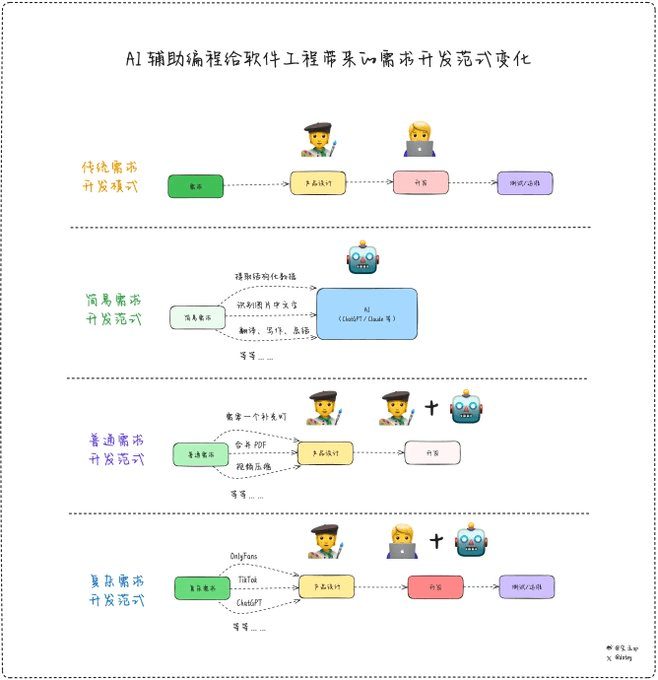
Optimal Text Segment Selection and URL Rearrangement in DeepSearch/DeepResearch

If you've read Jina's last long classic post,Design and Implementation of DeepSearch/DeepResearch", then it is worth digging deeper into the details that can dramatically improve the quality of the answer. This time, we will focus on two details:
Extracting optimal text segments from long web pages: How to use late-chunking algorithms to select the most relevant snippets of information from long web content. Rearrangement of collected URLs: How to use Reranker to let LLM Agent intelligently choose which URL to crawl among hundreds of URLs?
Some of you may remember our conclusion in the previous post that "In DeepSearch, the Embeddings model is only suitable for query de-duplication such as the STS (Semantic Text Similarity) task, and Reranker wasn't even in our original DeepSearch programming implementation."
In hindsight, both types of recall models still have their value, just not in the way we normally think of them. We've always followed the "80-20" principle in search, and we don't try to push models just to take care of the emotional value, or to prove our presence in the marketplace as a provider of Embeddings and Rerankers. We're very 80-20, very pragmatic.Pragmatic to the point that we only care about the most essential needs of the search system.
So, after weeks of trial and iteration, we discovered some unconventional but very effective applications of Embeddings and Reranker in the DeepSearch/DeepResearch system. After using these methods, we significantly improved the quality of Jina DeepSearch (you are welcome to experience them). We would also like to share these experiences with our peers who are working together in this field.
Selection of optimal text segments from long text
The problem is this: with Jina Reader After reading the content of the web page, we need to put it into the Agent's context as a piece of knowledge for it to reason about. While cramming the entire content into the LLM's context in one fell swoop would be the least cumbersome way to do this, given that the Token Cost and speed of generation, this is certainly not the best option. In practice, we need to identify the parts of the content that are most relevant to the problem and add only those parts as knowledge to the context of the Agent.
💡 Here we are talking about cases where the content is still too long even after cleaning it up into clean Markdown using Jina Reader. For example, in long pages like GitHub Issues, Reddit posts, forum discussions and blog posts.
LLM-based screening methods have the same cost and latency issues, so we'll have to find out if there are any small model solutions:We need smaller, cheaper models that still support multiple languages.This is a key factor, as there is no guarantee that questions or documentation will always be in Chinese.
On one side we have the question (the original query or "poor information" question) and on the other side we have a lot of Markdown content, most of which is irrelevant. We need to pick out the most relevant pieces to the question. It's a lot like RAG The chunking problem that the community has been working on since 2023 - using the Retriever model to retrieve only relevant chunks and put them into a context window for summarization.
However, there are two key differences in our situation:
A finite number of text blocks in a finite number of documents.
Assuming that each block has about 500 tokens, a typical long web document has about 200,000 to 1,000,000 tokens (99th percentile). We use Jina Reader to crawl 4-5 URLs at a time, which generates a few hundred blocks of text. That means hundreds of vectors and hundreds of cosine similarities. This is easily handled in memory with JavaScript, and there's no need for a vector database.
We need continuous blocks of text to form an effective summary of knowledge.
We cannot accept summaries like [1-2, 6-7, 9, 14, 17, ...] summaries that consist of scattered sentences like this. A more useful summary of knowledge would be like [3-15, 17-24, ...] which would better maintain the coherence of the text. This would make it easier for LLMs to copy and cite from knowledge sources, and would also reduce the number of "illusions".
The rest are the same caveats that developers complain about: each block of text can't be too long because the vector model can't handle too long a context; chunking leads to loss of context and makes the vectors in each block of text independently and identically distributed; and, how the heck do you find the optimal boundaries that preserve both readability and semantics? If you know what we're talking about, chances are you've been plagued by these problems in your RAG implementations as well.
