
Rolled Up! Long Text Vector Model Chunking Strategies Competition

The Long Text Vector Model can encode ten pages of text into a single vector, which sounds powerful, but is it really practical?
A lot of people think... Not necessarily.
Is it okay to use it directly? Should it be chunked? What is the most efficient way to chunk? In this article, we will take you to explore different chunking strategies for long text vector models, analyze the pros and cons, and help you avoid pitfalls.
The Problem of Long Text Vectorization
First, let's see what problems there are with compressing an entire article into a single vector.
As an example of building a document search system, a single article may contain multiple topics. For example, this blog on the ICML 2024 attendee report contains an introduction to the conference, a presentation of Jina AI's work (jina-clip-v1) and summaries of other research papers. If the entire article is vectorized into a single vector, that vector will mix information from three different topics:
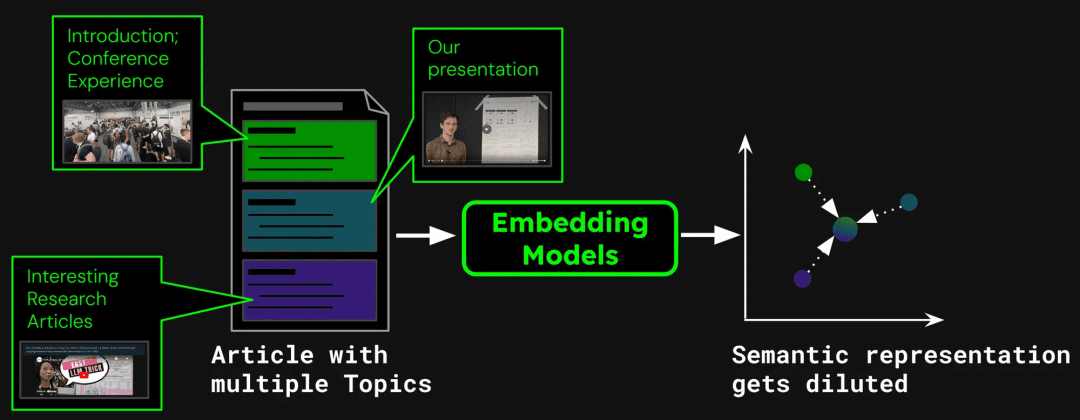
This can lead to the following problems:
1. Presentation Dilution
indicates that dilution weakens the precision of the text vectors. While blog posts contain multiple topics, theHowever, user search queries tend to focus on only one of these. Representing the entire article with a single vector is equivalent to compressing all the topic information into a single point in the vector space. As more text is added to the model's input, this vector progressively represents the overall subject matter of the article, diluting the details of particular passages or topics. This is like mixing multiple paints into a single color, making it difficult for a user to identify a specific color from the mix when trying to find it.
2. Limited capacity
The dimension of the vector generated by the model is fixed, and the long text contains a lot of information, which will inevitably lead to a loss of information in the transformation process. It is like compressing a high-definition map into a postage stamp, and many details are not visible.
3. Loss of information
Many long text models can only handle up to 8192 tokens. better text will have to be truncated, usually to the end, and if the key information is at the end of the document, the retrieval may fail.
4. Segmentation requirements
Some applications only need to vectorize specific segments of text, such as question and answer systems, where only the paragraphs containing the answers need to be extracted for vectorization. In this case, chunking of the text is still required.
3 Long Text Processing Strategies
Before we start the experiment, we first define three chunked strategies in order to avoid conceptual confusion:
1. No Chunking:Encodes the entire text directly into a single vector.
2. Naive Chunking:The text is first divided into multiple text chunks and vectorized separately. Commonly used methods include fixed-size chunking, which splits the text into fixed token number of chunks; sentence-based chunking: chunking in sentences; semantic-based chunking: chunking based on semantic information. In this experiment, fixed size chunking is used.
3. Late Chunking:It is a new method of reading through the whole text before chunking it and consists of two main steps:
- Full text of the code: Encode the entire document first to get a vector representation of each token, preserving the complete contextual information.
- chunk pooling: Generate vectors for each text block by average pooling the token vectors of the same text block according to the chunk boundary. Since the vector of each token is generated in the context of the full text, late partitioning can preserve the contextual information between blocks.
