How to calculate the number of parameters for a large model, and what do 7B, 13B and 65B stand for?

Recently, many people engaged in large model training and inference have been discussing the relationship between the number of model parameters and model size. For example, the famous alpaca series of LLaMA large models contains four versions with different parameter sizes, LLaMA-7B, LLaMA-13B, LLaMA-33B and LLaMA-65B.
The "B" here is an abbreviation for "Billion", which stands for billion. Thus, the smallest LLaMA-7B model contains about 7 billion parameters, while the largest LLaMA-65B model contains about 65 billion parameters.
So, how are these parametric quantities calculated? Also, what is the approximate level of large model parameter count corresponding to a 100GB model file? Billions, tens of billions, hundreds of billions, or trillions? This paper will answer these questions in depth.
I. Methods for calculating the amount of large model parameters
We will take the Transformer, the infrastructure of the big model, as an example to analyze the process of parameter counting in detail.
A standard Transformer The model consists of L identical layers stacked on top of each other, and each layer contains two main parts: the Self-Attention layer (SAL) and the feed-forward neural network layer (MLP).
1. Self-Attention
Self-attention mechanism is the core of Transformer. Whether it is Self-Attention or Multi-Head Self-Attention (MHA), its core parameter amount is calculated in the same way.
In the self-attention layer, the input sequence is first mapped into three vectors: a query vector (Query, Q), a key vector (Key, K) and a value vector (Value, V). In MHA, these three vectors are further partitioned into multiple heads, each of which is responsible for focusing on a different part of the input sequence.

- Single-head self-attention. Q, K, V are each linearly transformed by a weight matrix of shape [h, h], where h is the hidden layer dimension. Thus, the total number of parameters of Q, K, V is 3h². In addition, there is a linear transformation layer for the output with the same weight matrix shape [h, h]. Therefore, the total number of parameters for single-headed self-attention is 4h² (ignore the bias term).
- Multi-Headed Attention (MHA). Suppose there are n_heads, each with dimension h_head = h / n_head. Each head has a separate Q, K, V weight matrix of the shape [h, h_head]. Therefore, the parametric quantity of the Q, K, V weight matrices for each head is 3 * h * h_head = 3h²/n_head. The total number of parameters for the n_head heads is n_head * (3h²/n_head) = 3h². Finally, the shape of the linear transformation weight matrix of the output layer is [h, h]. So the total number of parameters in the MHA is also 4h² (ignore the bias term).
Therefore, the number of parameters in the self-attentive layer can be approximated as 4h², both for single and multiple heads.
2. Feed-forward neural network layer (MLP)
The MLP layer consists of two linear layers. The first linear layer extends the hidden layer dimension h to 4h, and the second linear layer then shrinks the dimension back from 4h to h.