But long story short - use jina-embeddings-v3 (used form a nominal expression) Late ChunkingIt solves all three problems perfectly. "Late splitting" preserves the contextual information of each block, is not sensitive to boundaries, and jina-embeddings-v3 itself state-of-the-art in asymmetric multilingual retrieval tasks. Interested readers can follow Jina's blog post or paper for details on the overall implementation.
🔗 https://arxiv.org/pdf/2409.04701

Flowchart for segment selection using late scores
This figure illustrates the summary selection algorithm, which works like one-dimensional convolution (Conv1D). The process first splits a long document into fixed-length chunks, and then uses a late-partitioning-enabled jina-embeddings-v3 vectorize these blocks of text. After calculating the similarity scores between each block and the question, a sliding window moves over these similarity scores to find the window with the highest average.
Here is the schematic code: using late partitioning and average pooling similar to "one-dimensional convolution" to pick out the most relevant passages to the problem.
function cherryPick(question, longContext, options) {
if (longContext.length < options.snippetLength * options.numSnippets)
return longContext;
const chunks = splitIntoChunks(longContext, options.chunkSize);
const chunkEmbeddings = getEmbeddings(chunks, "retrieval.passage");
const questionEmbedding = getEmbeddings([question], "retrieval.query")[0];
const similarities = chunkEmbeddings.map(embed =>
cosineSimilarity(questionEmbedding, embed));
const chunksPerSnippet = Math.ceil(options.snippetLength / options.chunkSize);
const snippets = [];
const similaritiesCopy = [...similarities];
for (let i = 0; i < options.numSnippets; i++) {
let bestStartIndex = 0;
let bestScore = -Infinity;
for (let j = 0; j <= similarities.length - chunksPerSnippet; j++) {
const windowScores = similaritiesCopy.slice(j, j + chunksPerSnippet);
const windowScore = average(windowScores);
if (windowScore > bestScore) {
bestScore = windowScore;
bestStartIndex = j;
}
}
const startIndex = bestStartIndex * options.chunkSize;
const endIndex = Math.min(startIndex + options.snippetLength, longContext.length);
snippets.push(longContext.substring(startIndex, endIndex));
for (let k = bestStartIndex; k < bestStartIndex + chunksPerSnippet; k++)
similaritiesCopy[k] = -Infinity;
}
return snippets.join("\n\n");
}
When calling the Jina Embeddings API, remember to set the task Set to retrieval, open the late_chunking(math.) genustruncate Also set it up like below:
await axios.post(
'https://api.jina.ai/v1/embeddings',
{
model: "jina-embeddings-v3",
task: "retrieval.passage",
late_chunking: true,
input: chunks,
truncate: true
},
{ headers });
If the problem is to be vectorized, remember to put task exchange (sth) for (sth else) retrieval.queryThen turn it off. late_chunkingThe
The full implementation code can be found on GitHub:https://github.com/jina-ai/node-DeepResearch/blob/main/src/tools/jina-latechunk.ts
URL Sorting for Next Reads
The problem is as follows: In every DeepSearch long process, you may collect a bunch of URLs from the search engine results page (SERP), and every time you open a web page, you can find out a lot of new links along the way, even after de-emphasizing, it's still easily a few hundred URLs. Similarly, stuffing LLMs with all these URLs will not work. Not only will it waste valuable context length, but more importantly, we found that LLMs are basically just choosing blindly. So we had to find a way to guide the LLM to pick out the URLs that were most likely to contain the answer.
curl https://r.jina.ai/https://example.com \
-H "Accept: application/json" \
-H "Content-Type: application/json" \
-H "X-Retain-Images: none" \
-H "X-Md-Link-Style: discarded" \
-H "X-Timeout: 20" \
-H "X-With-Links-Summary: all"
This is the best way to configure Jina Reader to crawl a page in DeepSearch. It will single out all the links on the page, put them in the links field, and delete them from the content field.
You can think of this problem as "in-context PageRank", except that we are scoring hundreds of URLs in a single session.
We take into account several factors: time of last update, frequency of occurrence of the domain name, structure of the page path, and most importantly semantic relevance to the question, to calculate a composite score. However, we can only use information that is available before we even click on the URL.

1. Frequency signals: If a URL appears several times in different sources, it is given more weight. Also, if a domain name appears frequently in search results, URLs from that domain are given extra points. This is because, in general, popular domains tend to contain more authoritative content.
2. Route structure: We analyze the path structure of URLs to determine what content is clustered together. If multiple URLs all belong to the same path hierarchy, they will score higher; however, the deeper the path, the score bonus will gradually decrease.
3. Semantic relevance: we use jina-reranker-v2-base-multilingual to evaluate the semantic relevance of the question and the textual information (e.g., title and abstract) of each URL, which is a typical reordering problem. The textual information for each URL comes from several places:
Search Engine Results Page (SERP) API Returns title and summary (https://s.jina.ai/ This interface, with 'X-Respond-With': 'no-content', returns just the title and summary, not the specific content). Anchor text for URLs on the page (using the https://r.jina.ai interface and setting 'X-With-Links-Summary': 'all' returns summary information, or anchor text, for all links within the page).
