
Advanced RAG: Architecture, Technology, Applications and Development Perspectives

Retrieval-augmented generation (RAG) has become an important framework in the AI field, greatly improving the accuracy and relevance of large language models (LLMs) when generating responses using external knowledge sources. According to Databricks The data show that 60% of LLM applications in the enterprise use retrieval-enhanced generation (RAG), with 30% using a multistep process.RAG has received a lot of attention because it generates responses that are nearly as good as those that rely on fine-tuned models alone Improved accuracy of the 43%It shows that the RAG great potential for improving the quality and reliability of AI-generated content.
However, traditional RAG approaches still face a number of challenges in responding to complex queries, understanding nuanced contexts, and handling multiple data types. These limitations have driven the creation of advanced RAGs, which aim to enhance AI's capabilities in information retrieval and generation. Notably.number of companies The RAG has been integrated into approximately 60% products, demonstrating its importance and effectiveness in practical applications.
One of the major breakthroughs in the field is the introduction of multimodal RAGs and knowledge graphs. Multimodal RAG extends the ability of RAGs to process not only text, but also a wide range of data including images, audio and video. This enables AI systems to be more comprehensive and have stronger contextual understanding when interacting with users. Knowledge graphs, on the other hand, improve the coherence and accuracy of the information retrieval process and the generated content through structured knowledge representation.Microsoft Research suggests that the GraphRAG required Token The number is reduced from 26% to 97% over other methods, showing higher efficiency and reduced computational cost.
These advances in RAG technology have resulted in significant performance gains across multiple benchmarks and real-world applications. For example.knowledge map achieved an accuracy of 86.31% in the RobustQA test, which greatly exceeds other RAG methods. In addition, theSequeda and Allemang of follow-up studies have found that combining ontologies reduces the 20% error rate. Businesses have also benefited greatly from these advances, theLinkedIn reported a 28.61 TP3T reduction in customer support resolution time through a RAG plus knowledge graph approach.
In this paper, we will delve into the evolution of advanced RAGs, exploring the complexity of multimodal RAGs and Knowledge Graph RAGs and their effectiveness in enhancing AI-driven information retrieval and generation. We will also discuss the potential application of these innovations in different industries as well as the challenges faced in generalizing and applying these technologies.
- [What is Retrieval Augmented Generation (RAG) and why is it important for Large Language Modeling (LLM)?]
- [Types of RAG architecture]
- [From basic RAG to advanced RAG: how to overcome limitations and enhance capacity]
- [Advanced RAG system components and processes in the enterprise]
- [Advanced RAG technology]
- [Advanced RAG applications and case studies]
- [How to build a dialog tool using advanced RAG?]
- [How do I build an advanced RAG application?]
- [The Rise of Knowledge Graphs in Advanced RAG]
- [Advanced RAG: Enhanced generation of extended horizons through multimodal retrieval]
- [How LeewayHertz's GenAI collaboration platform, ZBrain, stands out among advanced RAG systems].
Advanced RAG: Architecture, Technology, Applications and Development Perspectives PDF download:
Advanced RAG: Architecture, Technology, Applications and Development Perspectives
What is Retrieval Augmented Generation (RAG) and why is it important for Large Language Modeling (LLM)?
Large Language Models (LLMs) have become central to AI applications, relying on their power for everything from virtual assistants to sophisticated data analysis tools. But despite their capabilities, these models have limitations in providing up-to-date and accurate information. This is where Retrieval Augmented Generation (RAG) provides a powerful complement to LLM.
What is Retrieval Augmented Generation (RAG)?
Retrieval Augmented Generation (RAG) is an advanced technique that enhances the generative capabilities of Large Language Models (LLMs) by integrating external knowledge sources.LLMs are trained on large datasets, with billions of parameters, and are capable of performing a wide range of tasks, such as question answering, language translation, and text completion.RAG goes a step further, by referencing authoritative and domain-specific knowledge bases to improve the relevance, accuracy, and usefulness of the generated content without the need to retrain the model. RAG goes a step further by referencing authoritative and domain-specific knowledge bases to improve the relevance, accuracy, and utility of the generated content without the need to retrain the model. This cost-effective and efficient approach is ideal for enterprises looking to optimize their AI systems.
How can RAG (Retrieval Augmented Generation) help Large Language Modeling (LLM) to solve the core problem?
Large Language Models (LLMs) play a key role in driving intelligent chatbots and other Natural Language Processing (NLP) applications. Through extensive training, they attempt to provide accurate answers in a variety of contexts. However, LLMs themselves have some shortcomings and face multiple challenges:
- error message: Inaccurate answers may be generated when there is insufficient knowledge of LLM.
- Outdated information: The training data is static, so the responses generated by the model may be outdated.
- non-authoritative source: Generated responses may sometimes come from unreliable sources, affecting credibility.
- terminological confusion: Inconsistent use of the same terminology by different data sources can easily lead to misunderstandings.
RAG addresses these issues by providing LLM with an external authoritative source of data to improve the accuracy and real-time nature of the model's responses. The following points explain why RAG is so important to the development of LLM:
- Improve accuracy and relevance: LLMs sometimes give inaccurate or irrelevant answers due to the static nature of the training data; RAG extracts the most up-to-date and relevant information from authoritative sources to ensure that the model's answers are more accurate and relevant to the current context.
- Breaking through the limits of static data: The LLM's training data is sometimes outdated and does not reflect the latest research or news. the RAG gives the LLM access to the most recent data, keeping the information current and relevant.
- Enhance user trust: LLM may generate so-called "illusions" - confident but erroneous answers - and the RAG enhances transparency and user trust by allowing LLM to cite sources and provide verifiable information.
- cost savingRAG provides a more cost-effective alternative to retraining the LLM with new data, and by utilizing external data sources instead of retraining the entire model, advanced AI techniques are more widely available.
- Enhanced developer control and flexibility: RAG provides developers with more freedom to flexibly specify knowledge sources, quickly adapt to changes in requirements, and ensure appropriate handling of sensitive information to support a wide range of applications and improve the effectiveness of AI systems.
- Providing customized answersWhile traditional LLMs tend to give overly general answers, RAG combines LLMs with the organization's internal databases, product information, and user manuals to provide more specific and relevant answers, dramatically improving the customer support and interaction experience.
RAG (Retrieval Augmented Generation) enables LLM to generate more accurate, real-time and contextualized answers by integrating with external knowledge bases. This is critical for organizations that rely on AI, from customer service to data analytics, RAG not only improves efficiency, but also increases user trust in AI systems.
Types of RAG Architecture
Retrieval Augmented Generation (RAG) represents a major advancement in AI technology by combining language models with external knowledge retrieval systems. This hybrid approach enhances the ability of AI response generation by obtaining detailed and relevant information from large external data sources. Understanding the different types of RAG architectures helps us to better leverage their benefits according to our specific needs. Below is an in-depth look at the three main RAG architectures:
1. Naive RAG
Naive RAG is the most basic retrieval enhancement generation method. Its principle is simple, the system extracts relevant chunks of information from the knowledge base based on the user's query, and then uses these chunks of information as the context to generate the answer through language modeling.
Features:
- Retrieval mechanism: A simple retrieval method is used to extract relevant blocks of documents from a pre-established index, usually through keyword matching or basic semantic similarity.
- contextual integration: The retrieved documents are spliced with the user's query and fed into the language model to generate answers. This fusion provides a richer context for the model to generate more relevant answers.
- processing flow: The system follows a fixed process: retrieve, splice, generate. The model does not modify the extracted information, but uses it directly to generate answers.
2. Advanced RAG
Advanced RAG is based on Naive RAG and utilizes more advanced techniques to improve retrieval accuracy and contextual relevance. It overcomes some of the limitations of Naive RAG by combining advanced mechanisms to better process and utilize contextual information.
Features:
- Enhanced retrieval: Enhance the quality and relevance of retrieved information using advanced search strategies such as query expansion (adding relevant terms to the initial query) and iterative search (optimizing documents in multiple stages).
- contextual optimization: Selectively focusing on the most relevant parts of the context through techniques such as the attention mechanism helps the language model to generate more accurate and contextually more precise responses.
- optimization strategy: Optimization strategies, such as relevance scoring and contextual enhancement, are used to ensure that the model captures the most relevant and high-quality information to generate responses.
3. Modular RAG
Modular RAG is the most flexible and customizable RAG architecture. It breaks down the retrieval and generation process into separate modules, allowing optimization and replacement according to the needs of specific applications.
Features:
- modular design: Decompose the RAG process into different modules such as query expansion, retrieval, reordering and generation. Each module can be optimized independently and replaced on demand.
- Flexible customization: Allows for a high degree of customization, where developers can experiment with different configurations and techniques at each step to find the best solution. The methodology provides customized solutions for a variety of application scenarios.
- Integration and Adaptation: The architecture is capable of integrating additional functionalities such as a memory module (for recording past interactions) or a search module (for extracting data from a search engine or knowledge graph). This adaptability allows the RAG system to be flexibly adapted to meet specific needs.
Understanding these types and characteristics is critical to selecting and implementing the most appropriate RAG architecture.
From Basic to Advanced RAG: Breaking Through Limitations to Enhance Abilities
Retrieval-augmented generation (RAG) is used in the Natural Language Processing (NLP) It has become a very effective method for combining information retrieval and text generation to produce more accurate and contextualized output. However, as the technology has evolved, the initial "basic" RAG systems have revealed some flaws, which have driven the emergence of more advanced versions. The evolution of basic RAG to advanced RAG means that we are gradually overcoming these shortcomings and greatly improving the overall capabilities of the RAG system.