- The weight matrix of the first linear layer has the shape [h, 4h] and the number of parameters is 4h².
- The weight matrix of the second linear layer has the shape [4h, h] and the number of parameters is also 4h².
The total number of parameters in the MLP layer is therefore 8h² (ignoring the bias term).
3. Layer Normalization
After each Self-Attention and MLP layer, and after the last layer of Transformer output, there is usually a Layer Normalization operation. Each Layer Normalization layer contains two trainable parameters:
- Scaling parameter (gamma): the shape is [h].
- Translation parameter (beta): the shape is [h].
Since each Transformer layer has two Layer Normalization (after Self-Attention and MLP, respectively) plus one after the output layer, the total number of Layer Normalization parameters for the L-layer Transformer is (2L + 1) * 2h.
4. Embedding
The input text first needs to be converted into word vectors through the word embedding layer. Assuming that the size of the word list is V and the dimension of the word vector is h, then the number of parameters of the word embedding layer is Vh.
5. Output layer
The weight matrix of the output layer is usually shared with the word embedding layer (Weight Tying) to reduce the number of parameters and possibly improve performance. Therefore, if weight sharing is used, the output layer usually does not introduce additional number of parameters. If no sharing is used, the number of parameters is Vh.
6. Positional Encoding
Position encoding is used to provide the model with information about the position of words in the input sequence.
- Trainable Position Codes. If trainable positional encoding is used, the number of parameters is N * h, where N is the maximum sequence length. For example, the maximum sequence length of ChatGPT is 4k.
- Relative position codes (e.g. RoPE or ALiBi). These methods do not introduce trainable parameters.
Due to the relatively small number of positionally encoded parameters, they are usually negligible in the calculation of the total number of parameters.
7. Calculation of the total number of participants
In summary, the total number of parameters for an L-layer Transformer model is:
Total number of parameters = L * (Self-Attention parameter + MLP parameter + LayerNorm parameter * 2) + Embedding parameter + Output layer parameter + LayerNorm parameter (after output layer)
Total number of parameters ≈ L * (4h² + 8h² + 4h) + Vh + (optional Vh) + 2h
Total number of parameters ≈ L * (12h² + 4h) + Vh + 2h (assuming that the output layer shares weights with the word embedding layer)
When the hidden dimension h is large, the primary terms 4h and 2h are negligible and the model parametric quantities can be further approximated as:
Total number of parameters ≈ 12Lh² + Vh
8. Estimation of the number of LLaMA participants
The following table shows some of the key parameters of the different versions of LLaMA and the estimation of their parameter counts:
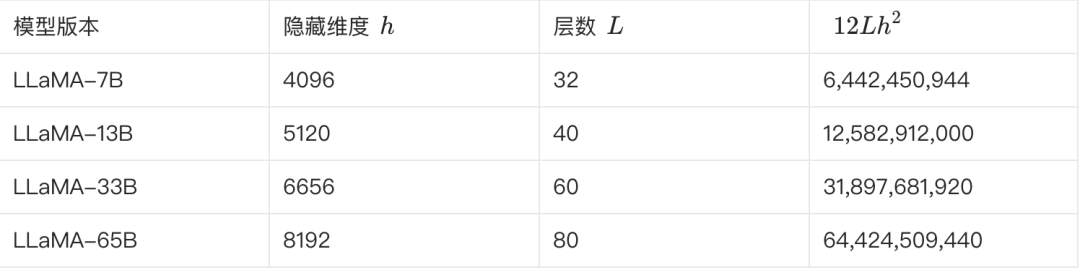
**We can verify this based on the above equation. In the case of LLaMA-7B, for example, according to the table, L=32, h=4096, V=32000.**
Estimated number of parameters ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6.55B
This estimate is closer to 6.7B. Several other versions can be estimated and validated in this way.
II. Large model parametric quantities and model size conversion
Understanding how the number of parameters is calculated, we next look at how the number of parameters and the model size are converted.
We still use LLaMA-7B as an example, which has about 7 billion participants.
- Theoretical calculations. If each parameter is stored in FP32 (32-bit floating point number occupying 4 bytes) format, the theoretical size of LLaMA-7B is: 7B * 4 bytes = 28GB.
- Physical Storage. In order to save storage space and improve computational efficiency, model weights are usually stored in a lower precision format, such as FP16 (16-bit floating-point number occupying 2 bytes) or BF16. When using FP16 storage, the size of LLaMA-7B is theoretically: 7B * 2 bytes = 14GB.
- Other factors. In addition to the weight parameters, the model file may also contain information about the optimizer state (e.g., momentum and variance of the Adam optimizer), word lists, model configuration, etc., which will take up additional storage space. In addition, some parameters (e.g., gamma and beta for Layer Normalization) may be stored in FP32 format.
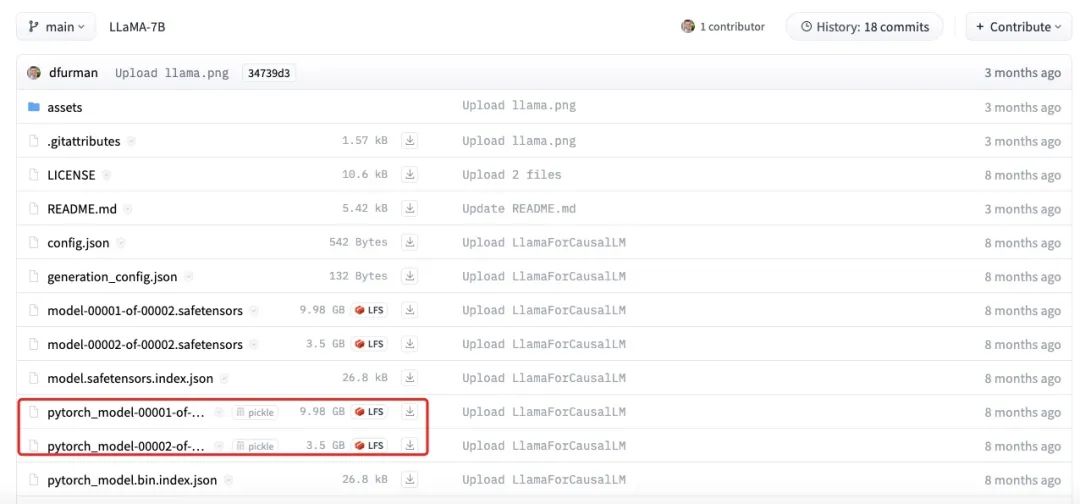
The figure above shows the actual size of the LLaMA-7B model file. It can be seen that the total size of each part is about 13.5GB, which is closer to our estimate of 14GB. The small differences may be caused by rounding errors, bias parameters, or the fact that some parameters are still stored using FP32.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...