Recently, I found an eye-catching domestic open source AI knowledge base framework: KAG (Knowledge Augmented Generation).
KAG Jointly launched by Ant Group, Zhejiang University and many other organizations, it focuses on building knowledge bases in vertical fields. The data of the paper shows that KAG in the field of e-government reaches the 91.6%'s amazing accuracy rate, also excels in scenarios such as e-healthcare Q&A.
This article will take you on an in-depth look at KAG principle, application scenarios, compare RAG The article also provides a tutorial on how to install and use KAG locally and a demonstration of its effects, which will give you an immersive experience of the KAG framework open-sourced by Ant. If you are planning to use AI to build your own knowledge base, this article is not to be missed!
What is KAG? Core Concepts for a New Generation of Knowledge Base Frameworks
KAG (Knowledge Augmented Generation) is an inferential question and answer framework based on the OpenSPG engine and large-scale language model (LLM). Its core concepts areCombining the dual advantages of knowledge graph and vector retrieval, it aims to provide users with more rigorous decision support and more accurate information retrieval services.
KAG realizes the deep fusion and enhancement of LLM and Knowledge Graph through the following four key technologies:
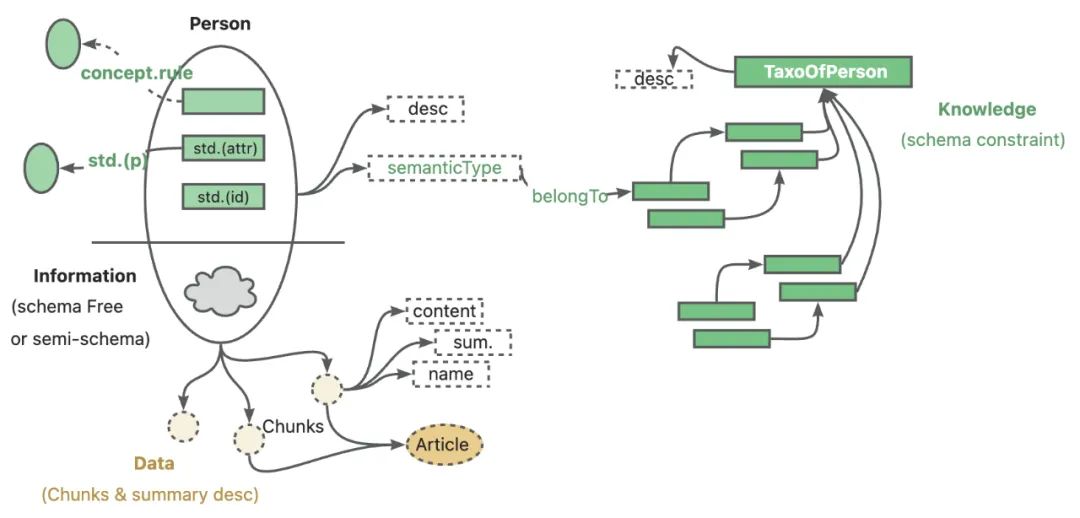
- Knowledge of LLM-friendly representation: Optimize the structure of knowledge graphs to make them easier to understand and exploit by large language models.
- Cross-indexing between knowledge graphs and original text fragments: Establish bi-directional links between entities and relationships in the knowledge graph and the original text fragments to improve retrieval efficiency and accuracy.
- Logical form-guided hybrid reasoning engine: Combine the logical reasoning power of the Knowledge Graph with the semantic understanding power of the LLM to realize more complex reasoning quizzes.
- Knowledge Alignment with Semantic Reasoning: Ensure that the knowledge in the knowledge graph is aligned with the semantic space of the language model to enhance the effectiveness of knowledge utilization.
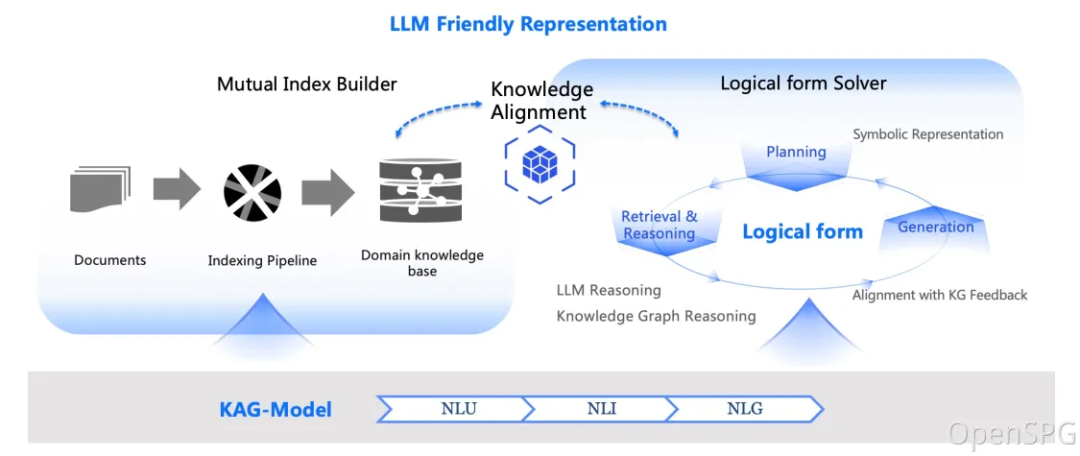
In short, KAG innovatively combines the advantages of knowledge graph and vector retrieval to build a powerful knowledge base framework. It can not only utilize the logical reasoning capability of LLM, but also combine with knowledge graph for deep reasoning to accomplish complex information retrieval tasks. What's more, when knowledge graph information is insufficient, KAG can also skillfully utilize vector retrieval technology to supplement relevant text fragments to ensure the comprehensiveness and accuracy of the answers.
Overview of KAG's overall architecture
The KAG framework consists of two core modules: knowledge building (kg-builder) and problem solving (kg-solver).
- kg-builder The module focuses on the efficient construction of knowledge, optimizes the knowledge representation for LLM, and supports flexible knowledge modeling and bi-directional indexing.
- kg-solver The module is then responsible for efficient problem solving, which is achieved by a hybrid reasoning engine that integrates multiple capabilities such as retrieval, graphical reasoning, linguistic reasoning and numerical computation to solve complex problems.
- The third module, kag-model, will be open-sourced to further improve the functionality of the KAG framework.
KAG vs. Traditional RAG: Differences and Advantages Explained
RAG (Retrieval-Augmented Generation) has been widely used as a common knowledge base technology. So, what are the differences and advantages of KAG over RAG? We compare and analyze it through the following dimensions:
1. Knowledge representation:
- RAG. It mainly relies on vector similarity for retrieval, and the knowledge representation is relatively simple, making it difficult to handle complex problems requiring multi-hop reasoning.
- KAG. Adopting a more friendly knowledge representation for LLM, compatible with schema-less and schema-constrained knowledge, supporting inter-indexed structure of graph-structured knowledge and textual knowledge, the knowledge representation is more enriched and structured.
2. Reasoning skills:
- RAG. Insensitivity to the logical relationships of knowledge and lack of logical reasoning skills to cope with problems in specialized areas requiring complex reasoning.
- KAG. Introduces a logical-symbol guided hybrid reasoning engine with powerful logical reasoning and multi-hop factual quizzing to handle more complex and specialized problems.
3. Performance:
- RAG. It performs poorly in the multi-hop task and the cross-paragraph task, generating text that is relatively weak in coherence and logic.