Limitations of the Basic RAG

The underlying RAG framework is an initial attempt to combine retrieval and generation for NLP. While this approach is innovative, it still faces some limitations:
- Simple Search Methods: Most of the basic RAG systems rely on simple keyword matching, an approach that makes it difficult to understand the nuances and context of the query and thus retrieve insufficiently or partially relevant information.
- Difficulty understanding context: It is difficult for these systems to properly understand the context of a user query. For example, the underlying RAG system may retrieve documents containing the query keywords, but fails to capture the true intent or context of the user, thus failing to accurately meet the user's needs.
- Limited ability to handle complex queries: Basic RAG systems perform poorly when faced with complex or multi-step queries. Their limitations in understanding context and accurate retrieval make it difficult to handle complex problems effectively.
- Static knowledge base: The underlying RAG system relies on a static knowledge base and lacks a mechanism for dynamic updating; information may become outdated over time, affecting the accuracy and relevance of the response.
- Lack of iterative optimization: The underlying RAG lacks a mechanism to optimize based on feedback, cannot improve performance through iterative learning, and stagnates over time.
Transition to Advanced RAG
As technology has evolved, more sophisticated solutions to the shortcomings of basic RAG systems have become available. Advanced RAG systems overcome these challenges in several ways:
- More complex search algorithms: Advanced RAG systems use sophisticated techniques such as semantic search and contextual understanding, which can go beyond keyword matching to understand the real meaning behind the query, thus improving the relevance of the retrieved results.
- Enhanced Contextual Integration: These systems incorporate context and relevance weights to integrate retrieval results to ensure that not only is the information accurate, but it is also appropriate in context and better responds to the user's query and intent.
- Iterative optimization and feedback mechanisms::
The Advanced RAG system employs an iterative optimization process that continually improves accuracy and relevance over time by incorporating user feedback. - Dynamic knowledge updating::
The advanced RAG system is capable of dynamically updating the knowledge base, continuously introducing the latest information and ensuring that the system always reflects the latest trends and developments. - Complex contextual understanding::
Leveraging more advanced NLP techniques, advanced RAG systems have a deeper understanding of the query and context, analyzing semantic nuances, contextual cues, and user intent to generate more coherent and relevant responses.
Advanced RAG system improvements on components
The evolution from basic to advanced RAG means that the system achieves significant improvements in each of the four key components: storage, retrieval, enhancement and generation.
- stockpile: Advanced RAG systems make information retrieval more efficient by storing data through semantic indexing, organizing data by its meaning rather than simply by keywords.
- look up: With the enhancement of semantic search and contextual retrieval, the system not only finds relevant data, but also understands the user's intent and context.
- reinforce: The enhancement module of the Advanced RAG system generates more personalized and accurate responses through a dynamic learning and adaptation mechanism that is continuously optimized based on user interactions.
- generating: The Generation module leverages sophisticated contextual understanding and iterative optimization to be able to generate more coherent and contextual responses.
The evolution from basic RAG to advanced RAG is a significant leap forward. By using sophisticated retrieval techniques, enhanced contextual integration, and dynamic learning mechanisms, advanced RAG systems provide a more accurate and context-aware approach to information retrieval and generation. This advancement improves the quality of AI interactions and lays the foundation for more refined and efficient communication.
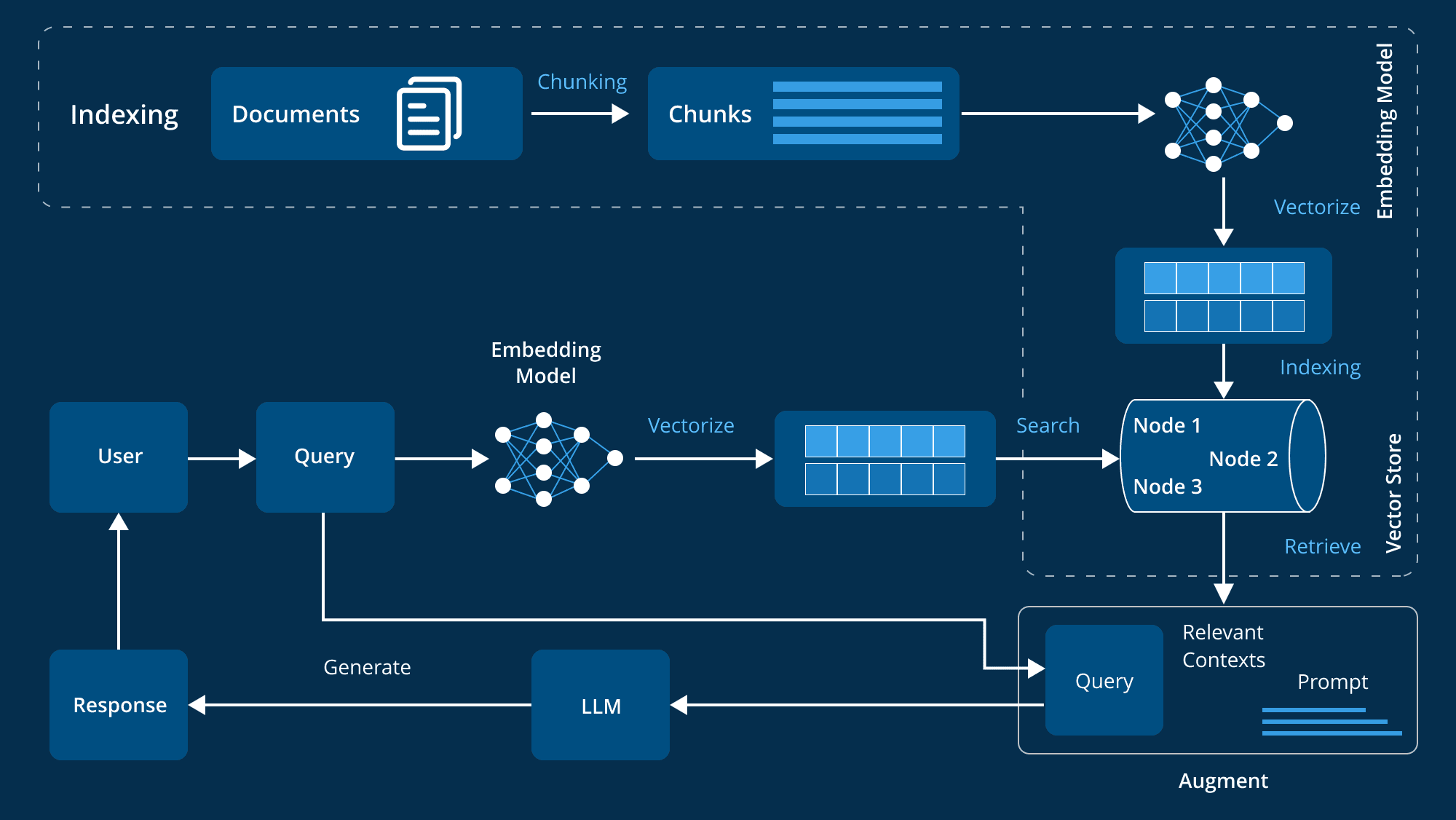
Components and workflows of an enterprise-level advanced RAG system
In the field of enterprise applications, there is a growing need for systems that can intelligently retrieve and generate relevant information. Retrieval-enhanced generation (RAG) systems have emerged as powerful solutions that combine the accuracy of information retrieval with the generative power of large language models (LLMs). However, to build an advanced RAG system that fits the complex needs of an organization, its architecture must be carefully designed.
Core Architecture Components
An advanced Retrieval Augmentation Generation (RAG) system requires multiple core components that work together to ensure system efficiency and effectiveness. These components cover data management, user input processing, information retrieval and generation, and ongoing system performance enhancement. The following is a detailed breakdown of these key components:
- Data preparation and management
The foundation of an advanced RAG system is the preparation and management of data, which involves a number of key components:
- Data chunking and vectorization: Data is broken down into more manageable chunks and transformed into vector representations, which is critical to improving retrieval efficiency and accuracy.
- Metadata and Summary Generation: Generating metadata and summaries allows for quick reference and reduces retrieval time.
- Data cleansing: Ensuring that the data is clean, organized, and free of noise is key to ensuring that the retrieved information is accurate.
- Handles complex data formats: The system's ability to handle complex data formats ensures that a wide range of data types are effectively utilized across the enterprise.
- User Configuration Management: Personalization is important in enterprise environments, and by managing user configurations, responses can be tailored to individual needs, optimizing the user experience.
- User Input Processing
The user input processing module plays a vital role in ensuring that the system can handle queries efficiently:
- User authentication: The security of enterprise systems is very important and authentication mechanisms ensure that only authorized users can use the RAG system.
- Query Optimizer: The structure of the user's query may not be suitable for retrieval, and the optimizer optimizes the query to improve the relevance and accuracy of the retrieval.
- Input protection mechanisms: Protection mechanisms protect the system from extraneous or malicious inputs and ensure the reliability of the retrieval process.
- Chat History Utilization: By referring to previous conversations, the system is better able to understand and respond to the current query, generating more accurate and contextualized answers.
- information retrieval system
The information retrieval system is at the heart of the RAG architecture and is responsible for retrieving the most relevant information from a pre-processed index of data:
- Data indexing: Efficient indexing technology ensures fast and accurate information retrieval, and advanced indexing methods support the processing of large amounts of enterprise data.
- Hyperparameter tuning: The parameters of the retrieval model are tuned to optimize its performance and ensure that the most relevant results are retrieved.