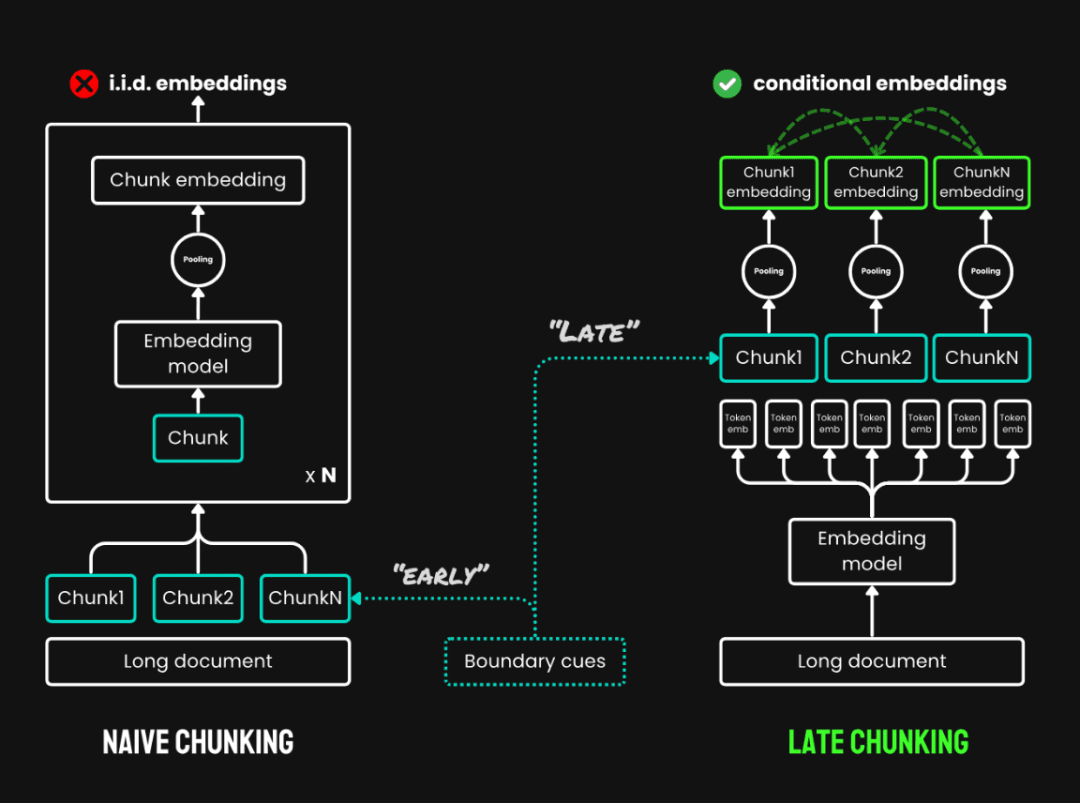
Late division vs. plain chunking
For models that exceed the maximum input length (e.g., 8192 tokens) of very long text, we use Long Late Chunking, adds a pre-segmentation step to late-splitting by first splitting the document into multiple overlapping macroblocks, each of which has a length within the model's processable range. Then, a standard late-splitting strategy (encoding and pooling) is applied inside each macroblock. The overlap between macroblocks is used to ensure continuity of contextual information.
Late Score Specific Implementation Code: https://github.com/jina-ai/late-chunking在 Notebook Experience: https://colab.research.google.com/drive/1iz3ACFs5aLV2O_ uZEjiR1aHGlXqj0HY7?usp=sharing
So, which is the best method?
For comparison purposes, we used the data on 5 datasets, using the jina-embeddings-v3 Experiments were conducted where all long texts were truncated to the maximum input length of the model (8192 Tokens) and segmented into text blocks of 64 Tokens each.

The 5 test datasets also correspond to 5 different retrieval tasks
The figure below shows the difference in performance between the 3 methods on different tasks, no one method is best in all cases and the choice depends on the specific task.
