
LongBench v2: Evaluating long text +o1?


Evaluating Big Models for 'Deep Understanding and Reasoning' in Real-World, Long Text, Multi-Tasking
In recent years, significant progress has been made in research on large language models for long texts, with the length of the context window of the models having been extended from the initial 8k to 128k or even 1M tokens. however, a key question still remains: do these models truly understand the long texts they are dealing with? In other words, are they able to understand, learn and reason deeply based on the information in long texts?
To answer this question and to push forward the advancement of long text models for deep comprehension and reasoning, a team of researchers from Tsinghua University and Smart Spectrum have launched LongBench v2, a benchmark test designed to evaluate the deep comprehension and reasoning capabilities of LLMs in real-world long text multitasking.
We believe that LongBench v2 will advance the exploration of how scaling inference-time compute (e.g., o1 models) can help solve deep understanding and inference problems in long text scenarios.
specificities
LongBench v2 has several significant features over existing benchmarks for long text comprehension:
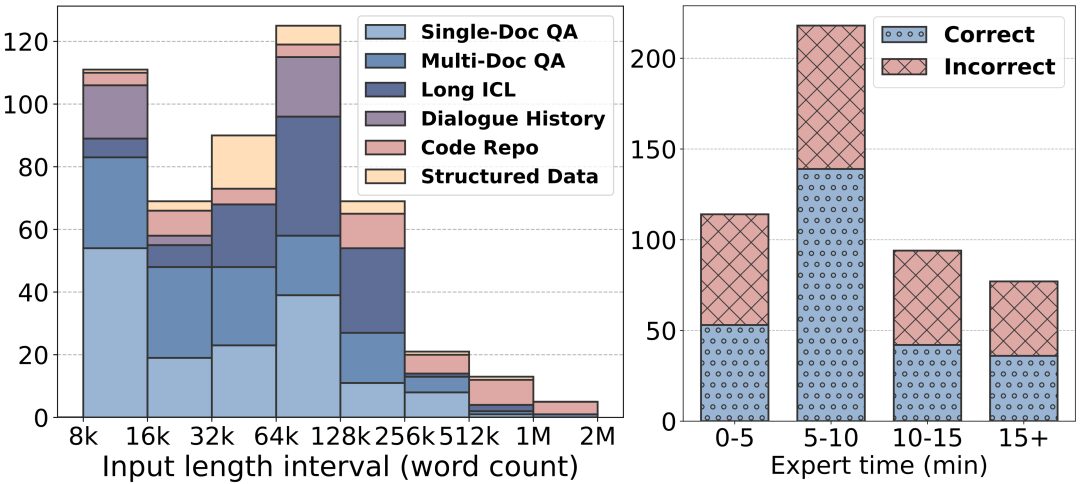
Longer text lengths: LongBench v2's text lengths range from 8k to 2M words, with most of the text being less than 128k in length.
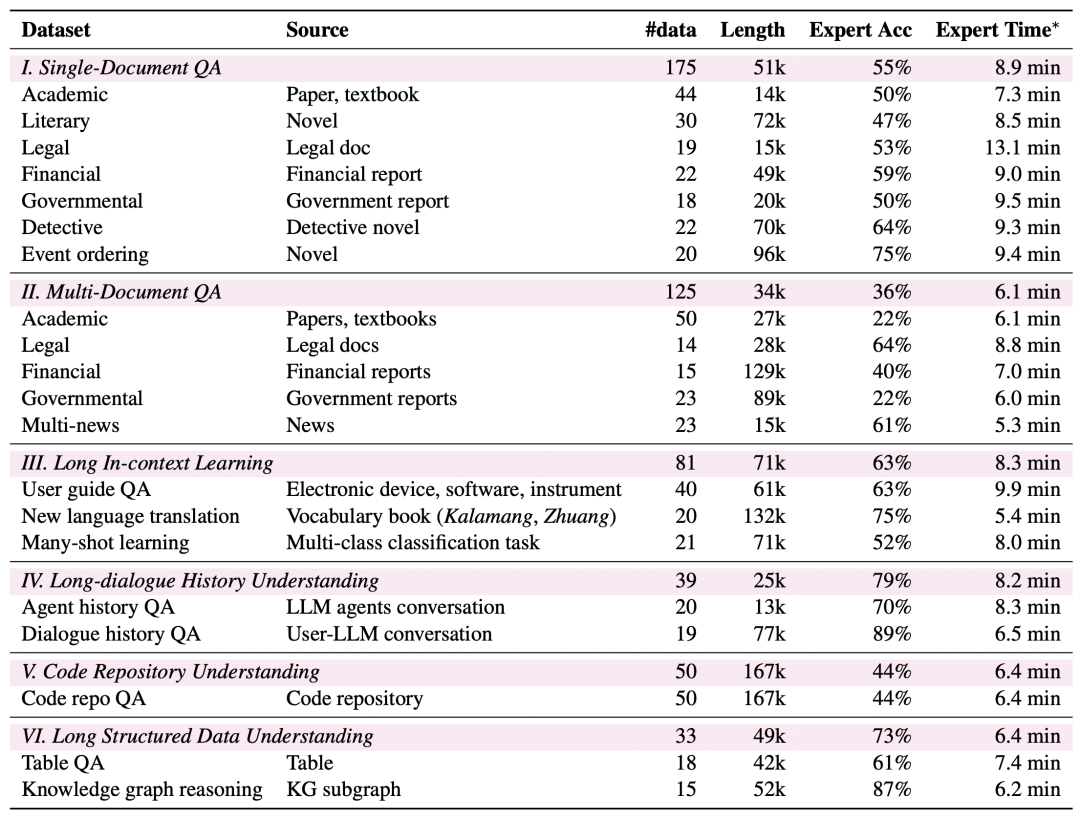
Higher Difficulty: LongBench v2 contains 503 challenging four-choice multiple-choice questions - questions that even human experts using the in-document search tool would struggle to answer correctly in a short period of time. Human experts averaged only 53.71 TP3T of accuracy under the 15-minute time limit (251 TP3T at random).