- KAG. It performs well in multi-hop and cross-passage tasks, significantly improving reasoning accuracy and information coverage, and generating more accurate and comprehensive answers.
4. Applicable scenarios:
- RAG. It is more suitable for general text generation and retrieval tasks, but performance will be limited in specialized fields such as law, medicine, and science, which require complex reasoning.
- KAG. Particularly suitable for complex reasoning and multi-hop factual quizzes that require Area of specializationThe company is able to provide more specialized and accurate knowledge services, such as financial, medical, legal, and governmental affairs.
All in all, by fusing knowledge graph and vector retrieval, and deeply optimizing the knowledge representation and reasoning capability, KAG shows the potential to surpass the traditional RAG technology in dealing with complex problems and professional domain knowledge Q&A.
Local deployment of "feeding level" tutorial: KAG installation, use, the effect of the demo
Theoretical analysis needs to be tested in practice! Next, I'll show you how to install, deploy and use KAG locally by hand, with a simple demonstration of the results.
KAG Related Resources:
- Github Address.https://github.com/OpenSPG/KAG
- Official website.https://spg.openkg.cn/
Hardware Configuration Recommendations:
- CPU ≥ 8 cores
- Memory RAM ≥ 32 GB
- Hard disk Disk ≥ 100 GB
The official recommended configuration is high, but according to my actual test, it can run basically smoothly on a Windows PC with 16GB RAM. Therefore, this tutorial will demonstrate the installation and use of KAG in a Windows environment.
Step 1: Install Docker Desktop
The installation and deployment of KAG relies on a Docker environment, so make sure you have Docker Desktop installed on your computer.
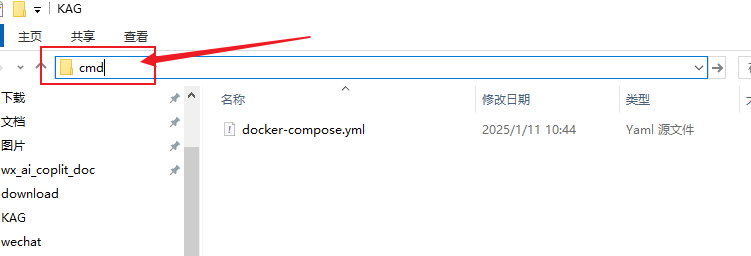
Step 2: Create the docker-compose.yml file
- Create a folder named KAG in the root directory of your D drive (or other disk).
- Inside the KAG folder, create a new file called docker-compose.yml.
- Copy and paste the following YAML code into the docker-compose.yml file and save it.
version: "3.7"
services.
server: "3.7
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-server:latest
container_name: release-openspg-server
ports.
- "8887:8887"
depends_on.
- mysql
- neo4j
- minio
# volumes.
# - /etc/localtime:/etc/localtime:ro
environment: /etc/localtime:/etc/localtime:ro
TZ: Asia/Shanghai
LANG: C.UTF-8
command: [
"java",
"-Dfile.encoding=UTF-8",
"-Xms2048m",
"-Xmx8192m",
"-jar".
"arks-sofaboot-0.0.1-SNAPSHOT-executable.jar",
'---server.repository.impl.jdbc.host=mysql',
'--server.repository.impl.jdbc.password=openspg',
'---builder.model.execute.num=5',
'--cloudext.graphstore.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j',
'--cloudext.searchengine.url=neo4j://release-openspg-neo4j:7687?user=neo4j&password=neo4j@openspg&database=neo4j'
]
mysql.
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-mysql:latest
container_name: release-openspg-mysql
volumes: mysql_data:release-openspg-mysql
- mysql_data:/var/lib/mysql
environment: mysql_data:/var/lib/mysql
TZ: Asia/Shanghai
LANG: C.UTF-8
MYSQL_ROOT_PASSWORD. openspg
MYSQL_DATABASE: openspg
ports.
- "3306:3306"
command: [
'--character-set-server=utf8mb4',
'--collation-server=utf8mb4_general_ci'
]
neo4j.
restart: always
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-neo4j:latest
container_name: release-openspg-neo4j
ports.
- "7474:7474"
- "7687:7687"
environment.
- TZ=Asia/Shanghai
- NEO4J_AUTH=neo4j/neo4j@openspg
- NEO4J_PLUGINS=["apoc"]
- NEO4J_server_memory_heap_initial__size=1G
- NEO4J_server_memory_heap_max__size=4G
- NEO4J_server_memory_pagecache_size=1G
- NEO4J_apoc_export_file_enabled=true
- NEO4J_apoc_import_file_enabled=true
- NEO4J_dbms_security_procedures_unrestricted=*
- NEO4J_dbms_security_procedures_allowlist=*
NEO4J_dbms_security_procedures_unrestricted
- neo4j_logs:/logs
- neo4j_data:/data
minio.
image: spg-registry.cn-hangzhou.cr.aliyuncs.com/spg/openspg-minio:latest
container_name: release-openspg-minio
command: server --console-address ":9001" /data
command: server --console-address ":9001" /data
environment: MINIO_ACCESS_KNOWLEDGE
MINIO_ACCESS_KEY: minio
MINIO_SECRET_KEY: minio@openspg
TZ: Asia/Shanghai
TZ: Asia/Shanghai
- 9000:9000
- 9001:9001
volumes: minio_data:/data
- minio_data:/data
volumes: minio_data:/data
mysql_data.
neo4j_logs.
minio_data: minio_data:/data volumes: mysql_data.
minio_data.
Step 3: Start the KAG service
- Open a command prompt and switch to the KAG folder directory (enter cmd in the KAG folder address field).
- Type docker-compose up -d at the command line and enter to begin automated installation and deployment of KAG.
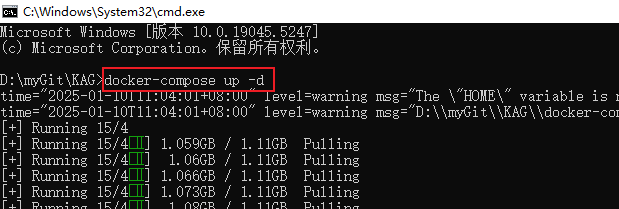
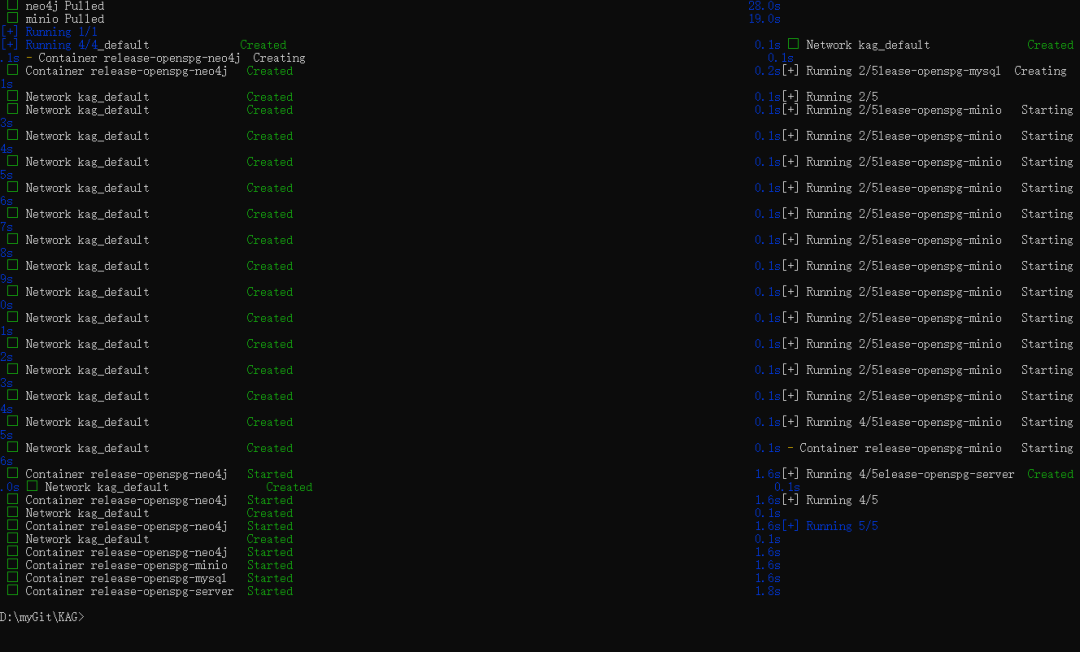
- Wait for some time, when you see mysql, neo4j, openspg-server, minio four services are displayed Created or Started status, it means that the KAG service has been successfully started.