- Result reordering: After retrieval, the system reorders the results to ensure that the most relevant information is prioritized for display, improving response quality.
- Embedding Optimization: By adjusting the embedding vectors, the system is able to better match the query with the relevant data, thus improving the accuracy of the retrieval.
- Hypothetical problems with HyDE technology: Generating hypothetical question and answer pairs using HyDE (Hypothetical Document Embedding) technology can better cope with information retrieval when the query and document are asymmetric.
- Information generation and processing
When relevant information is retrieved, the system needs to generate a coherent and contextually relevant response:
- Response Generation: Utilizing advanced Large Language Models (LLMs), the module synthesizes retrieved information into comprehensive and accurate responses.
- Output protection and auditing: In order to ensure that the generated responses meet the specifications, the system uses various rules to review them.
- Data caching: Frequently accessed data or answers are cached, thus reducing retrieval time and improving system efficiency.
- Personalized Generation: The system customizes the generated content to the user's needs and configuration to ensure the relevance and accuracy of the response.
- Feedback and system optimization
Advanced RAG systems should be capable of self-learning and improvement, and feedback mechanisms are essential for continuous optimization:
- User Feedback: By collecting and analyzing user feedback, the system can identify areas for improvement and evolve to better meet user needs.
- Data optimization: Based on user feedback and new findings, the data in the system is continuously optimized to ensure the quality and relevance of the information.
- Generate quality assessments: The system regularly evaluates the quality of the generated content for continuous optimization.
- System monitoring: Continuously monitor system performance to ensure it is running efficiently and can respond to changes in demand or changes in data patterns.
Integration with enterprise systems
For an advanced RAG system to work optimally in an enterprise environment, seamless integration with existing systems is essential:
- CRM and ERP system integration: Interfacing advanced RAG systems with Customer Relationship Management (CRM) and Enterprise Resource Planning (ERP) systems enables efficient access and utilization of critical business data, improving the ability to generate accurate and contextually relevant answers.
- APIs and microservices architecture: The use of flexible APIs and a microservices architecture allows the RAG system to be easily integrated into existing enterprise software, enabling modular upgrades and extensions.
Security and Compliance
Security and compliance are especially important due to the sensitivity of enterprise data:
- Data Security Protocol: Strong data encryption and secure data processing measures are used to protect sensitive information and ensure compliance with data protection regulations such as GDPR.
- Access control and authentication: Implement secure user authentication and role-based access control mechanisms to ensure that only authorized personnel can access or modify the system.
Scalability and performance optimization
Enterprise-class RAG systems need to be scalable and able to maintain good performance under high loads:
- Cloud Native Architecture: The use of cloud-native architecture provides the flexibility to scale resources on demand, ensuring high system availability and performance optimization.
- Load balancing and resource management: Efficient load balancing and resource management strategies help the system handle large volumes of user requests and data while maintaining optimal performance.
Analysis and reporting
An advanced RAG system should also have robust analytics and reporting capabilities:
- Performance Monitoring: Real-time monitoring of system performance, user interactions, and system health by integrating advanced analytics tools is critical to maintaining system efficiency.
- Business Intelligence Integration: Integration with Business Intelligence tools can provide valuable insights to help decision making and drive business strategy.
Advanced RAG systems at the enterprise level represent a combination of cutting-edge AI technology, robust data processing mechanisms, secure and scalable infrastructure, and seamless integration capabilities. By combining these elements, organizations are able to build RAG systems that can efficiently retrieve and generate information while also being a core part of the enterprise technology system. These systems not only deliver significant business value, but also improve decision-making and enhance overall operational efficiency.
Advanced RAG Technology
Advanced Retrieval Augmented Generation (RAG) encompasses a range of technological tools designed to improve efficiency and accuracy at all stages of processing. These advanced RAG systems are able to better manage data and provide more accurate, contextualized responses by applying advanced technologies at different stages of the process, from indexing and query transformation to retrieval and generation. Below are some of the advanced techniques used to optimize each stage of the RAG process:
1. Index
Indexing is a key process that improves the accuracy and efficiency of Large Language Models (LLMs) systems. Indexing is more than just storing data; it involves systematically organizing and optimizing data to ensure that information is easy to access and understand while maintaining important context. Effective indexing helps retrieve data accurately and efficiently, enabling LLMs to provide relevant and accurate responses. Some of the techniques used in the indexing process include:
Technique 1: Optimizing Text Blocks through Block Optimization
The purpose of block optimization is to adjust the size and structure of text blocks so that they are not too large or too small while maintaining context, thus improving retrieval.
Technique 2: Converting Text to Vectors Using Advanced Embedding Models
After creating blocks of text, the next step is to convert these blocks into vector representations. This process transforms text into numeric vectors that capture its semantic meaning. Models like the BGE-large or E5 embedding families are effective in representing the nuances of the text. These vector representations are crucial in subsequent retrieval and semantic matching.
Technique 3: Enhancing Semantic Matching by Embedding Fine Tuning
The purpose of embedding fine-tuning is to improve the semantic understanding of the indexed data by the embedding model, and thus to improve the matching accuracy between the retrieved information and the user query.
Technique 4: Improving Search Efficiency through Multiple Representations
Multi-representation techniques convert documents into lightweight retrieval units, such as summaries, to speed up the retrieval process and improve accuracy when working with large documents.
Technique 5: Using Hierarchical Indexes to Organize Data
Hierarchical indexing enhances retrieval by structuring data into multiple levels, from detailed to general, through models like RAPTOR, which provide broad and precise contextual information.
Technique 6: Enhancing Data Retrieval through Metadata Attachment
Metadata appending techniques add additional information to each data block to improve analysis and categorization capabilities, making data retrieval more systematic and contextual.
2. Query conversion
Query transformation aims to optimize user input and improve the quality of information retrieval. By utilizing LLMs, the transformation process is able to make complex or ambiguous queries clearer and more specific, thus improving overall search efficiency and accuracy.
Technique 1: Using HyDE (Hypothetical Document Embedding) to Improve Query Clarity
HyDE improves the relevance and accuracy of information retrieval by generating hypothesis data to enhance semantic similarity between questions and reference content.
Technique 2: Simplifying Complex Queries with Multi-Step Queries
Multi-step queries break down complex questions into simpler sub-questions, retrieve the answers to each sub-question separately, and aggregate the results to provide a more accurate and comprehensive response.
Technique 3: Enhancing Context with Backtracking Hints
The backtracking hinting technique generates a broader general query from the complex original query, such that the context helps to provide a basis for the specific query, improving the final response by combining the results of the original and broader query.
Technique 4: Improving Retrieval Through Query Rewriting
The query rewriting technique utilizes the LLM to reformulate the initial query to improve retrieval.Both LangChain and LlamaIndex employ this technique, with LlamaIndex providing a particularly powerful implementation that dramatically improves retrieval.
3. Query routing
The role of query routing is to optimize the retrieval process by sending the query to the most appropriate data source based on the characteristics of the query, ensuring that each query is processed by the most appropriate system component.
Technique 1: Logical Routing
Logical routing optimizes retrieval by analyzing the structure of the query to select the most appropriate data source or index. This approach ensures that the query is processed by the data source best suited to provide an accurate answer.
Technology 2: Semantic Routing
Semantic routing directs the query to the correct data source or index by analyzing the semantic meaning of the query. It improves the accuracy of retrieval by understanding the context and meaning of the query, especially for complex or nuanced issues.
4. Pre-search and data indexing techniques
Pre-retrieval optimization improves the quality and retrievability of information in a data index or knowledge base. Specific optimization methods vary depending on the nature, source, and size of the data. For example, increasing information density can generate more accurate responses with fewer tokens, which improves the user experience and reduces costs. However, optimization methods that work for one system may not work for others. Large Language Models (LLMs) provide tools for testing and tuning these optimizations, allowing tailored approaches to improve retrieval across different domains and applications.
Technique 1: Increasing Information Density with LLMs
A fundamental step in optimizing a RAG system is to improve the quality of the data before it is indexed. By utilizing LLMs for data cleansing, tagging and summarization, information density can be increased, leading to more accurate and efficient data processing results.
Technique 2: Hierarchical Index Search
Hierarchical indexing searches simplify the search process by creating document summaries as the first layer of filters. This multi-layered approach ensures that only the most relevant data is considered during the search phase, thereby improving search efficiency and accuracy.
Technique 3: Improving Search Symmetry through Hypothetical Q&A Pairs
To address the asymmetry between queries and documents, this technique uses LLMs to generate hypothetical Q&A pairs from documents. By embedding these Q&A pairs into the retrieval, the system can better match the user query, thus improving semantic similarity and reducing retrieval errors.
Technique 4: De-duplication with LLMs
Duplicate information can be both beneficial and detrimental to a RAG system. Using LLMs to de-duplicate data blocks optimizes data indexing, reduces noise, and increases the likelihood of generating accurate responses.
Technique 5: Testing and Optimizing Chunking Strategies
An effective chunking strategy is critical for retrieval. By performing A/B testing with different chunk sizes and overlap ratios, the optimal balance for a particular use case can be found. This helps to retain sufficient context without spreading or diluting relevant information too thinly.
Technique 6: Using Sliding Window Indexes
Sliding window indexing ensures that important contextual information is not lost between segments by overlapping blocks of data during indexing. This approach maintains data continuity and improves the relevance and accuracy of retrieved information.
Technique 7: Increase data granularity
Enhancing data granularity is done primarily through the application of data cleansing techniques that remove irrelevant information and retain only the most accurate and up-to-date content in the index. This improves the quality of retrieval and ensures that only relevant information is considered.