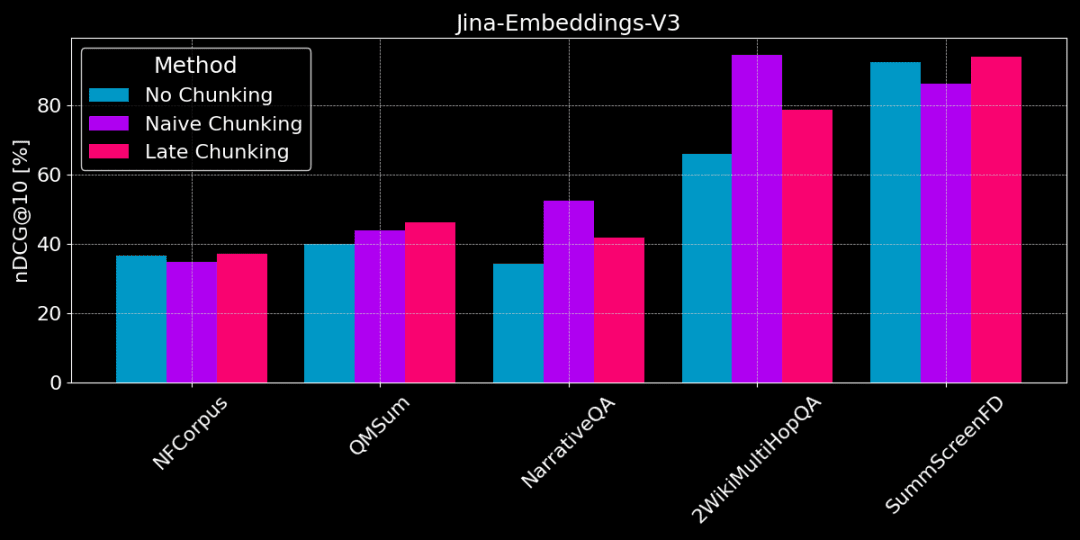
No chunking vs plain chunking vs late chunking
👩🏫 Find specific facts, plain chunking is good.
If specific, localized factual information needs to be extracted from text (e.g., "Who stole something?") ), datasets like QMSum, NarrativeQA, and 2WikiMultiHopQA, plain chunking performs better than vectorizing the entire document. Because answers are usually located in a specific part of the text, plain chunking can more accurately locate the chunk of text that contains the answer, without being distracted by other extraneous information.
But plain chunking also cuts off context and may lose global information to properly parse referential relationships and references in the text.
👩🏫 The article is thematically coherent and late scores are better.
Late marking is more effective if the subject matter is clear and the chapter structure is coherent. Because late division takes into account the context, it allows for a better understanding of the meaning and relevance of each part, including the referential relationships within long texts.
However, if there is a lot of irrelevant content in the article, the late scoring will take into account the "noise" and lead to performance regression and accuracy degradation. For example, NarrativeQA and 2WikiMultiHopQA do not perform as well as plain chunking because there is too much irrelevant information in these articles.
Does chunk size matter?
The following figure shows the performance of the plain chunking and late chunking methods on different datasets with different chunk sizes:
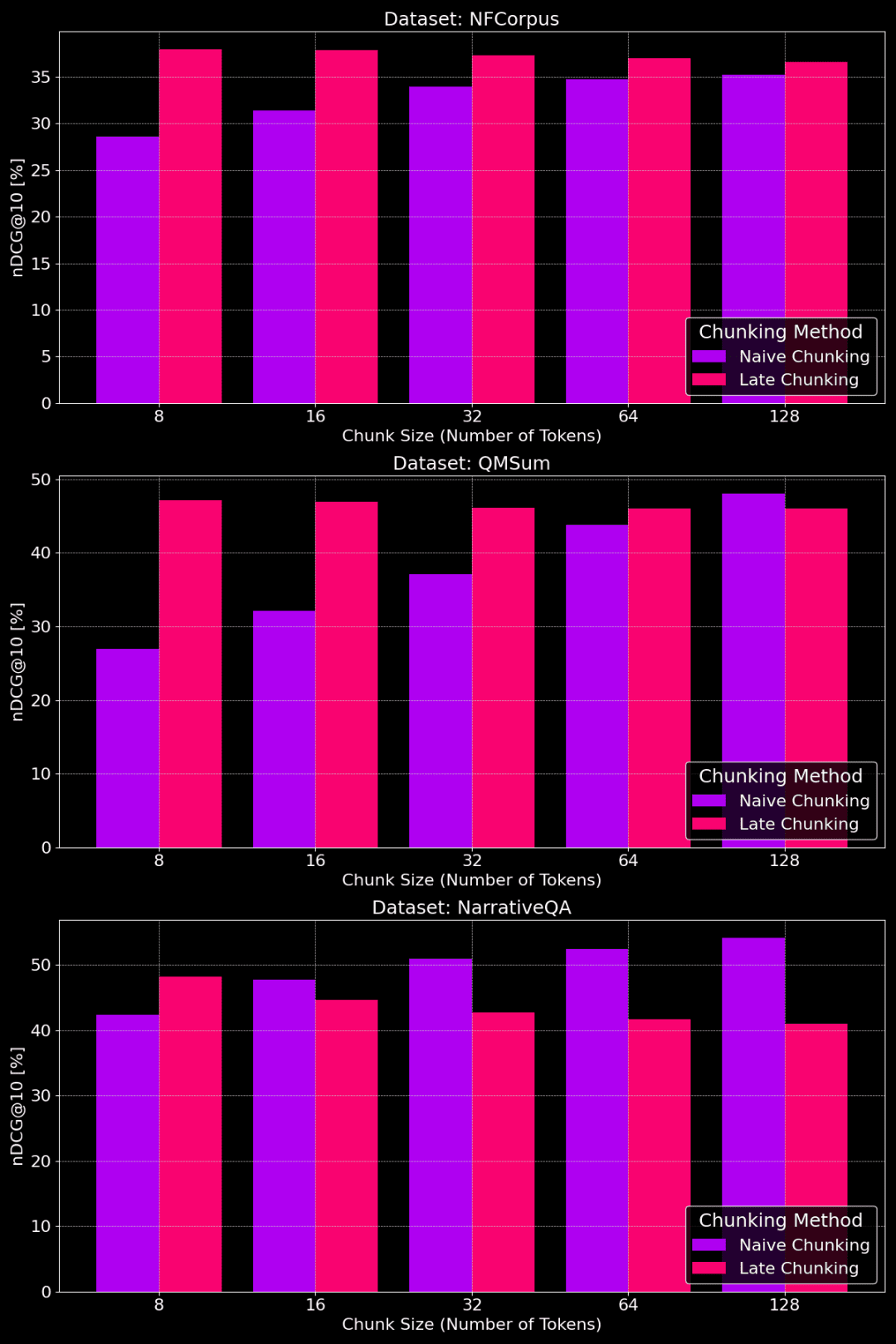
Performance comparison of plain chunking and late chunking with different chunk sizes
As we can see from the figure, the optimal chunk size actually depends on what the specific dataset looks like.
For the late-splitting method, smaller chunks capture the contextual information better, and so work better. In particular, if there is a lot of content in the dataset that is not related to the topic (as in the case of the NarrativeQA dataset), too large a context can instead introduce noise and hurt performance.
For plain chunking, larger chunks sometimes work better because the information contained is more comprehensive and less lossy. However, sometimes the chunks are too large and the information is too cluttered, which in turn reduces the accuracy of retrieval. So, the optimal chunk size needs to be adjusted to the specific dataset and task, and there is no one-size-fits-all answer.
After understanding the advantages and disadvantages of different chunking strategies, how do we choose the right one?
1. Where is full text vectorization (without chunking) appropriate?
- The theme is singular, with key information concentrated at the beginning:For example, in structured news stories, the key information is often in the headlines and opening paragraphs. In this case, direct use of full-text vectorization usually yields good results because the model is able to capture the main information.