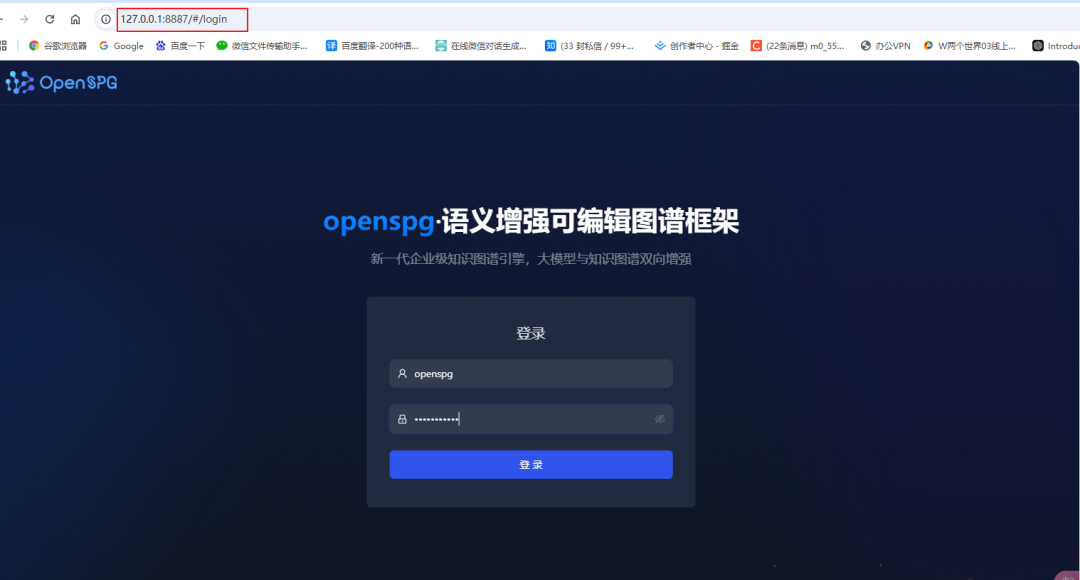
Step 4: Visit the KAG backend administration page
- Open your browser and enter the address 127.0.0.1:8887 to access the KAG background operation page.
- Log in to the system using the default username openspg and the default password openspg@kag.
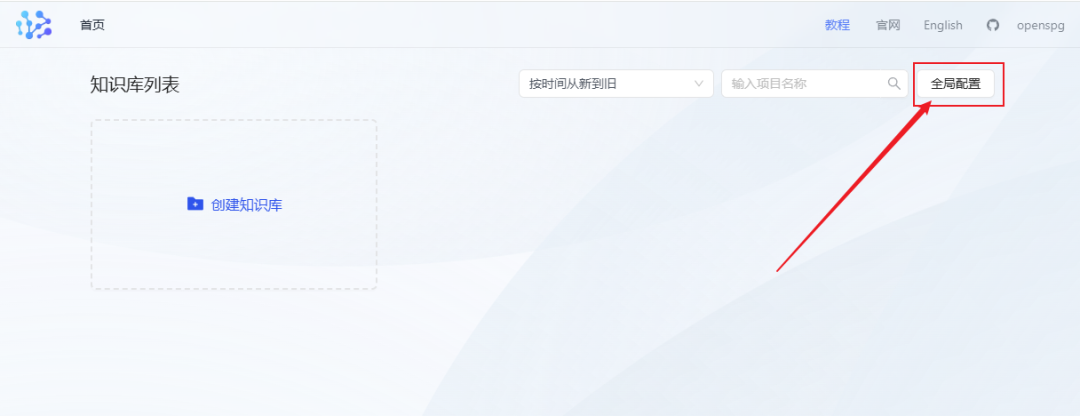
Step 5: Configure the KAG system
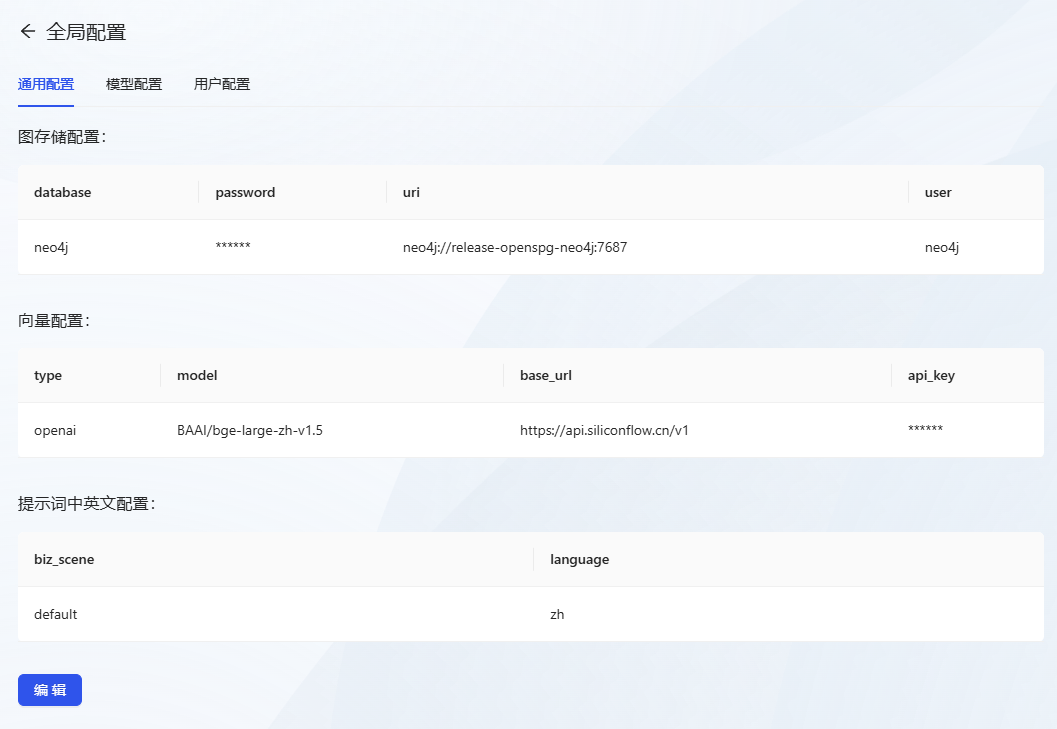
- After logging in, first click the Global Configuration menu.
