
OpenAI Release: Applications and Best Practices for AI Inference Modeling

In the field of artificial intelligence, the choice of model is crucial. openAI, an industry leader, offers a family of models of two main types:inference model (Reasoning Models) and GPT model (GPT Models). The former is represented by the o-series of models, such as o1 cap (a poem) o3-miniThe latter is known for its GPT family of models, such as the GPT-4o. Understanding the differences between these two types of models, and the application scenarios in which they each excel, is critical to fully utilizing the potential of AI.
This article will delve into that:
- Key differences between OpenAI inference models and GPT models.
- When to prioritize using OpenAI's inference models.
- How to effectively cue inference models for optimal performance.
The other day Microsoft engineers released a Hint Engineering for OpenAI O1 and O3-mini Inference Models , it is possible to compare the differences in application between the two.
Inference Model vs. GPT Model: Strategists vs. Executors
OpenAI's o-series of inference models exhibit their own strengths in different types of tasks and require different cueing strategies than the familiar GPT models. It is important to understand that these two types of models are not simply better or worse, but have a different capability focus. This reflects OpenAI's continued efforts to expand the boundaries of its modeling capabilities to address the needs of increasingly complex applications that require deep reasoning.
OpenAI has specifically trained the o-series models, internally codenamed Planners, to think longer and deeper, enabling them to excel in areas such as strategy formulation, complex problem planning, and decision-making based on large amounts of ambiguous information. The ability of these models to perform tasks with high precision and accuracy makes them ideal for fields that traditionally rely on human experts, such as math, science, engineering, financial services, and legal services.
On the other hand, OpenAI's GPT models (internally codenamed "Workhorses") are more low-latency and cost-effective, and are designed for direct task execution. In practice, a common pattern is to use a combination of these two types of models: use the o-series models to formulate a macro strategy for problem solving, and then efficiently execute specific subtasks with the help of the GPT models, especially in scenarios where speed and cost-efficiency are more critical than absolute accuracy. This division of labor reflects the maturity of the AI model design philosophy, which separates planning from execution.
How to choose the right model? Understanding your needs
When choosing a model, the key is to define the core requirements of your application scenario:
- Speed and cost. If you prioritize speed and cost efficiency, then the GPT model is usually the faster and more economical choice.
- Clearly defined tasks. For applications with clear goals and well-defined task boundaries, the GPT model is able to accomplish the execution tasks with excellence.
- Accuracy and Reliability. If your application requires extreme accuracy and reliability of results, the o-Series models are the more trusted decision makers.
- Complex Problem Solving. In the face of high ambiguity and complexity, the o-series models are able to cope effectively.
So, if speed and cost are primary concerns, and your use cases primarily involve straightforward, well-defined tasks, then OpenAI's GPT models are ideal. However, if accuracy and reliability are critical, and you need to solve complex, multi-step problems, then OpenAI's o-series models may be better suited to your needs.
In many real-world AI workflows, the best practice is to use a combination of these two models: the o family of models acts as a "planner" responsible for agent planning and decision making, while the GPT family of models acts as an "executor" responsible for specific task execution. This combination strategy fully utilizes the strengths of both types of models.

For example, OpenAI's GPT-4o and GPT-4o mini models can be used in customer service scenarios, where customer information is first used to categorize order details, identify order issues and return policies, and then these data points are fed into the o3-mini model, which makes the final decision about the feasibility of returning the product based on preset policies.
Application scenarios for inference models: excelling at complexity and ambiguity
OpenAI has summarized some typical patterns of successful applications of inference models through collaboration with customers and internal observations. The following list of application scenarios is not exhaustive, but rather a practical guide to help you better evaluate and test OpenAI's o-series models.
1. Managing ambiguity: understanding intent from fragmented information
Reasoning models are particularly good at handling tasks with incomplete or scattered information. Even when prompted with limited information, inference models can effectively understand the user's true intent and handle ambiguities in instructions appropriately. It is worth mentioning that inference models usually do not rush to make unwise guesses or try to fill in information gaps on their own, but rather proactively ask clarifying questions to ensure that the task requirements are accurately understood. This exemplifies the strength of reasoning models in dealing with uncertainty and complex tasks.
Hebbia, an AI knowledge platform for legal and financial domains, said: "o1's superior reasoning capabilities enable Matrix, OpenAI's multi-agent platform, to efficiently process complex documents and generate detailed, well-structured and informative responses. For example, o1 makes it easy for Matrix to recognize, with simple prompts, the amount available under a credit agreement with a restricted ability to pay. No other model has previously achieved this level of performance. In 52%'s intensive credit agreement complex cueing tests, o1 achieved more significant results compared to other models."