- In general, putting as much text content as possible into the model will not affect the retrieval results. However, long text models tend to pay more attention to the beginning part (title, introduction, etc.), and the information in the middle and end parts may be ignored. So, if the key information is in the middle or at the end of the article, this method will be much less effective.
- Detailed experimental results are given in:https://jina.ai/news/still-need-chunking-when-long-context-models-can-do-it-all
2. For what situations is Naive Chunking appropriate?
- Variety of topics, need to retrieve specific information: If your text contains more than one topic, or if the user query targets a specific fact in the text, plain chunking is a good choice. It can effectively avoid information dilution and improve the accuracy of retrieving specific information.
- Need to show localized text snippets: Similar to a search engine, the need to display text snippets related to the query in the results necessitates a chunking strategy.
- Also, chunking affects storage space and processing time by having to vectorize more blocks of text.
3. Where does Late Chunking fit in?
- Topic coherence, need for contextual information: For long texts with coherent topics, such as essays, long reports, etc., the late partitioning method can effectively retain the contextual information so as to better understand the overall semantics of the text. It is especially suitable for tasks that require understanding the relationship between different parts of a text, such as reading comprehension and semantic matching of long texts.
- Need to balance local details with global semantics: The late-splitting method is effective in balancing local details and global semantics in smaller chunk sizes, and in many cases can achieve better results than the other two methods. However, it is important to note that if the article has a lot of irrelevant content, late partitioning will be affected by the consideration of such irrelevant information.
reach a verdict
The selection of a long text vectorization strategy is a complex issue, with no one-size-fits-all best solution, and requires consideration of data characteristics and retrieval goals, including the previously mentioned text length, number of topics, and location of key information.
In this paper, we hope to provide a comparative analysis framework about different chunking strategies and provide some references through experimental results. In practical application, you can compare more experiments and choose the most suitable strategy for your scenario.
If you're interested in long text vectorizationjina-embeddings-v3Offering advanced long text processing capabilities, multi-language support, and late scoring, it's worth trying.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...