
Scaling Test-Time Compute: Chain of Thought on Vector Models

Since OpenAI released the o1 model.Scaling Test-Time Compute(Extended Reasoning) has become one of the hottest topics in AI circles. To put it simply, instead of piling up computing power in the pre-training or post-training phase, it is better to spend more computational resources in the inference phase (i.e., when the large language model generates output). o1 The model splits a large problem into a series of small problems (i.e., Chain-of-Thought), so that the model can think like a human being step-by-step to evaluate different possibilities, do more detailed planning, reflect on itself before giving an answer, etc. The model can also be used for the calculation of the answer. The model is allowed to think like a human, evaluating different possibilities, doing more detailed planning, reflecting on itself before giving an answer, etc. In this way, the model does not need to be re-trained, and the performance can be improved only by additional computation during reasoning.Instead of rote memorization, the model should be made to think more-- This strategy is particularly effective in complex reasoning tasks with significant improvement in results, and Alibaba's recent release of the QwQ model confirms this technological trend: improving model capabilities by expanding the computation at reasoning time.
👩🏫 In this paper, Scaling refers to increasing computational resources (e.g., arithmetic or time) in the reasoning process. It does not refer to horizontal scaling (distributed computing) or accelerated processing (reduced computation time).

If you have also used the o1 model, you will definitely feel that multi-step reasoning is more time-consuming because the model needs to build chains of thought to solve the problem.
At Jina AI, we focus more on Embeddings and Rerankers than on Large Language Models (LLMs.) So, naturally, we came up with the idea:Is it possible to apply the concept of "chain of thought" to the Embedding model as well?
While it may not be intuitive at first glance, this paper explores a new perspective and demonstrates how Scaling Test-Time Compute can be applied to thejina-clipin order to provide a better understanding of Tricky Out Of Domain (OOD) Images Categorize to solve otherwise impossible tasks.
We experimented with Pokémon recognition, which is still quite challenging for vector models. a model like CLIP, although strong in image-text matching, tends to roll over when it encounters out-of-domain (OOD) data that the model has not seen before.
However, we found thatBy increasing the model inference time and using a chain-of-thinking-like multi-objective classification strategy, the classification accuracy of out-of-domain data can be improved without the need to adjust the model.
Case Study: Pokémon Image Categorization
🔗 Google Colab: https://colab.research.google.com/drive/1zP6FZRm2mN1pf7PsID-EtGDc5gP_hm4Z#scrollTo=CJt5zwA9E2jB
We used the TheFusion21/PokemonCards dataset, which contains several thousand Pokemon card images.This is an image classification task, input a cropped Pokémon deck (with the text description removed) and output the correct Pokémon name. But this is difficult for the CLIP Embedding model for several reasons:
- Pokémon names and looks are relatively new to the model, and it's easy to roll over with direct categorization.
- Each Pokémon has its own visual characteristics, such as shapes, colors, and poses, which are better understood by CLIP.
- The style of the cards is uniform, thoughBut the different backgrounds, poses and drawing styles add to the difficultyThe
- This task requiresConsider multiple visual features simultaneously, like the complex chain of thought in LLM.

We've removed all the textual information (title, footer, description) from the cards, lest the models cheat and find the answers directly from the text, since the labels of these Pokémon classes are their names, such as Absol, Aerodactyl.