--Hebbia, an AI knowledge platform company for the legal and financial sectors
2. Information retrieval: finding the needle in the haystack, pinpointing the location
When confronted with massive amounts of unstructured information, the inference model demonstrates strong information comprehension and is able to accurately extract the most relevant information to the question, thus efficiently answering the user's question. This highlights the superior performance of inference models in information retrieval and key information filtering, especially when dealing with large-scale datasets.
Endex, an AI financial intelligence platform, shares, "To deeply analyze company acquisitions, the o1 model was used to review dozens of company documents, including contracts and lease agreements, with the aim of looking for potential clauses that could adversely affect the deal. The model was tasked with flagging key provisions. In doing so, o1 keenly identified a key "change of control" clause in a footnote: a clause that stipulated the immediate repayment of a $75 million loan if the company were to be sold. o1's attention to detail was also crucial in identifying a key clause in the footnote: a clause that stipulated the immediate repayment of a $75 million loan if the company were to be sold. o1's high attention to detail enables OpenAI's AI agents to effectively support the work of financial professionals by accurately identifying mission-critical information."
--Endex, AI Financial Intelligence Platform
3. Relationship discovery and nuance identification: digging deeper into the value of data
OpenAI has found that inference models are particularly adept at analyzing dense, unstructured documents hundreds of pages long, such as legal contracts, financial statements, and insurance claims. These models are effective at extracting information from complex documents, making connections between different documents, and making inferential decisions based on facts implicit in the data. This shows that inference models have significant advantages in processing complex documents and mining deep information.
Blue J, the AI platform for tax research, mentions, "Tax research often requires integrating information from multiple documents to form a final, compelling conclusion. After replacing the GPT-4o model with the o1 model, OpenAI found that o1 performs better at reasoning about the interactions between documents, and is able to draw logical conclusions that are not apparent in any single document. As a result, by switching to the o1 model, OpenAI saw an impressive 4x improvement in end-to-end performance."
--Blue J, AI Platform for Tax Research
Reasoning models are equally adept at understanding nuanced policies and rules and applying them to specific tasks to arrive at reasonable conclusions.
BlueFlame AI, an investment management AI platform, gives an example: "In the financial analytics space, analysts are often required to deal with complex situations related to shareholders' rights and need to have a deep understanding of the associated legal complexities. OpenAI tested about 10 models from different vendors using a challenging but common question: How will financing behavior affect existing shareholders, especially when they exercise their anti-dilution privilege? This question requires reasoning about company valuations before and after the financing and dealing with the complexities of cyclical dilution - a question that would take even a top financial analyst 20-30 minutes to wrap their head around. OpenAI found that the o1 and o3-mini models solve this problem perfectly! These models even generated a clear computational table showing in detail the impact of financing behavior on $100,000 shareholders."
--BlueFlame AI, an investment management AI platform
4. Multi-step agency planning: planning for operations, planning for success
Inference models play a crucial role in agent planning and strategy formulation. OpenAI has observed that inference models, when positioned as "planners", are able to generate detailed, multi-step solutions to complex problems. Subsequently, the system can select and assign the most appropriate GPT model ("executor") to execute each step, based on varying demands on latency and intelligence. This further demonstrates the advantages of using a combination of models, with the inference model acting as the "brain" for strategy planning and the GPT model acting as the "arms and legs" for execution.
Argon AI, an AI knowledge platform for the pharmaceutical industry, reveals, "OpenAI employs the o1 model as a planner in its agent infrastructure, enabling it to orchestrate other models in the workflow to efficiently complete multi-step tasks. OpenAI has found that the o1 model is very good at choosing the right type of data and breaking down large, complex problems into smaller, manageable modules so that other models can focus on specific executions."
--Argon AI, an AI knowledge platform for the pharmaceutical industry
Lindy.AI, a working AI assistant, shared, "The o1 model provides powerful support for the many agent workflows of Lindy, OpenAI's AI working assistant. The model is able to utilize function calls to extract key information from a user's calendar or email to automatically assist them in scheduling meetings, sending emails, and managing other aspects of their daily tasks. OpenAI switched all of Lindy's past agent steps that were causing problems to the o1 model and observed that Lindy's agent functionality became flawless almost overnight!"
