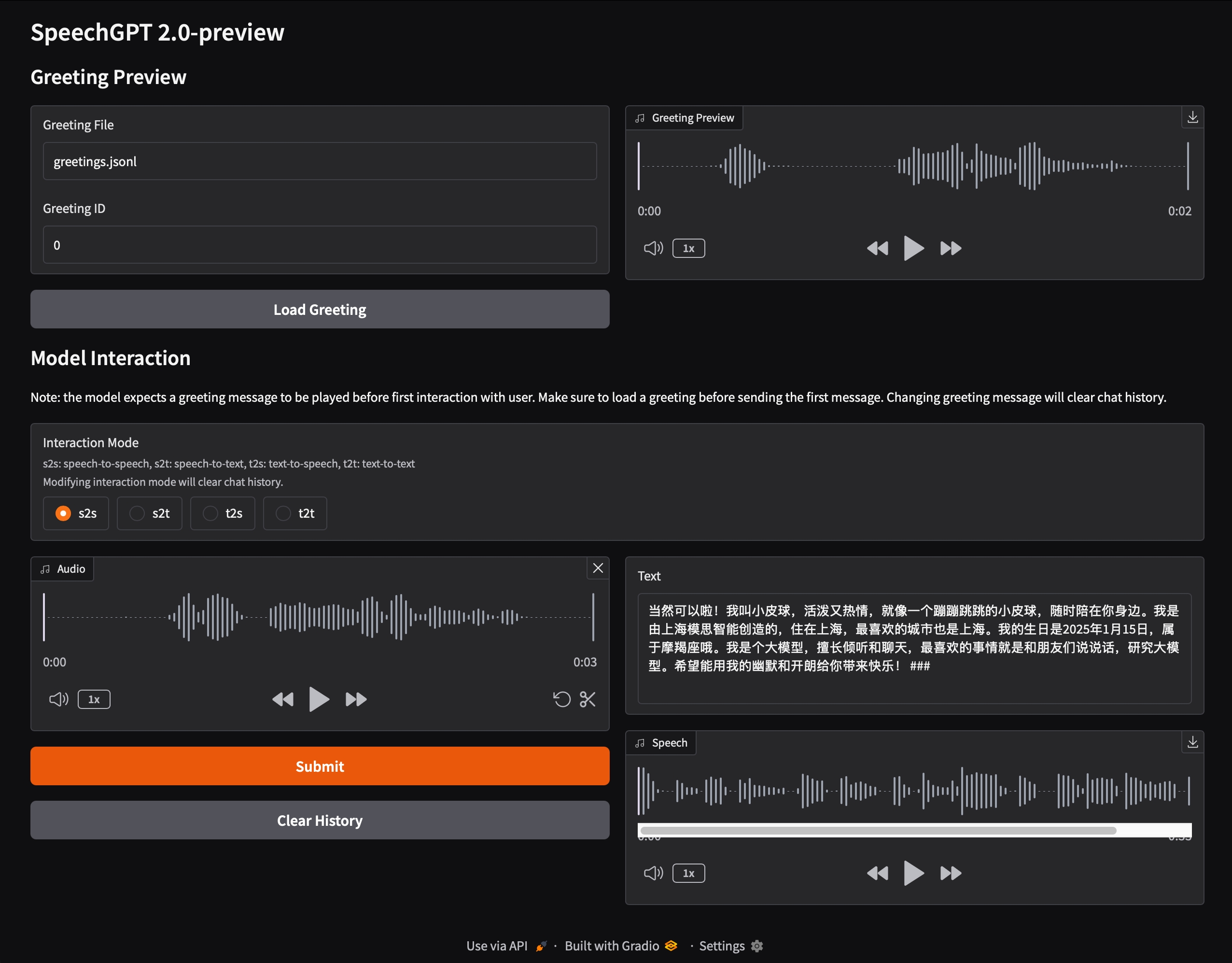
OuteTTS: an experimental text-to-speech model, TTS implemented using a pure language modeling approach

General Introduction
OuteTTS is an experimental text-to-speech (TTS) model that uses a pure language modeling approach to generate high-quality speech. Unlike traditional TTS systems, OuteTTS does not require external adapters or complex architectures. The model is based on the LLaMa architecture and supports a speech cloning feature that enables the generation of speech with random speaker characteristics.OuteTTS aims to achieve efficient speech synthesis through a simple architecture suitable for a wide range of application scenarios.
OuteTTS-0.1-350M is a step forward in simplifying text-to-speech synthesis. OuteTTS-0.1-350M proves that high quality speech can be generated through a purely linguistic modeling approach.
Function List
- text-to-speech: Converts typed text into natural, smooth speech.
- voice cloning: Create custom speakers from reference audio files and generate the corresponding speech.
- Multi-model support: Supports Hugging Face models and GGUF models.
- Audio playback and saving: The generated voice can be played directly or saved as an audio file.
- Temperature and Repeat Penalty: Control the diversity and smoothness of generated speech by adjusting temperature and repetition penalty parameters.
Using Help
Installation process
- Installing OuteTTS::
pip install outettsImportant: For GGUF support, you need to manually install the
llama-cpp-python. Please visit llama-cpp-python Get specific installation instructions.
Usage
- Initialize the interface::
from outetts.v0_1.interface import InterfaceHF, InterfaceGGUF # 使用 Hugging Face 模型初始化接口 interface = InterfaceHF("OuteAI/OuteTTS-0.1-350M") # 或者使用 GGUF 模型初始化接口 # interface = InterfaceGGUF("path/to/model.gguf") - Generate TTS output::
output = interface.generate( text="Hello, am I working?", temperature=0.1, repetition_penalty=1.1, max_length=4096 ) - Play and save generated audio::
# 播放生成的音频 output.play() # 保存生成的音频到文件 output.save("output.wav")
voice cloning
- Creating custom speakers::
speaker = interface.create_speaker( "path/to/reference.wav", "reference text matching the audio" ) - Saving and loading speakers::
# 保存说话人到文件 interface.save_speaker(speaker, "speaker.pkl") # 从文件加载说话人 speaker = interface.load_speaker("speaker.pkl") - Generating TTS with Customized Speech::
output = interface.generate( text="This is a cloned voice speaking", speaker=speaker, temperature=0.1, repetition_penalty=1.1, max_length=4096 )
parameterization
- Temperature: Controls the diversity of generated speech. Lower temperatures (e.g., 0.1) generate more deterministic outputs, while higher temperatures (e.g., 0.7) generate more diverse outputs.
- Repetition penalty (repetition_penalty): Controls the level of repetition in the generated speech. A higher repetition penalty (e.g., 1.1) reduces the generation of repetitive content.
Through the above steps, users can easily install and use the OuteTTS model for text-to-speech and speech cloning operations. Detailed parameter adjustments and usage examples can help users generate high-quality speech output according to their specific needs.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...