Technique 8: Adding Metadata
Adding metadata, such as date, purpose, or section, can increase the precision of the search, allowing the system to focus more effectively on the most relevant data and improve the overall search.
Technique 9: Optimizing Index Structure
Optimizing the indexing structure involves resizing chunks and employing multiple indexing strategies, such as sentence window retrieval, to enhance the way data is stored and retrieved. By embedding individual sentences while maintaining contextual windows, this approach enables richer and more contextually accurate retrieval during inference.
5. Retrieval techniques
In the retrieval phase, the system collects the information needed to answer the user's query. Advanced search technology ensures that the retrieved content is both comprehensive and contextually complete, laying a solid foundation for subsequent processing steps.
Technique 1: Optimizing Search Queries with LLMs
LLMs can optimize a user's search query to better match the requirements of the search system, whether it is a simple search or a complex conversational query. This optimization ensures that the search process is more targeted and efficient.
Technique 2: Fixing Query-Document Asymmetry with HyDE
By generating hypothetical answer documents, HyDE technology improves semantic similarity in retrieval and solves the asymmetry between short queries and long documents.
TECHNIQUE 3: Implementation of Query Routing or RAG Decision Models
In systems that use multiple data sources, query routing optimizes retrieval efficiency by pointing searches to the appropriate databases. the RAG decision model further optimizes this process by determining when a retrieval is needed to conserve resources when the large language model can respond independently.
Technique 4: Deep Exploration with Recursive Searchers
A recursive searcher performs further queries based on the previous result and is suitable for exploring relevant data in depth to obtain detailed or comprehensive information.
Technique 5: Optimizing Data Source Selection with Route Retrievers
The Routing Retriever utilizes LLM to dynamically select the most suitable data source or query tool to improve the retrieval process based on the context of the query.
Technique 6: Automated Query Generation Using an Automated Retriever
The auto-retriever uses the LLM to automatically generate metadata filters or query statements, thus simplifying the database query process and optimizing information retrieval.
Technique 7: Combining results using a fusion searcher
The Fusion Retriever combines results from multiple queries and indexes to provide a comprehensive and non-duplicative view of the information, ensuring a comprehensive search.
Technique 8: Aggregating Data Contexts with Automated Merge Searchers
The Auto Merge Retriever combines multiple data segments into a unified context, improving the relevance and completeness of information by integrating smaller contexts.
Technique 9: Fine-tuning the Embedding Model
Fine-tuning the embedding model to make it more domain-specific improves the ability to handle specialized terminology. This approach enhances the relevance and accuracy of retrieved information by aligning domain-specific content more closely.
Technique 10: Implementing Dynamic Embedding
Dynamic embeddings go beyond static representations by adapting word vectors to the context, providing a more nuanced understanding of the language. This approach, such as OpenAI's embeddings-ada-02 model, captures contextual meaning more accurately and thus provides more accurate retrieval results.
Technique 11: Utilizing Hybrid Search
Hybrid search combines vector search with traditional keyword matching, allowing for both semantic similarity and precise term recognition. This approach is particularly effective in scenarios where precise term recognition is required, ensuring comprehensive and accurate retrieval.
6. Post-retrieval techniques
After obtaining relevant content, the post-retrieval phase focuses on how to put this content together effectively. This step involves providing precise and concise contextual information to the Large Language Model (LLM), ensuring that the system has all the details needed to generate coherent and accurate responses. The quality of this integration directly determines the relevance and clarity of the final output.
Technique 1: Optimizing search results through reordering
After retrieval, the reordering model rearranges the search results to place the most relevant documents closer to the query, thus improving the quality of the information provided to the LLM, which in turn improves the generation of the final response. Reordering not only reduces the number of documents that need to be provided to the LLM, but also acts as a filter to improve the accuracy of language processing.
Technique 2: Optimizing Search Results with Contextual Cue Compression
LLM can filter and compress the retrieved information before generating the final prompt. Compression helps LLM focus more on critical information by reducing redundant background information and removing extraneous noise. This optimization improves the quality of the response by focusing on the important details. Frameworks like LLMLingua further improve this process by removing extraneous tokens, making the prompts more concise and effective.
Technique 3: Scoring and Filtering of Retrieved Documents by Correcting RAGs
Before content is entered into the LLM, documents need to be selected and filtered to remove irrelevant or less accurate documents. This technique ensures that only high-quality, relevant information is used, thereby improving the accuracy and reliability of the response. Corrective RAG utilizes a model such as T5-Large to assess the relevance of retrieved documents and filters out those below a preset threshold, ensuring that only valuable information is involved in the generation of the final response.
7. Generative technologies
During the generation phase, the retrieved information is evaluated and reordered to identify the most important content. Advanced technology at this stage involves selecting those key details that increase the relevance and reliability of the response. This process ensures that the generated content not only answers the query but is also well supported by the retrieved data in a meaningful way.
Technique 1: Reducing Noise with Chain-of-Thought Tips
Chain-of-thought prompts help LLM deal with noisy or irrelevant background information, increasing the likelihood of generating an accurate response even if there are interferences in the data.
TECHNIQUE 2: Empowering systems for self-reflection through self-RAG
Self-RAG involves training the model to use reflective tokens during generation so that it can evaluate and improve its own output in real time, choosing the best response based on facticity and quality.
Technique 3: Ignoring extraneous backgrounds through fine-tuning
The RAG system was specifically fine-tuned to enhance the LLM's ability to ignore extraneous backgrounds, ensuring that only relevant information influences the final response.
Technique 4: Enhancing LLM Robustness to Irrelevant Backgrounds with Natural Language Reasoning
Integrating natural language inference (NLI) models helps to filter out irrelevant background information by comparing the retrieved context with the generated answer, ensuring that only relevant information influences the final output.
Technique 5: Controlling Data Retrieval with FLARE
FLARE (Flexible Language Model Adaptation for Retrieval Enhancement) is a cue-engineering based approach that ensures that LLM retrieves data only when necessary. It continuously adapts the query and checks for low probability keywords that trigger the retrieval of relevant documents to enhance the accuracy of the response.
Technique 6: Improving Response Quality with ITER-RETGEN
ITER-RETGEN (Iterative Retrieval-Generation) improves response quality by iteratively executing the generation process. Each iteration uses the previous result as a context to retrieve more relevant information, thus continuously improving the quality and relevance of the final response.
Technique 7: Clarifying Issues Using ToC (Tree of Clarification)
ToC recursively generates specific questions to clarify ambiguities in the initial query. This approach refines the Q&A process by continuously evaluating and refining the original questions, resulting in a more detailed and accurate final response.
8. Assessment
In advanced Retrieval Augmented Generation (RAG) technologies, the evaluation process is critical to ensure that the information retrieved and synthesized is both accurate and relevant to the user's query. The evaluation process consists of two key components: quality scores and required capabilities.
Quality scoring focuses on measuring the accuracy and relevance of the content:
- Background Relevance. Evaluate the applicability of retrieved or generated information in the specific context of the query. Ensure that the response is accurate and tailored to the user's needs.
- Answer Fidelity. Check that the answers generated accurately reflect the retrieved data and do not introduce errors or misleading information. This is essential to maintain the reliability of the system's output.
- Relevance of answer. Evaluate whether the generated response directly and effectively answers the user's query, ensuring that the answer is both useful and consistent with the gist of the question.
The required capabilities are those that the system must have in order to deliver high quality results:
- Noise Robustness. Measure the ability of the system to filter extraneous or noisy data to ensure that these disturbances do not affect the quality of the final response.
- Negative Rejection. Test the effectiveness of the system in recognizing and excluding erroneous or irrelevant information from contaminating the generated output.
- Integration of information. Evaluate the system's ability to integrate multiple pieces of relevant information into a coherent, comprehensive response that provides the user with a complete answer.
- Counterfactual robustness. Examine the system's performance in dealing with hypothetical or counterfactual scenarios to ensure that responses remain accurate and reliable even when dealing with speculative questions.
Together, these evaluation components ensure that the Advanced RAG system provides a response that is both accurate and relevant, robust, reliable and customized to the specific needs of the user.
Additional technologies
Chat Engine: Enhancing Conversation Capabilities in the RAG System
Integrating a chat engine into an advanced Retrieval Augmented Generation (RAG) system enhances the system's ability to handle follow-up questions and maintain the context of the conversation, similar to traditional chatbot technology. Different implementations offer different levels of complexity:
- Context chat engine: This underlying approach guides Large Language Modeling (LLM) responses by retrieving context relevant to the user's query, including previous chats. This ensures that the conversation is coherent and contextually appropriate.
- Concentration plus contextualization mode: This is a more advanced approach that condenses the chat logs and latest messages from each interaction into an optimized query. This refined query captures the relevant context and combines it with the original user message to provide to the LLM to generate a more accurate and contextualized response.
These implementations help to improve the coherence and relevance of conversations in the RAG system and provide different levels of complexity depending on the needs.
Reference citations: ensure sources are accurate
Ensuring the accuracy of references is important, especially when multiple sources contribute to the generated responses. This can be accomplished in several ways:
- Direct source labeling: Setting up a task in a Language Model (LLM) prompt requires that the source be directly labeled in the generated response. This approach allows the original source to be clearly labeled.
- Fuzzy matching technique: Fuzzy matching techniques, such as those used by LlamaIndex, are employed to align portions of the generated content with blocks of text in the source index. Fuzzy matching improves the accuracy of the content and ensures that it reflects the source information.