- Common Configurations: Perform the following configuration
- Figure Storage Configuration
- database:neo4j
- password: neo4j@openspg
- uri: neo4j://release-openspg-neo4j:7687
- user:neo4j
- Cue word configuration in English and Chinese
- biz_scene: default
- Language: zh
- vector configuration (computing) (using the free Vector Model API)
- type: openai
- model: BAAI/bge-large-zh-v1.5
- base_url:https://api.siliconflow.cn/v1
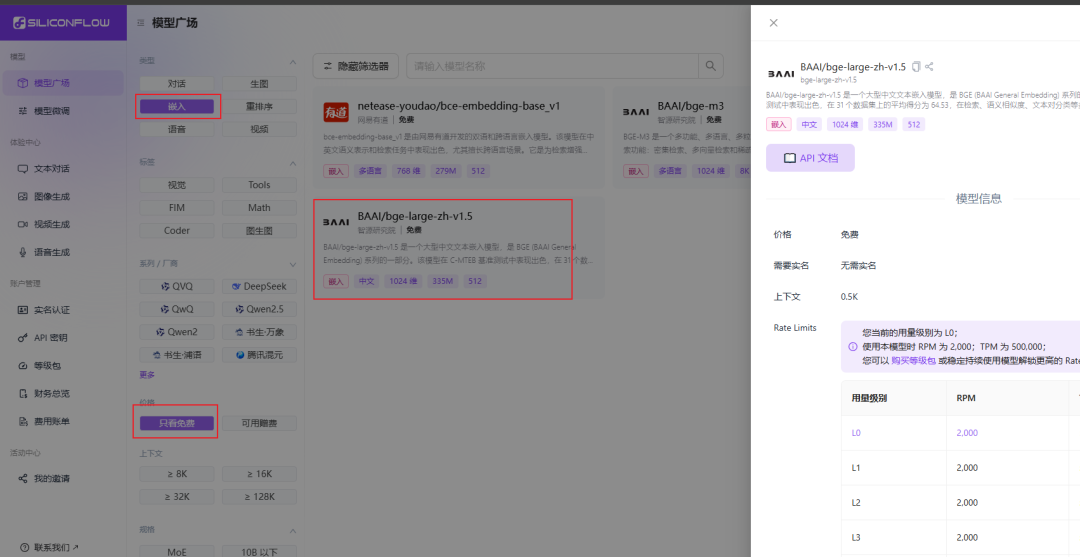
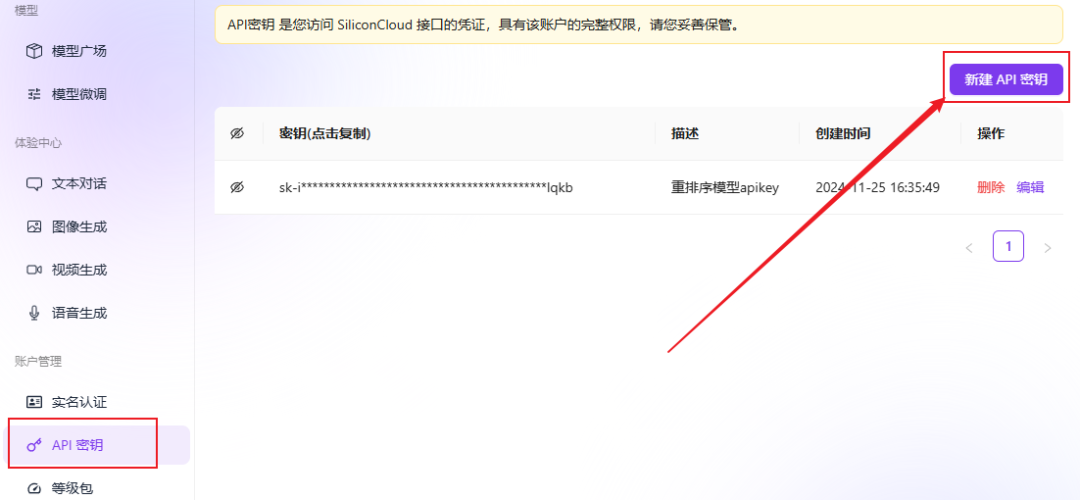
- api_key: go to Silicon-based flow platform to get a free API Key.
- Silicon-based flow After registering and logging in to the platform, you can find the free vector model and create an API key by following the guidelines in the image below.
- Model Configuration: Click Add maas model (compatible with openai interface), configure the large language model you wish to use.
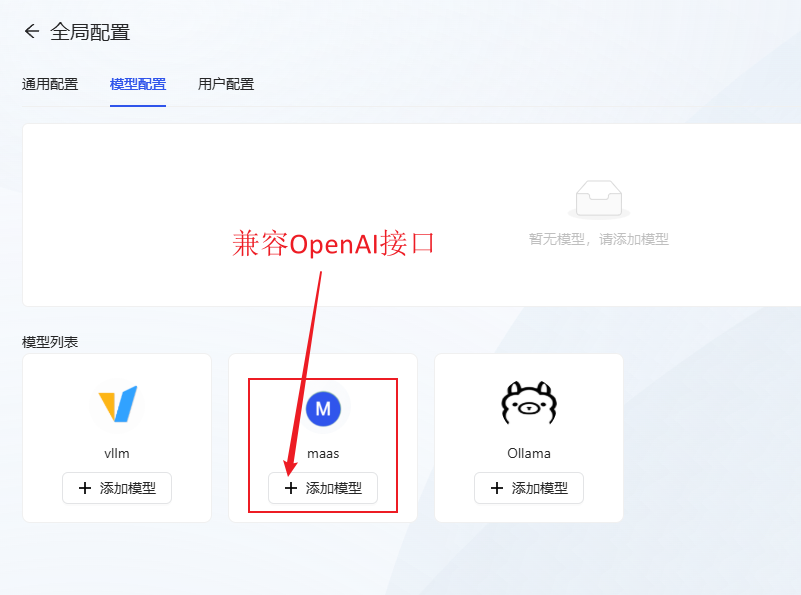
- Take gpt-4o as an example, fill in the model information and click OK to save.
