Top 5 AI Inference Platforms That Use Full-Blooded DeepSeek-R1 for Free

Due to excessive traffic and a cyber attack, the DeepSeek website and app have been up and down for a few days, and the API is not working.

We have previously shared the method for deploying DeepSeek-R1 locally (seeDeepSeek-R1 Local Deployment), but the average user is limited to a hardware configuration that makes it difficult to run even a 70b model, let alone a full 671b model.
Luckily, all major platforms have access to DeepSeek-R1, so you can try it as a flat replacement.
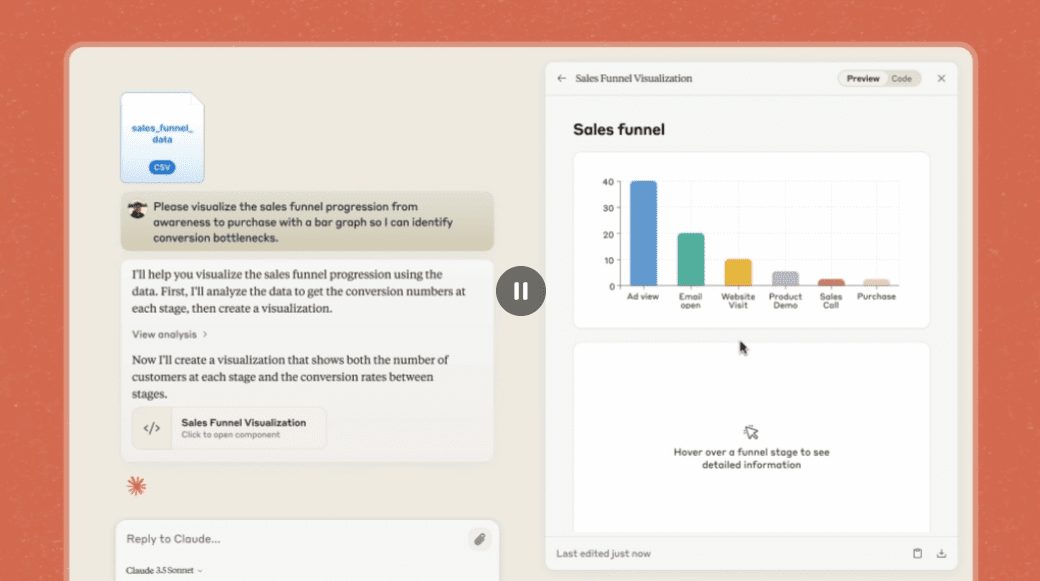
I. NVIDIA NIM Microservices
NVIDIA Build: Integration of multiple AI models and free experience
Website: https://build.nvidia.com/deepseek-ai/deepseek-r1
NVIDIA deployed the full volume parameter 671B of the DeepSeek-R1 Models, the web version is straightforward to use, and you can see the chat window when you click on it:
Also listed on the right is the code page:
Simply test it:

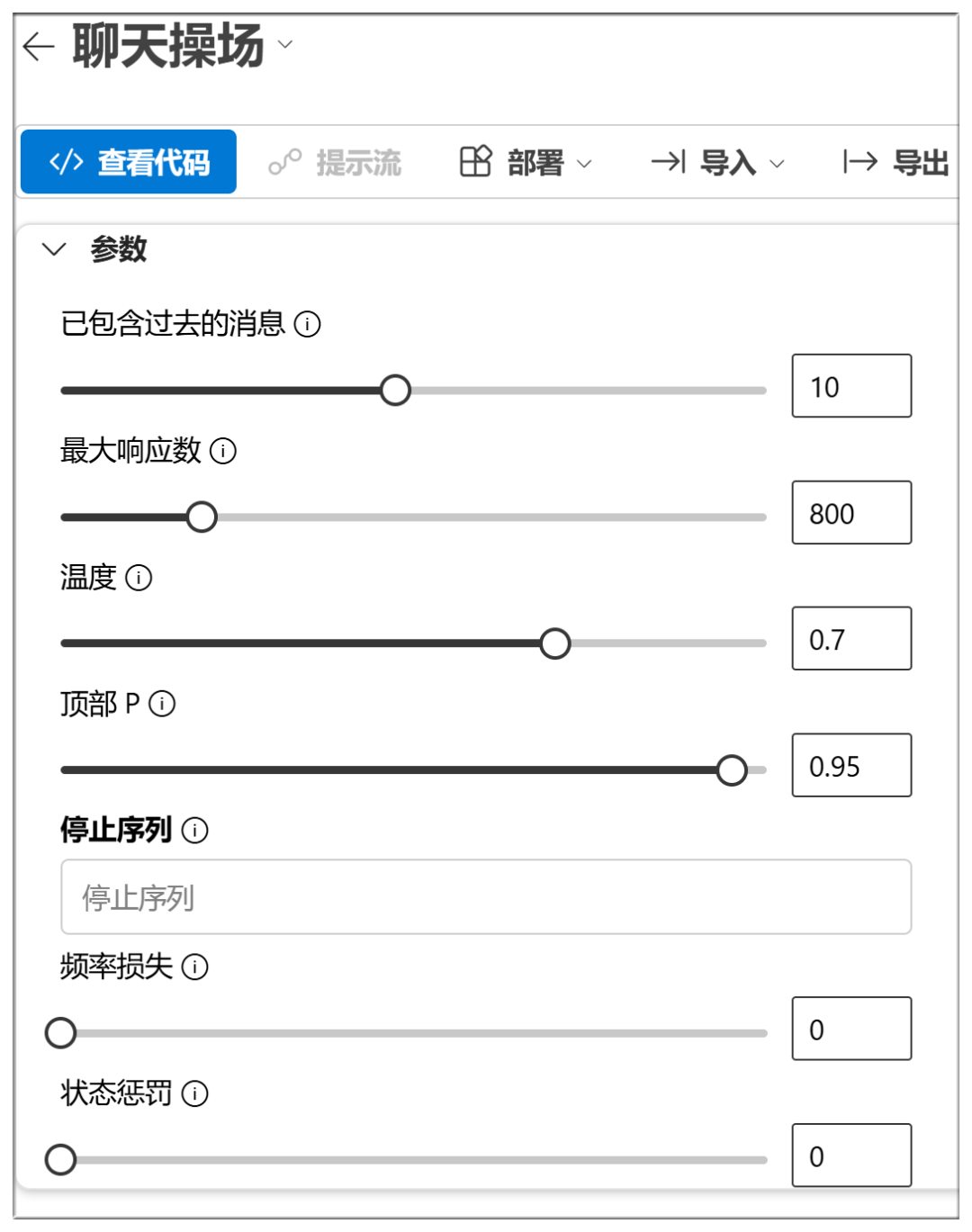
Below the chat box, you can also turn on some parameter items (which can be defaulted in most cases):
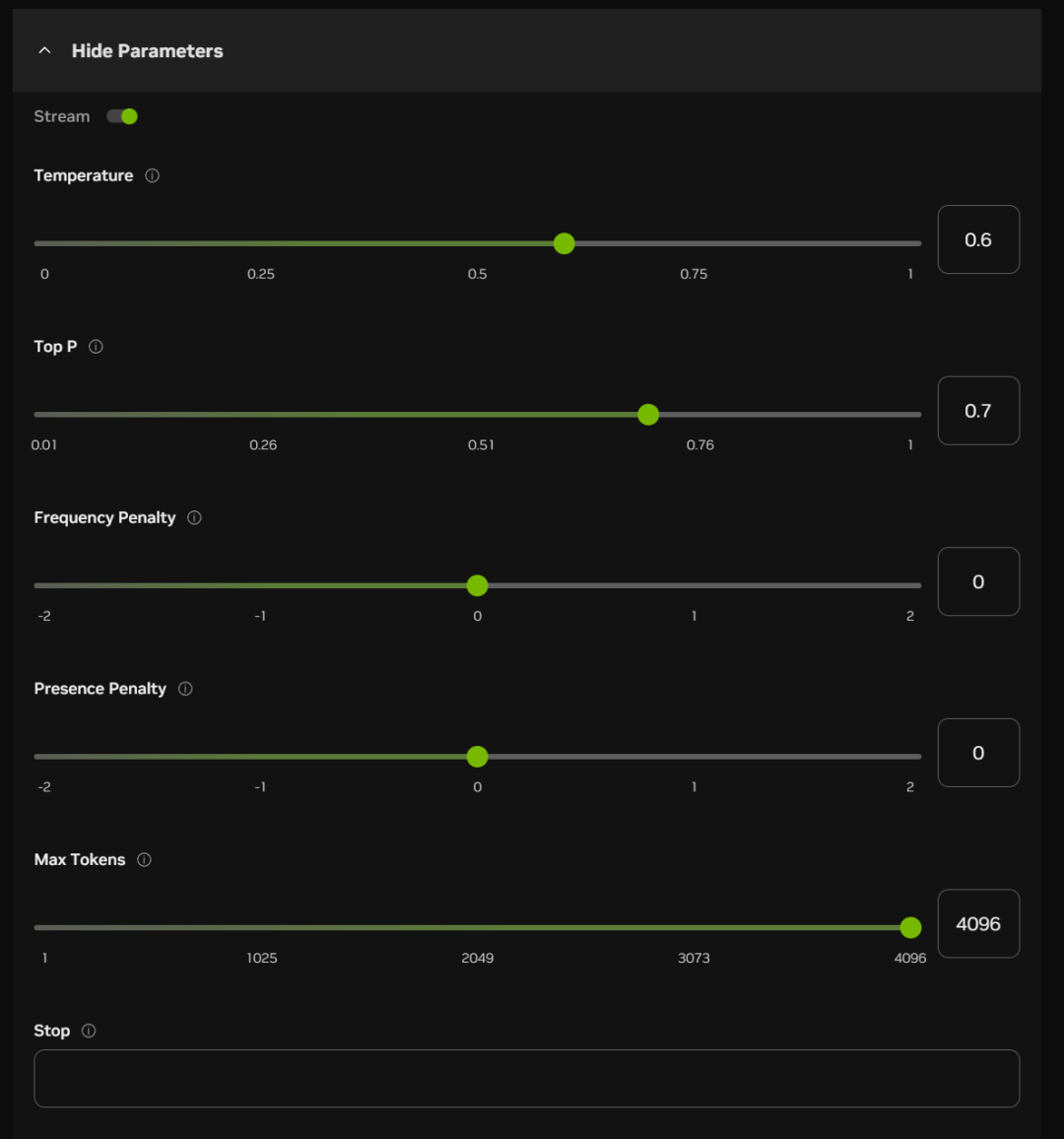
The approximate meaning and function of these options are listed below:
Temperature:
The higher the value, the more randomized the output is, potentially generating more creative responses
Top P (nuclear sampling):
Higher values retain more probabilistic quality tokens and generate more diversity
Frequency Penalty:
Higher values penalize high-frequency words more and reduce verbosity or repetition
Presence Penalty:
The higher the value, the more inclined the model is to try new words
Max Tokens (maximum generation length):
The higher the value, the longer the potential length of the response
Stop:
Stop output when generating certain characters or sequences, to prevent generating too long or running out of topics.