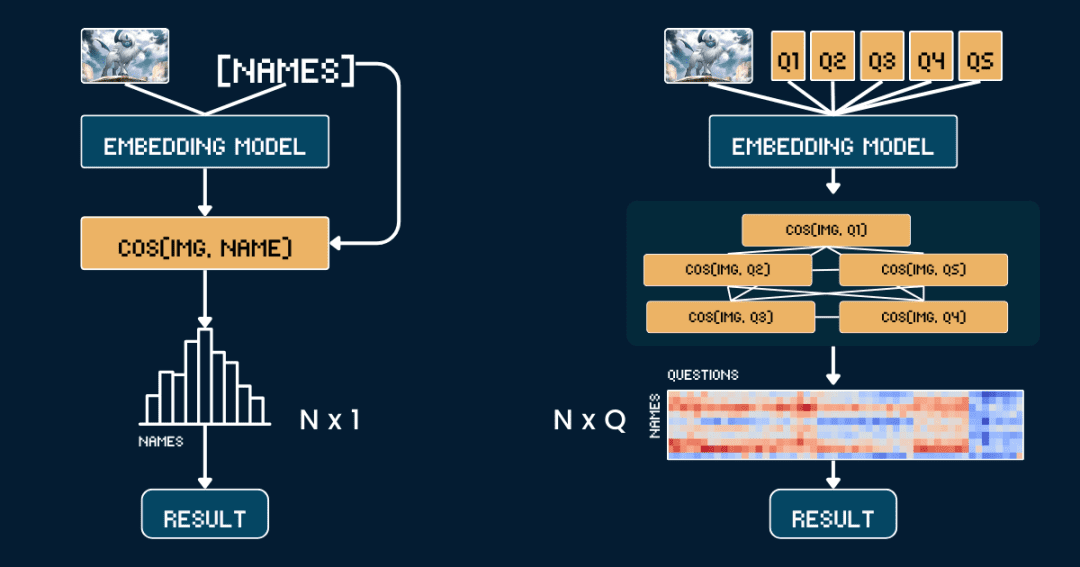
Benchmarking method: direct similarity comparison
Let's start with the simplest baseline methodology, the Direct comparison of similarity between Pokémon pictures and namesThe
First, it is better to remove all textual information from the cards, so that the CLIP model does not have to guess the answer directly from the text. Then, we use the jina-clip-v1 cap (a poem) jina-clip-v2 The model encodes the image and the Pokémon name separately to get their respective vector representations. Finally, the cosine similarity between the image vectors and the text vectors is computed, and whichever name has the highest similarity is considered to be which Pokémon the picture is.
This approach is equivalent to doing a one-to-one match between the image and the name, without taking into account any other contextual information or attributes. The following pseudo-code briefly describes the process.
# 预处理 cropped_images = [crop_artwork(img) for img in pokemon_cards] # 去掉文字,只保留图片 pokemon_names = ["Absol", "Aerodactyl", ...] # 宝可梦名字# 用 jina-clip-v1 获取 embeddings image_embeddings = model.encode_image(cropped_images) text_embeddings = model.encode_text(pokemon_names) # 计算余弦相似度进行分类 similarities = cosine_similarity(image_embeddings, text_embeddings) predicted_names = [pokemon_names[argmax(sim)] for sim in similarities] # 哪个名字相似度最高,就选哪个 # 评估准确率 accuracy = mean(predicted_names == ground_truth_names)
Advanced: applying chains of thought to image categorization
This time, instead of matching pictures and names directly, we split the Pokémon identification into several parts, just like playing "Pokémon Connect".
We defined five sets of key attributes: primary color (e.g., "white", "blue"), primary form (e.g., "a wolf", "a winged reptile"), key features (e.g., "a white horn", "large wings"), body size (e.g., "four-legged wolf-like", "a wolf-like"), and key attributes (e.g., "a white horn", "large wings"). ", "winged and slender"), and background scenes (e.g., "outer space", "green forest").
For each set of attributes, we designed a special cue word, such as "This Pokémon's body is primarily {}-colored", and then filled in the possible options.Next, we use the model to calculate the similarity scores for the image and each option, and convert the scores to probabilities using the softmax function, which gives a better measure of the model's confidence.
The complete chain of thought (CoT) consists of two parts:classification_groups cap (a poem) pokemon_rules, the former defines the questioning framework: each attribute (e.g., color, form) corresponds to a question template and a set of possible answer options. The latter documents which options should be matched for each Pokémon.