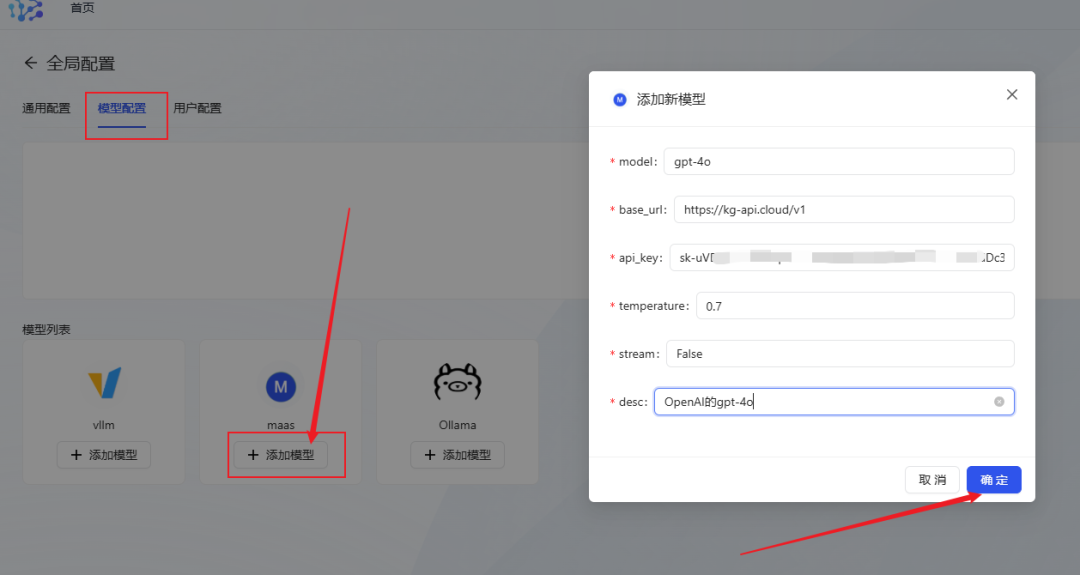
- Model API relay station recommendationIf you have a variety of big model API call needs, you can consider using API transit service, which is compatible with OpenAI interface, supports one-click switching between domestic and foreign mainstream big models, and provides MJ, SD, and Suno and other drawing and music creation interfaces. The price is also more favorable.
Step 6: Create a Knowledge Base and Import Documents
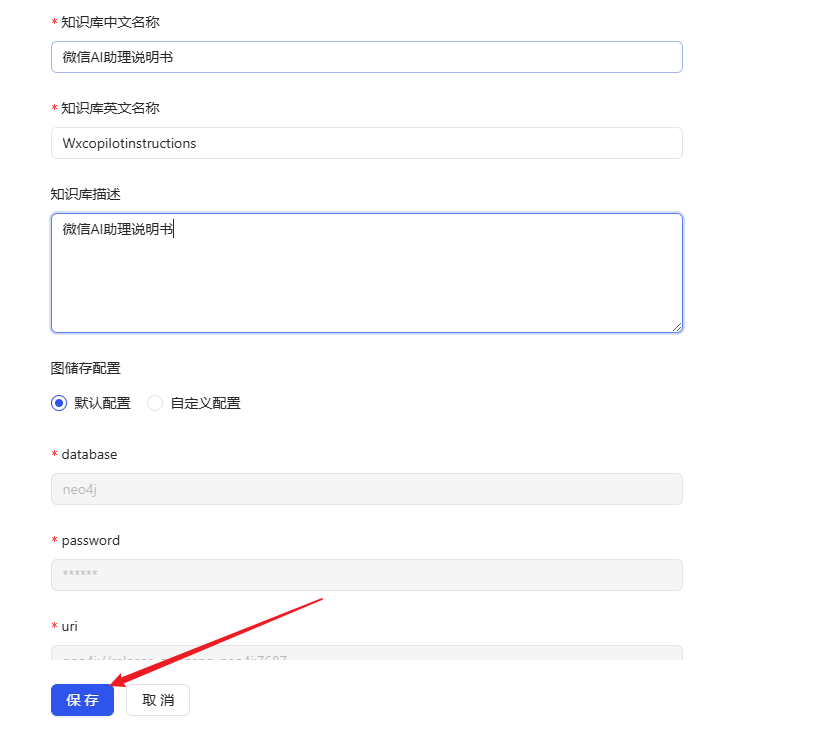
- Return to the home page and click Create Knowledge Base.

- Name the knowledge base and click Save.
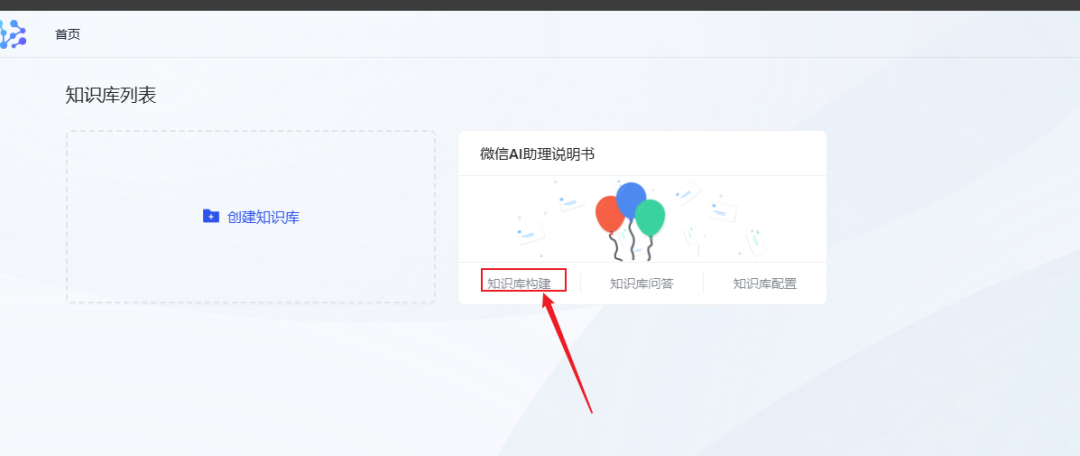
- After successful creation, find the newly created knowledge base on the home page and click Knowledge Base Build.
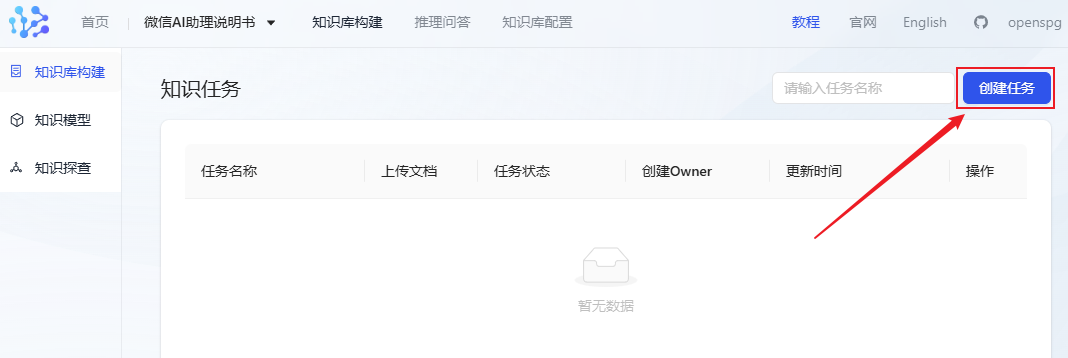
- Click Create Task to start importing documents.
- Upload your knowledge base documents (currently KAG only supports uploading one document at a time, if you have multiple documents you need to upload them in batches). Here I have uploaded documents related to my latest product, WeChat AI Assistant.
- Call for File Merge Tool Sharing: If you have a good free file merger tool, welcome to share it in the comment section for easy batch processing of documents.