Currently, due to the increasing number of white johns (look at the number of people in the queue in the chart below), NIM is lagging some of the time:
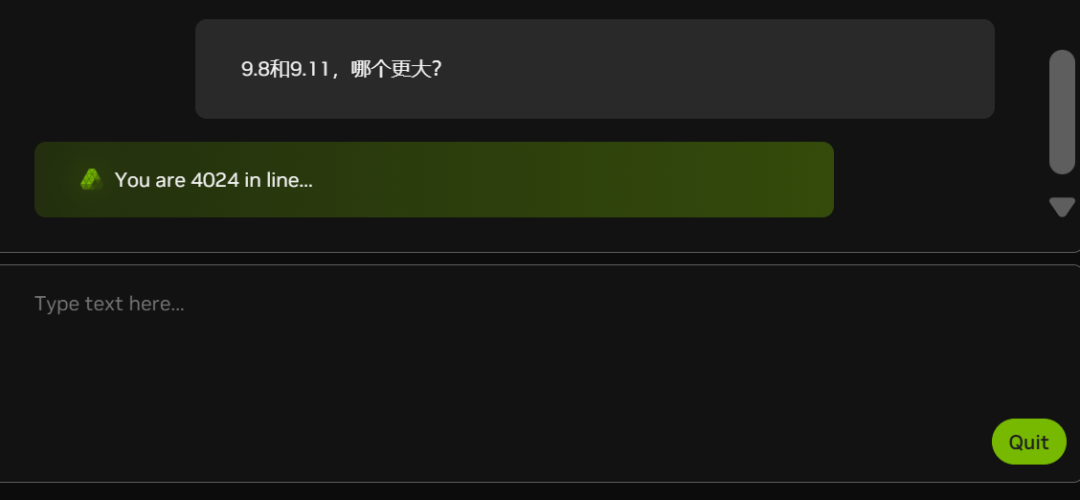
Is NVIDIA also short of graphics cards?
NIM microservices also support API calls to DeepSeek-R1, but you need to sign up for an account with an email address:
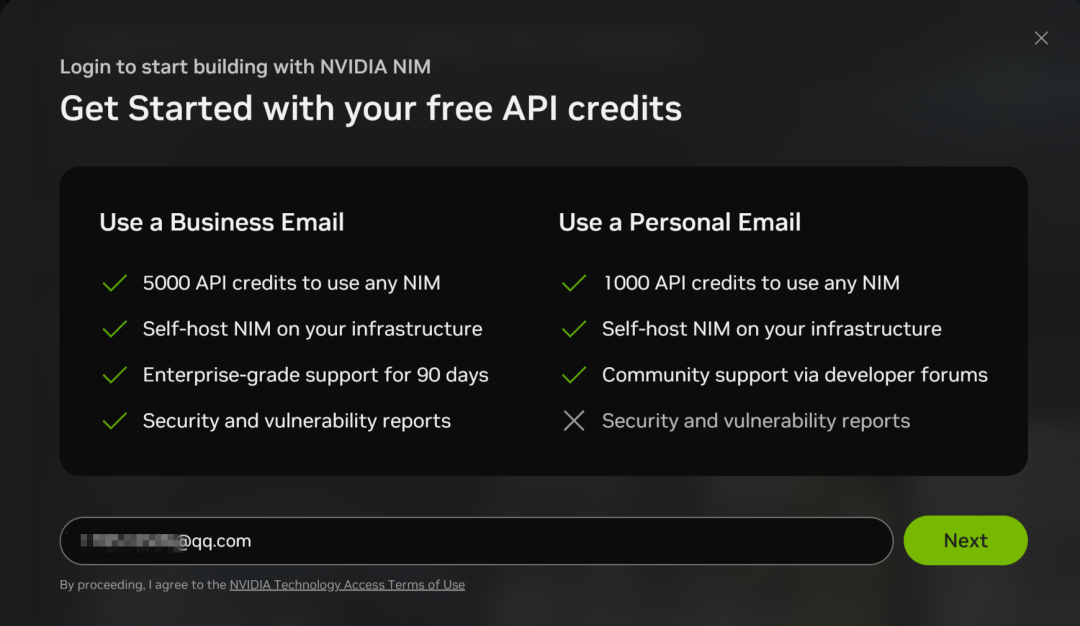
The registration process is relatively simple, using only email verification:

After registering, you can click on "Build with this NIM" at the top right of the chat interface to generate an API KEY. Currently, you will get 1000 points (1000 interactions) for registering, so you can use it all up and register again with a new email address.
