
Late Chunking x Milvus: How to Improve RAG Accuracy


01.contexts
In RAG application development, the first step is to chunk the document, efficient document chunking can effectively improve the accuracy of the subsequent recall content. How to efficiently chunk is a hot topic of discussion, there are such as fixed-size chunking, random-size chunking, sliding-window resampling, recursive chunking, based on the content of the semantic chunking and other methods. Late Chunking proposed by Jina AI deals with the chunking problem from another perspective, let's take a look at it.
02.What's Late Chunking?
Traditional chunking may lose long-distance contextual dependencies in documents when processing long documents, which is a major pitfall for information retrieval and understanding. That is, when the key information is scattered in multiple text blocks, the text chunking fragment out of context is likely to lose its original meaning, resulting in poorer subsequent recall.
Take Milvus 2.4.13 release note for example, if it is divided into two document blocks as follows, and if we want to query theMilvus 2.4.13有哪些新功能?, the directly relevant content is in chunk 2, while the Milvus version information is in chunk 1. At this point, it is difficult for the Embedding model to correctly link these references to the entities, resulting in poor quality Embedding.
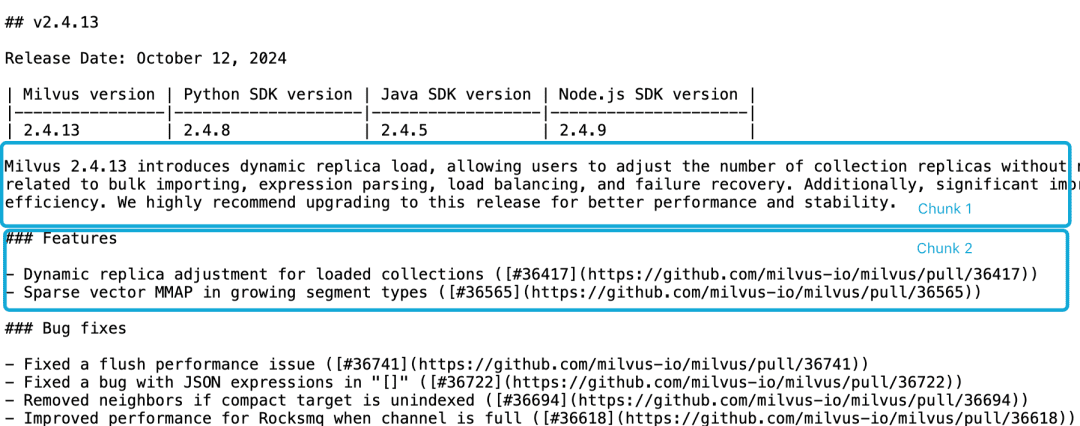
LLM has difficulty solving such a correlation problem due to the fact that the functional description is not in the same chunk as the version information and the lack of a larger contextual document. Although there are a number of heuristics that attempt to alleviate this problem, such as sliding window resampling, overlapping context window lengths, and multiple document scans, however, like all heuristics, these methods are hit and miss; they may work in some cases, but there are no theoretical guarantees.
Traditional chunking uses a pre-chunking strategy, i.e., chunking first and then going through the Embedding model. The text is first cut based on parameters such as sentence, paragraph or preset maximum length. The Embedding model then processes these chunks one by one, through methods such as average pooling, the token Late Chunking is to first go through the Embedding model and then chunk it (this is what late means), we first vectorize the Embedding model and then chunk it. Late Chunking, on the other hand, is to go through the Embedding model first and then chunk it (the meaning of late is here, first vectorize and then chunk it), we will first take the Embedding model's transformer The layer is applied to the entire text, generating a sequence of vector representations for each token that contains rich contextual information. Then, these token vector sequences are average pooled to get the final block Embedding that considers the whole text context.