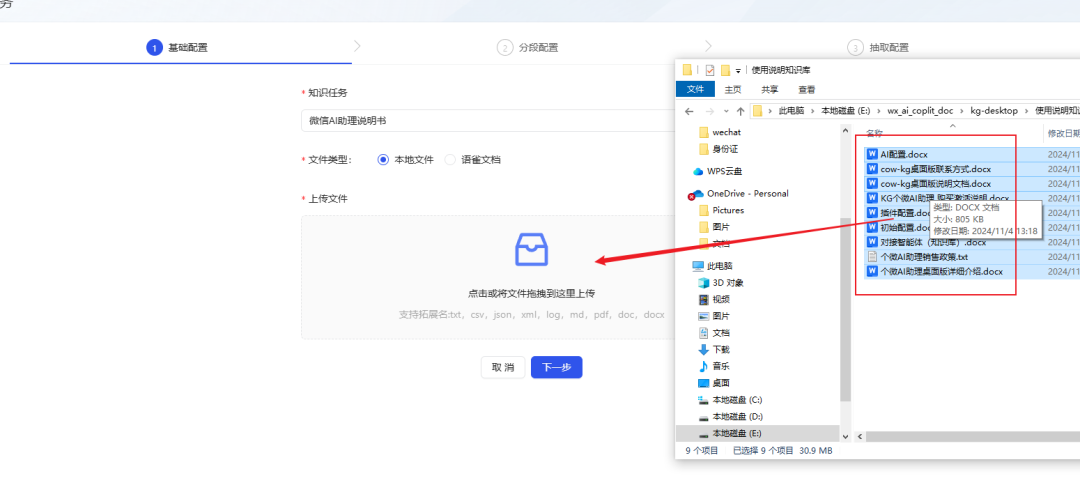
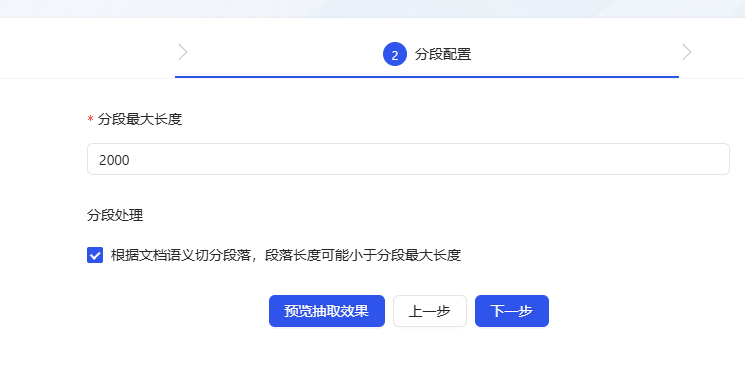
- In the next step of the setup, it is recommended to check Split paragraphs according to document semantics to preserve the contextual coherence of the paragraphs.
- extraction model option default (the default configuration is fine). clue Can be customized as needed, here I simply set it to "Q&A Split" (understanding is not always accurate, welcome to correct).
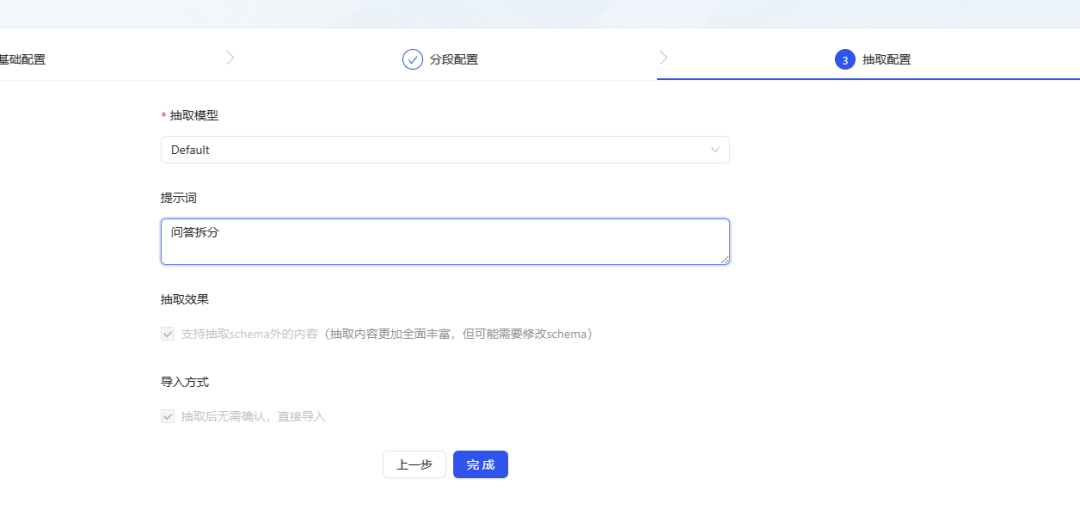
- Click Finish and the KAG begins extracting and parsing the document, a process that may take some time.
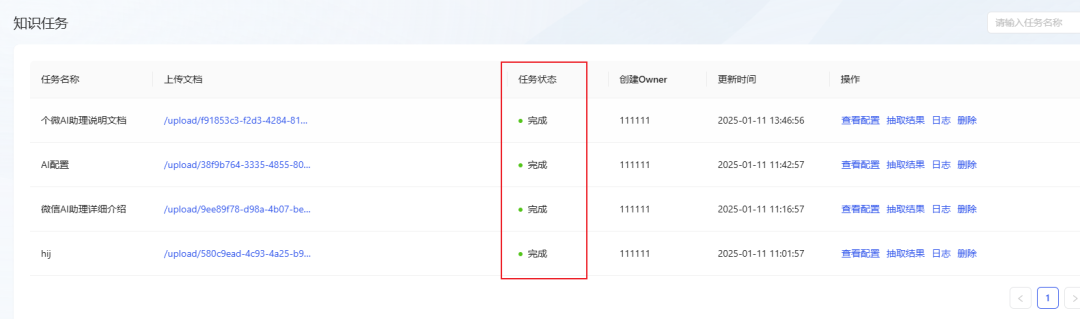
- The document parsing process is divided into 6 steps, as shown in the following figure:
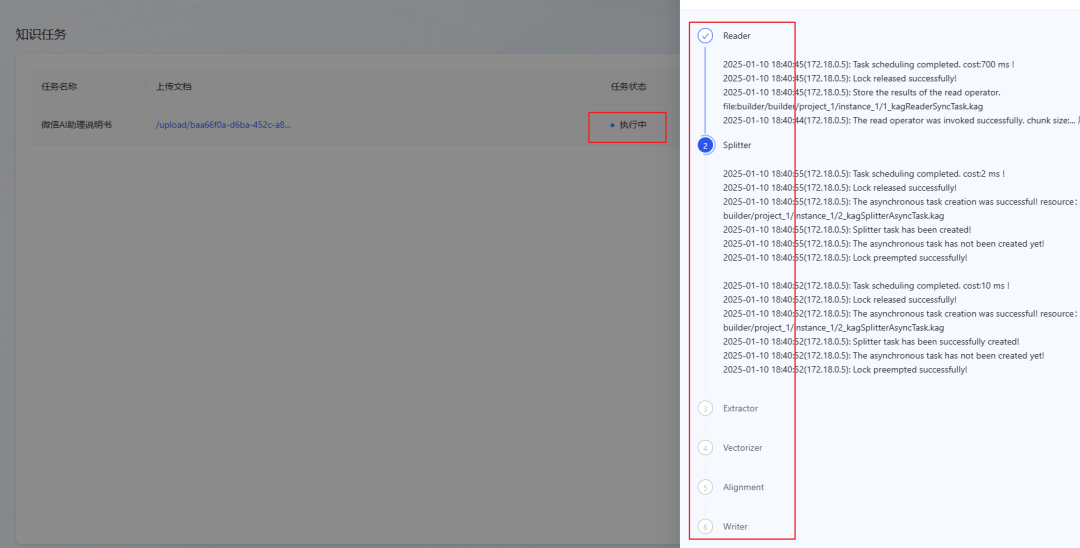
- Wait for the task status to change to Completed, indicating that the document has been successfully imported into the Knowledge Base. (If the status has not been updated for a long time, try refreshing the page).