--Lindy.AI, Work AI Assistant
5. Visual Reasoning: Insight into the Information Behind the Image
As of today.o1 is the only inference model that supports visual inference capabilities. o1 together with GPT-4o The significant difference between theo1 Even the most challenging visual information, such as complexly structured charts, tables, or photographs with poor image quality, can be handled effectively. This highlights the importance of o1 Unique advantages in the field of visual information processing.
Safetykit, an AI merchant monitoring platform, mentions, "OpenAI is dedicated to automating risk and compliance reviews for millions of online products, including luxury jewelry replicas, endangered species, and regulated items. In OpenAI's most challenging image categorization task, the GPT-4o model is only 50% accurate. and
o1The model achieves an impressive accuracy of up to 88% without any modifications to OpenAI's existing processes."-Safetykit, AI Merchant Monitoring Platform
OpenAI's own internal tests have also shown that theo1 The model is able to recognize fixtures and materials from highly detailed architectural drawings and generate a comprehensive bill of materials. One of the most surprising phenomena observed by OpenAI is that theo1 The model is able to make connections across different images - for example, it can take the legend on one page of an architectural drawing and apply it exactly to another page without explicit instructions. In the example below, we can see that for the "4x4 PT Wooden Column," theo1 The model was able to correctly recognize that "PT" stands for "pressure treated" based on the legend. This is a good demonstration of the o1 model's power in complex visual information understanding and cross-document reasoning.

6. Code review, debugging and quality improvement: strive for excellence, code optimization
Inference models excel in code review and improvement, and are particularly good at handling large-scale code bases. Given the relatively high latency of inference models, code review tasks are typically run in the background. This suggests that, despite the latency, inference models have important applications in code analysis and quality control, especially for scenarios that do not require high real-time performance.
AI code review startup CodeRabbit reveals, "OpenAI offers automated AI code review services on code hosting platforms like GitHub and GitLab. The code review process is inherently insensitive to latency, but requires a deep understanding of code changes across multiple files. This is where the o1 model excels - it reliably detects subtle changes in the codebase that might be easily missed by a human reviewer. After switching to the o-series models, OpenAI saw a 3x increase in product conversions."
-CodeRabbit, the AI code review startup
even though GPT-4o cap (a poem) GPT-4o mini model may be better suited for low-latency coding scenarios, but OpenAI has also observed that o3-mini model excels in latency-insensitive code generation use cases. This means that the o3-mini It also holds potential in the area of code generation, especially in application scenarios that require high code quality and are relatively forgiving of latency.
AI-driven code-completion startups Codeium commented, "Even in the face of challenging coding tasks, the
o3-miniModels are also able to consistently generate high-quality, conclusive code and very frequently give the right solution when the problem is well defined. Other models may only be suitable for small, rapid code iterations, but theo3-miniModels specialize in planning and executing complex software design systems."--Codeium, the AI-driven code extension startup
7. Model evaluation and benchmarking: objective evaluation and selection of the best of the best
OpenAI also found that inference models performed well in benchmarking and evaluating other model responses. Data validation is critical to ensure the quality and reliability of datasets, especially in sensitive areas such as healthcare. Traditional validation methods rely on predefined rules and patterns, but methods like o1 cap (a poem) o3-mini Such advanced models are able to understand the context and reason about it, enabling more flexible and intelligent verification methods. This suggests that inference models can act as "referees" to assess the quality of other models' outputs, which is critical for iterative optimization of AI systems.
Braintrust, the AI evaluation platform, notes, "Many customers use the LLM-as-a-judge feature in the Braintrust platform as part of their evaluation process. For example, a healthcare company might use a program like
gpt-4oSuch a master model to summarize the patient history problem and then use theo1model to assess the quality of summaries. One Braintrust customer found that using4oThe F1 score is 0.12 when the model is used as a referee, and switching to theo1After modeling, the F1 score jumped to 0.74! In these use cases, they found that theo1The model's reasoning capabilities are transformative in capturing the nuances of completion results, especially in the most difficult and complex scoring tasks."--Braintrust, an AI evaluation platform
Tips for Effectively Prompting Reasoning Models: Simplicity Comes First
Reasoning models tend to perform best when they receive clear and concise cues. Some traditional cue engineering techniques, such as instructing the model to "think step-by-step," may not be effective in improving performance, and can even be counterproductive at times. Here are some best practices, or you can just refer to the cueing examples to get started.
- Developer messages replace system messages. surname Cong
o1-2024-12-17version onwards, the inference model began to support developer messages instead of traditional system messages to conform to the command chain behavior described in the model specification. - Keep the prompts simple and direct: Reasoning models excel at understanding and responding to clear and concise instructions. Therefore, clear and direct instructions are more effective for inference models than complex cue engineering techniques.
