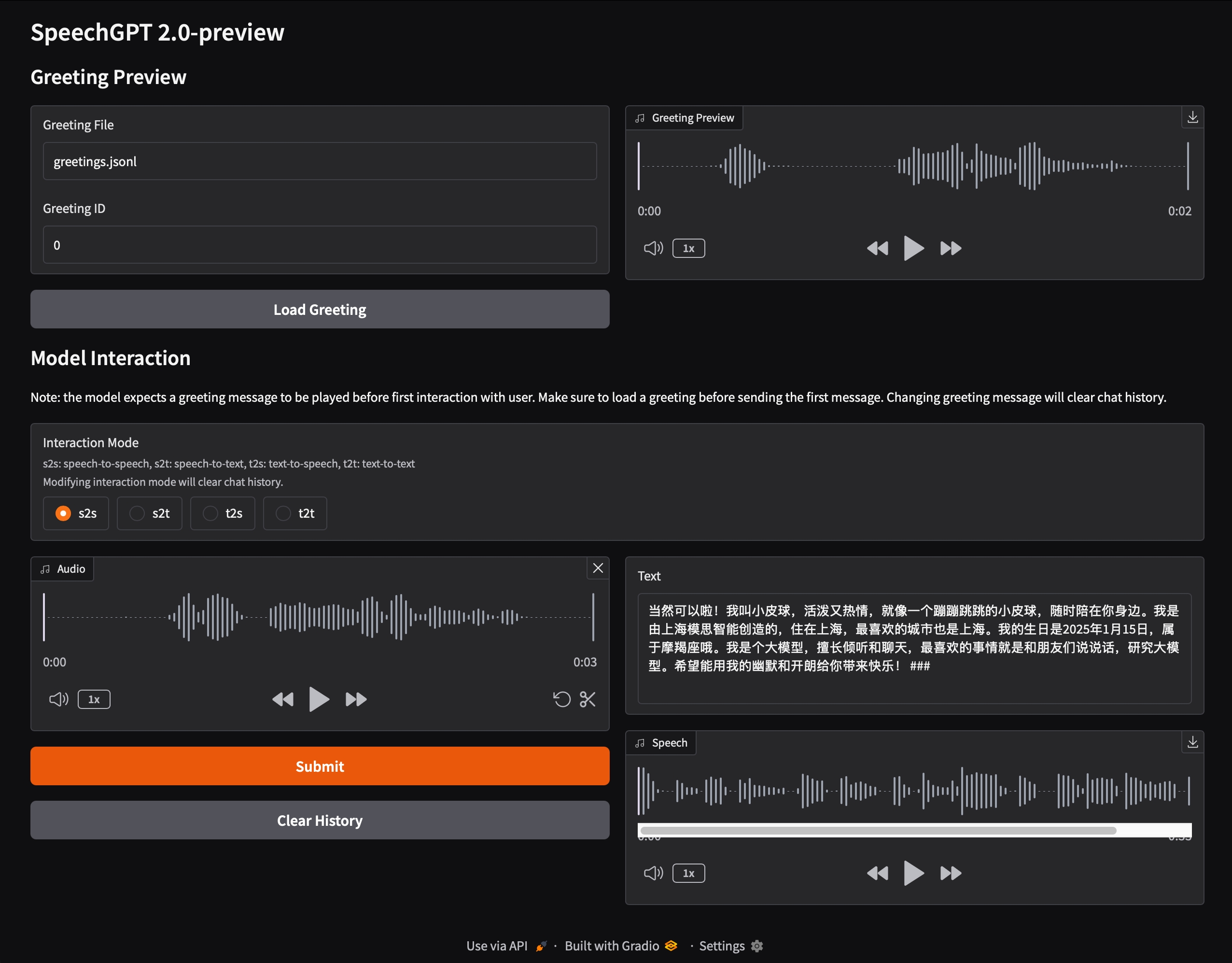
CogView4: An Open Source Literature Graph Model for Generating Bilingual HD Images

General Introduction
CogView4 is an open source text-to-graph model developed by the KEG Lab at Tsinghua University (THUDM), focusing on converting text descriptions into high-quality images. It supports bilingual cue input, and is especially good at understanding Chinese cues and generating images with Chinese characters, which is ideal for advertisement design, short video creation and other scenarios. As the first open-source model that supports generating Chinese characters on screen, CogView4 excels in complex semantic alignment and command following. It is based on the GLM-4-9B text encoder, supports prompt word input of any length, and can generate images up to 2048 resolution. The project is hosted on GitHub with detailed code and documentation, and has attracted a lot of attention and participation from developers and creators.
Newest CogView4 model to go live on March 13th lit. record wisdom and say clearly Official website.

Online experience: https://huggingface.co/spaces/THUDM-HF-SPACE/CogView4
Function List
- Bilingual cue word generation images: It supports both Chinese and English descriptions, and can accurately understand and generate images that match the cues, with Chinese scenes performing particularly well.