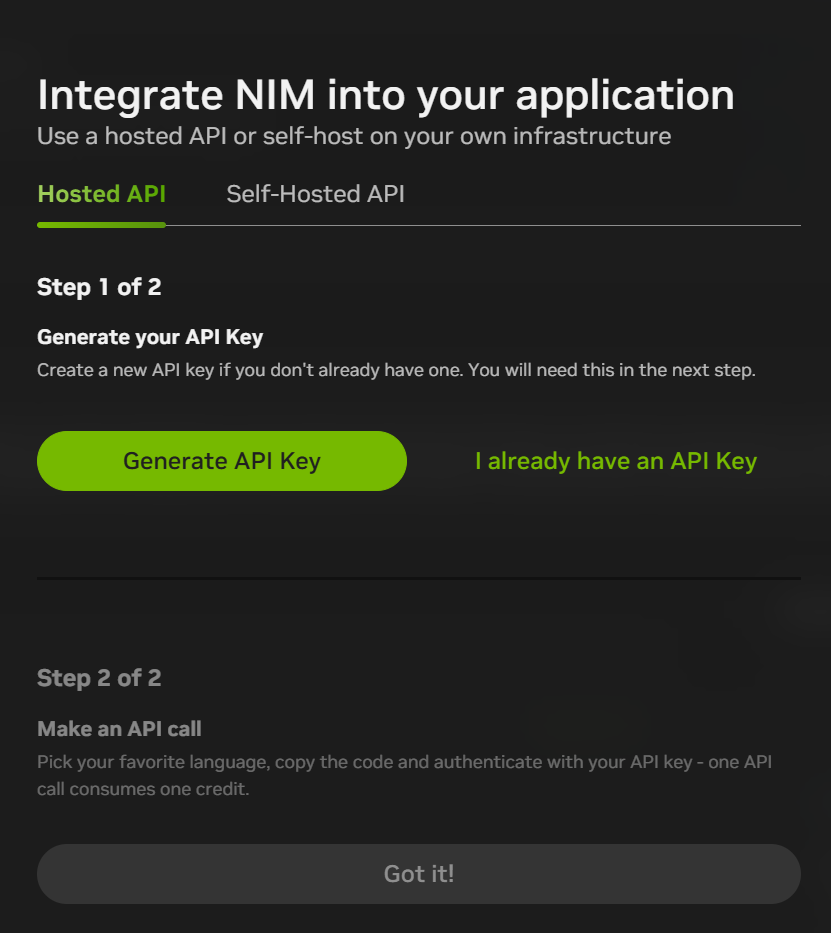
The NIM microservices platform also provides access to many other models:
II. Microsoft Azure
Web site:
https://ai.azure.com
Microsoft Azure allows you to create a chatbot and interact with the model through a chat playground.
Azure is a lot of trouble to sign up for, first you have to create a Microsoft account (just log in if you already have one):
Creating an account also requires email verification:
Finish by proving you're human by answering 10 consecutive netherworld questions:

Getting here isn't enough to create a subscription:
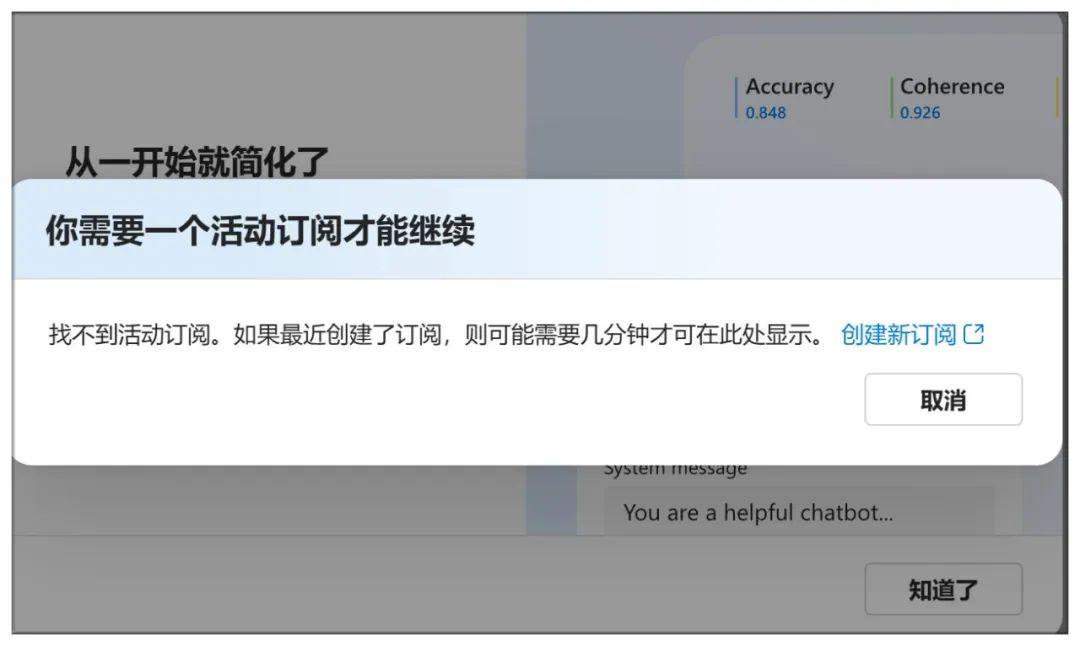
Verify information such as cell phone number as well as bank account number:
Next, select "No technical support":

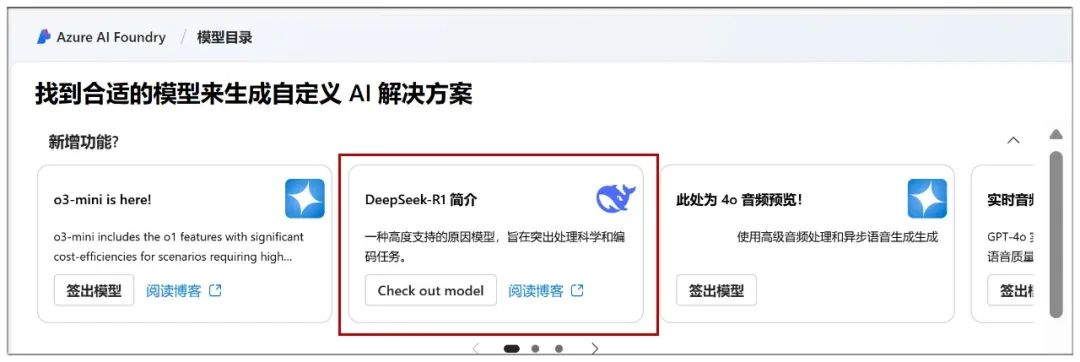
Here you can start the cloud deployment, in the "Model Catalog" you can see the prominent DeepSeek-R1 model:
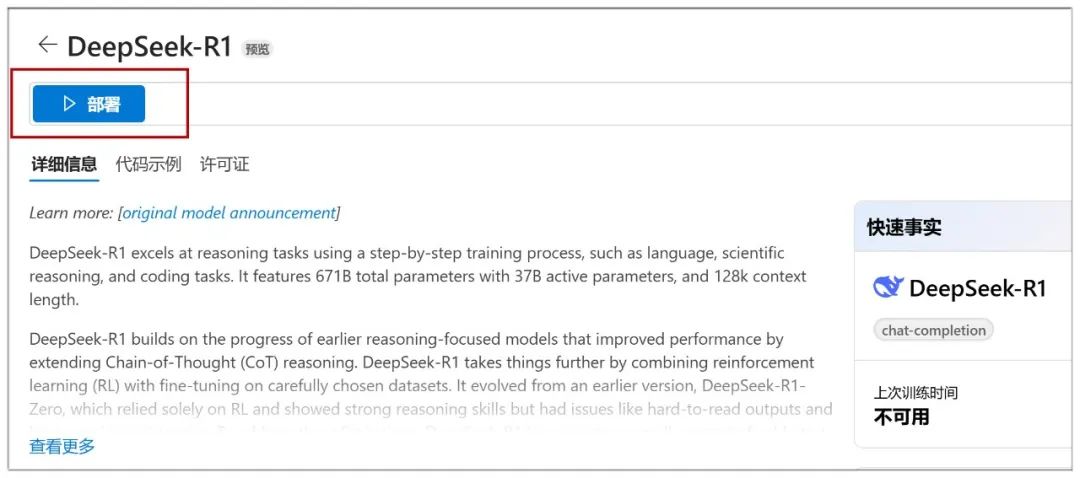
After clicking on it, click on "Deploy" on the next page:
Next, you need to select "Create New Project":
Then default them all and click "Next":
Next, click "Create":
Creating it under this page starts, and it takes a while to wait:
When you're done, you'll come to this page where you can click "Deploy" to go to the next step:
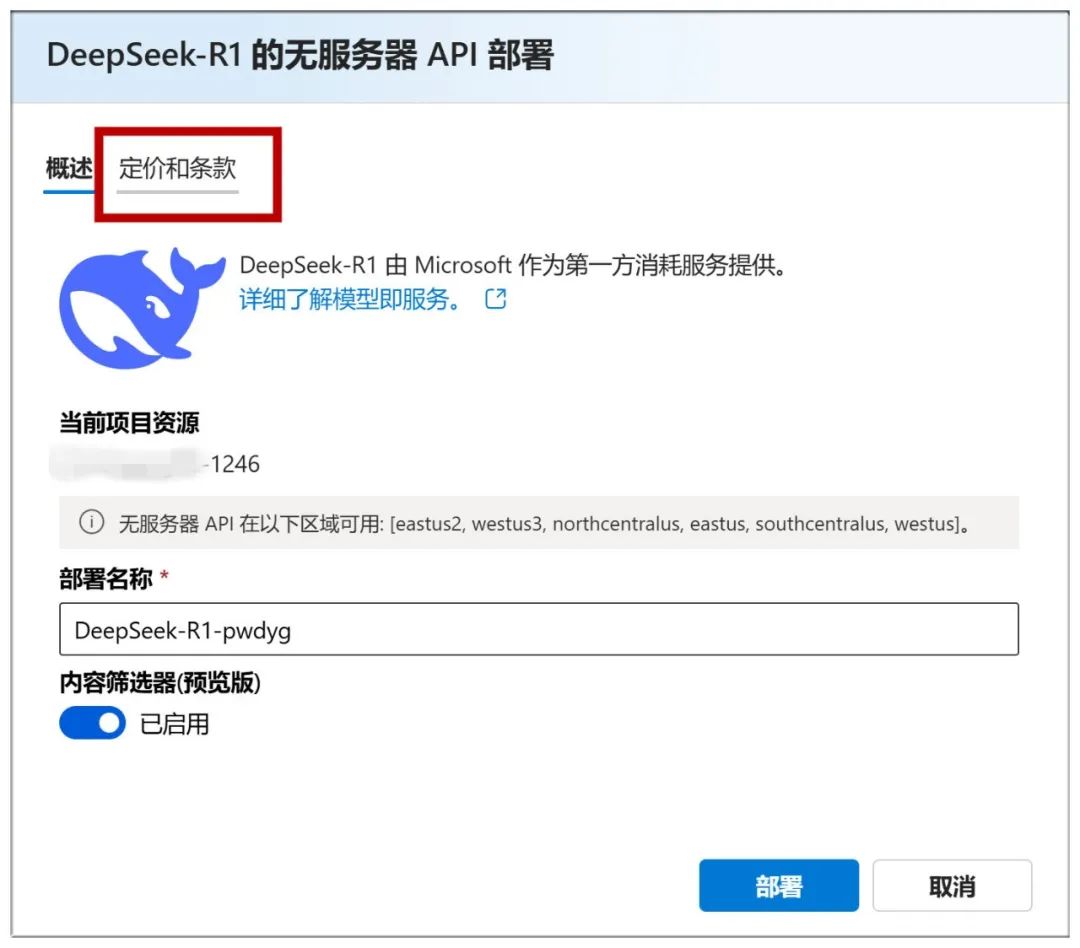
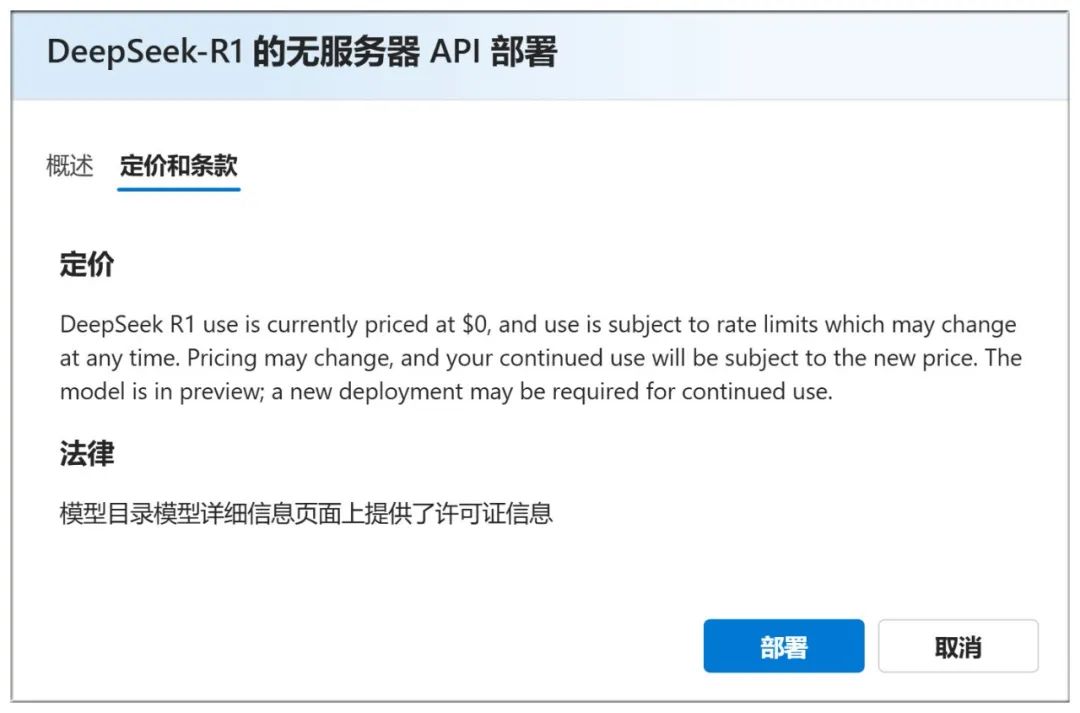
You can also check the "Pricing and Terms" above to see that it is free to use:
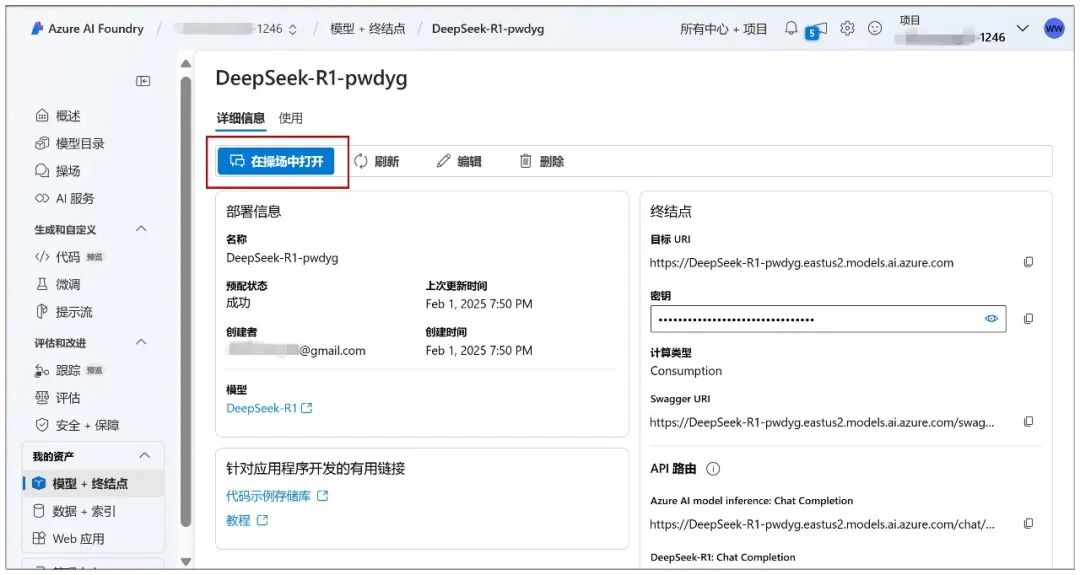
