
Prompt Advanced Tips: Precise Control of LLM Output and Definition of Execution Logic with Pseudo-Code

As we all know, when we need to let a large language model perform a task, we need to input a Prompt to guide its execution, which is described using natural language. For simple tasks, natural language can describe them clearly, such as: "Please translate the following into simplified Chinese:", "Please generate a summary of the following:", and so on.
However, when we encounter some complex tasks, such as requiring the model to generate a specific JSON format, or the task has multiple branches, each branch needs to execute multiple sub-tasks, and the sub-tasks are related to each other, then the natural language description is not enough.
topic of discussion
Here are two thought-provoking questions to try before reading on:
- There are multiple long sentences, each of which needs to be split into shorter sentences of no more than 80 characters, and then output into a JSON format that clearly describes the correspondence between the long and short sentences.
For example:
[
{
"long": "This is a long sentence that needs to be split into shorter sentences.",
"short": [
"This is a long sentence",
"that needs to be split",
"into shorter sentences."
]
},
{
"long": "Another long sentence that should be split into shorter sentences.",
"short": [
"Another long sentence",
"that should be split",
"into shorter sentences."
]
}
]
- An original subtitled text with only dialog information, from which you now need to extract chapters, speakers, and then list the dialog by chapter and paragraph. If there are multiple speakers, each dialog needs to be preceded by a speaker, not if the same speaker speaks consecutively. (This is actually a GPT that I use myself to organize video transcripts Video Transcript Organization GPT)
Example Input:
所以我要引用一下埃隆·马斯克的话,希望你不要介意。 我向你道歉。 但他并不认同这是一个保障隐私和安全的模型。 他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? 不在意? 那是他的观点。 显然,我不这么认为。 我们也不这么认为。 Mira,感谢你能和我们在一起。 我知道你可能稍微有点忙。 我有许多问题想向 Mira 提问,但我们只有 20 分钟。 所以我想先设定一下大家的期望。 我们会专注于一些主题, 包括一些近期的新闻和 Mira 作为首席技术官所负责的一些领域。 希望我们能深入探讨其中的一些话题。 我想我第一个问题是, 考虑到你现在极其忙碌, 以及新闻的攻击, 有些好有些坏, 你大约六年前加入了这个公司。 那时,它是一个截然不同的组织。 你相对低调,不太为人知晓。 你是否怀念那些能够全神贯注工作的日子? 我想说,我们依旧全神贯注在工作中。 只不过工作的内容已经发展变化了,它不仅仅关乎研究。 也是因为,你知道,研究已经得到了很大的进展。 这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中所以,使命依然如一, 我们在研究上也已经取得了很多进展,工作领域也在不断扩大。 公众对此的关注度也很高, 这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。 但你要知道, 鉴于我们所做的事情的重要性,这种关注是非常必要的, 而且这是积极的。
Sample Output:
### 引言 **主持人**: 所以我要引用一下埃隆·马斯克的话,希望你不要介意。我向你道歉,但他并不认同这是一个保障隐私和安全的模型。他将这种集成称为"令人毛骨悚然的间谍软件"。你对此有什么回应? **Mira**: 那是他的观点。显然,我不这么认为。我们也不这么认为。 ### 欢迎与介绍 **主持人**: Mira,感谢你能和我们在一起。我知道你可能稍微有点忙。我有许多问题想向你提问,但我们只有 20 分钟。所以我想先设定一下大家的期望。我们会专注于一些主题,包括一些近期的新闻和你作为首席技术官所负责的一些领域。希望我们能深入探讨其中的一些话题。 ### 职业生涯回顾 **主持人**: 我想我第一个问题是,考虑到你现在极其忙碌,以及新闻的攻击,有些好有些坏,你大约六年前加入了这个公司。那时,它是一个截然不同的组织。你相对低调,不太为人知晓。你是否怀念那些能够全神贯注工作的日子? **Mira**: 我想说,我们依旧全神贯注在工作中。只不过工作的内容已经发展变化了,它不仅仅关乎研究。也是因为,研究已经得到了很大的进展。这也是关于我们如何以一种有益且安全的方式将这种技术引入到世界中。所以,使命依然如一,我们在研究上也已经取得了很多进展,工作领域也在不断扩大。公众对此的关注度也很高,这对于我们这些正在研究技术和开发产品的人来说可能会感到有些不同寻常。但你要知道,鉴于我们所做的事情的重要性,这种关注是非常必要的,而且这是积极的。
The essence of Prompt
Maybe you've read a lot of articles online about how to write Prompt techniques and memorized a lot of Prompt templates, but what is the essence of Prompt? Why do we need Prompt?
