using Models in the RAG System Select Dfiy's Knowledge Base, select Create Knowledge Base, import a text file, confirm the Embedding model option, use the recommended hybrid search for the search settings, and turn on the Rerank model: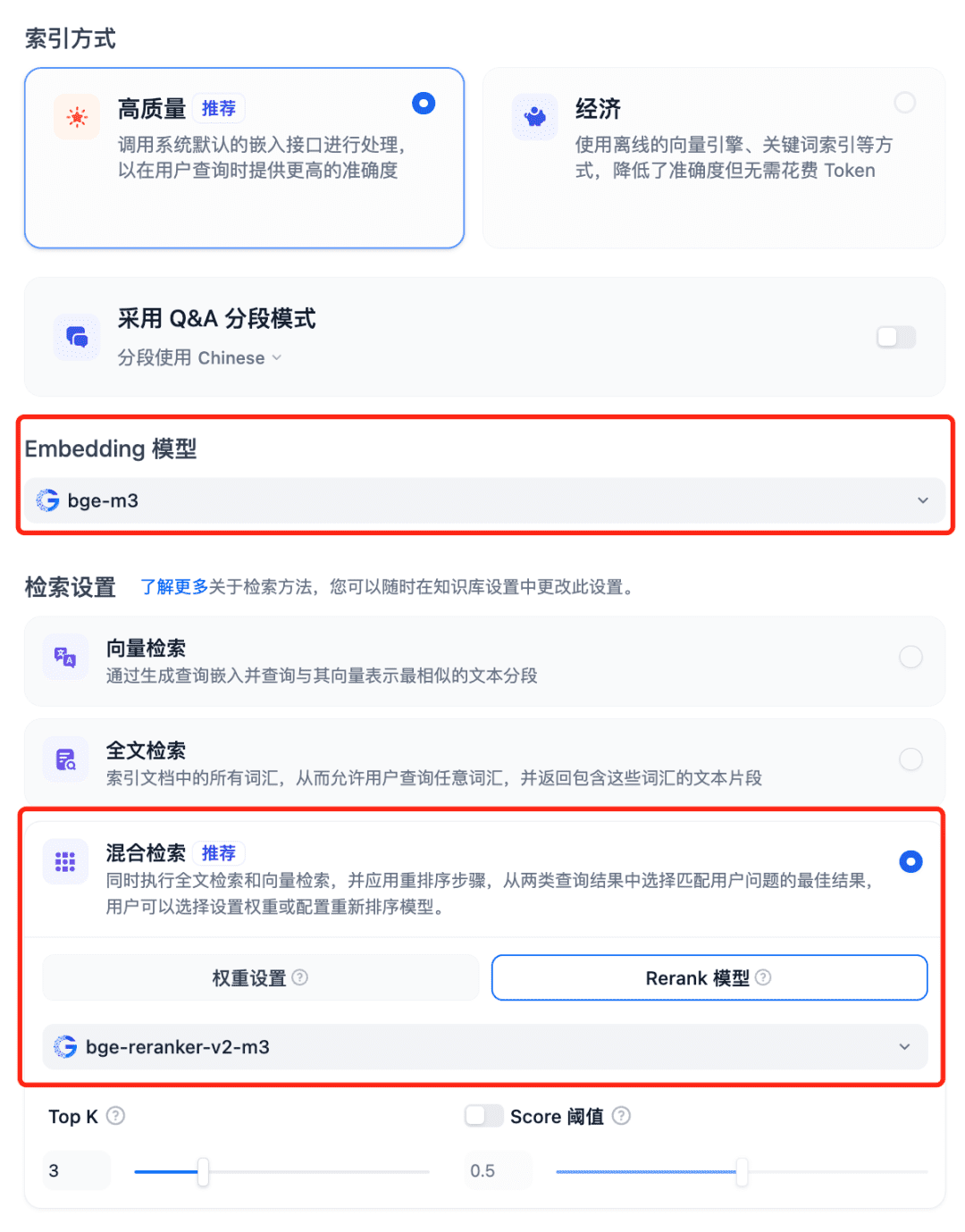
Save and begin the process of vectorizing the document, and once the vectorization is complete, the knowledge base is ready to use.