For example, Absol's color should be "white" and its form should be "wolf". We'll talk about how to build a complete CoT structure later, and the pokemon_system below is a concrete example of a CoT:
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
In short, instead of simply comparing similarities once, we now make multiple comparisons, combining the probabilities of each attribute so that we can make a more reasonable judgment.
# 分类流程
def classify_pokemon(image):
# 生成所有提示
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# 获取向量及其相似度
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# 将相似度转换为每个属性组的概率
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# 根据匹配的属性计算每个宝可梦的得分
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get) # 返回得分最高的宝可梦
Complexity analysis of the two methods
Now let's analyze the complexity, suppose we want to find the name that best matches the given image among N Pokémon names:
The baseline method requires the computation of N text vectors (one for each name) as well as 1 image vector, followed by N similarity calculations (image vectors are compared to each text vector).Therefore, the complexity of the benchmark method mainly depends on the number of computations N of the text vectors.
And our CoT method needs to compute Q text vectors, where Q is the total number of all question-option combinations, and 1 picture vector. After that, Q similarity calculations (comparison of picture vectors with text vectors for each question-option combination) need to be performed.Therefore, the complexity of the method depends mainly on Q.
In this example, N = 13 and Q = 52 (5 groups of attributes with an average of about 10 options per group). Both methods need to compute image vectors and perform classification steps, and we round off these common operations in the comparison.
In the extreme case, if Q = N, then our method effectively degenerates into a benchmark method. So, the key to effectively extending the inference-time computation is:
Design the problem to increase the value of Q. Make sure each question provides useful clues to help us narrow it down. It is best not to have duplicate information between questions to maximize information gain.
Results
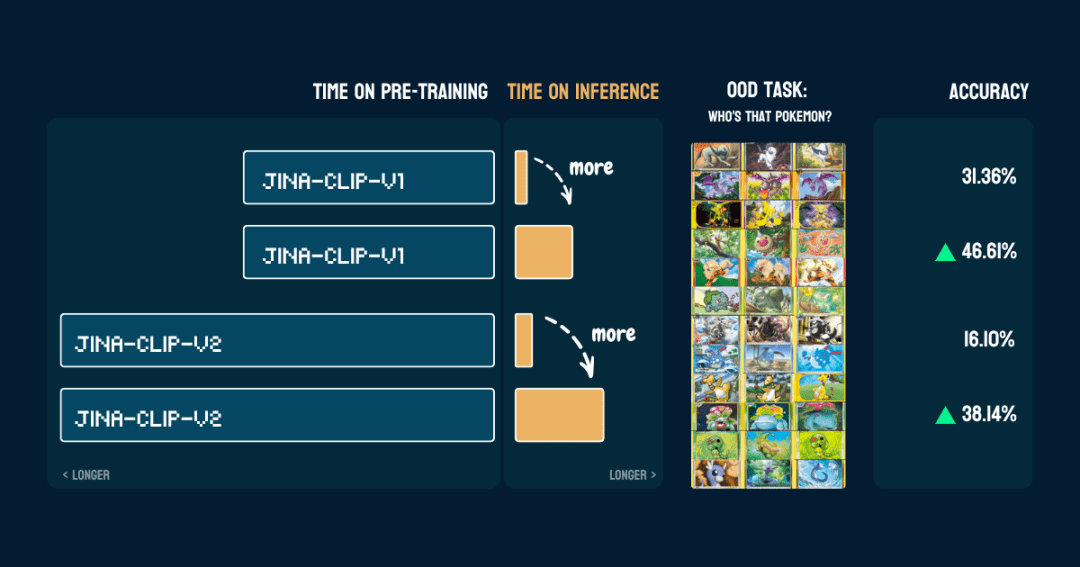
We evaluated it on 117 test images containing 13 different Pokémon. The accuracy results are as follows:

It also shows that oncepokemon_systemIt's built.The same CoT can be used directly on a different model without changing the code and without fine-tuning or additional training.
