R1-Omni: an open source model for analyzing emotions through video and audio

General Introduction
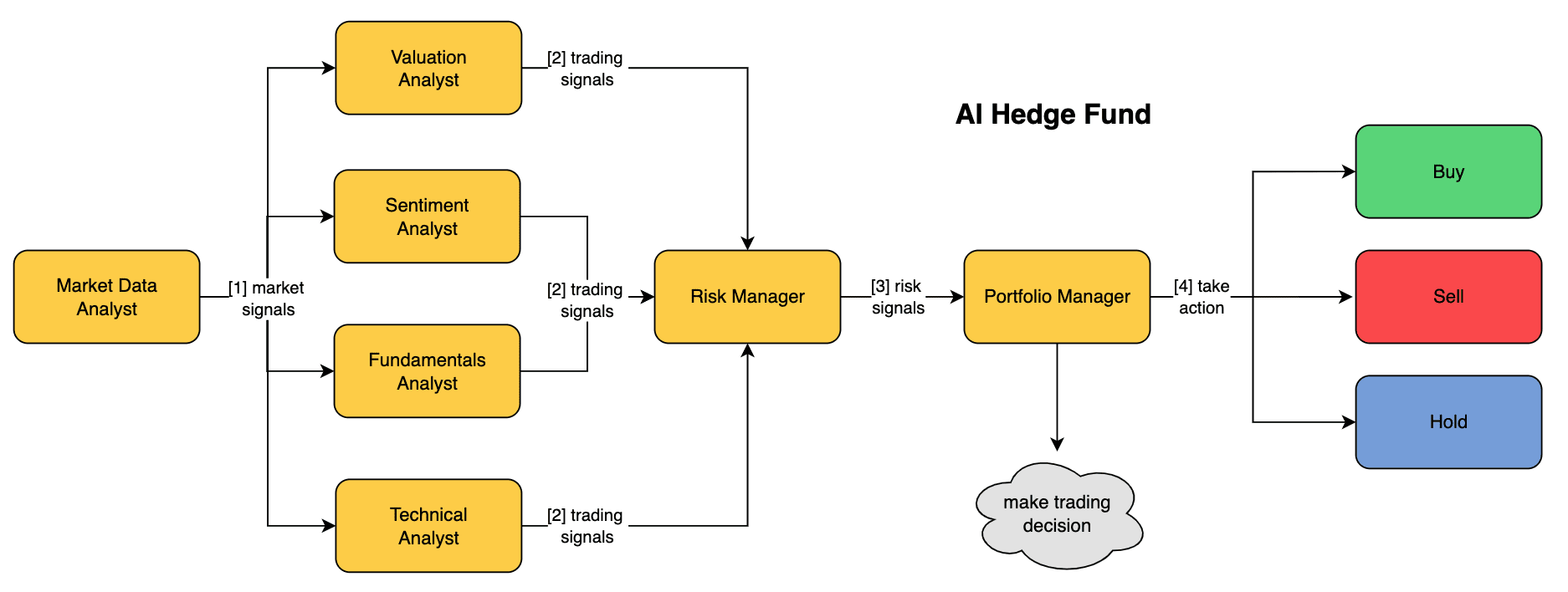
R1-Omni is an open source project launched on GitHub by the HumanMLLM team. It is the first to apply reinforcement learning with verifiable rewards (RLVR) techniques to a multimodal large language model, focusing on emotion recognition. The project analyzes video and audio data to recognize a character's emotions, such as anger, happiness, or surprise. It is developed with HumanOmni-0.5B as the base model and provides free code and model downloads for researchers and developers.R1-Omni performs well on datasets such as DFEW, MAFW, etc., and understands emotions more accurately especially in complex scenes. The project is still being continuously updated, and plans to open more training data and features.

Function List
- emotion recognition: Analyze video and audio to determine a character's emotional state, such as anger, happiness, surprise, etc.
- multimodal processing: Combining visual and auditory data to improve the accuracy of emotion recognition.
- Enhanced Learning Optimization: Enhancing model inference and adaptation through RLVR techniques.
- Model Download: HumanOmni-0.5B, EMER-SFT, MAFW-DFEW-SFT and R1-Omni models are available.
- Open Source Support: Open source code and partial datasets to support secondary development by users.
- Performance: Provides test results on multiple datasets to facilitate user evaluation of effectiveness.
Using Help
Installation and environment setup
The use of the R1-Omni requires a certain level of skill. The following are the detailed installation steps:
1. System requirements
- operating system: Support for Linux, Windows or macOS.