Recall tests can be performed to confirm the recall effectiveness of the knowledge base, and the Rerank model will be refined to recall more relevant documents to achieve better recall results: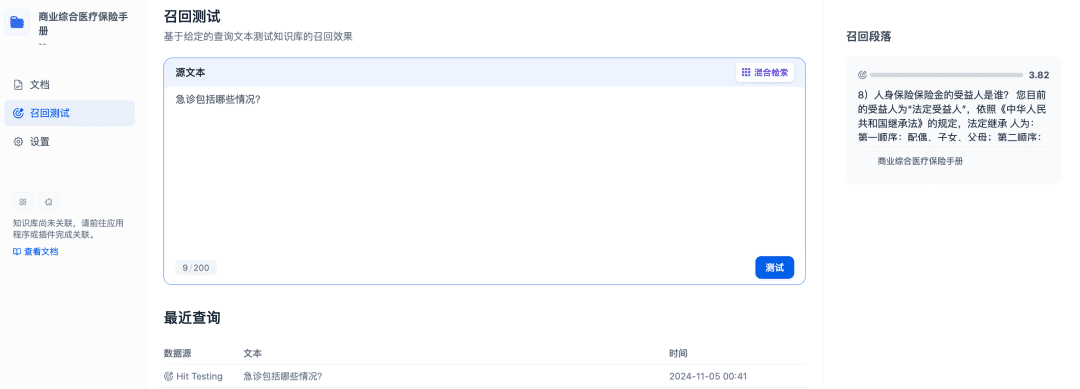
Next create a chat assistant app in the chat room: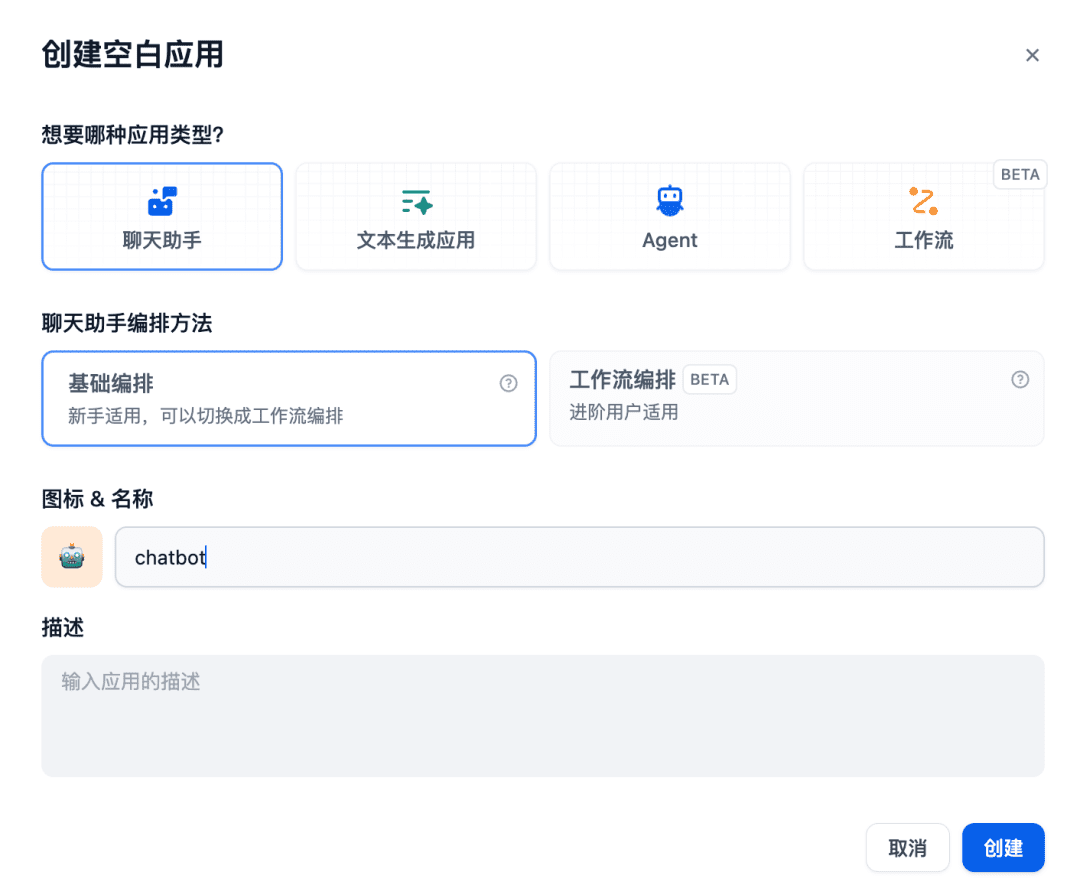
Adding the relevant knowledge base to the context is ready for use, at which point the Chat model, Embedding model and Reranker model will work together to support the RAG application, with the Embedding model responsible for vectorization, the Reranker model responsible for fine-tuning the content of the recall, and the Chat model responsible for answering based on the content of the question and the context of the recall: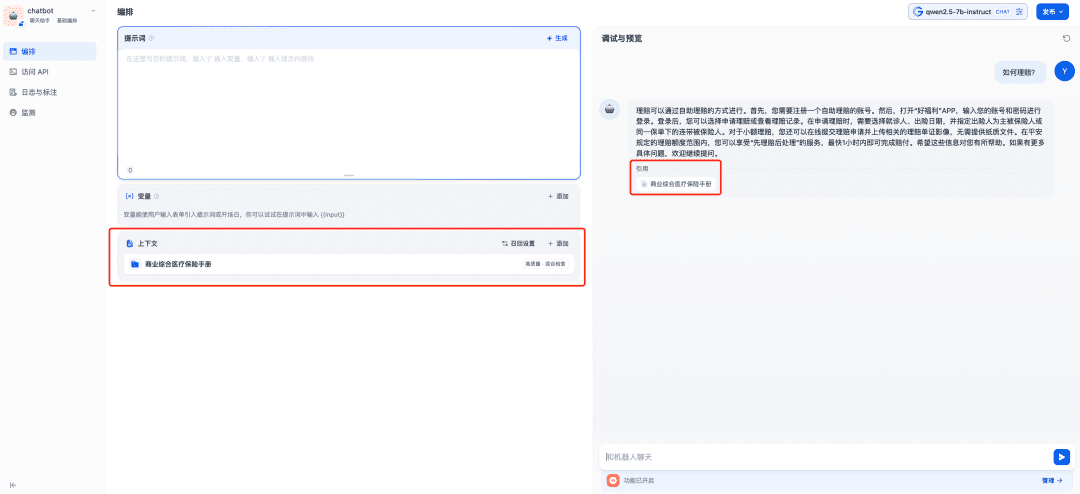
The above is an example of using Dify to interface with GPUStack models. Other RAG systems can also interface with GPUStack via OpenAI / Jina compatible APIs, and can utilize the various Chat, Embedding and Reranker models deployed by the GPUStack platform to support the RAG system.