Interesting.jina-clip-v1The model's base accuracy on Pokémon classification is then higher (31.36%) because it was trained on the LAION-400M dataset containing Pokémon data. While jina-clip-v2The model was trained on DFN-2B, which is a higher quality dataset, but also filters out more data and probably removes Pokémon-related content as well, so it has a lower base accuracy (16.10%).
Wait, how does this method work?
👩🏫 Let's review what we did.
We started out with fixed pre-trained vector models that couldn't handle out-of-distribution (OOD) problems with zero samples. But when we built a classification tree, they suddenly could do it. What is the secret to this? Is it something along the lines of weak learner integration in traditional machine learning? It's worth noting that our vector model can be upgraded from "bad" to "good" not because of integrated learning per se, but because of the external domain knowledge contained in the classification tree. You can repeatedly classify thousands of questions with zero samples, but if the answers don't contribute to the final result, it's meaningless. It's like a game of "you tell me, I guess" (twenty questions), where you need to progressively narrow down the solution with each question. Thus, it is this external knowledge or thought process that is the key- As in our example, the key is how the Pokemon system is built.This expertise can come from humans or from large language models.
pokemon_systemquality ofTheThere are many ways to build this CoT system, from manual to fully automated, each with its own advantages and disadvantages.1. Manual construction
2. LLM-assisted construction
我需要一个宝可梦分类系统。对于以下宝可梦:[Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...],创建一个包含以下内容的分类系统:
1. 基于以下视觉属性的分类组:
- 宝可梦的主要颜色
- 宝可梦的形态
- 宝可梦最显著的特征
- 宝可梦的整体体型
- 宝可梦通常出现的背景环境
2. 对于每个分类组:
- 创建一个自然语言提示模板,用 "{}" 表示选项
- 列出所有可能的选项
- 确保选项互斥且全面
3. 创建规则,将每个宝可梦映射到每个属性组中的一个选项,使用索引引用选项
请以 Python 字典格式输出,包含两个主要部分:
- "classification_groups": 包含每个属性的提示和选项
- "pokemon_rules": 将每个宝可梦映射到其对应的属性索引
示例格式:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color.",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # "white" 的索引
...
},
...
}
}
LLM quickly generates a first draft, but it also requires manual checking and corrections.
A more reliable approach would be Combining LLM generation and manual validation. The LLM is first allowed to generate an initial version, then manually checks and modifies the attribute groupings, options, and rules, and then feeds the modifications back to the LLM for continued refinement until it is satisfied. This approach balances efficiency and accuracy.
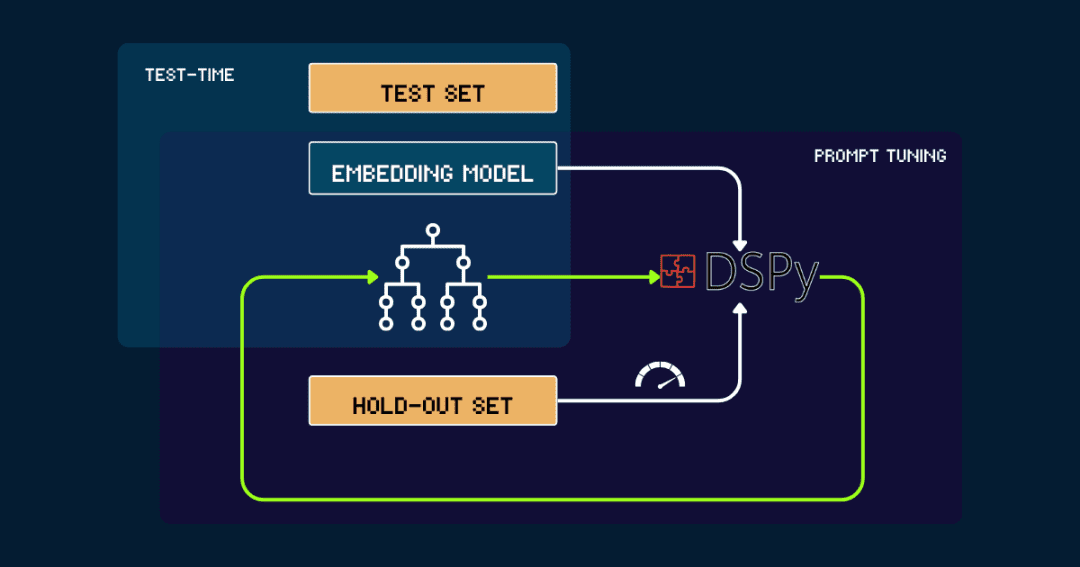
3. Automated builds with DSPy
For fully automated builds pokemon_system, which can be optimized iteratively with DSPy.