- Avoid Thought Chains Tip. Since inference models are already internally capable of reasoning, there is no need to prompt them to "think step-by-step" or "explain your reasoning process". This redundant prompting may instead degrade model performance.
- Use delimiters to improve clarity. Using separators such as Markdown, XML tags, and section headings to clearly label different parts of the input helps the model to accurately understand the content of the different sections.
- Prioritize attempts at zero-sample cues before considering lesser-sample cues: the Inference models usually produce good results without the need for few sample examples. Therefore, it is recommended that you first try to write zero-sample hints without examples. If you have more complex requirements for the output results, it may be helpful to include some examples of inputs and desired outputs in your hints. However, it is important to make sure that the examples are highly consistent with your prompt instructions, as deviations between the two may lead to poor results.
- Provide clear and specific guidance. If there are explicit constraints that can limit the range of responses from the model (e.g., "Propose a solution with a budget of less than $500"), clearly articulate those constraints in the prompt.
- Clarification of the final objective. In the instructions, be as specific as possible in describing the criteria by which successful responses will be judged, and encourage the model to keep reasoning and iterating until your success criteria are met.
- Markdown formatting control. surname Cong
o1-2024-12-17Starting with version 1, inference models in the API avoid generating responses with Markdown formatting by default. If you want the model to include Markdown formatting in the response, add the stringFormatting re-enabledThe
Inference Modeling API Usage Examples
Reasoning models are unique in their "thinking" process. Unlike traditional language models, inference models think deeply internally and build a long chain of reasoning before giving an answer. As stated in the official OpenAI description, these models think deeply before they respond to the user. This mechanism gives inference models the ability to excel at tasks such as solving complex puzzles, coding, scientific reasoning, and multi-step planning for Agent workflows.
Similar to OpenAI's GPT model, OpenAI provides two inference models to meet different needs:o3-mini The model stands out with its smaller size and faster speed, while the token The cost is also relatively low; and o1 Models, on the other hand, trade off greater scale and slightly slower speed for more powerful problem solving.o1 Models typically generate better quality responses when dealing with complex tasks and show better generalization performance across domains.
Quick Start
To help developers get started quickly, OpenAI provides an easy-to-use API interface. Below is a quick start example of how to use the inference model in chat completions:
Using inference models in chat completions
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
reasoning_effort: "medium",
messages: [
{
role: "user",
content: prompt
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,
格式为 '[1,2],[3,4],[5,6]',并以相同的格式打印转置矩阵。
"""
response = client.chat.completions.create(
model="o3-mini",
reasoning_effort="medium",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o3-mini",
"reasoning_effort": "medium",
"messages": [
{
"role": "user",
"content": "编写一个 bash 脚本,该脚本接收一个以字符串形式表示的矩阵,格式为 \"[1,2],[3,4],[5,6]\",并以相同的格式打印转置矩阵。"
}
]
}'
Intensity of reasoning: controlling the depth of thinking in models
In the above example, thereasoning_effort The parameter (affectionately referred to as "juice" during the development of these models) is used to guide how much inference computation the model performs before generating a response. The user can specify for this parameter low,medium maybe high One of the three values. Among them.low model focuses on speed and lower token costs, while the high mode prompts the model to perform deeper and more comprehensive reasoning, but increases token consumption and response time. The default value is set to medium, aims to achieve a balance between speed and inference accuracy. Developers can flexibly adjust the inference intensity according to the needs of actual application scenarios to achieve optimal performance and cost-effectiveness.
How Reasoning Works: An In-Depth Analysis of the Model "Thinking" Process
The inference model builds on the traditional input and output tokens by introducing the Reasoning about tokens This concept. These inference tokens are analogous to the model's "thought process", which the model utilizes to decompose its understanding of the user's cues and explore multiple possible paths for generating answers. Only after the generation of inference tokens is complete does the model output the final answer, i.e., a complementary token visible to the user, and discard the inference token from the context.
The following figure shows an example of a multi-step dialog between a user and an assistant. At each step of the dialog, input and output tokens are retained, while inference tokens are discarded by the model.