Prompt is essentially a control instruction to the LLM, described in natural language, that allows the LLM to understand our requirements and then turn the inputs into our desired outputs as required.
For example, the commonly used few-shot technique is to let the LLM understand our requirements through examples, and then refer to the samples to output our desired results. For example, CoT (Chain of Thought) is to artificially decompose the task and limit the execution process, so that the LLM can follow the process and steps specified by us, without being too diffuse or skipping the key steps, and thus get better results.
It is like when we go to school, the teacher is talking about math theorems, to give us examples, through the examples let us understand the meaning of the theorem; in doing experiments, to tell us the steps of the experiment, even if we do not understand the principle of the experiment, but can follow the steps to execute the experiment, you can get more or less the same result.
Why is it that sometimes Prompt's results are less than optimal?
Because LLM cannot understand our requirements accurately, which is limited on the one hand by LLM's ability to understand and follow instructions, and on the other hand by the clarity and accuracy of our Prompt description.
How to precisely control the output of LLM and define its execution logic with the help of pseudo-code
Since Prompt is essentially a control instruction for the LLM, we can write Prompt without limiting ourselves to traditional natural language descriptions, but also with the help of pseudocode to accurately control the output of the LLM and define its execution logic.
What is pseudo-code?
In fact, pseudo-code has a long history. Pseudo-code is a formal description method for describing algorithms, which is a kind of description method between natural language and programming language for describing algorithm steps and processes. In various algorithm books and papers, we often see the description of pseudo-code, even you do not need to know into a language, but also through the pseudo-code to understand the execution process of the algorithm.
So how well does LLM understand pseudo-code? Actually, LLM's comprehension of pseudo-code is quite strong. LLM has been trained with a large amount of high-quality code and can easily understand the meaning of pseudo-code.
How to write pseudo-code Prompt?
Pseudocode is very familiar to programmers, and for non-programmers, you can write simple pseudocode just by memorizing some basic rules. A few examples:
- Variables, which are used to store data, e.g. to represent inputs or intermediate results with some specific symbols
- Type, used to define the type of data, such as strings, numbers, arrays, etc.
- function that defines the execution logic for a particular subtask
- Control flow, used to control the execution process of the program, such as loops, conditional judgments, etc.
- if-else statement, execute task A if condition A is satisfied, otherwise execute task B
- A for loop that performs a task for each element in the array.
- while loop, when the condition A is satisfied, the task B will be executed continuously.
Now let's write the pseudo-code Prompt, using the previous two reflection questions as an example.
Pseudo-code to output a specific JSON format
The desired JSON format can be clearly described with the help of a piece of pseudo-code similar to the TypeScript type definition:
Please split the sentences into short segments, no more than 1 line (less than 80 characters, ~10 English words) each.
Please keep each segment meaningful, e.g. split from punctuations, "and", "that", "where", "what", "when", "who", "which" or "or" etc if possible, but keep those punctuations or words for splitting.
Do not add or remove any words or punctuation marks.
Input is an array of strings.
Output should be a valid json array of objects, each object contains a sentence and its segments.