By applying these strategies, the accuracy and reliability of reference citations can be significantly improved, ensuring that the responses generated are both credible and well supported.
Agents in Retrieval Augmented Generation (RAG)
Agents play an important role in improving the performance of Retrieval Augmented Generation (RAG) systems by providing additional tools and functionality to the Large Language Model (LLM) to extend its reach. Originally introduced through the LLM API, these agents enable LLMs to utilize external code functions, APIs, and even other LLMs to enhance their functionality.
One important application of agents is in multi-document retrieval. For example, recent OpenAI assistants demonstrate advances in this concept. These assistants augment traditional LLMs by integrating features such as chat logs, knowledge stores, document upload interfaces, and function call APIs that convert natural language into actionable commands.
The use of agents also extends to the management of multiple documents, where each document is handled by a specialized agent, such as summaries and quizzes. A centralized high-level agent oversees these document-specific agents, routing queries and consolidating responses. This setup supports complex comparisons and analysis across multiple documents, demonstrating advanced RAG techniques.
Response to Synthesizer: crafting the final answer
The final step in the RAG process is to synthesize the retrieved context and the initial user query into a response. In addition to directly combining the context with the query and processing it through the LLM, more refined approaches include:
- Iterative optimization: Splitting the retrieved context into smaller parts optimizes the response through multiple interactions with the LLM.
- Contextual summary: Compressing a large amount of context to fit within the LLM prompts ensures that responses remain focused and relevant.
- Multi-Answer Generation: Generate multiple responses from different segments of the context and then integrate these responses into a unified answer.
These techniques enhance the quality and accuracy of RAG system responses, demonstrating the potential for advanced methods in response synthesis.
Adopting these advanced RAG technologies can significantly improve system performance and reliability. By optimizing every stage of the process, from data preprocessing to response generation, organizations can create more accurate, efficient and powerful AI applications.
Advanced RAG Applications and Examples
Advanced Retrieval Augmented Generation (RAG) systems are used in a wide range of fields to enhance data analysis, decision making and user interaction through their powerful data processing and generation capabilities. From market research to customer support to content creation, advanced RAG systems have demonstrated significant benefits in a variety of areas. Specific applications of these systems in different areas are described below:
1. Market Research and Competitive Analysis
- data integration: The RAG system is capable of integrating and analyzing data from a variety of sources such as social media, news articles and industry reports.
- trend identification: By processing large amounts of data, the RAG system is able to identify emerging trends in the market and changes in consumer behavior.
- Competitor Insight: The system provides detailed competitor strategies and performance analysis to help companies self-assess and benchmark.
- actionable insight: Businesses can use these reports for strategic planning and decision-making.
2. Customer Support and Interaction
- Context-aware responses: The RAG system retrieves relevant information from the knowledge base to provide accurate and contextualized answers to customers.
- Reducing the workload: Automating common problems takes the pressure off of manual support teams, allowing them to handle more complex issues.
- Personalized Service: The system customizes responses and interactions to meet individual needs by analyzing customer history and preferences.
- Enhancing the interactive experience: High-quality support services enhance customer satisfaction and strengthen customer relationships.
3. Regulatory Compliance and Risk Management
- Regulatory analysis: The RAG system scans and interprets legal documents and regulatory guidance to ensure compliance.
- risk identification: By comparing internal policies with external regulations, the system quickly identifies potential compliance risks.
- Compliance Recommendations: Provide practical advice to help companies fill compliance gaps and reduce legal risks.
- Efficient reporting: Generate compliance reports and summaries that are easy to audit and inspect.
4. Product Development and Innovation
- Customer Feedback Analysis: The RAG system analyzes customer feedback to identify common problems and pain points.
- Market Insights: Track emerging trends and customer needs to guide product development.
- Innovative proposals: Provide potential product features and recommendations for improvement based on data analysis.
- competitive positioning: To help companies develop products that meet market needs and stand out from the competition.
5. Financial analysis and forecasting
- data integration: The RAG system integrates financial data, market conditions and economic indicators for comprehensive analysis.
- Trend analysis: Identify patterns and trends in financial markets to aid forecasting and investment decisions.
- investment advice: Provide practical advice on investment opportunities and risk factors.
- strategic planning: Support strategic financial decision-making through accurate forecasting and data-driven recommendations.
6. Semantic Search and Efficient Information Retrieval
- contextual understanding: The RAG system performs semantic search by understanding the context and meaning of user queries.
- Relevant results:: Improve search efficiency by retrieving the most relevant and accurate information from massive amounts of data.
- save time:: Optimize the data retrieval process and reduce the time spent searching for information.
- Improve Accuracy: Provides more accurate search results than traditional keyword search methods.
7. Enhancing Content Creation
- Trend Integration: The RAG system utilizes the most up-to-date data to ensure that the content generated is in line with current market trends and audience interests.
- Automatic content generation:: Automatically generate content ideas and drafts based on topics and target audiences.
- Enhancing participation: Generate more engaging and relevant content to enhance user interaction.
- timely update:: Ensure that content reflects the latest events and market developments and remains current.
8. text summary
- Highly effective summaries: The RAG system can effectively summarize long documents, distilling key points and important findings.
- save time: Save reading time by providing concise report summaries for busy executives and managers.
- emphasize:: Highlight key messages to help decision makers quickly grasp the main points.
- Increased efficiency in decision-making:: Provide relevant information in an easy-to-understand manner to improve the efficiency of decision-making.
9. Advanced Question and Answer System
- Precise Answers: The RAG system extracts data from a wide range of information sources to generate accurate answers to complex questions.
- Access Enhancement:: Enhance access to information in various areas, such as healthcare or finance.
- context-sensitive:: Provide targeted answers based on users' specific needs and questions.
- Complex issues:: Addressing complex issues by integrating multiple sources of information.
10. Conversation agents and chatbots
- contextual information: The RAG system enhances the interaction between chatbots and virtual assistants by providing relevant contextual information.
- Improve Accuracy:: Ensure that the dialog agent's responses are accurate and informative.
- user support: Enhance the user assistance experience by providing an intelligent and responsive dialog interface.
- Interactive Nature:: Real-time retrieval of relevant data to make interactions more natural and engaging.
11. information retrieval
- Advanced Search: Enhance search engine accuracy through RAG's retrieval and generation capabilities.
- Information Fragment Generation: Generate effective snippets of information to enhance the user experience.
- Search Result Enhancement:: Enrich search results with answers generated by the RAG system to improve query resolution.
- knowledge engine:: Use company data to answer internal questions, such as human resources policies or compliance issues, to facilitate access to information.
12. Personalized Recommendations
- Analyzing customer data: Generate personalized product recommendations by analyzing past purchases and reviews.
- Enhancing the shopping experience:: Improve the user shopping experience by recommending products based on personal preferences.
- increase revenue: Recommend relevant products based on customer behavior to increase sales.
- marketplace matching:: Align recommended content with current market trends to meet changing customer needs.
13. text completion
- contextualization:: The RAG system completes portions of the text in a contextually appropriate manner.
- increase efficiency:: Provide accurate completions to simplify tasks such as email writing or code writing.
- Enhancing Productivity:: Reduce the time it takes to complete writing and coding tasks and increase productivity.
- Maintaining consistency:: Ensure that textual complements are consistent with existing content and tone.
14. Data analysis
- Full data integration:: The RAG system integrates data from internal databases, market reports and external sources to provide a comprehensive view and in-depth analysis.
- accurate forecast:: Improve the accuracy of forecasts by analyzing the latest data, trends and historical information.
- Insight Discovery: Analyze comprehensive datasets to identify and assess new opportunities and provide valuable insights for growth and improvement.
- Data-Driven Recommendations:: Provide data-driven recommendations by analyzing comprehensive data sets to support strategic decision-making and improve the overall quality of decision-making.
15. translation task
- search for a translation:: Retrieve relevant translations from databases to help with translation tasks.
- Context Generation:: Generate consistent translations based on the context and with reference to the retrieved corpus.
- Improve Accuracy:: Utilize data from multiple sources to improve the accuracy of translations.
- increase efficiency: Streamline the translation process through automation and context-aware generation.
16. Customer Feedback Analysis
- comprehensive analysis:: Analyze feedback from different sources to gain a comprehensive understanding of customer sentiment and issues.
- insight: Provide detailed insights that reveal recurring themes and customer pain points.
- data integration: Integrate feedback from internal databases, social media and reviews for comprehensive analysis.
- Informatized Decision Making:: Make faster, smarter decisions based on customer feedback to improve products and services.
These applications demonstrate the wide range of possibilities of advanced RAG systems, demonstrating their ability to improve efficiency, accuracy and insight. Whether it's improving customer support, enhancing market research or streamlining data analysis, advanced RAG systems provide invaluable solutions that drive strategic decision-making and operational excellence.
Building Dialog Tools with Advanced RAG
Conversational AI tools play a critical role in modern user interactions, providing vivid and rapid feedback across a variety of platforms. We can take the capabilities of these tools to a whole new level by integrating an advanced Retrieval Augmented Generation (RAG) system, which combines powerful information retrieval capabilities with advanced generation techniques to ensure that conversations are both informative and maintain a natural flow of communication. When incorporated into conversational AI tools, the RAG system provides users with accurate and contextually rich responses while maintaining a natural conversational cadence. This section explores how RAG can be used to build advanced conversational tools, highlighting the key elements to focus on when building these systems and how to make them effective and practical in real-world applications.