Broader Task Coverage: LongBench v2 covers six major task categories, including single-document quizzing, multi-document quizzing, long text context learning, long dialog history understanding, code repository understanding, and long structured data understanding, with a total of 20 subtasks covering a variety of real-world scenarios.
Higher Reliability: To ensure the reliability of the assessment, all questions in LongBench v2 are in multiple-choice format and undergo a rigorous manual labeling and review process to ensure the high quality of the data.
Data collection process
To ensure the quality and difficulty of the data, LongBench v2 employs a rigorous data collection process that consists of the following steps:
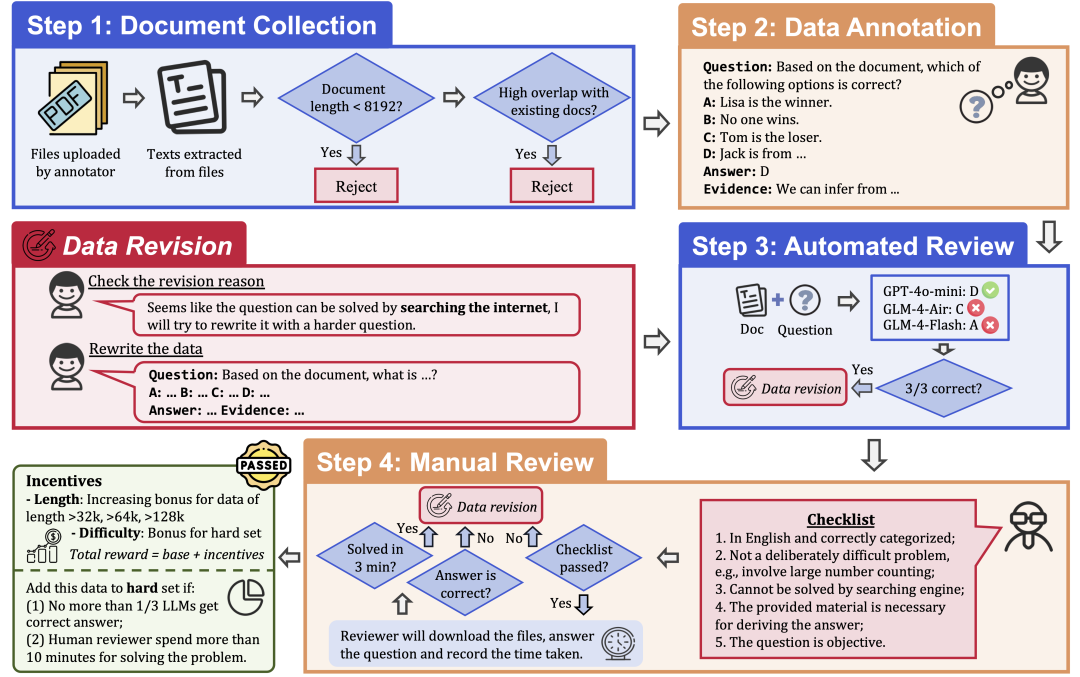
Document Collection: Recruit 97 annotators from top universities, with a variety of academic backgrounds and grades, to collect long documents that they have personally read or used, such as research papers, textbooks, novels, and so on.
Data Labeling: Based on the collected documents, the labeler asks a multiple-choice question with four options, a correct answer, and corresponding evidence.
Automatic review: The labeled data were automatically reviewed using three LLMs (GPT-4o-mini, GLM-4-Air, and GLM-4-Flash) with 128k context windows, and if all three models answered the question correctly, the question was considered too simple and needed to be relabeled.