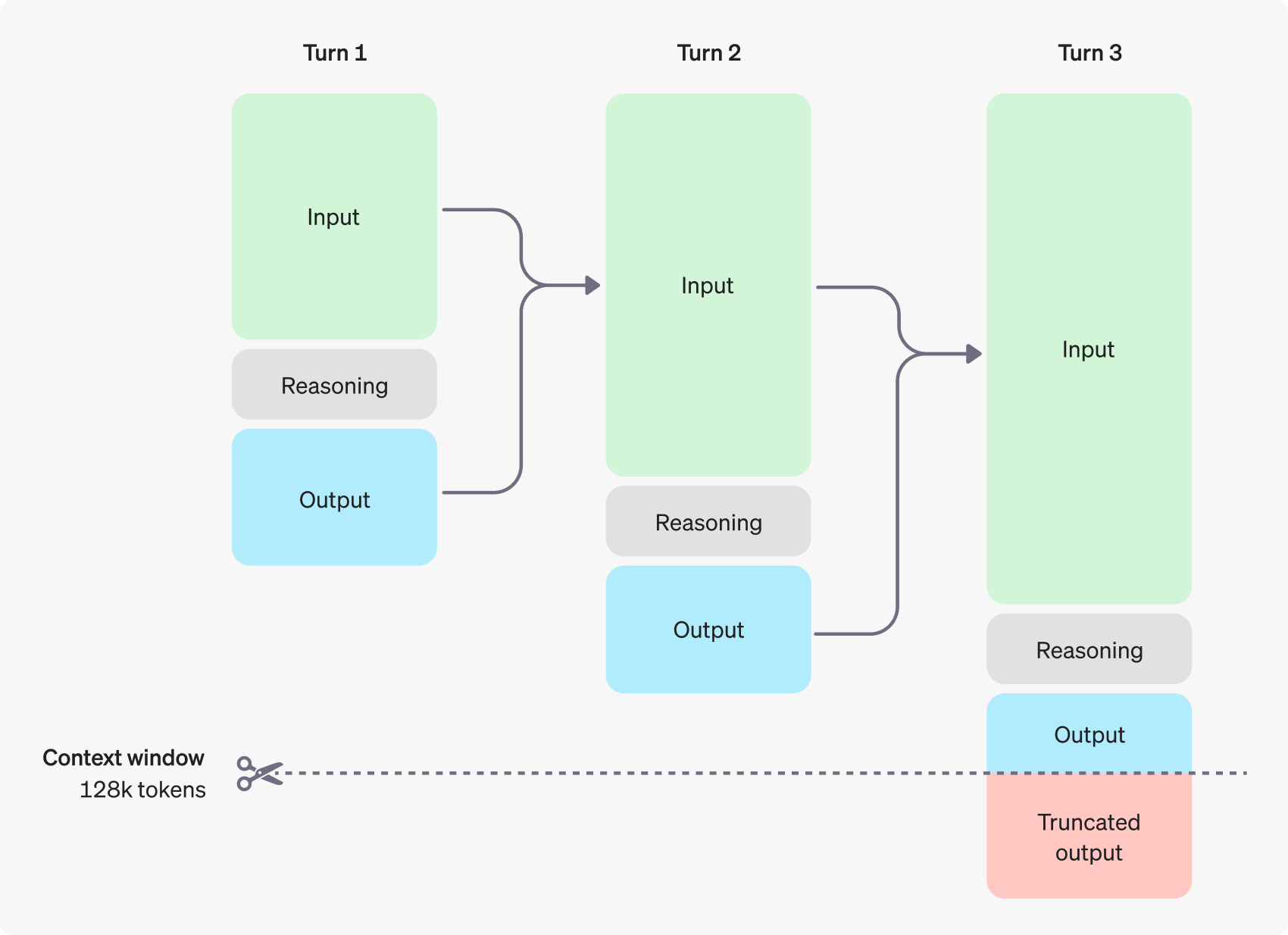
It is worth noting that although inference tokens are not visible through the API interface, they still occupy the model's context window space and count towards the total token usage, and need to be paid for just like output tokens. Therefore, in practice, developers need to fully consider the impact of reasoning tokens and reasonably manage the model's context window and token consumption.
Contextual window management: ensuring models have plenty of "room to think"
When creating a completions request, it is important to make sure that the context window has enough space for the inference tokens generated by the model.Depending on the complexity of the problem, the model may need to generate hundreds to tens of thousands of inference tokens.The user can create a completion request with the chat completion response object's usage object by using the completion_tokens_details field to see the exact number of inference tokens used by the model for a particular request:
{
"usage": {
"prompt_tokens": 9,
"completion_tokens": 12,
"total_tokens": 21,
"completion_tokens_details": {
"reasoning_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
}
}
Users can review the context window lengths for different models on the Model Reference page. Proper evaluation and management of the context window is essential to ensure that the inference model works effectively.