Step 7: Demonstration of the effect
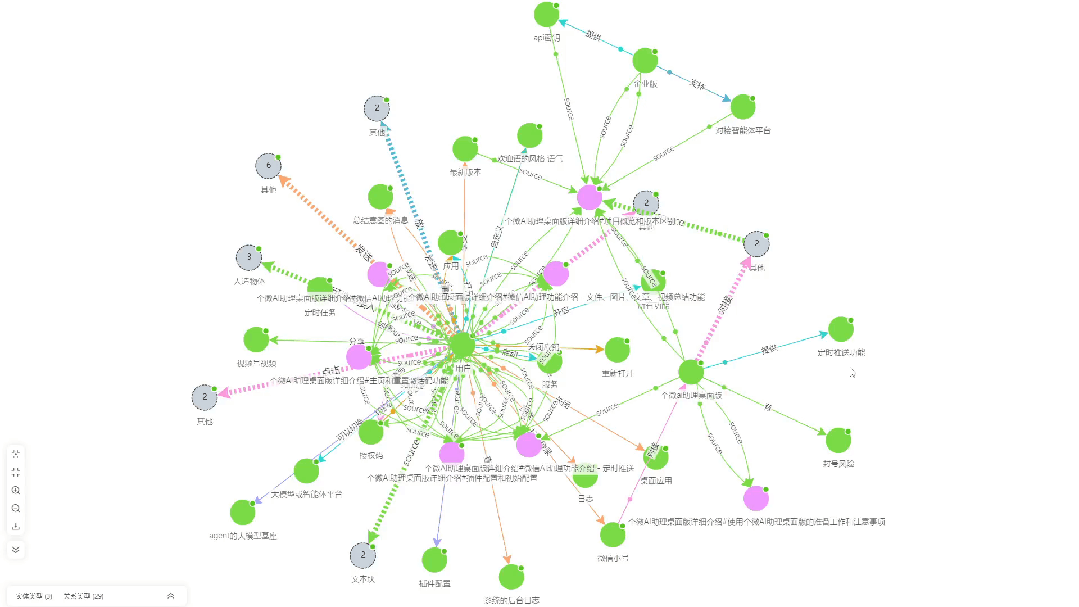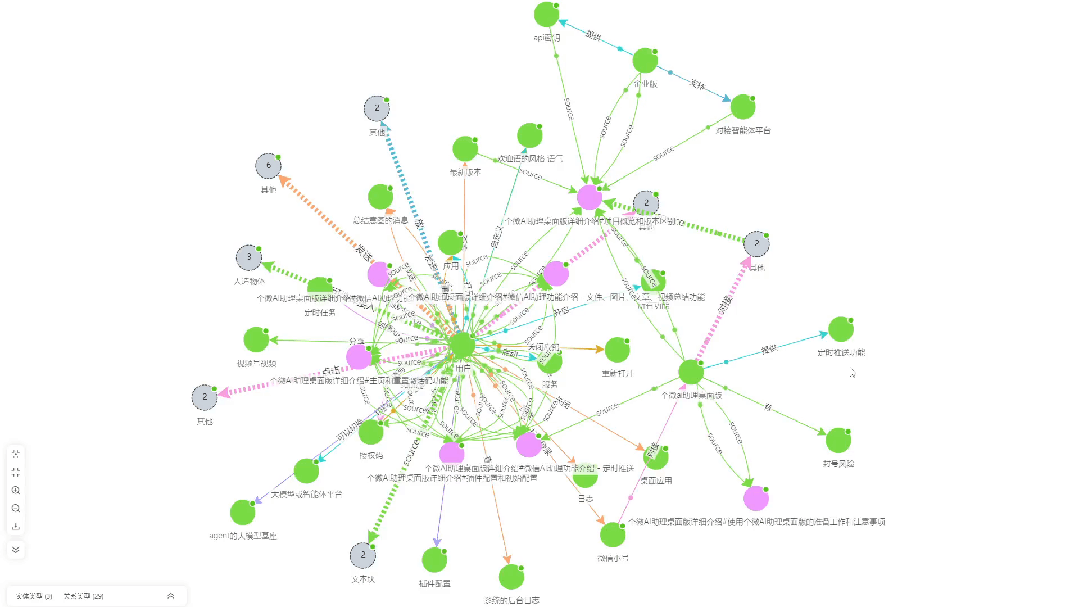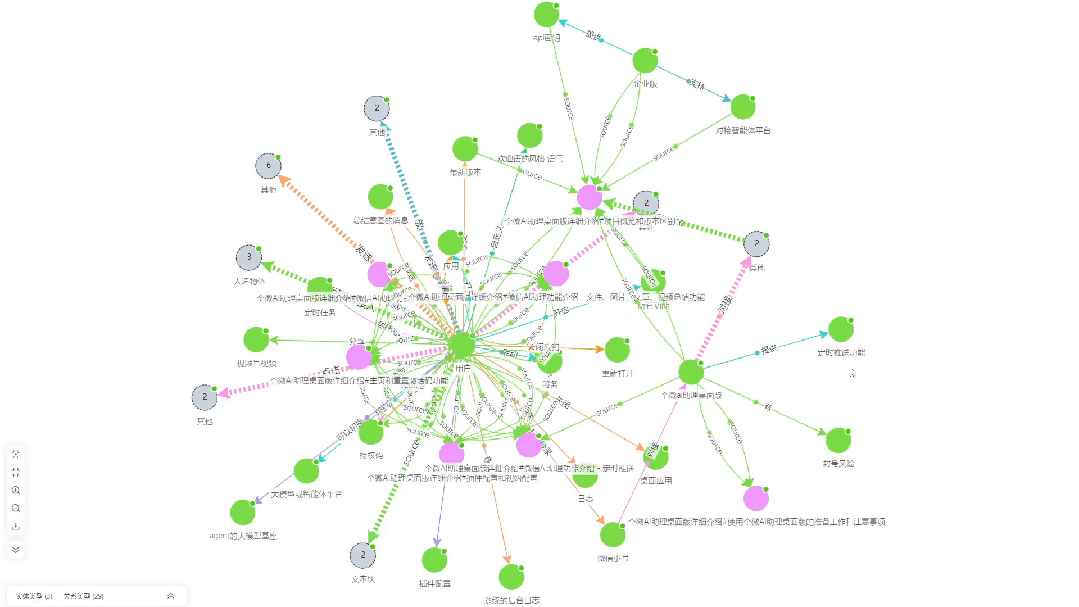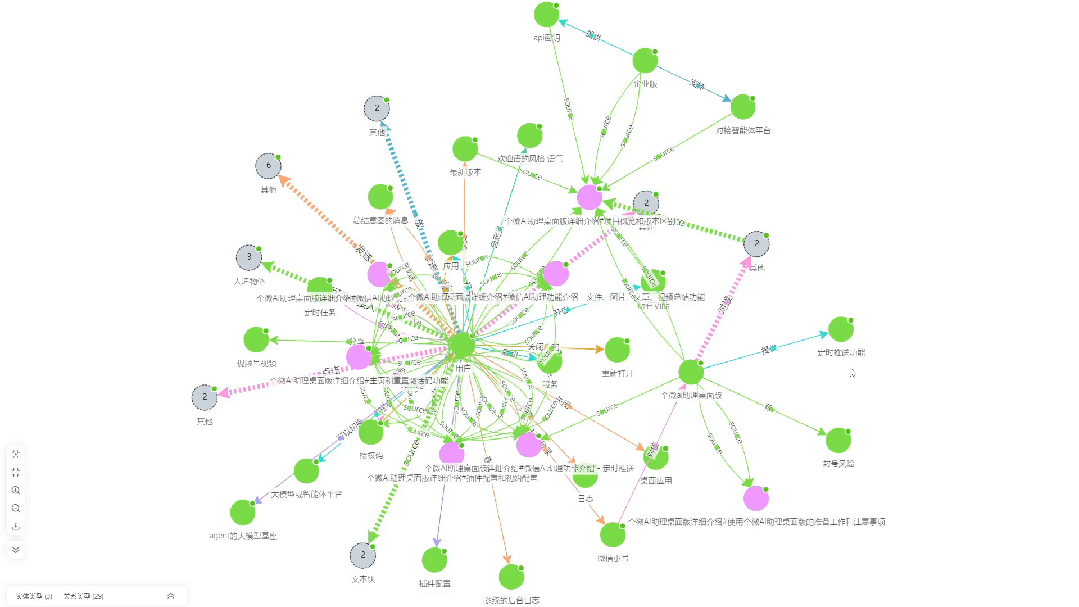
- Knowledge extraction correlation diagram: This is a visualization of the knowledge association relationships that KAG extracts from the document.
