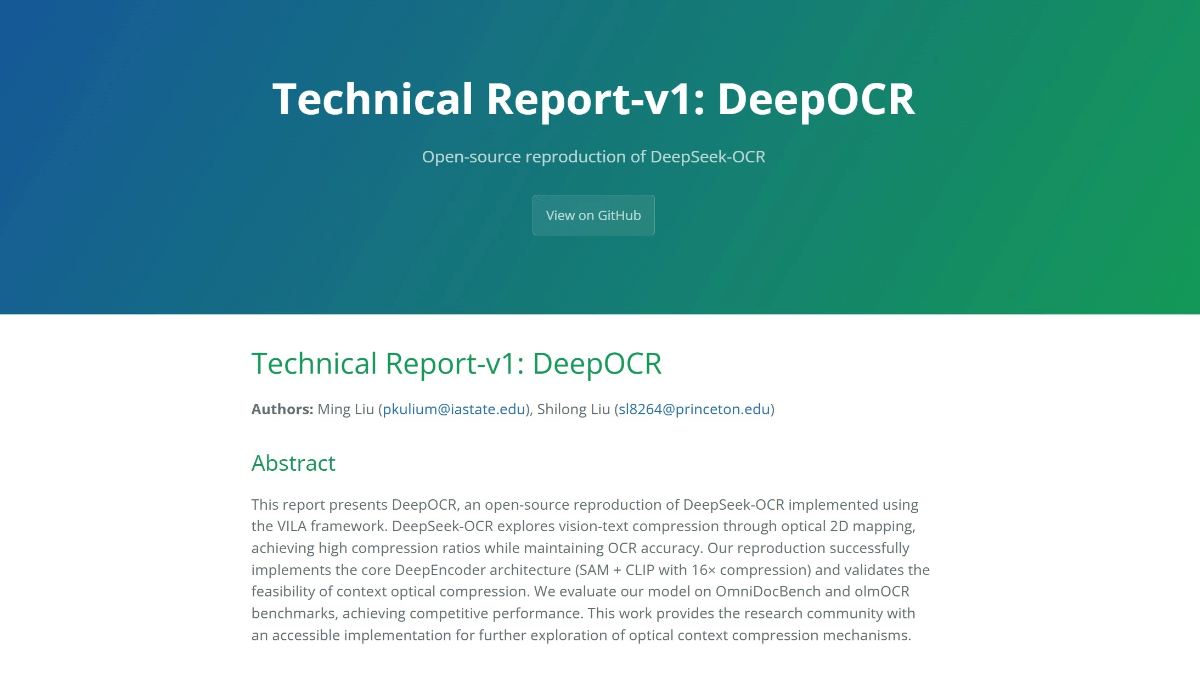
HumanOmni: a multimodal macromodel for analyzing human video emotions and actions

General Introduction
HumanOmni is an open source multimodal big model developed by the HumanMLLM team and hosted on GitHub. It focuses on analyzing human video and can process both picture and sound to help understand emotions, actions, and conversational content. The project used 2.4 million human-centered video clips and 14 million command data for pre-training, and 50,000 hand-labeled video clips (with more than 100,000 commands) for fine-tuning. humanOmni handles facial, bodily, and interactional scenarios in three branches, and dynamically adapts fusion methods based on inputs. It is the industry's first human-centered multimodal model and outperforms many similar models. The team has also launched R1-Omni based on it, which for the first time incorporates reinforcement learning to improve inference. The code and some of the datasets are open for easy access by researchers and developers.