Cost control: fine-tuning and optimizing token consumption
To effectively manage the cost of the inference model, users can use the max_completion_tokens parameter that limits the total number of tokens generated by the model, including inference tokens and complementary tokens.
In earlier models, themax_tokens The parameter controls both the number of tokens generated by the model and the number of tokens visible to the user, which are always the same. However, for inference models, the total number of tokens generated by the model may exceed the number of tokens ultimately seen by the user due to the introduction of internal inference tokens.
Consider that some applications may rely on max_tokens parameter is consistent with the number of tokens returned by the API, OpenAI has introduced a special max_completion_tokens parameter to more explicitly control the total number of tokens generated by the model, including inference tokens and user-visible complement tokens.This explicit parameterization ensures a smooth transition for existing applications using the new model, avoiding potential compatibility issues. For all previous models, themax_tokens The function of the parameter remains unchanged.
Making room for reasoning: avoiding "thinking" interruptions
If the number of tokens generated reaches the context window limit or the user-set max_completion_tokens value, the API will return a chat completion response with the finish_reason The field is set to length. This can happen before the model generates any user-visible complementary tokens, which means that the user may have to pay for input tokens and inference tokens, but end up not receiving any visible responses.
To avoid the above, always make sure that the context window is reserved with plenty of space, or place the max_completion_tokens parameter is adjusted to a higher value. openAI recommends reserving space for at least 25,000 tokens for the inference and output processes when first trying out these inference models. As users become familiar with the number of inference tokens required for their prompts, this buffer size can be adjusted as appropriate for more granular cost control.
Tip suggestion: unlocking the potential of reasoning models
There are some key differences that the user should be aware of when prompting for inference models and GPT models. Overall, inference models tend to give better results for tasks that only provide high-level guidance. This is in contrast to the GPT model, which typically performs better when very precise instructions are received.
- Reasoning models like experienced senior colleagues -- Users can be trusted to work out the specific details autonomously by simply telling them what they want to achieve.
- The GPT model is more like a junior assistant -- They work best when they have clear and detailed instructions for creating a specific output.
To learn more about best practices for using inference models, see the official OpenAI guide.
Tip Example: Application Scenario Demonstration
Coding (code refactoring)
OpenAI's o-series models demonstrate powerful algorithmic understanding and code generation capabilities. The following example shows how the o1 model can be utilized to refactor to specific criteria React Component.
refactor code
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
指令:
- 给定以下 React 组件,修改它,使非小说类书籍显示红色文本。
- 回复中仅返回代码
- 不要包含任何额外的格式,例如 markdown 代码块
- 对于格式,使用四个空格缩进,并且不允许任何代码行超过 80 列
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
Code (project planning)
OpenAI's o-series model is also good at developing multi-step project plans. The following example shows how to use the o1 model to create a complete file system structure for a Python application and generate Python code that implements the required functionality.
Plan and create a Python project
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
`.trim();
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
},
],
});
console.log(completion.usage.completion_tokens_details);
from openai import OpenAI
client = OpenAI();
prompt = """
我想构建一个 Python 应用程序,它可以接收用户的问题,并在数据库中查找答案。
数据库中存储了问题到答案的映射关系。如果找到密切匹配的问题,则检索匹配的答案。
如果没有找到,则要求用户提供答案,并将问题/答案对存储在数据库中。
为我创建一个目录结构计划,我需要这个结构,然后完整地返回每个文件中的代码。
只在开头和结尾提供你的推理过程,不要在代码中穿插推理。
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
STEM research
OpenAI's o-series models have demonstrated excellent performance in STEM (Science, Technology, Engineering, and Math) research. These models often give impressive results for prompts designed to support basic research tasks.
Raising issues related to basic science research
import OpenAI from "openai";
const openai = new OpenAI();
const prompt = `
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
`;
const completion = await openai.chat.completions.create({
model: "o3-mini",
messages: [
{
role: "user",
content: prompt,
}
],
});
console.log(completion.choices[0].message.content);
from openai import OpenAI
client = OpenAI();
prompt = """
为了推进新型抗生素的研究,我们应该考虑研究哪三种化合物?
为什么我们应该考虑它们?
"""
response = client.chat.completions.create(
model="o3-mini",
messages=[
{
"role": "user",
"content": prompt
}
]
);
print(response.choices[0].message.content);
official example
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...