
AI Engineering Institute: 2.4 Data Chunking Techniques for Retrieval Augmented Generation (RAG) Systems

summary
Data chunking is a key step in a retrieval augmentation generation (RAG) system. It breaks large documents into smaller, manageable pieces for efficient indexing, retrieval, and processing. This README provides RAG Overview of the various chunking methods available in the pipeline.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
Importance of chunking in RAG
Effective chunking is critical to the RAG system because it can:
- Improve retrieval accuracy by creating coherent self-contained units of information.
- Improving the efficiency of embedding generation and similarity search.
- Allows for more precise context selection when generating responses.
- Help manage language models and embedded systems of Token Limitations.
Chunking method
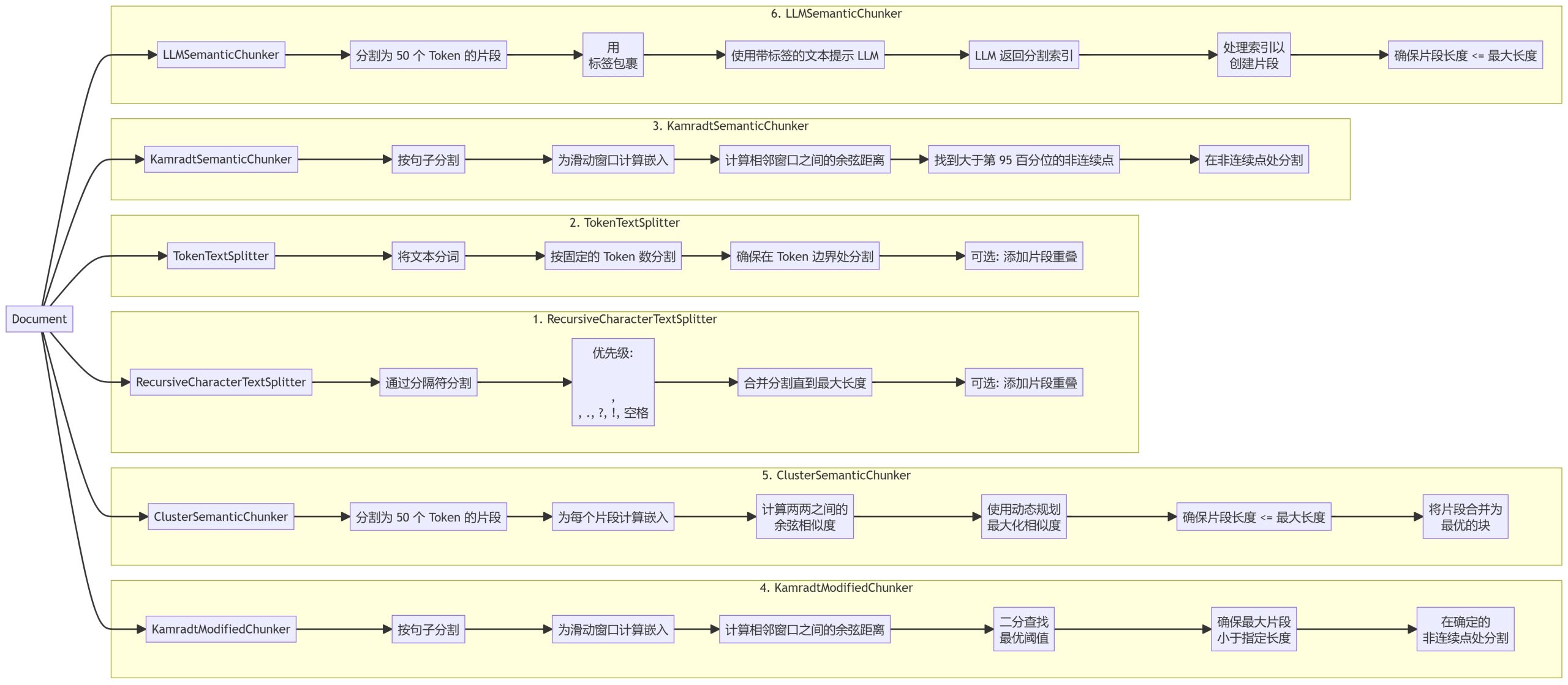
We have implemented six different chunking methods, each with different advantages and usage scenarios:
- RecursiveCharacterTextSplitter
- TokenTextSplitter
- KamradtSemanticChunker
- KamradtModifiedChunker
- ClusterSemanticChunker
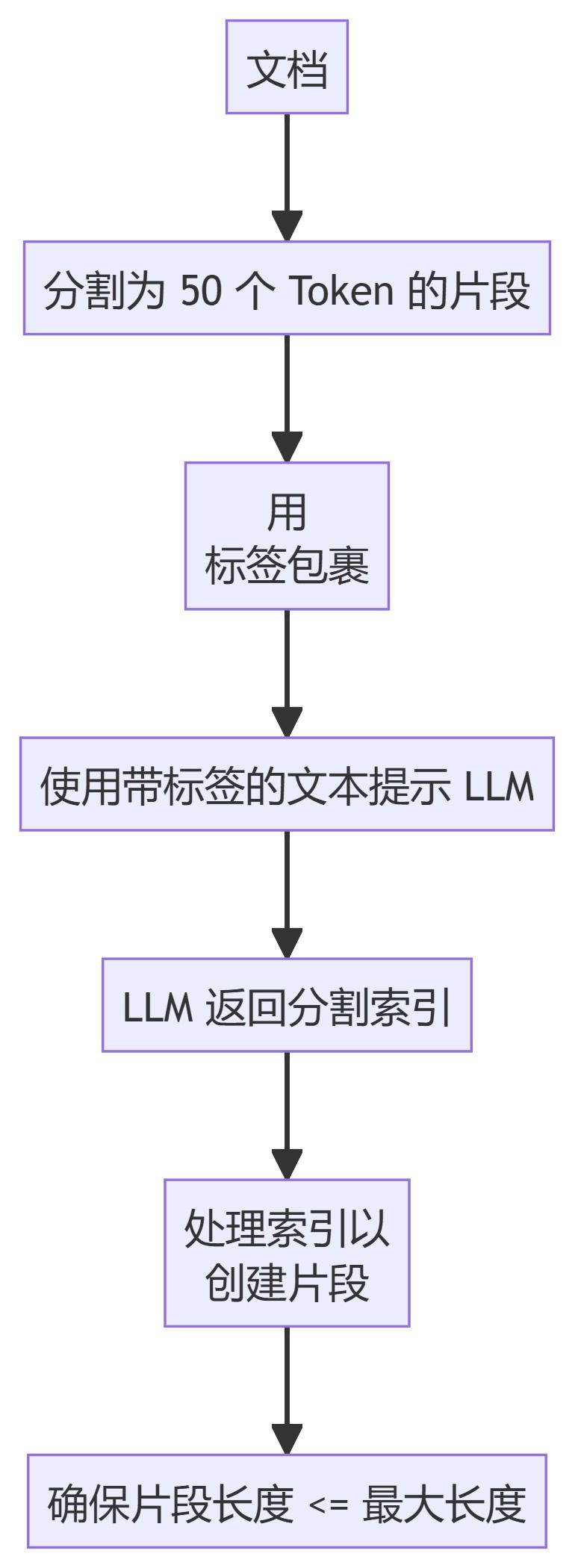
- LLMSemanticChunker
chunking
1. RecursiveCharacterTextSplitter
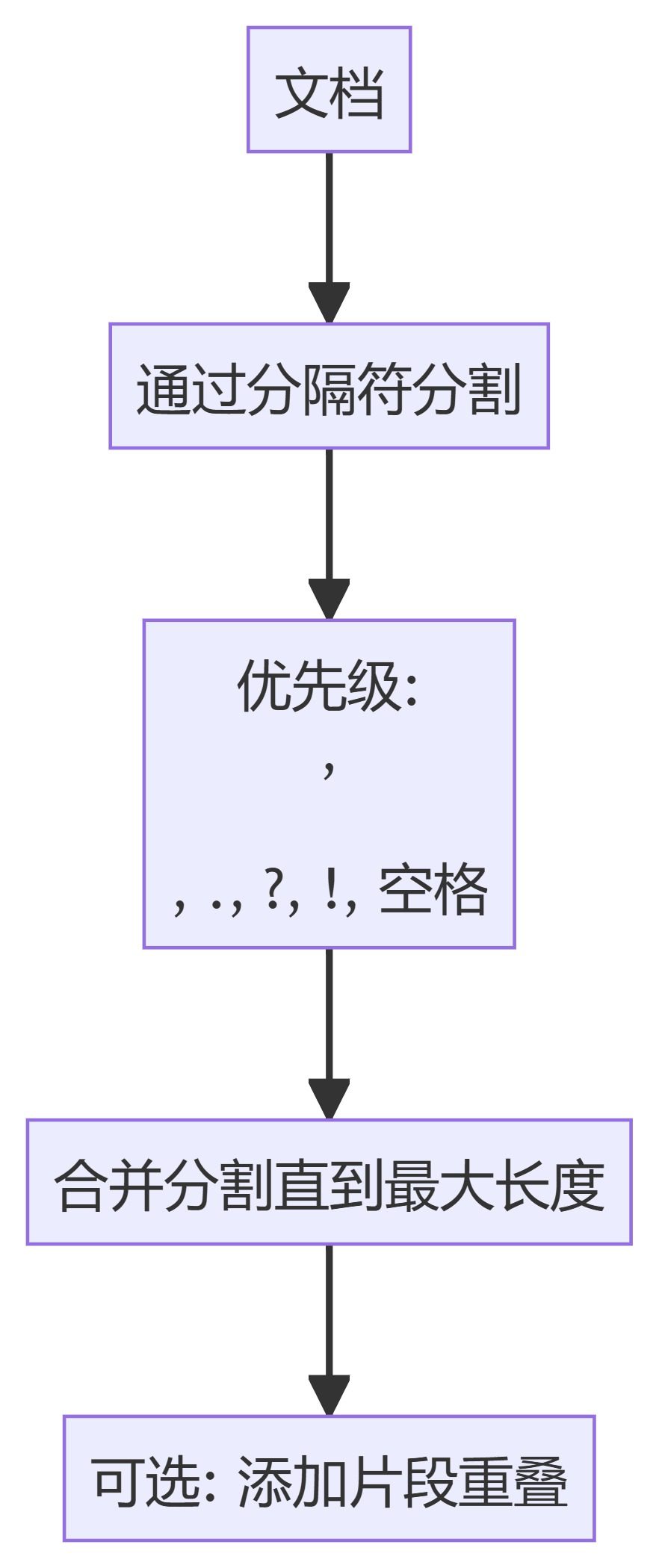
2. TokenTextSplitter

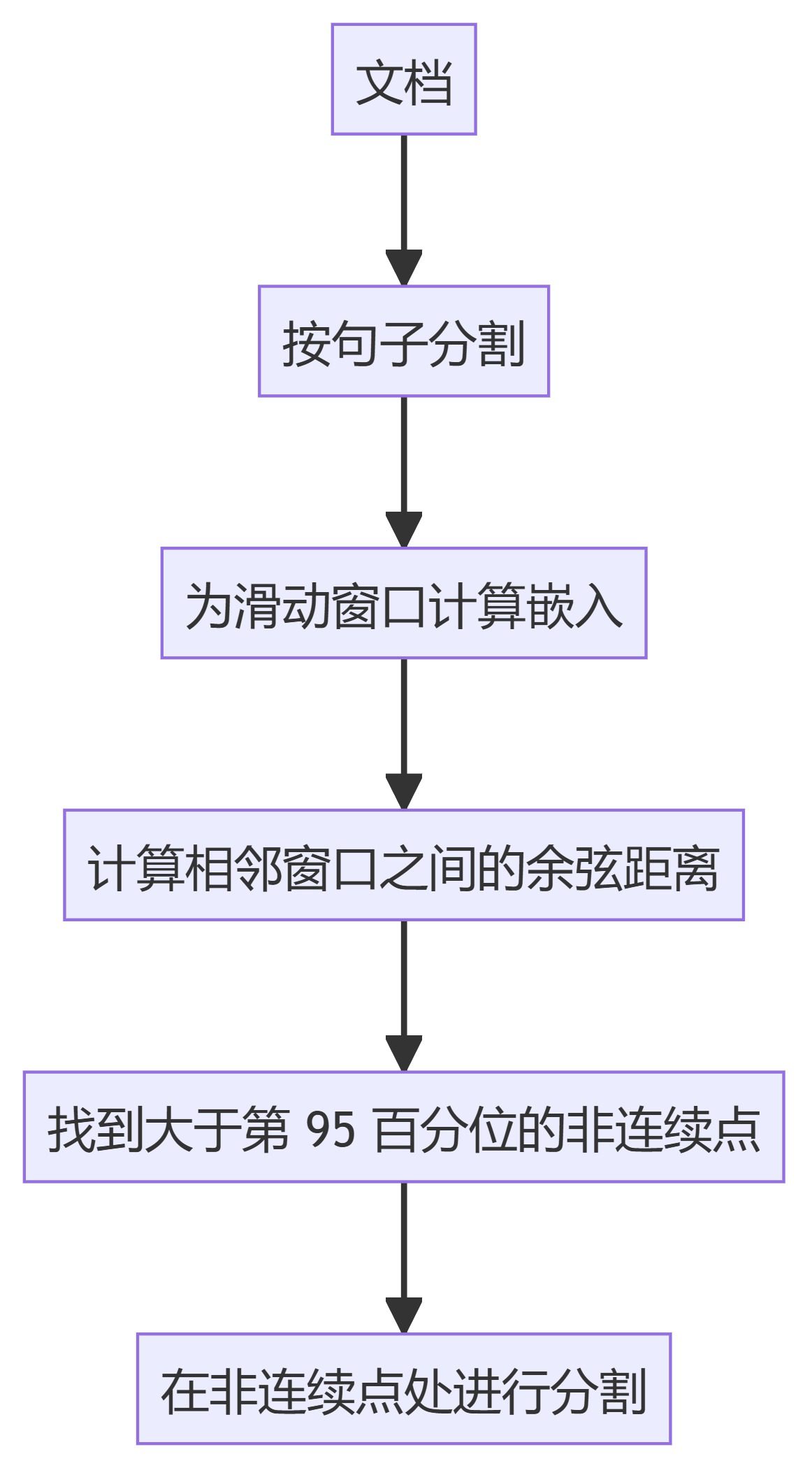
3. KamradtSemanticChunker
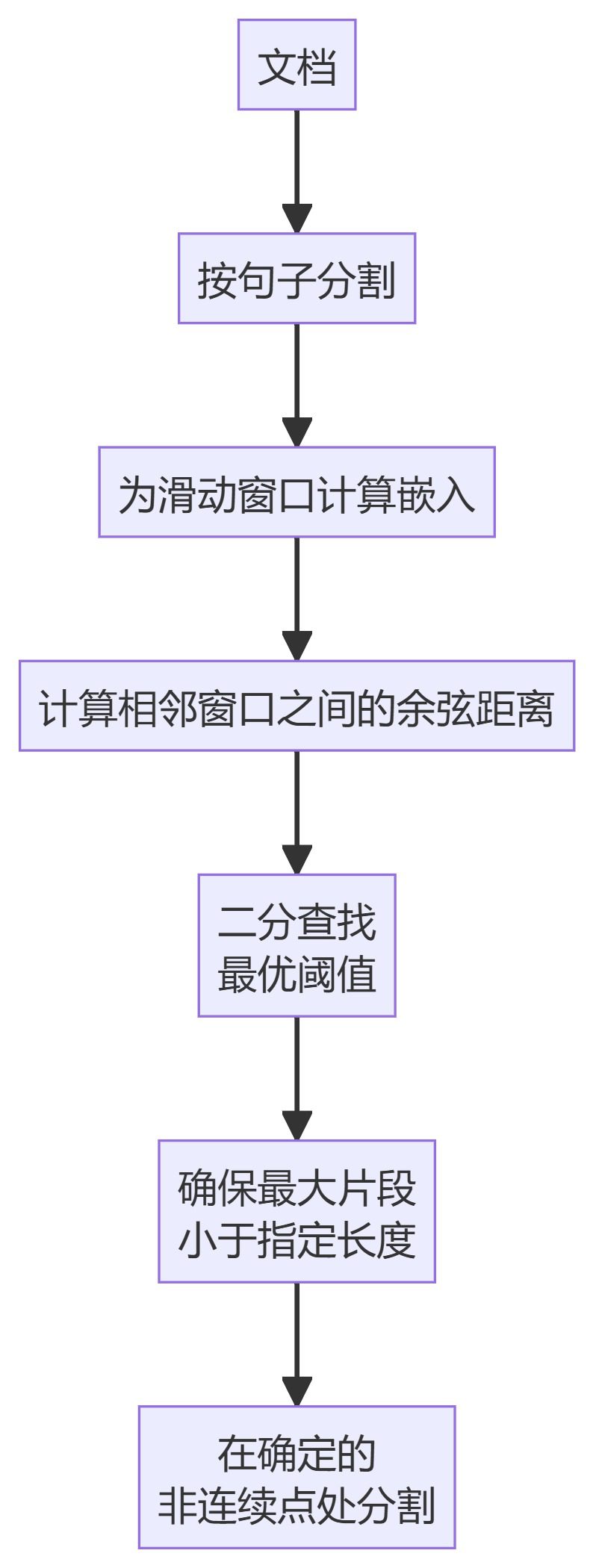
4. KamradtModifiedChunker
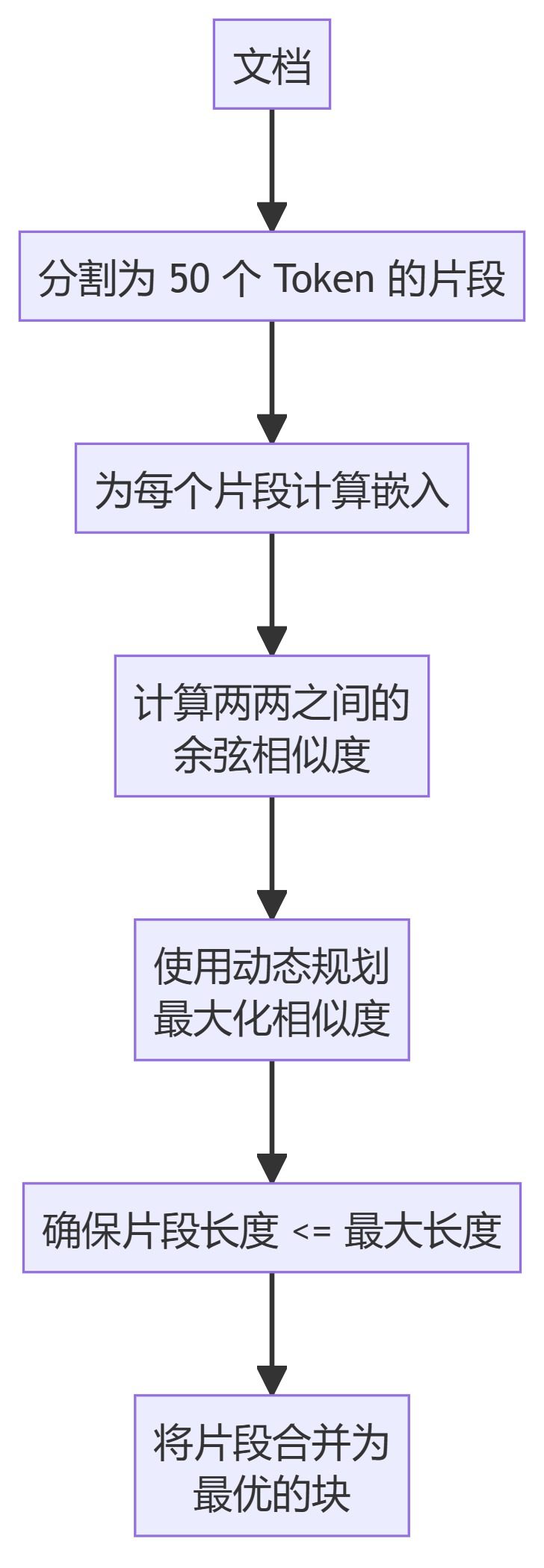
5. ClusterSemanticChunker
6. LLMSemanticChunker