- Q&A Effectiveness Test::
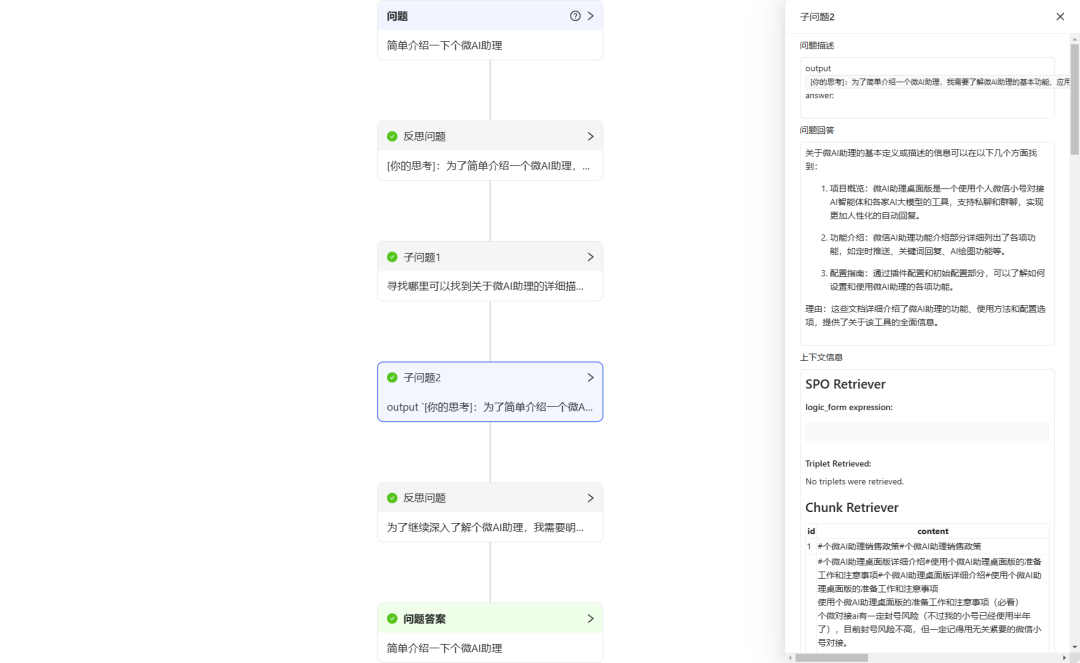
- Question 1: "Briefly introduce the Personal Micro AI Assistant."
KAG performs a process of thinking and reasoning, then retrieves and gives the answer. As you can see, the answers given by KAG are relatively accurate and comprehensive. However, the response time is slow, about 40 seconds (so KAG may not be suitable for simple Q&A scenarios).

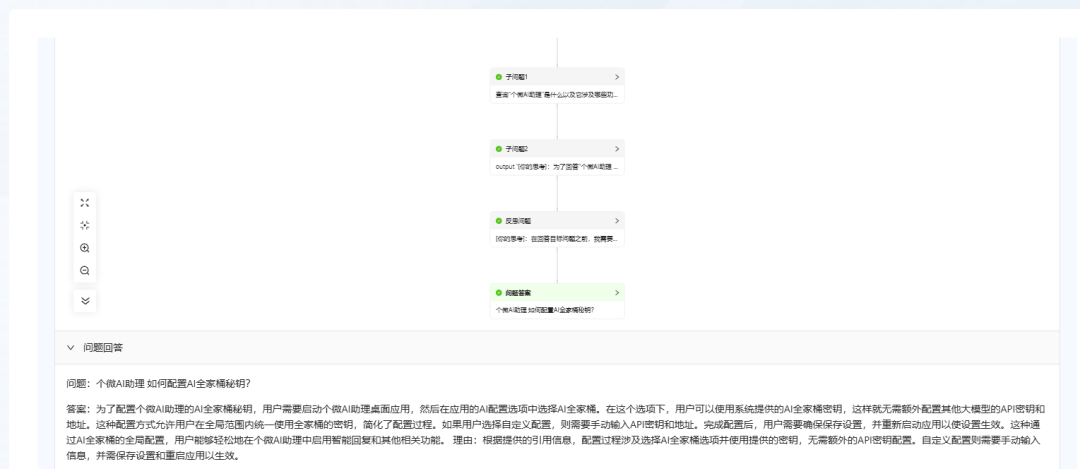
- Question 2: "How to configure the AI Family Bucket secret key for Personal Micro AI Assistant?"
KAG is also able to provide an answer, but it still takes longer.
Summary and outlook
Through the above experience, we can see that the ant open source KAG knowledge base framework is still in the rapid development stage, some features and user experience is still to be improved (such as knowledge base parameter adjustment, knowledge base editing and modification of the function is not perfect, the use of the use of some Bugs may also be encountered). However, from the Github update records, the KAG team is actively carrying out code iteration and functional optimization.
The technical direction of KAG fusing Knowledge Graph and Vector Retrieval is very promising. Just as RAG technology requires high-quality knowledge base data, model augmentation, and parameter tuning to achieve the best results, the development of KAG also requires continuous improvement and optimization.
As mentioned at the beginning of the article, KAG is better suited for specialized fields that require complex reasoning, such as healthcare, finance, law, and government, rather than simple day-to-day question-and-answer scenarios (where responsiveness is a shortcoming).
At present, KAG has not yet opened the API, and it is expected that after the API is opened in the future, it can be integrated into the Agent application, and through the problem recognition mechanism, simple and complex problems can be handled separately, so as to realize the advantages of KAG in complex problem processing.
All in all, this article aims to give you a taste of the cutting-edge technology that is KAG. Although KAG may not be perfect yet, it has shown great potential as an open source knowledge base framework. We believe that with the joint efforts of the community and the continuous iteration of the technology, KAG will bring more possibilities to the field of AI knowledge bases.