4. Last updated: Some of DeepSearch's queries have high timeliness requirements, so in general, the newer the URL, the higher the value. However, without the large-scale indexing capability of Google, it is difficult to accurately determine the last update time of a web page. We use a combination of the following signals to give a timestamp with a confidence score so that we can prioritize displaying the latest content when needed:
Filtering functions provided by the SERP API (e.g., the tbs parameter of s.jina.ai, which allows filtering by time). HTTP Header information analysis (such as Last-Modified and ETag fields). Metadata extraction (e.g. meta tags and Schema.org timestamps). Content pattern recognition (recognizes dates visible in HTML). Metrics for specific CMS platforms (e.g. WordPress, Drupal, Ghost, etc.)
5. Restricted content: Some social media platforms have content that is restricted or requires payment to access. There is no way to legally access this content without logging in. Therefore, we actively maintain a blacklist of these problematic URLs and domains, lowering their rankings and avoiding wasting computing resources on this inaccessible content.
6. Domain name diversitySometimes the top URLs are all from the same domain, which can cause DeepSearch to fall into "local optimization" and affect the quality of the final results. As mentioned earlier, the top URLs are all from StackOverflow, so to increase the diversity of the results, we can use an "explore-and-exploit" strategy: select the top K URLs from each domain.
The full code implementation of URL sorting can be found on our Github: https://github.com/jina-ai/node-DeepResearch/blob/main/src/utils/url-tools.ts#L192
<action-visit>
- Crawl and read full content from URLs, you can get the fulltext, last updated datetime etc of any URL.
- Must check URLs mentioned in <question> if any
- Choose and visit relevant URLs below for more knowledge. higher weight suggests more relevant:
<url-list>
+ weight: 0.20 "https://huggingface.co/docs/datasets/en/loading": "Load - Hugging FaceThis saves time because instead of waiting for the Dataset builder download to time out, Datasets will look directly in the cache. Set the environment ...Some datasets may have more than one version based on Git tags, branches, or commits. Use the revision parameter to specify the dataset version you want to load ..."
+ weight: 0.20 "https://huggingface.co/docs/datasets/en/index": "Datasets - Hugging Face🤗 Datasets is a library for easily accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP) tasks. Load a dataset in a ..."
+ weight: 0.17 "https://github.com/huggingface/datasets/issues/7175": "[FSTimeoutError] load_dataset · Issue #7175 · huggingface/datasetsWhen using load_dataset to load HuggingFaceM4/VQAv2, I am getting FSTimeoutError. Error TimeoutError: The above exception was the direct cause of the following ..."
+ weight: 0.15 "https://github.com/huggingface/datasets/issues/6465": "`load_dataset` uses out-of-date cache instead of re-downloading a ...When a dataset is updated on the hub, using load_dataset will load the locally cached dataset instead of re-downloading the updated dataset."
+ weight: 0.12 "https://stackoverflow.com/questions/76923802/hugging-face-http-request-on-data-from-parquet-format-when-the-only-way-to-get-i": "Hugging face HTTP request on data from parquet format when the ...I've had to get the data from their data viewer using the parquet option. But when I try to run it, there is some sort of HTTP error. I've tried downloading ..."
</url-list>
</action-visit>
summarize
Since Jina's DeepSearch was made available on February 2, 2025, two engineering details have been discovered that can dramatically improve quality.Interestingly, both details utilize multilingual Embedding and Reranker models in an "in-context-window" manner.It's nothing compared to the massive precomputed indexes that these models typically require.
This may foreshadow that future search technologies will move in the direction of polarization. We can borrow Kahneman's theory of dual processes to understand this trend:
Think fast. Fast-think (grep, BM25, SQL): fast, rule-based pattern matching with minimal computation. think slowly Slow-think (LLM): comprehensive reasoning with deep contextual understanding, but computationally intensive. mediumlook after Mid-think (Embedding, Reranker et al. Recall Model): has some semantic understanding, better than simple pattern matching, but far less inference than LLM.
One possibility is:Two-tiered search architectures are becoming increasingly popular: The lightweight, efficient SQL/BM25 takes care of the input of the retrieval and then feeds the results directly to the LLM for retrieval of the output. The residual value of the middle tier model is then shifted to tasks within a specific context window: e.g., filtering, de-duplication, sorting, and so on. In these scenarios, it would be inefficient to do complete reasoning with LLM instead.
But anyway.Selection of key segments cap (a poem) URL Sorting Still is still the fundamental aspect that directly affects the quality of a DeepSearch/DeepResearch system. We hope our findings will help you improve your own system.
Query expansion is another key factor in determining quality.Vegetables.We are actively evaluating a variety of approaches, from simple Prompt-based rewrites, to miniatures, to inference-based approaches. Please look forward to our subsequent findings in this direction!
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles



No comments...