
AI Engineering Academy: 2.3BM25 RAG (Retrieval Augmentation Generation)

summary
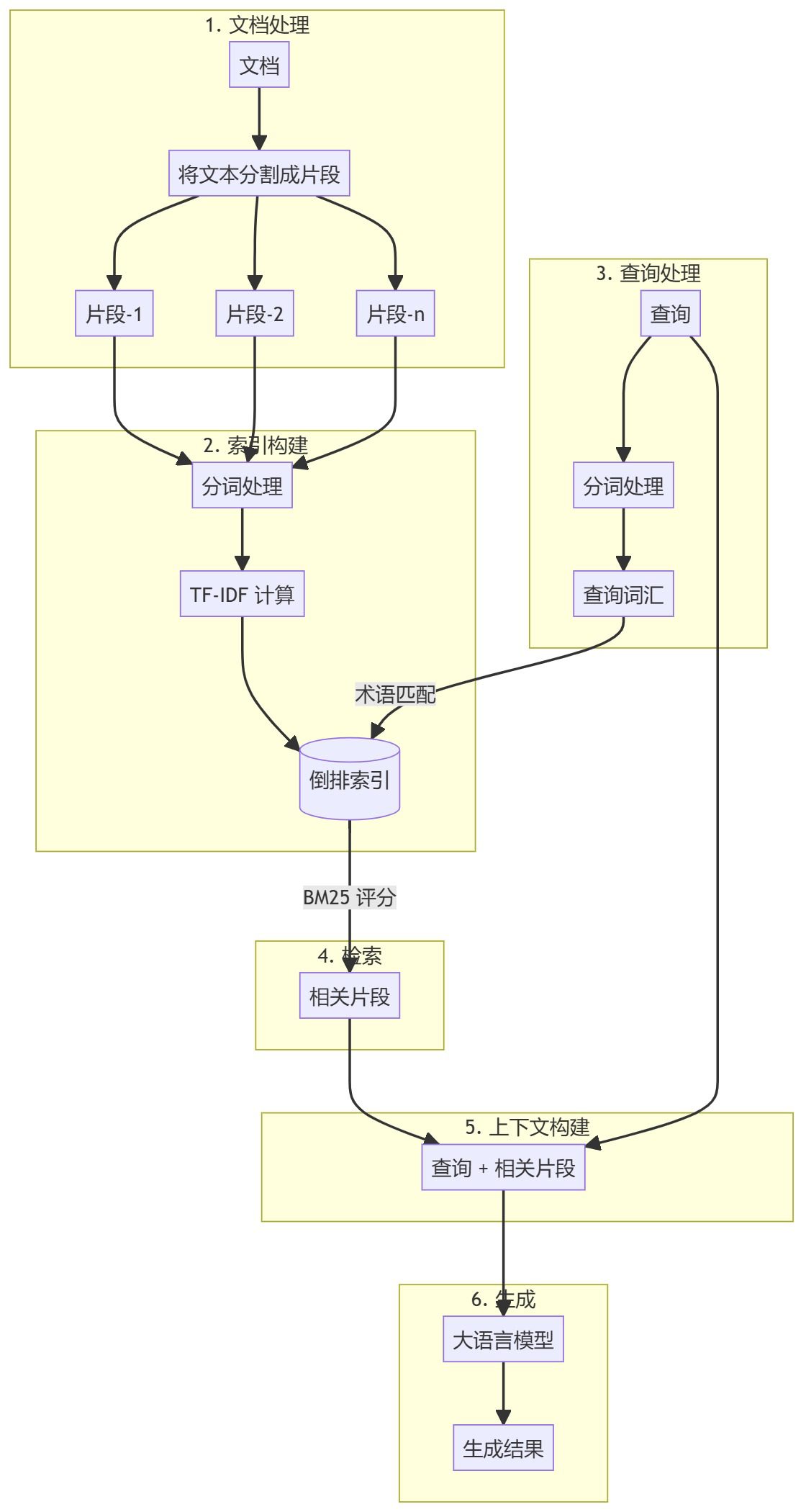
BM25 Retrieval Enhanced Generation (BM25 RAG) is an advanced technique that combines the BM25 (Best Matching 25) algorithm for information retrieval with a large language model for text generation. By using a validated probabilistic retrieval model, this method improves the accuracy and relevance of the generated responses.
BM25 RAG Workflow
Quick Start
Notebook
You can run the Jupyter notebook provided in this code base to explore the BM25 RAG in detail. https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_BM25_RAG
chat application
- Install dependencies:
pip install -r requirements.txt - Run the application:
python app.py - Dynamic ingestion of data:
python app.py --ingest --data_dir /path/to/documents
server (computer)
Run the server:
python server.py
The server contains two endpoints:
/api/ingest: for ingesting new documents/api/query: For queries BM25 RAG systems
Key features of the BM25 RAG
- probabilistic search: BM25 uses a probabilistic model to rank documents, providing a theoretically sound basis for retrieval.
- word frequency saturation:: BM25 takes into account the diminishing marginal returns of duplicate terms and improves retrieval quality.
- Document length normalization: The algorithm considers the document length and reduces the bias towards longer documents.
- contextual relevance: By generating a response based on the retrieved information, the BM25 RAG provides a more accurate and relevant answer.
- scalability: The BM25 search step efficiently handles large document sets.
Advantages of the BM25 RAG
- Improved accuracy: Combining the advantages of probabilistic retrieval and neural text generation.
- interpretability: The scoring mechanism of BM25 is more interpretable than the dense vector retrieval method.
- Handling long-tail queries: excels in queries that require specific or rare information.
- No embedding required: Unlike vector-based RAGs, BM25 does not require document embedding, reducing computational overhead.
pre-conditions
- Python 3.7+
- Jupyter Notebook or JupyterLab (for running the notebook)
- Required Python packages (see
requirements.txt) - API key for the selected language model (e.g. OpenAI API key)
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...