Designing the dialog process
At the heart of any dialog tool is its dialog flow-that is, the steps in how the system processes user input and generates responses. For advanced RAG-based tools, the design of the dialog flow needs to be carefully planned to take full advantage of the retrieval capabilities of the RAG system and the generation of language models. This flow typically consists of several key stages:
Problem assessment and reframing::
- The system first evaluates the question posed by the user and determines whether it needs to be reformatted to provide the context needed for an accurate answer. If the question is too vague or lacks key details, the system may reformat it into a standalone query, ensuring that all necessary information is included.
Relevance checking and routing::
- Once the question is properly formatted, the system looks for relevant data in the vector store (a database containing indexed information). If relevant information is found, the question is forwarded to the RAG application, which retrieves the information needed to generate an answer.
- If there is no relevant information in the vector store, the system needs to decide whether to continue with the answer generated by the language model alone or to request the RAG system to state that a satisfactory answer cannot be provided.
Generating a Response::
- Depending on the decision made in the previous step, the system either uses the retrieved data to generate a detailed answer or relies on the knowledge of the language model and the dialog history to respond to the user. This approach ensures that the tool is able to deal with real-world problems while also adapting to more casual, open-ended conversations.
Optimizing dialogue processes using decision-making mechanisms
An important aspect when building advanced RAG dialog tools is the implementation of decision-making mechanisms that control the flow of the dialog. These mechanisms help the system intelligently decide when to retrieve information, when to rely on generative capabilities, and when to inform the user that no relevant data is available. Through these decisions, the tool can become more flexible and adapt to various dialog scenarios.
- Decision Point 1: Reinvent or Continue?
The system first decides if the user's question can be handled as is or if it needs to be reshaped. This step ensures that the system understands the user's intent and has all the necessary context to enable efficient retrieval or generation before generating a response. - Decision Point 2: Retrieve or Generate?
In the case where remodeling is required, the system determines if there is relevant information in the vector store. If relevant data is found, the system will use the RAG for retrieval and answer generation. If not, the system needs to decide whether to rely on the language model alone to generate the answer. - Decision point 3: Inform or interact?
If neither the vector store nor the language model can provide a satisfactory answer, the system informs the user that no relevant information is available, thus maintaining the transparency and credibility of the dialog.
How to Design Effective Prompts for Conversational RAGs
Prompts play a key role in guiding conversational behavior in language models. Designing effective prompts requires a clear understanding of the contextual information, the goals of the interaction, and the desired style and tone. Example:
- background information: Provide relevant contextual information to ensure that the language model captures the necessary context when generating or adapting questions.
- Goal Oriented Tips: Clarify the purpose of each prompt, such as adjusting the question, deciding on a retrieval process, or generating a response.
- Style and tone: Specify the desired style (e.g., formal, casual) and tone (e.g., informative, empathetic) to ensure that the output of the language model meets the expectations of the user experience.
Building dialog tools using advanced RAG techniques requires an integrated strategy that combines the strengths of retrieval and generation. By carefully designing conversational flows, implementing intelligent decision-making mechanisms, and developing effective prompts, developers can create AI tools that provide both accurate and context-rich answers, as well as natural, meaningful interactions with users.
How to build advanced RAG applications?
It's great to start out building a basic Retrieval Augmented Generation (RAG) application, but to realize the full potential of RAG in more complex scenarios, you need to go beyond the basics. This section describes how to build an advanced RAG application that enhances the retrieval process, improves response accuracy, and implements advanced techniques such as query rewriting and multi-stage retrieval.
Before diving into the advanced techniques, let's briefly review the basic functionality of a RAG application.A RAG application combines the capabilities of a language model (LLM) with an external knowledge base for answering user queries. This process typically consists of two phases:
- look up: The application searches for text snippets from vector databases or other knowledge bases that are relevant to the user's query.
- read: The retrieved text is passed to the LLM to generate a response based on these contexts.
This "search and read" approach provides LLM with the background information needed to provide more accurate answers to queries requiring specialized knowledge.
The steps to build an advanced RAG application are as follows:
Step 1: Use advanced techniques to enhance retrieval
The retrieval stage is critical to the quality of the final response. In a basic RAG application, the retrieval process is relatively simple, but in an advanced RAG application, you can use the following enhancements:
1. Multi-stage search
Multi-stage searches help target the most relevant contexts by refining the search in multiple steps. It usually includes:
- Initial broad search: Start with a broad search for a range of potentially relevant documents.
- Refine your search: A more precise search based on preliminary results, narrowed down to the most relevant segments.
This approach improves the accuracy of the retrieved information, which in turn provides more accurate answers.
2. Query rewriting
Query rewriting converts a user's query into a format that is more likely to yield relevant results in a search. This can be accomplished in several ways:
- zero-sample rewrite: Rewrite queries without concrete examples, relying on the model's linguistic understanding.
- Sample less rewriting: Examples are provided to help models rewrite similar queries to improve accuracy.
- Customized Rewriters: Fine-tune the model dedicated to query rewriting to better handle domain-specific queries.
These rewritten queries better match the language and structure of documents in the knowledge base, thus improving retrieval accuracy.
3. Subquery decomposition
For complex queries involving multiple questions or aspects, decomposing the query into multiple subqueries can improve retrieval. Each subquery focuses on a particular aspect of the original question so that the system can retrieve the relevant context for each part and integrate the answers.
Step 2: Improve response generation
After you've enhanced the retrieval process, the next step is to optimize the way the Big Language Model generates responses:
1. Backtracking tips
When faced with complex or multi-layered questions, it can be helpful to generate additional, broader queries. These "fallback" hints can help retrieve a wider range of contextual information, thus allowing the Big Language Model to generate more comprehensive responses.
2. Hypothetical Document Embedding (HyDE)
HyDE is a state-of-the-art technique that captures the intent of a query by generating hypothetical documents based on the user's query, and then uses these documents to find matching real documents in a knowledge base. This approach is particularly suitable for use when the query is not semantically similar to the relevant context.
Step 3: Integration of feedback loops
In order to continuously improve the performance of RAG applications, it is important to integrate feedback loops into the system:
1. User feedback
Incorporate a mechanism that allows users to evaluate the relevance and accuracy of responses. This feedback can be used to adjust the retrieval and generation process.
2. Enhanced learning
Using reinforcement learning techniques, models are trained based on user feedback and other performance metrics. This enables the system to learn from its mistakes and improve accuracy and relevance over time.
Step 4: Expansion and optimization
As RAG applications continue to advance, performance scaling and optimization becomes increasingly important:
1. Distributed search
In order to cope with large-scale knowledge bases, distributed retrieval systems are implemented, which can process retrieval tasks in parallel across multiple nodes, thereby reducing latency and increasing processing speed.
2. Caching strategy
Implementing a caching strategy to store frequently accessed context blocks reduces the need for repetitive retrieval and speeds up response times.
3. Model optimization
Optimize large language models and other models used in the application to reduce the computational burden while maintaining accuracy. Techniques such as model distillation and quantization are very useful here.
Building an advanced RAG application requires an in-depth understanding of retrieval mechanisms and generation models, along with the ability to implement and optimize complex technologies. By following the steps outlined above, you can create an advanced RAG system that exceeds user expectations and delivers high-quality, contextually accurate responses for a variety of application scenarios.
The Rise of Knowledge Graphs in Advanced RAGs
As organizations increasingly rely on AI for complex data-driven tasks, the role of knowledge graphs in advanced retrieval augmentation generation (RAG) systems becomes particularly important.According to Gartner. The Knowledge Graph is one of the cutting-edge technologies that promises to disrupt several markets in the future.Gartner'sEmerging Technologies Impact Radar noted that knowledge graphs are a core support tool for advanced AI applications, and they provide the foundation for data management, reasoning capabilities, and reliability of AI output. This has led to the widespread use of knowledge graphs in various industries such as healthcare, finance, and retail.
What is a knowledge graph?
A knowledge graph is a structured representation of information in which entities (nodes) and the relationships between them (edges) are explicitly defined. These entities can be concrete objects (such as people and places) or abstract concepts. Relationships between entities help build a knowledge network that makes data retrieval, reasoning and inference more human cognitive. More than just storing data, the Knowledge Graph captures the rich and nuanced relationships within a domain, which makes it a powerful tool in AI applications.
Query Enhancement and Planning with Knowledge Graphs
Query enhancement is a solution to the problem of unclear questioning in the RAG system. The goal is to add the necessary context to a query to ensure that even vague questions can be accurately interpreted. For example, in the financial domain, questions such as "What are the current challenges in implementing financial regulation?" questions such as "What are the current challenges in implementing financial regulation?" can be augmented to include specific entities such as "AML compliance" or "KYC process" to focus the search process on the most relevant information.
In the legal domain, questions like "What are the risks associated with contracts?" can be augmented by adding specific contract types, such as "labor contract" or "service agreement", based on the context provided by the knowledge graph.
Query planning, on the other hand, breaks down complex queries into manageable parts by generating sub-questions. This ensures that the RAG system can retrieve and integrate the most relevant information to provide a comprehensive answer. For example, to answer the question, "What is the impact of the new financial reporting standards on the company?" the system might first retrieve data on individual reporting standards, implementation timelines, and historical impacts on different areas.
In the medical field, a question like "What are the latest medical device advances?" can be broken down into sub-questions that explore advances in specific areas, such as "implantable devices," "diagnostic devices," or "surgical tools," ensuring that the system obtains detailed and relevant information from each subcategory. detailed and relevant information from each subcategory.
