
AI Engineering Institute: 2.9 Sentence Window Retrieval Augmented Generation (RAG)

introductory
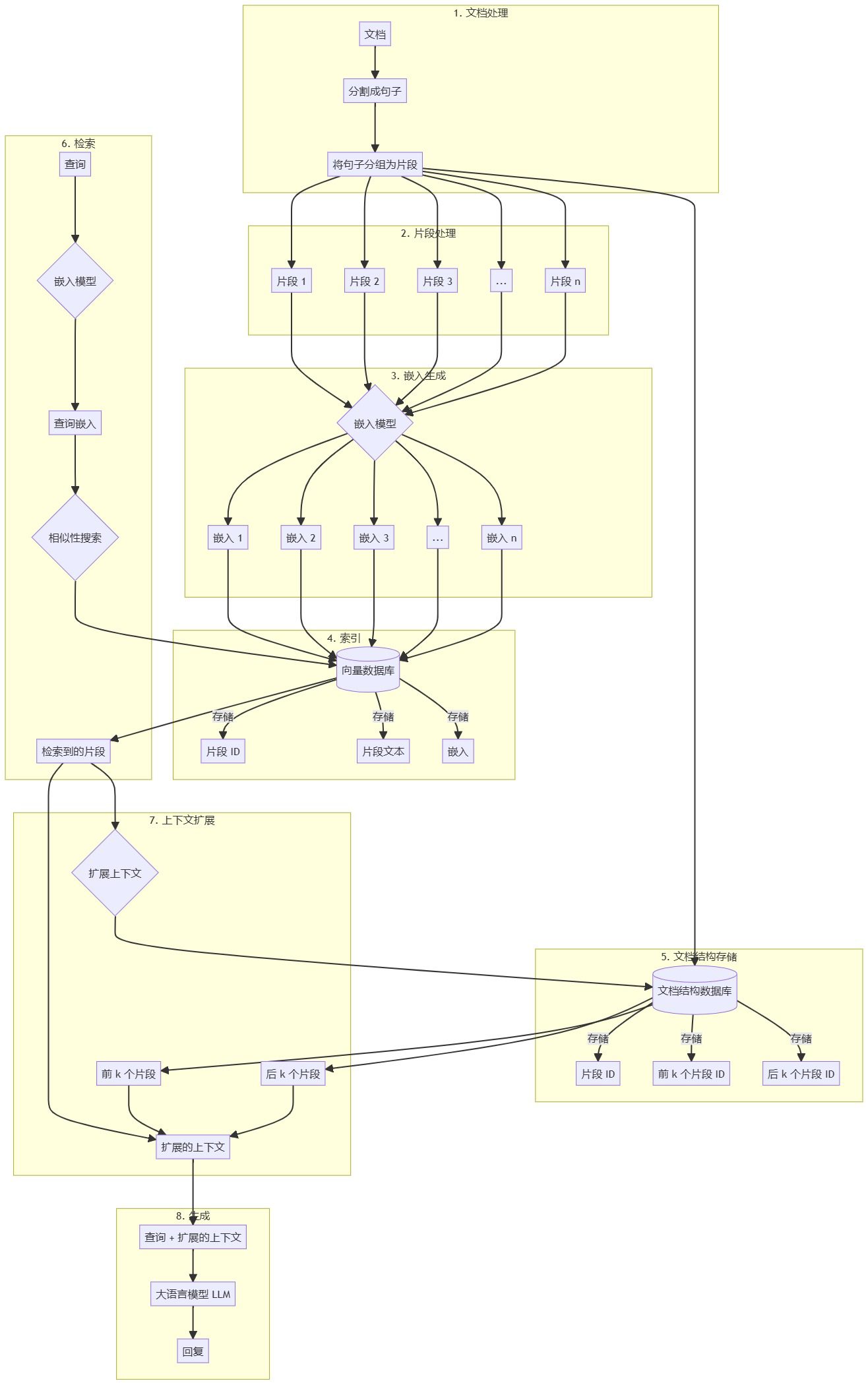
The Retrieval-Augmented Generation (RAG) method based on sentence windows is RAG A high-level implementation of a framework designed to enhance the context-awareness and coherence of AI-generated responses. The approach combines the power of large language modeling with efficient information retrieval techniques to provide a reliable solution for generating high-quality and context-rich responses.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/04_Sentence_Window_RAG
locomotive
Conventional RAG systems often struggle to maintain coherence across larger contexts or perform inadequately when dealing with information that spans multiple blocks of text. Sentence window-based retrieval-enhanced generation approaches address this limitation by preserving the contextual relationships between text blocks during the indexing process and utilizing this information in the retrieval and generation process.
Methodological details
Document preprocessing and vector store creation
- Document Splitting: Split the input document into sentences.
- Text Block Creation: Groups sentences into manageable chunks of text.
- embedded representation: Each text block is processed through an embedding model to generate a vector representation.
- Vector Database Index: Stores the IDs of text blocks, text contents and embedding vectors into a vector database for efficient similarity search.
- Document Structure Index: A separate database is used to store the relationships between blocks of text, including references of each block to the k preceding and following blocks.
Retrieval Enhancement Generation Workflow
- query processing: Embedded representation of user queries using the same embedding model as for text blocks.
- Similarity Search: Use query embedding vectors to retrieve the most relevant blocks of text in the vector database.
- context extension (computing): For each retrieved text block, k text blocks before and after are obtained from the document structure database for context expansion.
- contextual combination: Combine the retrieved text block and its extended context with the original query.
- Generating a Response: Pass the extended context and query to the big language model to generate the final answer.
Core features of RAG
- Efficient retrieval: Fast and accurate information retrieval through vector similarity search.
- Contextual reservations: Maintains the relationship between document structure and text blocks during the indexing phase.
- Flexible Context Window: Allows resizing of the context window during the retrieval phase.
- scalability: Can handle large collections of documents as well as diverse query types.
Advantages of the method
- Enhancing coherence: Contextual information is enhanced by the introduction of surrounding blocks of text, resulting in more coherent and contextually accurate responses.
- Reduction of hallucinations: By accessing the extended context, the model is enabled to generate answers based on the retrieved information, reducing the probability of generating false or irrelevant content.
- Storage Efficiency: Optimize storage space by storing only the necessary information into the vector database.
- Adjustable Context Window: Dynamically resize the context window according to the needs of different queries or applications.
- Retaining document structure: Maintaining the structure and flow of the original document allows the AI to understand and generate the document in a more nuanced way.
summarize
The Sentence Window-based Retrieval Augmented Generation (RAG) approach provides a powerful solution for improving the quality and contextual relevance of AI-generated responses. By preserving document structure and supporting flexible context extensions, the approach effectively addresses some of the key limitations of traditional RAG systems. It provides a reliable framework for building advanced Q&A systems, document analysis and content generation applications.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...