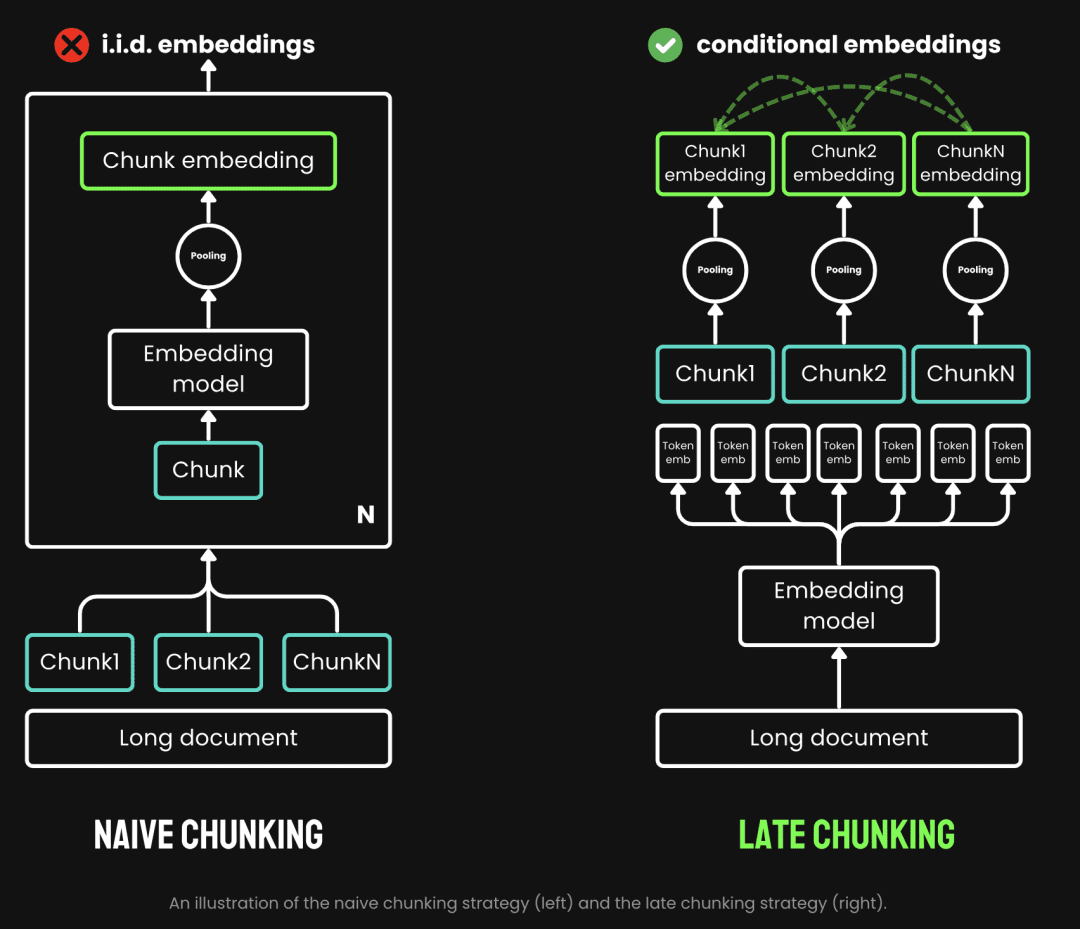
(Image source: https://jina.ai/news/late-chunking-in-long-context-embedding-models/)
Late Chunking generates block Embedding where each block encodes more contextual information, thus improving the quality and accuracy of the encoding. We can support long contextual Embedding models with jina-embeddings-v2-base-enIt can process up to 8192 tokens of text (equivalent to 10 pages of A4 paper), which basically meets the contextual requirements of most long texts.
In summary, we can see the advantages of Late Chunking in RAG applications:
- Improved Accuracy: By preserving contextual information, Late Chunking returns more relevant content for queries than simple chunking.
- Efficient LLM calls: Late Chunking reduces the amount of text passed to LLM because it returns fewer and more relevant chunks.
03.Testing Late Chunking
3.1. Late Chunking Basic Implementation
Function sentence_chunker for the original document to paragraph chunking, return the content of the chunks and chunk marking information span_annotations (i.e., chunks of the beginning and end of the mark)
def sentence_chunker(document, batch_size=10000):
nlp = spacy.blank("en")
nlp.add_pipe("sentencizer", config={"punct_chars": None})
doc = nlp(document)
docs = []
for i in range(0, len(document), batch_size):
batch = document[i : i + batch_size]
docs.append(nlp(batch))
doc = Doc.from_docs(docs)
span_annotations = []
chunks = []
for i, sent in enumerate(doc.sents):
span_annotations.append((sent.start, sent.end))
chunks.append(sent.text)
return chunks, span_annotations
Function document_to_token_embeddings passes the model jinaai/jina-embeddings-v2-base-en model as well as a tokenizer that returns the Embedding of the entire document.
def document_to_token_embeddings(model, tokenizer, document, batch_size=4096): tokenized_document = tokenizer(document, return_tensors="pt") tokens = tokenized_document.tokens() outputs = [] for i in range(0, len(tokens), batch_size): start = i end = min(i + batch_size, len(tokens)) batch_inputs = {k: v[:, start:end] for k, v in tokenized_document.items()} with torch.no_grad(): model_output = model(**batch_inputs) outputs.append(model_output.last_hidden_state) model_output = torch.cat(outputs, dim=1) return model_output
The function late_chunking chunks the Embedding of the entire document as well as the markup information span_annotations of the original chunks.
def late_chunking(token_embeddings, span_annotation, max_length=None): outputs = [] for embeddings, annotations in zip(token_embeddings, span_annotation): if ( max_length is not None ): annotations = [ (start, min(end, max_length - 1)) for (start, end) in annotations if start < (max_length - 1) ] pooled_embeddings = [] for start, end in annotations: if (end - start) >= 1: pooled_embeddings.append( embeddings[start:end].sum(dim=0) / (end - start) ) pooled_embeddings = [ embedding.detach().cpu().numpy() for embedding in pooled_embeddings ] outputs.append(pooled_embeddings) return outputs
If a model is usedjinaai/jina-embeddings-v2-base-enPerform Late Chunking
tokenizer = AutoTokenizer.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
# First chunk the text as normal, to obtain the beginning and end points of the chunks.
chunks, span_annotations = sentence_chunker(document)
# Then embed the full document.
token_embeddings = document_to_token_embeddings(model, tokenizer, document)
# Then perform the late chunking
chunk_embeddings = late_chunking(token_embeddings, [span_annotations])[0]
3.2. Comparison with Traditional Embedding Methods
Let's take the milvus 2.4.13 release note as an example.
Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.
This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.
Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.
We highly recommend upgrading to this release for better performance and stability.
Traditional Embedding, i.e., chunking followed by Embedding, and Late Chunking approach Embedding, i.e., Embedding followed by chunking, are performed respectively. Then, the milvus 2.4.13 Compare the results with those of the two Embedding approaches, respectively
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
milvus_embedding = model.encode('milvus 2.4.13')
for chunk, late_chunking_embedding, traditional_embedding in zip(chunks, chunk_embeddings, embeddings_traditional_chunking):
print(f'similarity_late_chunking("milvus 2.4.13", "{chunk}")')
print('late_chunking: ', cos_sim(milvus_embedding, late_chunking_embedding))
print(f'similarity_traditional("milvus 2.4.13", "{chunk}")')
print('traditional_chunking: ', cos_sim(milvus_embedding, traditional_embeddings))
From the results, words milvus 2.4.13 The similarity of Late Chunking results with chunked documents is higher than that of traditional Embedding because Late Chunking first performs Embedding for the entire text passage, which results in the entire text passage getting milvus 2.4.13 information, which in turn significantly improves similarity in subsequent text comparisons.
similarity_late_chunking("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
late_chunking: 0.8785206
similarity_traditional("milvus 2.4.13", "Milvus 2.4.13 introduces dynamic replica load, allowing users to adjust the number of collection replicas without needing to release and reload the collection.")
traditional_chunking: 0.8354263
similarity_late_chunking("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
late_chunking: 0.84828955
similarity_traditional("milvus 2.4.13", "This version also addresses several critical bugs related to bulk importing, expression parsing, load balancing, and failure recovery.")
traditional_chunking: 0.7222632
similarity_late_chunking("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
late_chunking: 0.84942204
similarity_traditional("milvus 2.4.13", "Additionally, significant improvements have been made to MMAP resource usage and import performance, enhancing overall system efficiency.")
traditional_chunking: 0.6907381
similarity_late_chunking("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
late_chunking: 0.85431844
similarity_traditional("milvus 2.4.13", "We highly recommend upgrading to this release for better performance and stability.")
traditional_chunking: 0.71859795
3.3. Testing Late Chunking in Milvus
Importing Late Chunking Data to Milvus
batch_data=[]
for i in range(len(chunks)):
data = {
"content": chunks[i],
"embedding": chunk_embeddings[i].tolist(),
}
batch_data.append(data)
res = client.insert(
collection_name=collection,
data=batch_data,
)
Query Testing
We define the cosine similarity query method as well as using the Milvus native query method for Late Chunking respectively.
def late_chunking_query_by_milvus(query, top_k = 3):
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
res = client.search(
collection_name=collection,
data=[query_vector.tolist()],
limit=top_k,
output_fields=["id", "content"],
)
return [item.get("entity").get("content") for items in res for item in items]
def late_chunking_query_by_cosine_sim(query, k = 3):
cos_sim = lambda x, y: np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
query_vector = model(**tokenizer(query, return_tensors="pt")).last_hidden_state.mean(1).detach().cpu().numpy().flatten()
results = np.empty(len(chunk_embeddings))
for i, (chunk, embedding) in enumerate(zip(chunks, chunk_embeddings)):
results[i] = cos_sim(query_vector, embedding)
results_order = results.argsort()[::-1]
return np.array(chunks)[results_order].tolist()[:k]
From the results, the two methods return the same content, which indicates that the results of the query for Late Chunking in Milvus are accurate.
> late_chunking_query_by_milvus("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
> late_chunking_query_by_cosine_sim("What are new features in milvus 2.4.13", 3)
['nn### Featuresnn- Dynamic replica adjustment for loaded collections ([#36417](https://github.com/milvus-io/milvus/pull/36417))n- Sparse vector MMAP in growing segment types ([#36565](https://github.com/milvus-io/milvus/pull/36565))...
04.summarize
We present the background, basic concepts, and underlying implementation of Late Chunking as it arose, and then find that Late Chunking works well by testing it at Mivlus. Overall, the combination of accuracy, efficiency, and ease of implementation makes Late Chunking an effective approach for RAG applications.
Reference.
- https://stackoverflow.blog/2024/06/06/breaking-up-is-hard-to-do-chunking-in-rag-applications
- https://jina.ai/news/late-chunking-in-long-context-embedding-models/
- https://jina.ai/news/what-late-chunking-really-is-and-what-its-not-part-ii/
Sample code:
Link: https://pan.baidu.com/s/1cYNfZTTXd7RwjnjPFylReg?pwd=1234 Extract code: 1234 code runs on aws g4dn.xlarge machine
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...