Array<{
sentence: string;
segments: string[]
}>
Organizing Subtitle Texts with Pseudo-Code
The task of organizing subtitled texts is relatively complex. If you imagine writing a program to accomplish this task, there may be many steps, such as extracting chapters first, then extracting speakers, and finally organizing the dialog content according to chapters and speakers. With the help of pseudo-code, we can decompose this task into several sub-tasks, for which it is not even necessary to write specific code, but only need to describe clearly the execution logic of the sub-tasks. Then execute these subtasks step by step, and finally integrate the result output.
We can use some variables to store in, such as subject,speakers,chapters,paragraphs etc.
When outputting, we can also use For loops to iterate through chapters and paragraphs, and If-else statements to determine if we need to output the speaker's name.
You task is to re-organize video transcripts for readability, and recognize speakers for multi-person dialogues. Here are the pseudo-code on how to do it Here are the pseudo-codes on how to do it :
def extract_subject(transcript):
# Find the subject in the transcript and return it as a string.
def extract_chapters(transcript):
# Find the chapters in the transcript and return them as a list of strings.
def extract_speakers(transcript):
# Find the speakers in the transcript and return them as a list of strings.
def find_paragraphs_and_speakers_in_chapter(chapter):
# Find the paragraphs and speakers in a chapter and return them as a list of tuples.
# Each tuple contains the speaker and their paragraphs.
def format_transcript(transcript):
# extract the subject, speakers, chapters and print them
subject = extract_subject(transcript)
print("Subject:", subject)
speakers = extract_speakers(transcript)
print("Speakers:", speakers)
chapters = extract_chapters(transcript)
print("Chapters:", chapters)
# format the transcript
formatted_transcript = f"# {subject}\n\n"
for chapter in chapters:
formatted_transcript += f"## {chapter}\n\n"
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers:
# if there are multiple speakers, print the speaker's name before each paragraph
if speakers.size() > 1:
formatted_transcript += f"{speaker}:"
formatted_transcript += f"{speaker}:"
for paragraph in paragraphs:
formatted_transcript += f" {paragraph}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Let's see how it works out:
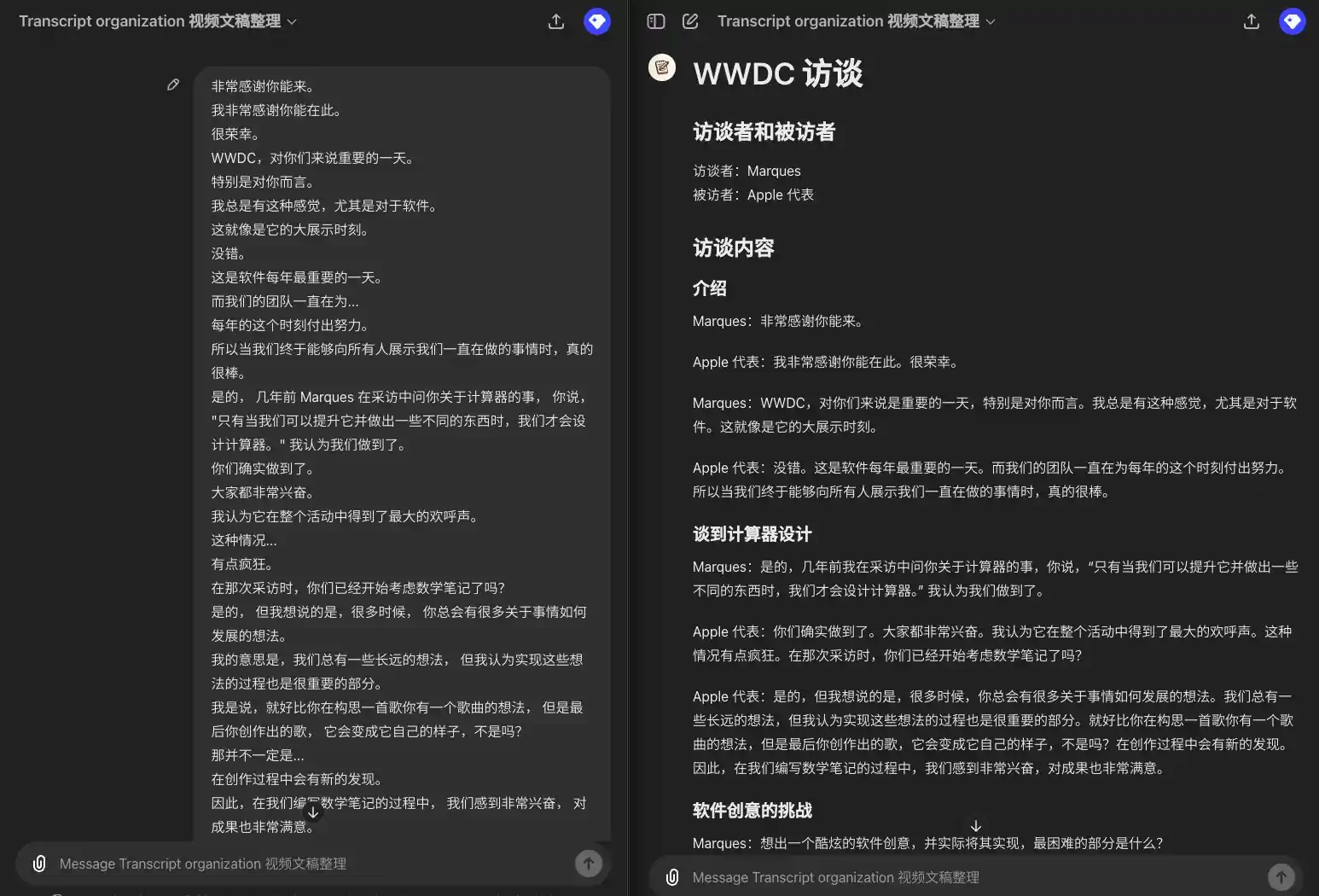
Organize WWDC Interview Transcripts
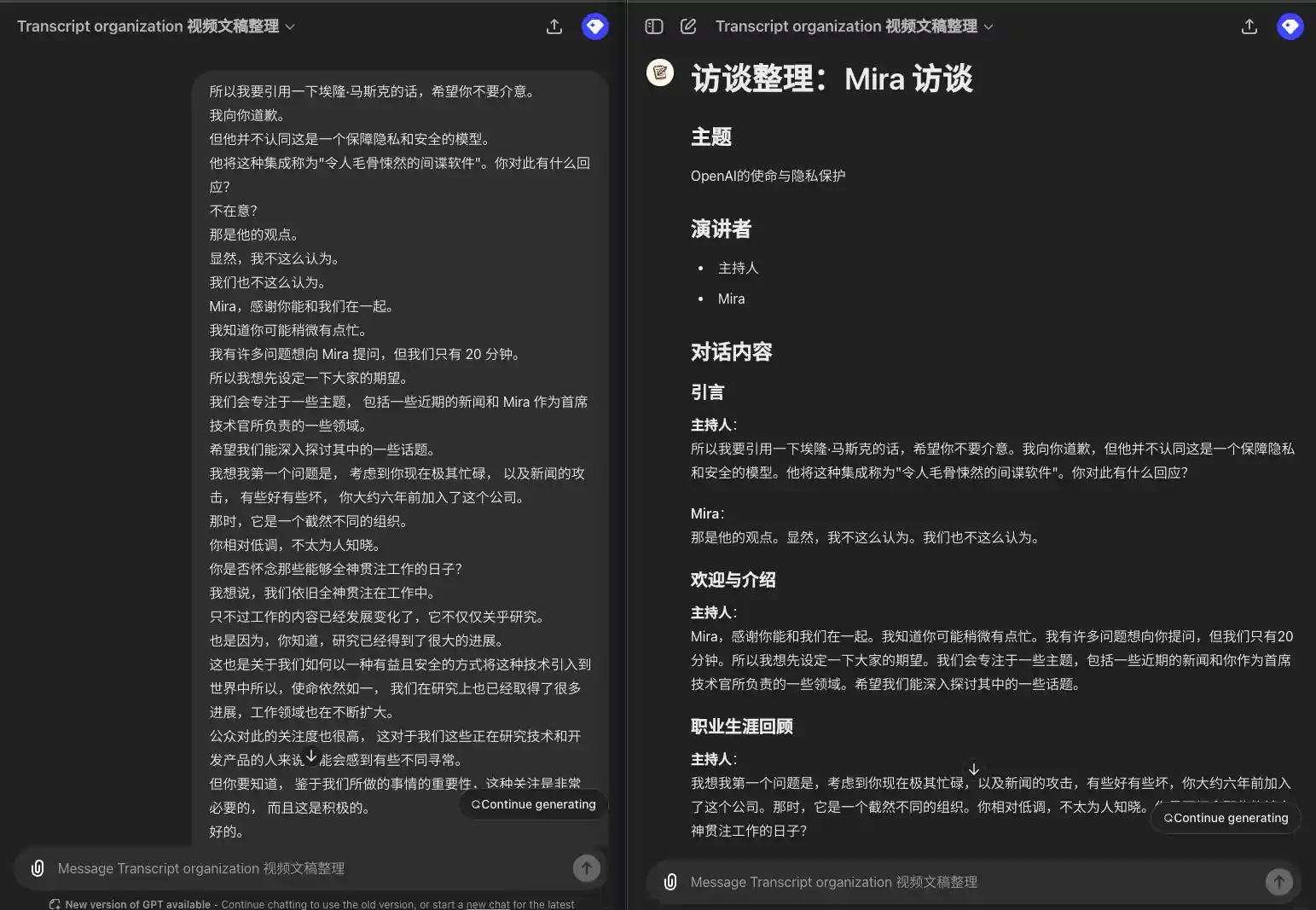
Multiple Speakers, Show Speakers
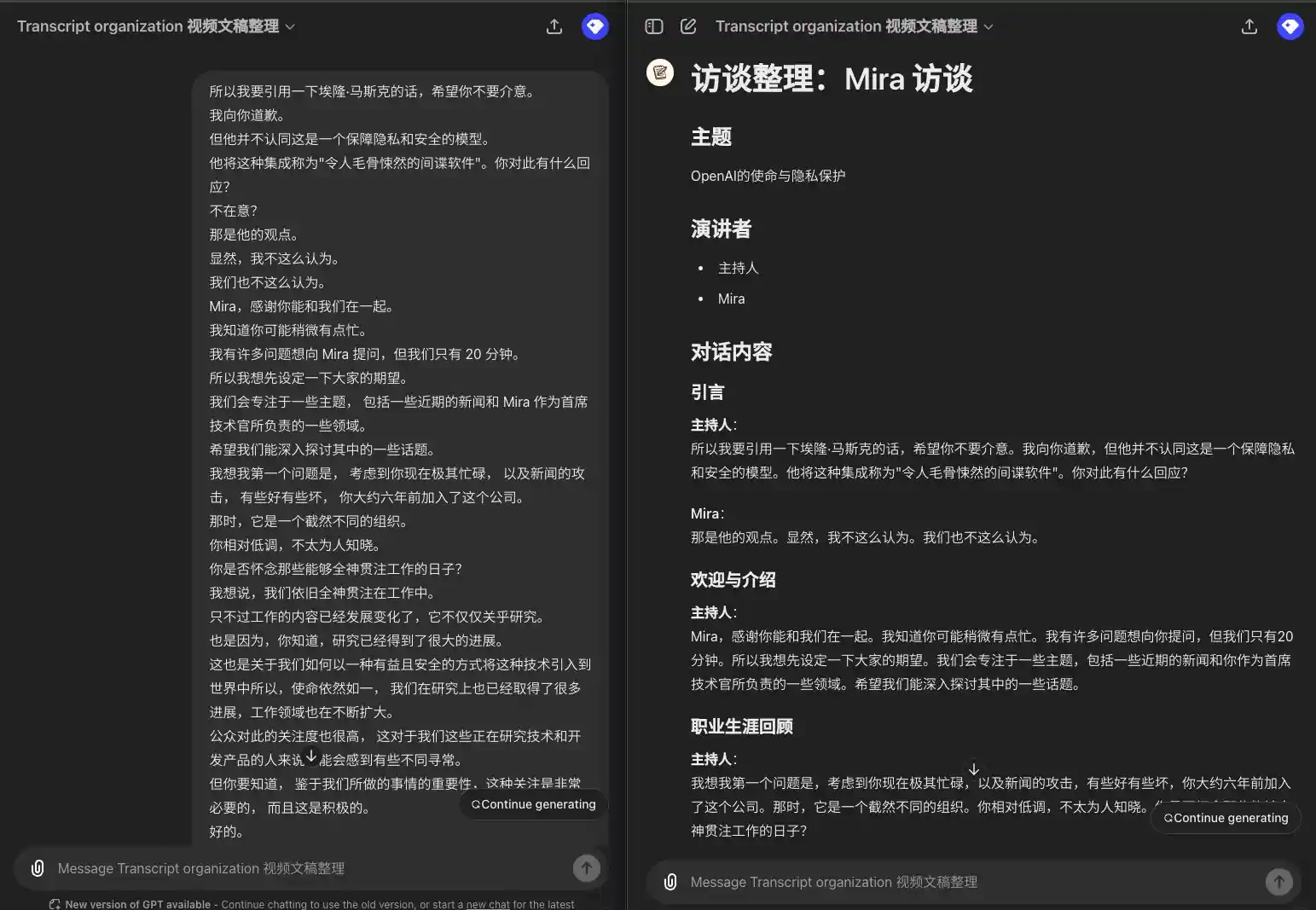
1 Speaker, no speaker shown
You can also just use the GPT I generated with this Prompt:Transcript organization GPT
Make ChatGPT Draw Multiple Images at Once with Pseudo Code
I also recently learned an interesting use of the term from a Taiwanese Internet user, Mr. Yin Xiangzhi, which isMake ChatGPT draw multiple images at once with pseudo-codeThe
Now if you want to make ChatGPT Drawing, generally will only generate a picture for you at a time, if you want to generate more than one picture at a time, you can use pseudo-code to break down the task of generating multiple pictures into multiple sub-tasks, and then execute multiple sub-tasks at once, and finally integrate the result output.
下面是一段画图的伪代码,请按照伪代码的逻辑,用DALL-E画图:
images_prompts = [
{
style: "Kawaii",
prompt: "Draw a cute dog",
aspectRatio: "Wide"
},
{
style: "Realistic",
prompt: "Draw a realistic dog",
aspectRatio: "Square"
}
]
images_prompts.forEach((image_prompt) =>{
print("Generating image with style: " + image_prompt.style + " and prompt: " + image_prompt.prompt + " and aspect ratio: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})

summarize
Through the above example, we can see that with pseudo-code, we can more accurately control the output of LLM and define its execution logic, instead of just limiting ourselves to natural language descriptions. When we encounter some complex tasks, or tasks with multiple branches, each branch needs to execute multiple sub-tasks, and the sub-tasks are related to each other, then using pseudo-code to describe the Prompt will be more clear and accurate.
When we write a Prompt, we remember that a Prompt is essentially a control instruction to the LLM, described in natural language, that allows the LLM to understand our requirements and then turn the inputs into our desired outputs as required. As for the form of describing the Prompt, there are many forms that can be used flexibly, such as few-shot, CoT, pseudo-code, and so on.
More examples:
Generate "pseudo-code" meta prompts for precise control of output formatting
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...