The following is a brief description of the GPUStack function.
GPUStack Features
- Heterogeneous GPU support: Support for heterogeneous GPU resources, currently supports Nvidia, Apple Metal, Huawei Rise and Moore Threads and other types of GPU/NPUs
- Multiple inference backends: vLLM and llama-box (llama.cpp) inference backends are supported, taking into account both production performance and multi-platform compatibility.
- Multi-platform support: Linux, Windows and macOS platforms, covering amd64 and arm64 architectures.
- Multi-model type support: supports various types of models such as LLM text model, VLM multimodal model, Embedding text embedding model and Reranker reordering model.
- Multi-Model Repository Support: Supports deployment of models from HuggingFace, Ollama Library, ModelScope and private model repositories.
- Rich automatic/manual scheduling policies: supports various scheduling policies such as compact scheduling, decentralized scheduling, specified worker label scheduling, specified GPU scheduling, etc.
- Distributed inference: If a single GPU can't run a large model, GPUStack's distributed inference feature can be used to automatically run the model on multiple GPUs across hosts
- CPU reasoning: If there is no GPU or insufficient GPU resources, GPUStack can use CPU resources to run large models, supporting two CPU reasoning modes: GPU&CPU hybrid reasoning and pure CPU reasoning.
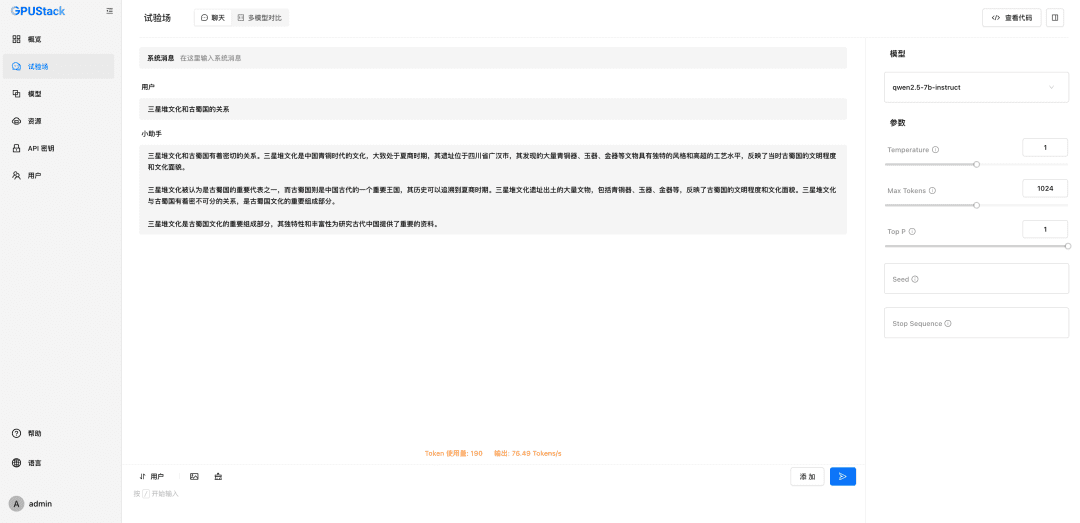
- Multi-model comparison: GPUStack in the Playground A multi-model comparison view is provided to compare the Q&A content and performance data of multiple models at the same time to evaluate the model Serving effect of different models, different weights, different Prompt parameters, different quantization, different GPUs, and different inference backends.
- GPU and LLM Observables: Provides comprehensive performance, utilization, status monitoring and usage data metrics to assess GPU and LLM utilization
GPUStack provides all the enterprise-class features needed to build a private large model-as-a-service platform. As an open source project, it requires very simple installation and setup to build a private large model-as-a-service platform out of the box.
summarize
The above is a configuration tutorial for installing GPUStack and integrating GPUStack models using Dify, the project's open source address is: https://github.com/gpustack/gpustack.
GPUStack as a low-barrier, easy-to-use, out-of-the-boxopen source platformIt can help enterprises quickly integrate and utilize heterogeneous GPU resources, and quickly build an enterprise-grade private big model-as-a-service platform in a short period of time.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...