- Python version: Python 3.8 or above is recommended.
- Hardware Support: NVIDIA GPUs are recommended (if acceleration is required), CPUs can also be run.
- Tool Preparation: You need to install Git to download the code.
2. Access to code
Enter the following command in the terminal to download the code for R1-Omni:
git clone https://github.com/HumanMLLM/R1-Omni.git
cd R1-Omni
3. Configuration environment
R1-Omni is developed based on the R1-V framework, please refer to the R1-V repository for environment setup. The steps are as follows:
- Create a virtual environment:
python -m venv venv
source venv/bin/activate # Linux/macOS
venv\Scripts\activate # Windows
- Installation of dependency packages: The following version is officially recommended, enter the command to install it:
pip install torch==2.5.1+cu124 torchvision==0.20.1+cu124 torchaudio==2.5.1+cu124 -f https://download.pytorch.org/whl/torch_stable.html
pip install transformers==4.49.0 flash-attn==2.7.4
Note: Make sure that the NVIDIA driver version is not lower than 535.54. For a complete list of dependencies, refer to the R1-V repository.
4. Download model
R1-Omni offers several model versions that can be downloaded from Hugging Face or ModelScope. Take Hugging Face as an example:
- interviews Hugging Face R1-OmniThe
- downloading
R1-Omni-0.5Bmodel, save it to a local path such as/path/to/models/R1-Omni-0.5BThe - Download Dependency Modeling:
- Audio Modeling:whisper-large-v3Save to
/path/to/models/whisper-large-v3The - Visual modeling:siglip-base-patch16-224Save to
/path/to/models/siglip-base-patch16-224The
5. Modification of configuration files
exist R1-Omni-0.5B Find in the folder config.json, open it with a text editor and modify the following two lines:
"mm_audio_tower": "/path/to/models/whisper-large-v3",
"mm_vision_tower": "/path/to/models/siglip-base-patch16-224"
Save and close the file.
Functional operation flow
1. Emotion recognition reasoning
Provided by R1-Omni inference.py Script for analyzing the sentiment of a single video. The steps of the operation are as follows:
- Prepare the video file (e.g.
video.mp4), make sure there's picture and sound. - Runs in the terminal:
python inference.py --modal video_audio \ --model_path /path/to/models/R1-Omni-0.5B \ --video_path video.mp4 \ --instruct "As an emotional recognition expert; throughout the video, which emotion conveyed by the characters is the most obvious to you? Output the thinking process in <think> </think> and final emotion in <answer> </answer> tags." - Example output:
<think>视频中一名男子站在彩色壁画前,穿棕色夹克,眉头紧皱,嘴巴张开,表情显得激动。音频中有“降低声音”和“别慌”的词语,语速快且语气紧张。综合分析,他的情绪是愤怒和不安。</think> <answer>angry</answer>
2. Testing model performance
Model performance has been officially tested on the DFEW, MAFW, and RAVDESS datasets. Users can download these datasets (see DFEW official website or MAFW official website) and then verify the local effects with the above commands. The comparison data are as follows:
- R1-Omni reaches 65.831 TP3T on DFEW (WAR), which is better than HumanOmni-0.5B's 22.641 TP3T.
3. Customized training
- Cold Start Training: Initialize the model based on the Explainable Multimodal Emotion Reasoning (232 samples) and HumanOmni (348 samples) datasets. Example data format:
[{"video": "MER24/sample_00000967.mp4", "conversations": [{"from": "human", "value": "<video>\n<audio>\n请识别视频中的主要情绪"}, {"from": "gpt", "value": "<think>视频中一名男子在打电话,眉头紧皱,语速快,语气紧张,表现出焦虑。</think>\n<answer>anxious</answer>"}]}]The data is not yet fully open source, so keep an eye on GitHub for updates.
- RLVR training: Using the MAFW and DFEW datasets (15,306 videos in total). Example data format:
[{"video": "DFEW/videos/1.mp4", "conversations": [{"from": "human", "value": "<video>\n<audio>\n请识别视频中的主要情绪"}, {"from": "gpt", "value": "sad"}]}]Training details are pending further official clarification.
caveat
- Video Request: Supports formats such as MP4, and must contain clear picture and audio.
- Model Selection: R1-Omni is the final version with optimal performance; other models are available for comparison experiments.
- Technical Support: Issues can be submitted on GitHub, and the team will continue to improve the documentation.
With the above steps, users can quickly install and use R1-Omni to experience its emotion recognition feature.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...