How to choose the right Embedding model?

Retrieval Augmented Generation (RAG) is a class of applications in Generative AI (GenAI) that supports the use of one's own data to augment the knowledge of an LLM model (e.g., ChatGPT).
RAG Three different AI models are commonly used, namely the Embedding model, the Rerankear model, and the Big Language model. In this article, we will cover how to choose the right Embedding model based on your data type as well as language or specific domain (e.g., legal).
1. Text data: MTEB ranking
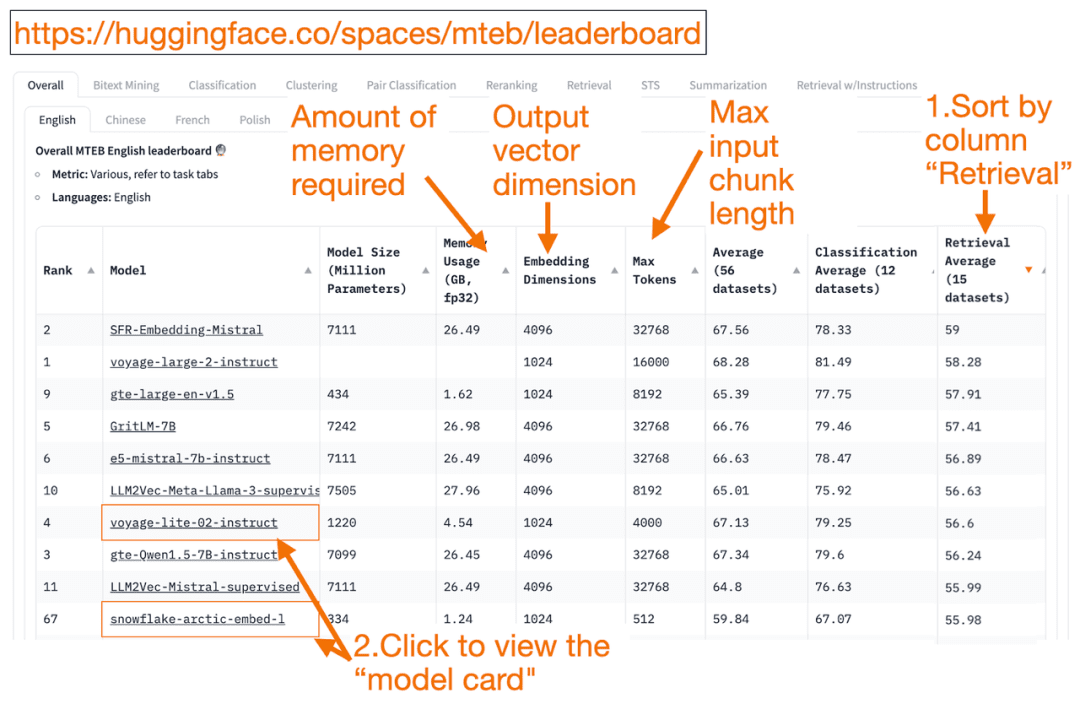
HuggingFace MTEB leaderboard is a one-stop list of text embedding models! You can find out the average performance of each model.
You can sort the "Retrieval Average" column in descending order, as this best fits the vector search task. Then, look for the highest ranked model with the smallest memory footprint.
- The Embedding vector dimension is the length of the vector, i.e. y in f(x)=y, which the model will output.
- greatest Token The number is the length of the input text block, i.e., x in f(x)=y , that you can enter into the model.
In addition to passing Retrieval In addition to task sorting, you can also filter by the following criteria:
- Languages: French, English, Chinese, Polish are supported. (e.g.: task=retrieval.
Language=chinese)
- Texts in the legal field.