Method Description
- RecursiveCharacterTextSplitter: Split text based on a hierarchy of delimiters, prioritizing natural breakpoints in the document.
- TokenTextSplitter: Splits text into blocks of a fixed number of tokens, ensuring that splitting occurs at token boundaries.
- KamradtSemanticChunker: Use sliding window embeddings to recognize semantic discontinuities and segment text accordingly.
- KamradtModifiedChunker: An improved version of KamradtSemanticChunker that uses bisection search to find the optimal threshold for segmentation.
- ClusterSemanticChunker: Split the text into small chunks, compute the embeddings, and use dynamic programming to create optimal chunks based on semantic similarity.
- LLMSemanticChunker: Determine appropriate segmentation points in text using language models.
Usage
To use these chunking methods in your RAG process:
- surname Cong
chunkersmodule to import the required chunkers. - Initialize the chunker with appropriate parameters (e.g., maximum chunk size, overlap).
- Pass your document to the chunker for chunking results.
Example:
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
How to choose a chunking method
The choice of chunking method depends on your specific use case:
- For simple text splitting, you can use RecursiveCharacterTextSplitter or TokenTextSplitter.
- If semantic-aware segmentation is required, consider KamradtSemanticChunker or KamradtModifiedChunker.
- For more advanced semantic chunking, use ClusterSemanticChunker or LLMSemanticChunker.
Factors to consider when selecting a method:
- Document structure and content types
- Required chunk size and overlap
- Available computing resources
- Specific requirements of the retrieval system (e.g., vector-based or keyword-based)
It is possible to try different methods and find the one that best suits your documentation and retrieval needs.
Integration with RAG systems
After completing the chunking, the following steps are usually performed:
- Generate embeddings for each chunk (for vector-based retrieval systems).
- Index these chunks in the selected retrieval system (e.g., vector database, inverted index).
- When answering a query, use the index chunks in the retrieval step.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...