Let's start with a simple pokemon_system start, either manually created or generated by LLM. It is then evaluated with data from the leaveout set, signaling the accuracy to DSPy as feedback.DSPy will use this feedback to generate a new pokemon_system, repeating this cycle until performance converges and there is no longer a significant improvement.
The vector model is fixed throughout the process. With DSPy the optimal pokemon_system (CoT) design can be found automatically and only needs to be tuned once per task.
Why Scaling Test-Time Compute on Vector Models?
It's too expensive to carry because of the constant increase in the size of pre-trained models.
Jina Embeddings collection fromjina-embeddings-v1,v2,v3 until (a time) jina-clip-v1,v2And jina-ColBERT-v1,v2, each upgrade relies on larger models, more pre-trained data, and increasing costs.
takejina-embeddings-v1For a June 2023 release, with 110 million parameters, training will cost $5,000 to $10,000 dollars. By the time jina-embeddings-v3, the performance has improved a lot, but it is still mainly by smashing money and piling up resources. Now, the training cost of top models has risen from several thousand dollars to tens of thousands of dollars, and large companies even have to spend hundreds of millions of dollars. Although the more investment in pre-training, the better the model results, but the cost is too high, the cost-effective is getting lower and lower, the development of the ultimate need to consider sustainability.
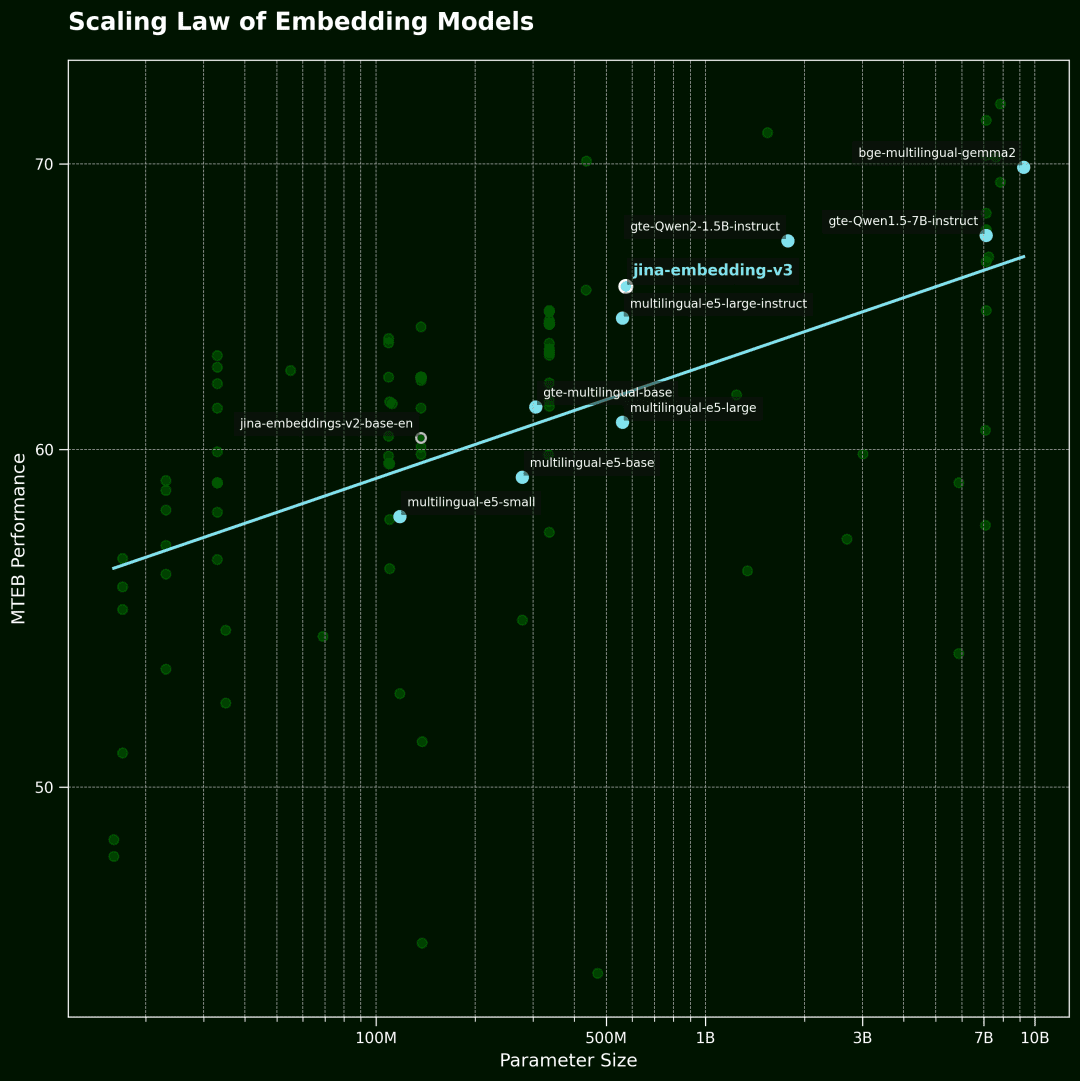
vector model of Scaling Law
This figure then shows the vector model of Scaling Law.The horizontal axis is the number of model parameters and the vertical axis is the average performance of the MTEB. Each point represents a vector model. The trend line represents the average of all models, and the blue points are multilingual models.
The data were selected from the top 100 vector models in the MTEB rankings. To ensure the quality of the data, we filtered out models that did not disclose model size information and some invalid submissions.