Through query enhancement and planning, the Knowledge Graph helps optimize and structure queries to improve the accuracy and relevance of information retrieval, ultimately providing more accurate and useful answers in complex areas such as finance, law and healthcare.
The Role of Knowledge Graphs in RAG
In retrieval-enhanced generation (RAG) systems, knowledge graphs enhance the retrieval and generation process by providing structured and context-rich data. Traditional RAG systems rely on unstructured text and vector databases, which can lead to inaccurate or incomplete information retrieval. By integrating knowledge graphs, RAG systems are able to:
- Improve query understanding: Knowledge graphs help the system to better understand the context and relationships of a query and thus retrieve relevant data more accurately.
- Enhanced answer generation: The structured data provided by the Knowledge Graph can generate more coherent, contextually relevant answers, reducing the risk of AI errors.
- Realizing Complex Reasoning: Knowledge graphs support multi-hop reasoning, where the system can infer new knowledge or connect disparate information by traversing multiple relationships.
The main components of the knowledge graph
The knowledge graph consists of the following main components:
- Nodes: Represents various entities or concepts in the field of knowledge, such as people, places, or things.
- Side: Describe the relationships between nodes, showing how these entities are interconnected.
- Properties: Additional information or metadata associated with nodes and edges that provide more context or detail.
- Triad: The basic building blocks of a knowledge graph, containing a topic, a predicate, and an object (e.g., "Einstein" [topic] "discovery" [predicate] "relativity" [object ]), these triples build the basic framework for describing relationships between entities.
Knowledge Graph-RAG Methodology
The KG-RAG methodology consists of three main steps:
- KG Construction: This step is to transform unstructured textual data into a structured knowledge graph, ensuring that the data is organized and relevant.
- Retrieve: Using a novel retrieval algorithm called Chain of Exploration (CoE), the system performs data retrieval through the knowledge graph.
- Response Generation: Finally, the retrieved information is used to generate coherent and contextualized responses, combining the structured data of the Knowledge Graph with the capabilities of a large language model.
This methodology highlights the important role of structured knowledge in enhancing the retrieval and generation process of RAG systems.
Benefits of Knowledge Graphs in RAG
Incorporating the Knowledge Graph into the RAG system brings several significant advantages:
- Structured Knowledge Representation: Knowledge graphs organize information in a way that reflects the complex relationships between entities, making data retrieval and use more efficient.
- Contextual understanding: Knowledge graphs provide richer contextual information by capturing relationships between entities, enabling RAG systems to generate more relevant and coherent responses.
- Reasoning skills: Knowledge mapping helps the system to generate more comprehensive and accurate answers by inferring new knowledge by analyzing the relationships between entities.
- Knowledge Integration: Knowledge graphs can integrate information from different sources to provide a more comprehensive view of data and help make better decisions.
- Interpretability and transparency: The structured nature of the knowledge graph makes the reasoning path clear and understandable, facilitates the explanation of the conclusion formation process, and improves the credibility of the system.
Integration of KG with LLM-RAG
The use of Knowledge Graphs in conjunction with Large Language Modeling (LLM) in RAG systems enhances the overall knowledge representation and reasoning capabilities. This combination enables dynamic knowledge fusion, ensuring that information remains current and relevant at the time of inference, thus generating more accurate and insightful responses.LLMs can leverage both structured and unstructured data to deliver better quality results.
Using Knowledge Graphs in Thought Chain Quizzes
Knowledge mapping is gaining traction in thought chain quizzing, especially when used in conjunction with Large Language Modeling (LLM). This approach works by breaking down complex questions into sub-questions, retrieving relevant information, and synthesizing it to form a final answer. Knowledge graphs provide structured information in this process, enhancing the reasoning power of the LLM.
For example, an LLM agent might first use the knowledge graph to identify relevant entities in a query, then obtain more information from different sources, and finally generate a comprehensive answer that reflects the interconnected knowledge in the graph.
Practical applications of knowledge graphs
In the past, knowledge graphs were mainly used in data-intensive domains, such as big data analytics and enterprise search systems, where their role was to maintain consistency and uniformity among different data silos. However, with the development of large language model-driven RAG systems, knowledge graphs have found new application scenarios. They now serve as a structured complement to probabilistic biglanguage models, helping to reduce false information, provide more context, and act as a memory and personalization mechanism in AI systems.
Introducing GraphRAG
GraphRAG is a state-of-the-art retrieval methodology that combines knowledge graphs and vector databases in a RAG (Retrieval Augmented Generation) architecture. This hybrid model leverages the strengths of both systems to provide AI solutions that are more accurate, contextualized and easy to understand.Gartner has stated The growing importance of knowledge graphs in enhancing product strategy and creating new AI application scenarios.
GraphRAG features include:
- Higher accuracy: By combining structured and unstructured data, GraphRAG is able to provide more accurate and comprehensive answers.
- Scalability: This approach simplifies the development and maintenance of RAG applications and allows for better scalability.
- Interpretability: GraphRAG provides clear inference paths that enhance the transparency of the system and make the AI outputs easier to understand and trust.
Advantages of GraphRAG
GraphRAG has several significant advantages over traditional RAG methods:
- Higher quality answers: Integrating the Knowledge Graph, GraphRAG improves the accuracy and relevance of AI-generated responses, with recent benchmarks showing a threefold improvement in accuracy.
- Cost-effectiveness: GraphRAG is more cost-effective, requires fewer computing resources and less training data, and is an attractive option for organizations looking to optimize their AI investments.
- Better scalability: This approach supports large-scale AI applications, enabling organizations to easily handle more complex queries and larger data sets.
- Improved interpretability: GraphRAG's structured approach provides clearer inference paths, making the AI decision-making process more transparent and easier to debug.
- Revealing Hidden Connections: Knowledge graphs can reveal relationships that go unnoticed in big datasets, providing deeper insights and enhancing the quality of the decision-making process.
Common GraphRAG Architectures
Several GraphRAG architectures are emerging as ways to effectively integrate knowledge graphs into RAG systems:
- Knowledge graphs with semantic clustering: This architecture improves the relevance and accuracy of data retrieval by clustering relevant information before generating answers.
- Integration of knowledge graphs with vector databases: This architecture combines the two systems to provide a richer context for the larger language model, which in turn generates more comprehensive and contextually appropriate responses.
- Knowledge graph-enhanced question and answer system: In this architecture, the knowledge graph adds factual information to the answers generated by the large language model after vector retrieval to ensure the accuracy and completeness of the responses.
- Graph-enhanced hybrid retrieval: This approach combines vector searches, keyword searches, and graph-specific queries to provide a powerful and flexible retrieval system that enhances the ability of large language models to generate relevant responses.
Emerging Patterns in GraphRAG
As GraphRAG continues to evolve, several emerging patterns are beginning to emerge:
- Query Enhancement: Optimize and enhance queries using knowledge graphs to ensure the most relevant information is retrieved.
- Answer Enhancement: Improve the accuracy and completeness of the responses generated by the Big Language Model by adding relevant facts.
- Answer Control: Utilize knowledge graphs to verify the accuracy of AI-generated content and reduce the risk of incorrect or false information.
These patterns demonstrate how GraphRAG is changing the way AI systems process complex queries and generate answers.
Applications of GraphRAG
- Legal research: GraphRAG's ability to navigate through a complex web of law, jurisprudence and case studies provides legal professionals with a powerful tool to help discover relevant legal information and potential connections.
- Healthcare: In healthcare, GraphRAG helps understand the complex relationships in medical knowledge, patient history, and treatment options to improve diagnostic accuracy and personalized treatment planning.
- Financial Analysis: GraphRAG helps analyze complex financial networks and dependencies, leveraging interconnected data from the knowledge graph to provide insights into market trends, risk management and investment strategies.
- Social Network Analysis: GraphRAG makes it possible to explore complex social structures and interactions, helping researchers and analysts understand patterns of relationships and influence in social networks.
- Knowledge management: GraphRAG enhances the corporate knowledge base by capturing and leveraging relationships and hierarchies within an organization, improving decision-making processes and fostering innovation within the enterprise.
As AI advances, it is becoming increasingly important to incorporate knowledge graphs into retrieval augmentation generation systems. Knowledge graphs provide a powerful framework for organizing and connecting data, leading to more accurate, contextualized, and easily interpretable AI solutions.The emergence of GraphRAG demonstrates the advantages of combining knowledge graphs with traditional vector methods, providing a more comprehensive and efficient approach to information retrieval and answer generation.
Advanced RAG: Expanding Horizons through Enhanced Generation with Multimodal Retrieval
Advances in artificial intelligence have been accompanied by breakthroughs that continue to expand the boundaries of machine understanding and generation. While traditional retrieval-enhanced generation (RAG) systems have focused primarily on textual data, the emergence of multimodal RAG marks an important technological leap. This innovative technology enables AI to process and integrate multiple forms of data-such as text, images, audio, and video-to generate content-rich and contextualized output. By utilizing multimodal data, these advanced AI systems become more flexible, context-sensitive, and able to provide deeper insights and more accurate responses. This section explores the core concepts, operational mechanisms, and potential applications of multimodal RAG, highlighting its importance in the next generation of AI interactions.
Understanding Multimodal RAG
Multimodal RAG is an advanced extension of the classic RAG framework that combines retrieval mechanisms with generative AI for multiple data types. While traditional RAG systems obtain information by querying textual databases, multimodal RAG extends this capability by integrating text, images, audio, and video into the retrieval and generation process. This extension allows AI models to utilize a wider range of inputs to generate more comprehensive and nuanced results.
How does the multimodal RAG work?