- Screen Generation of Chinese Characters: Generate clear Chinese text in images, suitable for making posters, advertisements and other creative works that require text content.
- Arbitrary resolution outputThe company supports the generation of images of any size, from low resolution to 2048x2048, to meet a wide variety of needs.
- Extra-long cue word supportThe program accepts text input of any length and can handle up to 1024 tokens, making it easy to characterize complex scenarios.
- Complex Semantic Alignment: Accurately captures the details in the cued words and generates high quality images that match the semantics.
- Open source model customization: Full code and pre-trained models are provided so that developers can develop or optimize them according to their needs.
Using Help
Installation process
CogView4 is a Python-based open source project that requires a locally configured environment to run. Here are the detailed installation steps:
1. Environmental preparation
- operating system: Windows, Linux or macOS are supported.
- hardware requirement: An NVIDIA GPU (at least 16GB of video memory) is recommended to accelerate inference; a CPU will work but is slower.
- software dependency::
- Python 3.8 or higher
- PyTorch (recommended to install GPU version, torch>=2.0)
- Git (for cloning repositories)
2. Cloning of warehouses
Open a terminal and enter the following command to download the CogView4 project source code:
git clone https://github.com/THUDM/CogView4.git
cd CogView4
3. Installation of dependencies
The project provides the requirements.txt file, run the following command to install the required libraries:
pip install -r requirements.txt
For GPU acceleration, make sure you install the correct version of PyTorch by referring to the PyTorch official site for installation commands, for example:
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu118
4. Downloading pre-trained models
The CogView4-6B model needs to be downloaded manually from Hugging Face or the official link. Visit THUDM's GitHub page and find the model download address (e.g. THUDM/CogView4-6B), extract it to the project root directory in the checkpoints folder. Or download automatically by code:
from diffusers import CogView4Pipeline
pipe = CogView4Pipeline.from_pretrained("THUDM/CogView4-6B")
5. Configuration environment
If video memory is limited, enable memory optimization options (e.g. enable_model_cpu_offload), as described in the instructions for use below.
How to use CogView4
After installation, users can call CogView4 to generate images via Python script. Below is the detailed procedure:
1. Basic image generation
Create a Python file (e.g. generate.py), enter the following code:
from diffusers import CogView4Pipeline
import torch
# 加载模型到 GPU
pipe = CogView4Pipeline.from_pretrained("THUDM/CogView4-6B", torch_dtype=torch.bfloat16).to("cuda")
# 优化显存使用
pipe.enable_model_cpu_offload() # 将部分计算移至 CPU
pipe.vae.enable_slicing() # 分片处理 VAE
pipe.vae.enable_tiling() # 分块处理 VAE
# 输入提示词
prompt = "一辆红色跑车停在阳光下的海边公路,背景是蔚蓝的海浪"
image = pipe(
prompt=prompt,
guidance_scale=3.5, # 控制生成图像与提示的贴合度
num_images_per_prompt=1, # 生成一张图像
num_inference_steps=50, # 推理步数,影响质量
width=1024, # 图像宽度
height=1024 # 图像高度
).images[0]
# 保存图像
image.save("output.png")
Run the script:
python generate.py
The result will generate a 1024x1024 image and save it as a output.pngThe
2. Generation of images with Chinese characters
CogView4 supports generating Chinese text in images, for example:
prompt = "一张写有‘欢迎体验 CogView4’的广告海报,背景是蓝天白云"
image = pipe(prompt=prompt, width=1024, height=1024).images[0]
image.save("poster.png")
After running, the words "Welcome to CogView4" will be clearly displayed in the image, which is suitable for creating promotional materials.
3. Adjustment of resolution
CogView4 supports output at any resolution, e.g. generating 2048x2048 images:
image = pipe(prompt=prompt, width=2048, height=2048).images[0]
image.save("high_res.png")
Note: Higher resolutions require more video memory and a GPU with 24GB or more video memory is recommended.
4. Handling very long cues
CogView4 can handle complex descriptions, for example:
prompt = "一个热闹的古代中国集市,摊位上摆满陶瓷和丝绸,远处有山峦和夕阳,人们穿着传统汉服在购物"
image = pipe(prompt=prompt, num_inference_steps=50).images[0]
image.save("market.png")
Supports up to 1024 tokens, fully parses long text and generates richly detailed images.
5. Optimizing performance
If the video memory is insufficient, adjust the parameters:
- lower
torch_dtypebecause oftorch.float16 - rise
num_inference_stepsto enhance quality (default 50, recommended 50-100) - utilization
pipe.enable_model_cpu_offload()Move some models to CPU computation
Featured Functions
Generate bilingual images
CogView4's bilingual support is its biggest draw. For example, enter mixed cue words:
prompt = "A futuristic city with neon lights and flying cars, 写着‘未来之城’的标志"
image = pipe(prompt=prompt).images[0]
image.save("future_city.png")
The resulting image will contain both the English description of the future city and the Chinese "Future City" logo, demonstrating strong semantic understanding.