On the other hand, vector models are now very powerful: multilingual, multitasking, multimodal, with excellent zero-sample learning and instruction-following capabilities.This versatility opens up a great deal of imaginative possibilities for algorithmic improvements and extensions of the computation at the time of inference.
The key question is:How much are users willing to pay for a query they really care about? If simply making the inference of a fixed pre-trained model take a little longer can dramatically improve the quality of the results, I believe many people will find it worthwhile.
In our opinion.Extended inference-time computation holds great untapped potential in the field of vector modeling, which will probably be an important breakthrough for future research.Instead of striving for a bigger model, it is better to put more effort in the inference phase and explore more ingenious computational methods to improve performance -- This may be a more economical and efficient route.
reach a verdict
exist jina-clip-v1/v2 In the experimental performance, we observed the following key phenomena:
we On data not seen by the model and outside the domain (OOD)(math.) genusBetter recognition accuracies were achieved and no fine-tuning or additional training of the model was performed at all. The system is operated through the Iteratively refining similarity search and classification criteria, realizing the ability to make finer distinctions. by introducing Dynamic Cue Tuning and Iterative Reasoning(analogous to a "chain of thought"), we transform the reasoning process of the vector model from a single query to a more complex chain of thought.
This is just the beginning! The potential of Scaling Test-Time Compute goes far beyond this!, there is still vast space to be explored. For example, we can develop more efficient algorithms to narrow the answer space by iteratively choosing the most efficient strategy, similar to the strategy of optimal solutions in the 'twenty questions' game. By expanding reasoning-time computation, we can push vector models beyond existing bottlenecks, unlocking complex and fine-grained tasks that once seemed out of reach, and pushing these models into broader applications.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...