Human Review: Data that passes the automated review is assigned to 24 specialized human experts for human review, who attempt to answer the question and determine if the question is appropriate and the answer is correct. If the expert is able to answer the question correctly within 3 minutes, the question is considered too simple and needs to be relabeled. In addition, if the expert believes that the question itself does not meet the requirements or the answer is incorrect, it will be returned for re-marking.
Data Revision: Data that does not pass the audit will be returned to the annotator for revision until it passes all audit steps.
Assessment results
The team evaluated 10 open-source LLMs and 6 closed-source LLMs using LongBench v2. Two scenarios were considered in the evaluation: zero-shot vs. zero-shot+CoT (i.e., letting the model output the chain-of-thought first, and then letting the model output the chosen answer).
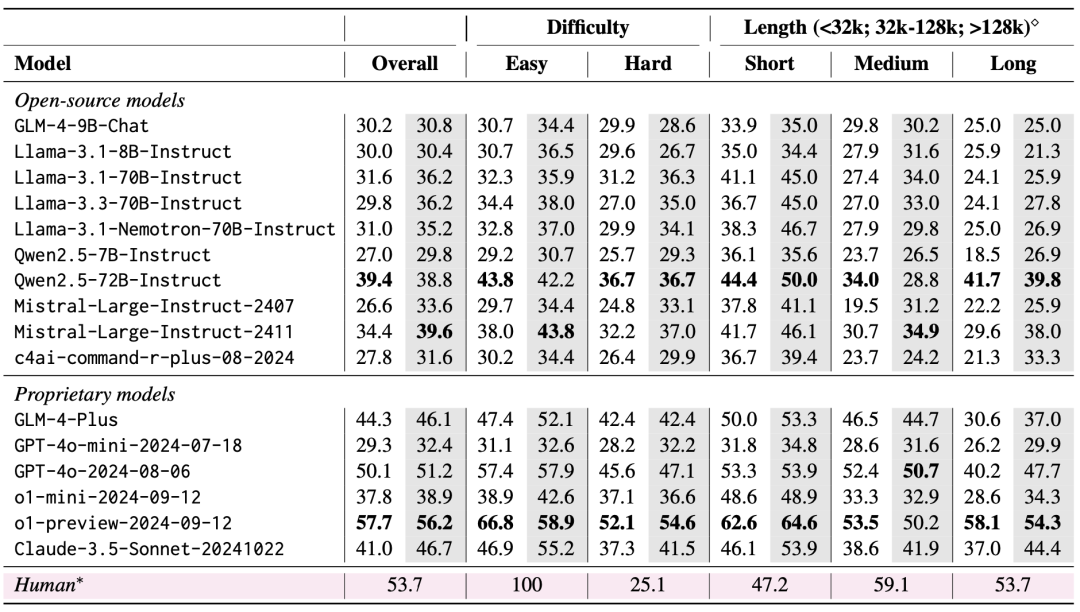
The evaluation results show that LongBench v2 is a great challenge for current LLMs, and even the best-performing model achieves only 50.1% accuracy with direct answer output, while the o1-preview model, which introduces a longer inference chain, achieves 57.7% accuracy, outperforming the human expert by 4%.
1. The Importance of Scaling Inference-Time Compute
A very important finding in the evaluation results is that the performance of the models on LongBench v2 can be significantly improved by Scaling Inference-Time Compute. For example, the o1-preview model achieves significant gains on tasks such as multi-document quizzing, long text context learning, and code repository understanding by integrating more inference steps compared to GPT-4o.
This suggests that LongBench v2 places higher demands on the reasoning capabilities of current models, and that increasing the time spent thinking and reasoning about reasoning appears to be a natural and critical step in addressing such long textual reasoning challenges.
2. RAG + Long-context experiments

It is found that the performance of both Qwen2.5 and GLM-4-Plus models does not improve significantly, and even decreases after the number of retrieved blocks exceeds a certain threshold (32k tokens, about 64 blocks of 512 length).
This suggests that simply increasing the amount of retrieved information does not always lead to performance improvements. In contrast, GPT-4o is able to efficiently utilize longer retrieval contexts with its optimal RAG Performance occurs at 128k retrieval length.
To summarize, RAG is of limited use when faced with long textual Q&A tasks that require deep understanding and reasoning, especially when the number of retrieved blocks exceeds a certain threshold. The model needs to have stronger reasoning capabilities, rather than just relying on retrieved information, in order to effectively handle the challenging problems in LongBench v2.
This also implies that future research directions also need to focus more on how to improve the model's own long text comprehension and reasoning capabilities, rather than just relying on external retrieval.
We expect LongBench v2 to push the boundaries of long text comprehension and reasoning techniques. Feel free to read our paper, use our data and learn more!
Home page: https://longbench2.github.io
Thesis: https://arxiv.org/abs/2412.15204
Data and Codes: https://github.com/THUDM/LongBench
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...