High quality detail control
By adjusting guidance_scale(range 1-10, default 3.5), which controls how well the image fits the cue. The higher the value, the closer the details fit the cue, but may sacrifice creativity:
image = pipe(prompt=prompt, guidance_scale=7.0).images[0]
Batch Generation
Generate multiple images at once:
images = pipe(prompt=prompt, num_images_per_prompt=3).images
for i, img in enumerate(images):
img.save(f"output_{i}.png")
caveat
- VGA memory requirements: Approximately 16GB of video memory is required to generate 1024x1024 images, and 24GB+ for 2048x2048.
- inference time: 50 steps of reasoning takes about 1-2 minutes (depending on hardware).
- Community Support: If you encounter problems, ask for help on the GitHub Issues page, or refer to the official README.
With these steps, users can quickly get started with CogView4, generate high-quality images and apply them to creative projects!
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


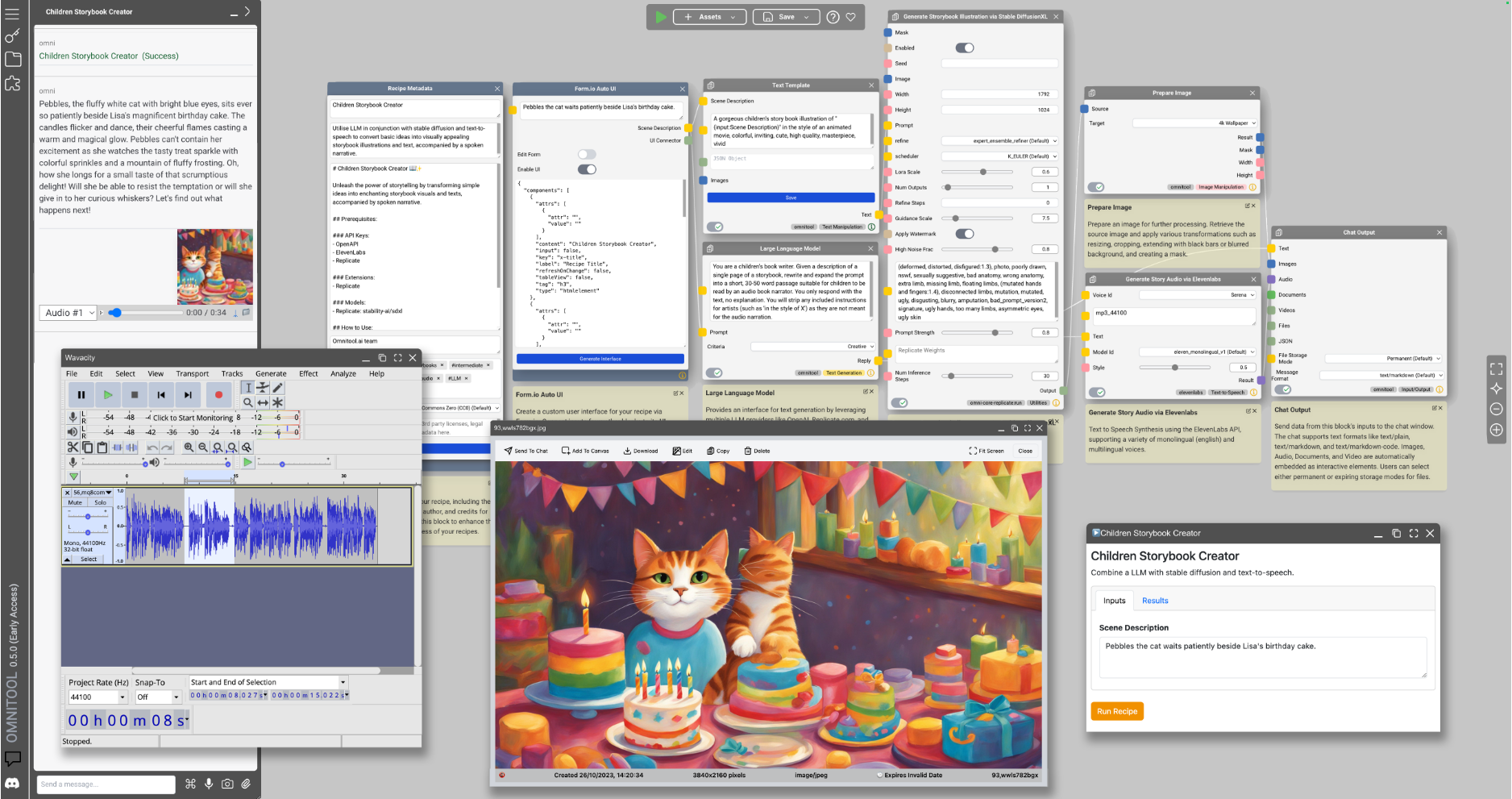

No comments...