Function List
- emotion recognition: Analyze facial expressions and voice tones in videos to determine character emotions, such as happy, angry, or sad.
- Description of facial expressions: Recognize and describe facial details of a person, such as a smile or a frown.
- Action Understanding: Analyze the movements of people in a video and describe what they are doing, such as walking or waving.
- speech processing: Extracts content from audio and supports speech recognition and intonation analysis.
- multimodal fusion: Combine picture and sound to understand complex scenes and provide more accurate analysis.
- Dynamic Branch Adjustment: Handle different scenes with three branches: face, body, and interaction, automatically adjusting weights.
- Open Source Support:: Provide code, pre-trained models and partial datasets to support secondary development.
Using Help
HumanOmni is suitable for users with a technical base, such as developers or researchers. The following installation and usage steps are detailed enough to get started straight away.
Installation process
To run HumanOmni, you need to prepare your environment first. The following are the specific steps:
- Check hardware and software requirements
- Operating System: Supports Linux, Windows or macOS.
- Python: requires version 3.10 or higher.
- CUDA: 12.1 or higher recommended (if using a GPU).
- PyTorch: Requires version 2.2 or higher, with CUDA support.
- Hardware: NVIDIA GPUs are recommended, CPUs work but are slow.
- Download Code
Open a terminal and enter the command to download the project:
git clone https://github.com/HumanMLLM/HumanOmni.git
cd HumanOmni
- Creating a Virtual Environment
Create separate environments with Conda to avoid conflicts:
conda create -n humanOmni python=3.10 -y
conda activate humanOmni
- Installation of dependencies
The project has arequirements.txtfile that lists the required libraries. Run the following command to install them:
pip install --upgrade pip
pip install -r requirements.txt
pip install flash-attn --no-build-isolation
- Download model weights
HumanOmni has three models:
HumanOmni-Video: Processing Video, 7B Parameters.HumanOmni-Audio: Processing Audio, 7B Parameters.HumanOmni-Omni: fusion of video and audio, 7B parameters (referred to as HumanOmni).
Download from Hugging Face or ModelScope, for example:- HumanOmni-7B
- HumanOmni-7B-Video
Download it and put it in the project folder.
- Verify Installation
Check the environment with the test command:
python inference.py --modal video --model_path ./HumanOmni_7B --video_path test.mp4 --instruct "Describe this video."
If the video description is output, the installation is successful.
Functional operation flow
At the heart of HumanOmni is analyzing video and audio. Below is a detailed breakdown of how the main features work.
1. Emotion recognition
- move
- Prepare a video containing a character (e.g.
sample.mp4). - Run command:
python inference.py --modal video_audio --model_path ./HumanOmni_7B --video_path sample.mp4 --instruct "Which emotion is most obvious?"
- The model outputs emotions such as "angry" or "happy".
- take note of
- The video should be clear and the characters' expressions and voices need to be recognizable.
- Longer videos may require more computation time.
2. Description of facial expressions
- move
- Enter the video and run:
python inference.py --modal video --model_path ./HumanOmni_7B --video_path sample.mp4 --instruct "What’s the major facial expression?"
- The output may be "smile" or "frown" with a brief description.
- suggestion
- Testing with short 10-30 second videos works better.
3. Movement understanding
- move
- Enter the video and run:
python inference.py --modal video --model_path ./HumanOmni_7B --video_path sample.mp4 --instruct "Describe the major action in detail."
- Outputs a description of the action, such as "a person is walking".
- finesse
- Make sure the action is obvious and avoid background clutter.
4. Speech processing
- move
- Input video with audio, run:
python inference.py --modal audio --model_path ./HumanOmni_7B --video_path sample.mp4 --instruct "What did the person say?"
- Output voice content, such as "Dogs are sitting by the door".
- take note of
- Audio should be clear and work best without noise.
5. Multimodal fusion
- move
- Input video and audio, run:
python inference.py --modal video_audio --model_path ./HumanOmni_7B --video_path sample.mp4 --instruct "Describe this video."
- The model will give a full description in conjunction with the picture and sound.
- dominance
- Ability to capture the correlation between emotions and actions for a more comprehensive analysis.
6. Training on customized data sets
- move
- Prepare a data file in JSON format containing the video path and command dialog. For example:
[
{
"video": "path/to/video.mp4",
"conversations": [
{"from": "human", "value": "What’s the emotion?"},
{"from": "gpt", "value": "sad"}
]
}
]
- downloading
HumanOmni-7B-Videocap (a poem)HumanOmni-7B-AudioWeights. - Run the training script:
bash scripts/train/finetune_humanomni.sh
- use
- It is possible to optimize the model with your own video data.
Frequently Asked Questions
- Runtime Error: Check that the Python and PyTorch versions match.
- Model Load Failure: Confirm that the path is correct and that there is enough disk space (about 10GB for the model).
- The results are not accurate.: Switch to clear video or adjust instruction presentation.
With these steps, users can easily install and use HumanOmni and experience its powerful features.
application scenario
- Educational research
Analyze classroom videos to identify student mood and engagement and help teachers adjust their teaching style. - medical assisting
The patient's expression and tone of voice aids the physician in determining psychological states, such as anxiety or depression. - film and television production
Analyze character emotions and actions to generate subtitles or plot descriptions to enhance creative efficiency. - social analytics
Used for conference video to understand participants' emotions and behaviors and optimize communication.
QA
- What file formats are supported?
Supports MP4 format, audio needs to be embedded in the video. - Do I need to network?
Not required. Download the code and model for offline use. - How does the model perform?
In terms of emotional comprehension, HumanOmni's DFEW data UAR amounted to 74.861 TP3T, far exceeding the 50.571 TP3T of GPT4-O. The average score for action comprehension was 72.6, which was higher than the 67.7 of Qwen2-VL-7B. - Can ordinary people use it?
Basic programming skills are required. If you don't know how to code, it is recommended to ask a technician for help.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts
![FLUX.1 Krea [dev] - 黑森林和Krea AI联合推出的文生图模型](https://aisharenet.com/wp-content/uploads/2025/08/1754032748-1754032748-FLUX.1-Krea-dev-website-2.png)


No comments...