The workflow of a multimodal RAG consists of encoding different types of data into a structured format, usually vectors, so that the AI model can process it. These vectors are stored in a shared embedding space that contains data from different modalities. When a query is made, the model retrieves relevant information from these modalities, thus ensuring a richer and more accurate response. For example, for a query about a historical event, the system may retrieve textual descriptions, relevant images, audio clips of expert commentary, and video footage, which together form a more detailed and informative response.
Methods for realizing multimodal RAGs
There are several approaches to realizing multimodal RAG, each with its own unique benefits and challenges:
- A single multimodal model:
This approach uses a unified model that is trained to encode various data types - e.g., text, images, audio - into a common vector space. The model can then seamlessly retrieve and generate across these data types. While this approach simplifies the process by using a single model, it requires complex training to ensure accurate encoding and retrieval of multimodal data. - Text-based base modal:
In this approach, non-textual data is converted into textual descriptions before encoding and storage. This approach takes advantage of the current state-of-the-art text models. However, there may be information loss during the conversion process, as nuances in the image or audio may not be fully represented in the text. - Multiple encoders:
This approach uses different models to encode different data types, each handled by its own specialized model. The retrieval process will integrate these results. While this approach allows for more specialized coding and more accurate data retrieval, it increases the complexity of the system and requires careful management of multiple models and their interactions.
Architecture of a multimodal RAG
The architecture of the multimodal RAG builds on the foundations of traditional RAGs while incorporating the complexity of dealing with multiple data types. The core architecture includes the following key components:
- Modal-specific encoders:
Each data modality, such as text, image or audio, is processed by a specialized encoder. These encoders convert the raw data into a uniform embedding space that allows all modalities to be compared and retrieved in a standardized way. - Shared embedded space:
A key component of a multimodal RAG is the shared embedding space, which stores encoded vectors from different modalities. This space allows for cross-modal comparisons and retrieval, enabling the model to recognize relevant information in different data types. - Retriever:
The Retriever component is responsible for querying the shared embedding space to find the most relevant data points across modalities. It can retrieve information based on various criteria such as relevance to the input query or similarity to other data points in the space. - Generator:
Once relevant information is retrieved, the generator component integrates this data into the AI model's response. The generator is typically a complex language model that can weave insights from multiple modalities into a coherent and contextually accurate output. - Integration mechanisms:
The fusion mechanism is responsible for combining the retrieved multimodal data into a unified representation for use by the generator. This process may involve selecting the most relevant modalities or synthesizing information from different sources to create a comprehensive response.
There are several key strategies that need to be employed to manage the information of different modalities in a RAG system:
- Uniformly embedded in the space:
Encoding all data types into a common embedding space enables the system to efficiently perform cross-modal retrieval operations. At the same time, this embedding space provides a basis for integrating and aligning data from different sources. - Cross-modal attention mechanisms:
Using a cross-modal attention mechanism ensures that the model can focus on the most relevant information in the retrieved data, regardless of which modality it comes from. This helps to balance the importance of various types of data in the final response. - Modality-specific post-processing:
After retrieval is complete, specific post-processing of the data for each modality may be required, such as resizing images or normalizing audio, to ensure that the data is optimized for integration and generation.
Multimodal RAG for Chatbot Applications
Multimodal RAGs greatly enhance the capabilities of chatbots, enabling them to provide richer and more contextualized interactive experiences. Traditional chatbots rely primarily on text, which limits their ability to respond to information that involves sight or sound. Multimodal RAG enables chatbots to capture and integrate information from images, video and audio clips to provide a more comprehensive and interesting user experience.
For example, using the multimodal RAG's Customer Support Chatbot Instructional videos, product images or audio guides can be displayed in response to a user's query, allowing for more interactive and practical assistance. This is particularly important in areas such as retail, healthcare and education, where communication often needs to be supported by multiple forms of information.
Expansion of multimodal RAG applications
The introduction of multimodal functionality is opening up new opportunities in a variety of industries:
- Healthcare:
Multimodal RAGs can combine textual medical records, radiologic images, laboratory results, and audio descriptions of patients to improve the accuracy and comprehensiveness of diagnostic systems. - Finance:
In financial services, multimodal RAG is able to process and analyze complex documents containing tables, charts and explanatory text to improve the decision-making process. - Education:
Educational platforms can utilize multimodal RAGs to blend text, video lectures, illustrations, and interactive simulations into a complete instructional story, providing a richer learning experience.
Multimodal RAG is an important technological advancement that has the potential to change the way AI systems interact with and respond to users. By incorporating multiple data types into the retrieval and generation process, multimodal RAG systems are able to provide richer, more accurate and contextualized outputs, opening up new possibilities across industries. As the technology evolves, it is expected that its applications will expand to further enhance AI's ability to process complex multimodal information.
How LeewayHertz's GenAI coordination platform, ZBrain, stands out among advanced RAG systems.
Curious about advanced RAG, multimodal RAG, and knowledge graphs? Imagine combining these powerful features into a single platform that allows you to easily build advanced AI applications. That's ZBrain.
ZBrainZBrain, developed by LeewayHertz, is a comprehensive orchestration platform designed to simplify and accelerate the development and scaling of enterprise-class AI solutions. Through its user-friendly, low-code environment, ZBrain enables organizations to rapidly create, deploy, and scale customized generative AI (GenAI) applications with reduced coding effort. The platform revolutionizes the enterprise AI development process by enabling organizations to leverage their own data to build highly customized and accurate AI applications. As a central control center, ZBrain seamlessly integrates with existing technology stacks to improve the efficiency of GenAI application development. Applications built on ZBrain excel in natural language processing (NLP) tasks such as report generation, translation, data analysis, text classification, and summarization. By leveraging private and contextual data, ZBrain ensures that responses are highly relevant and personalized to meet specific business needs.
How to interface with advanced Retrieval Augmentation Generation (RAG) systems
- Integration of diverse data sources: ZBrain integrates a variety of data sources including private, public, and real-time streams across all data formats (structured, semi-structured, and unstructured) to improve the accuracy and relevance of AI responses.
- Block-level optimization: The platform ensures that accurate and tailored outputs are generated by breaking down information into manageable chunks and applying the most effective search strategies.
- Automatic discovery of search strategies: Advanced algorithms in ZBrain automatically identify and apply optimal search strategies, reducing manual actions based on data and context and improving the accuracy of data retrieval.
- Protective measures and hallucination control: ZBrain is equipped with safeguards and phantom controls to prevent the generation of inaccurate or misleading information, ensuring high accuracy and reliability.
multimodal capability
- Handles multiple data formats. ZBrain excels in handling multiple data formats such as text, images, video and audio, providing a comprehensive and detailed response.
- Integration and Analysis Across Data Types. The platform is able to integrate and analyze various types of data to provide richer insights and relevant answers.
- Improved query processing. ZBrain efficiently manages and retrieves information from multiple data modalities, improving accuracy and insight into complex problems.
knowledge map
- Structured Data Framework. ZBrain organizes data into a structured network that improves retrieval accuracy and provides deeper insights by connecting related concepts.
- Deeper Data Insights. The interconnected nature of the Knowledge Graph enables ZBrain to deliver nuanced, context-aware answers that lead to richer and more meaningful insights.
- Extended Data Capabilities. ZBrain supports extending data at the block or file level, updating meta-information, and generating ontologies to improve data representation, organization, and retrieval.
Benefits of using ZBrain in enterprise AI solution development
ZBrain offers many advantages for enterprise AI solution development, including:
- scalability
ZBrain makes it easy to scale AI solutions to handle growing data volumes and usage scenarios without compromising performance. - Efficient integration
The platform easily integrates with existing technology stacks, reducing deployment time and cost and accelerating the adoption of AI. - customization
ZBrain supports the development of highly customized AI applications that meet specific business needs and align with organizational goals. - Resource efficiency
Its low-code nature reduces the need for a large number of developers and is suitable for organizations with smaller technical teams. - Comprehensive solutions
From development to deployment, ZBrain covers the entire lifecycle of an AI application in one comprehensive solution. - Cloud Neutral Deployment
ZBrain is cloud-neutral, allowing applications to be deployed on a variety of cloud platforms, providing flexibility to adapt to different organizational needs and infrastructure preferences.
ZBrain's advanced RAG system, multimodal support, and robust knowledge graph integration make it a powerful platform that delivers increased accuracy, efficiency, and insight across a wide range of applications.
footnote
Advances in Retrieval-Augmented Generation (RAG) have dramatically increased its capabilities, allowing it to overcome previous limitations and open up new potential in AI-driven information retrieval and generation. Through the use of sophisticated retrieval mechanisms, advanced RAG can access large amounts of data to ensure that the responses generated are both accurate and contextually relevant. This advancement paves the way for more dynamic and interactive AI applications, making RAG an important tool in areas such as customer service, research, knowledge management and content creation. The application of these advanced RAG technologies provides organizations with the opportunity to enhance the user experience, streamline processes and solve complex problems with greater accuracy and efficiency.
The introduction of Multimodal RAG and Knowledge Graph RAG further enhances the capabilities of this framework, driving widespread adoption across industries. Multimodal RAG combines textual, visual, and other forms of data to enable Large Language Modeling (LLM) to generate more comprehensive and context-aware responses that improve the user experience and provide richer and more nuanced information. And Knowledge Graph RAG utilizes interconnected data structures to retrieve and generate semantically rich content, greatly improving the accuracy and depth of information. These advances in RAG technology herald a new wave of AI innovation, providing smarter and more flexible solutions to complex information retrieval challenges.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...