(e.g. task=retrieval, language=law)
It is worth noting that since some of the training data has only recently become publicly available, some of the Embedding models on the MTEB may beseemingly suitableHowever, actual unsuitable models with inflated rankings may actually perform differently. As a result, HuggingFace has posted ablog (loanword)This section describes the key points for determining whether a model's ranking is credible or not. After clicking on a model link (called a "model card"):
- Look for blogs and papers that explain how models are trained and evaluated. Look closely at the language, data, and tasks used for model training. Also, look for models created by well-known companies. For example, on the voyage-lite-02-instruct model card, you'll see other VoyageAI models listed, but not this one. This is a hint! This model is an overfitting model and should not be used!
- In the screenshot below, I'll try the new model "snowflake-arctic-embed-1" from Snowflake because it's highly ranked, small enough to run on my laptop, and has links to blogs and papers on the model card.
The advantage of using HuggingFace is that if you need to change the model after selecting the Embedding model, you only need to change the model_name in the code!
import torch
from sentence_transformers import SentenceTransformer
# Initialize torch settings
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Load the model from Huggingface
model_name = "WhereIsAI/UAE-Large-V1" # Just change model_name to use a different model!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Get the model parameters and save for later
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Print model parameters
print(f"model_name: {model_name}")
print(f"EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f"MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

2. Image data: ResNet50
Sometimes you may want to search for images that are similar to the entered image. For example, you may be looking for more images of Scottish Fold Cats. In this case, you can upload a picture of a Scottish Fold Cat and ask the search engine to find similar images.
ResNet50 is a popular CNN model originally trained by Microsoft in 2015 using ImageNet data.
Similarly, forVideo SearchIn this case, ResNet50 can still convert the video into Embedding vectors. Then, a similarity search is performed on the static video frames and the most similar video is returned to the user as the best match.
3. Audio data: PANNs
Similar to image search, you can also search for similar audio based on input audio clips.
PANNs(Pre-trained Audio Neural Networks) are commonly used as Embedding models for audio search because PANNs are pre-trained on large-scale audio datasets and excel at tasks such as audio classification and labeling.
4. multimodal image and text data:
SigLIP or Unum
In recent years, a number of Embedding models trained on a mixture of unstructured data (text, images, audio or video) have emerged. These models are able to capture the semantics of multiple types of unstructured data simultaneously in the same vector space.
The multimodal Embedding model supports searching for images using text, generating text descriptions for images, or searching for images.
OpenAI in 2021 CLIP is the standard Embedding model. But because it was difficult to use because it required users to fine-tune themselves, by 2024 Google introduced the SigLIP(Sigmoidal-CLIP). The model achieves good performance when using zero-shot prompt.
Small LLM models are becoming increasingly popular today. This is because these models do not require large cloud clusters and can run on laptops. Smaller models take less memory, have lower latency and run faster than larger models.Unum Multimodal mini-Embedding models are provided.
5. Multi-modal text, audio and video data
Most multimodal text-to-audio RAG systems use multimodal generative LLMs, which first convert sound to text, generate sound-text pairs, and then convert the text to Embedding vectors. You can then use the RAG to retrieve the text as usual. In the last step, the text is mapped back to audio.
OpenAI Whisper can transcribe speech to text. In addition, OpenAI's Text-to-speech (TTS) The model can also convert text to audio.
The multimodal text-video RAG system uses a similar approach to first map video to text, convert it to an Embedding vector, search the text, and return the video as the search result.
OpenAI Sora Text can be converted to video. Similar to Dall-e, you provide text prompts while LLM generates video.Sora can also generate video from still images or other videos.
Milvus has now integrated the mainstream Embedding model, welcome to experience it:https://milvus.io/docs/embeddings.md
consultation
MTEB leaderboard: https://huggingface.co/spaces/mteb/leaderboard
MTEB Best Practices: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Similar image searches: https://milvus.io/docs/image_similarity_search.md
Image video search: https://milvus.io/docs/video_similarity_search.md
Similar audio searches: https://milvus.io/docs/audio_similarity_search.md
Text image search: https://milvus.io/docs/text_image_search.md
2024 SigLIP (sigmoid loss CLIP) Paper: https://arxiv.org/pdf/2401.06167v1
Unum Multimodal Embedding Model:
https://github.com/unum-cloud/uform
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...