Continue to this page by clicking on "Deployment" and you can click on "Open in Playground":
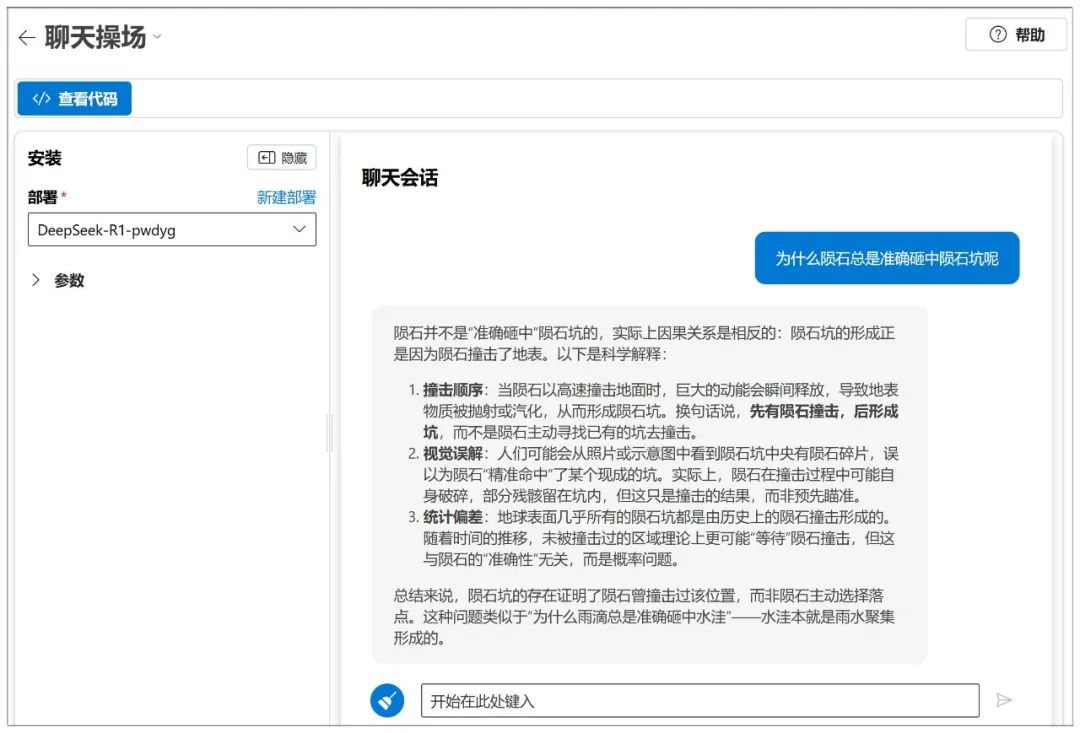
Then the conversation can begin:
Azure also has NIM-like parameter tuning available:
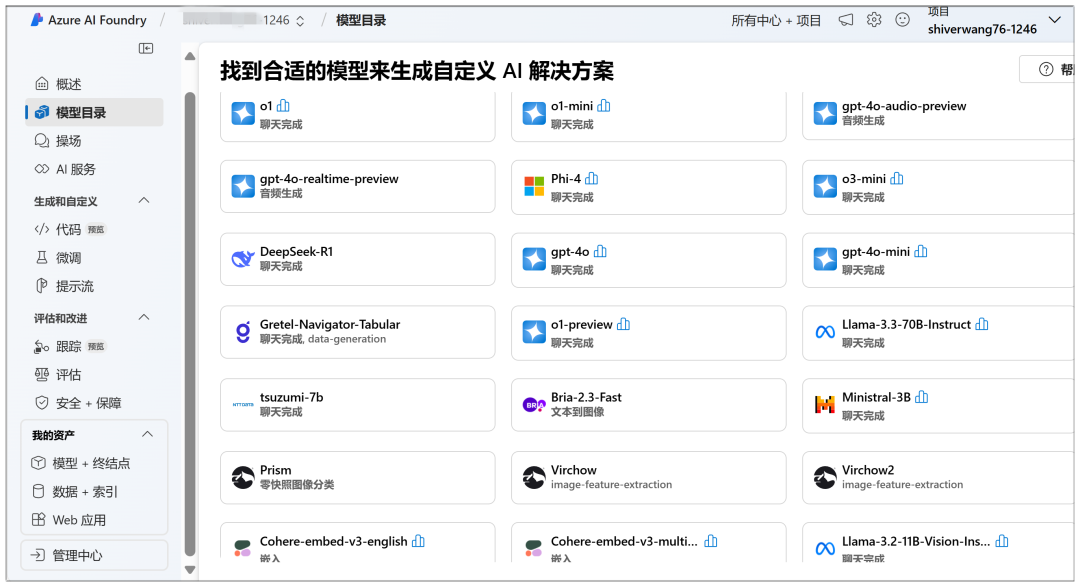
As a platform, there are many models that can be deployed:
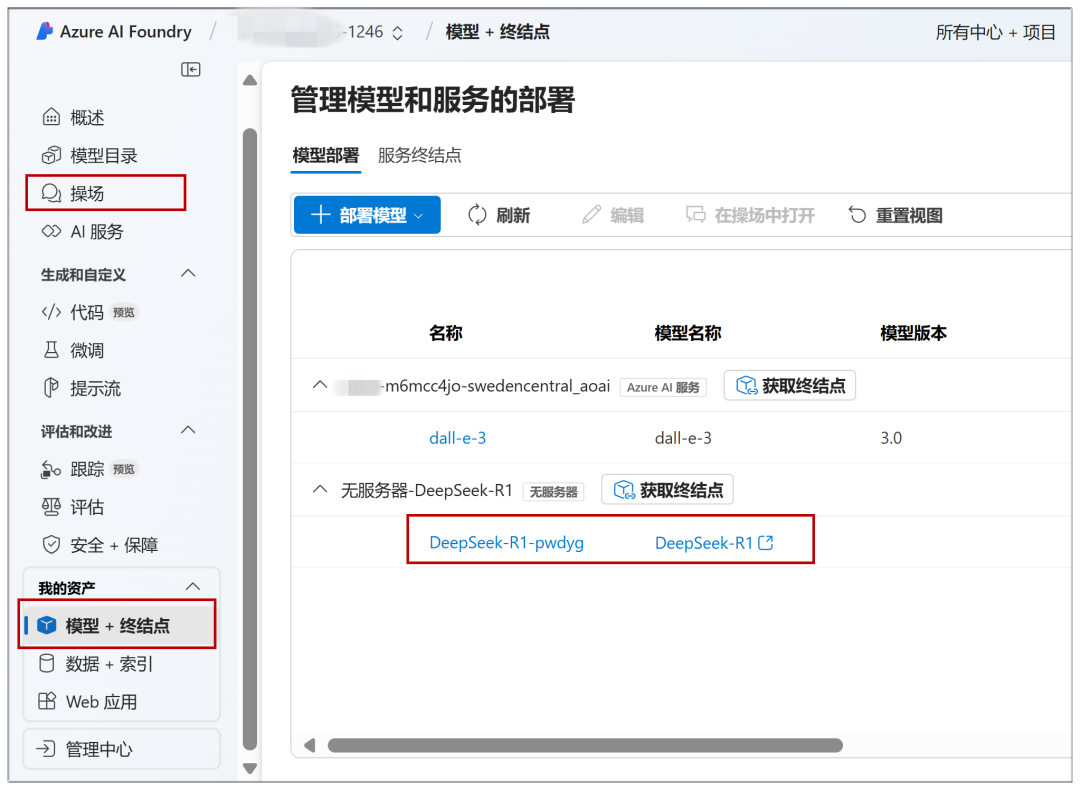
Already deployed models can be quickly accessed in the future via "Playground" or "Model + Endpoint" in the left menu:
III. Amazon AWS
Web site:
https://aws.amazon.com/cn/blogs/aws/deepseek-r1-models-now-available-on-aws
DeepSeek-R1 is also prominently displayed and lined up.

Amazon AWS registration process and Microsoft Azure is almost as troublesome, both have to fill in the payment method, but also phone verification + voice verification, here will not describe in detail:
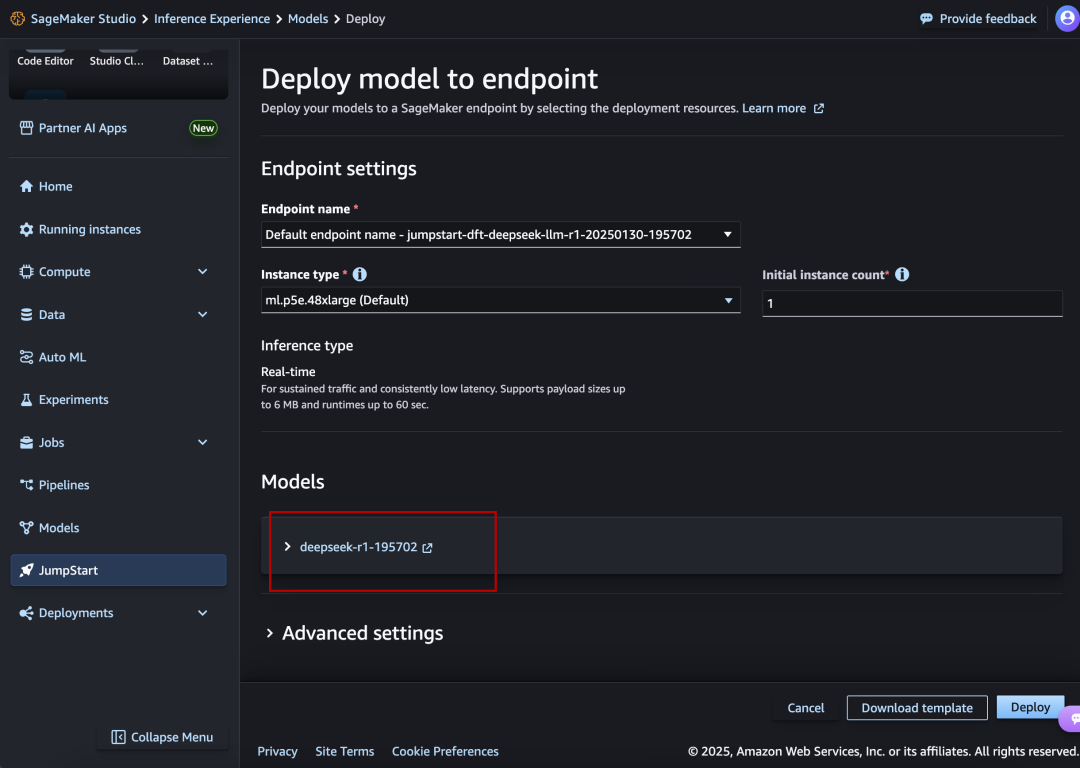
The exact deployment process is much the same as Microsoft Azure:
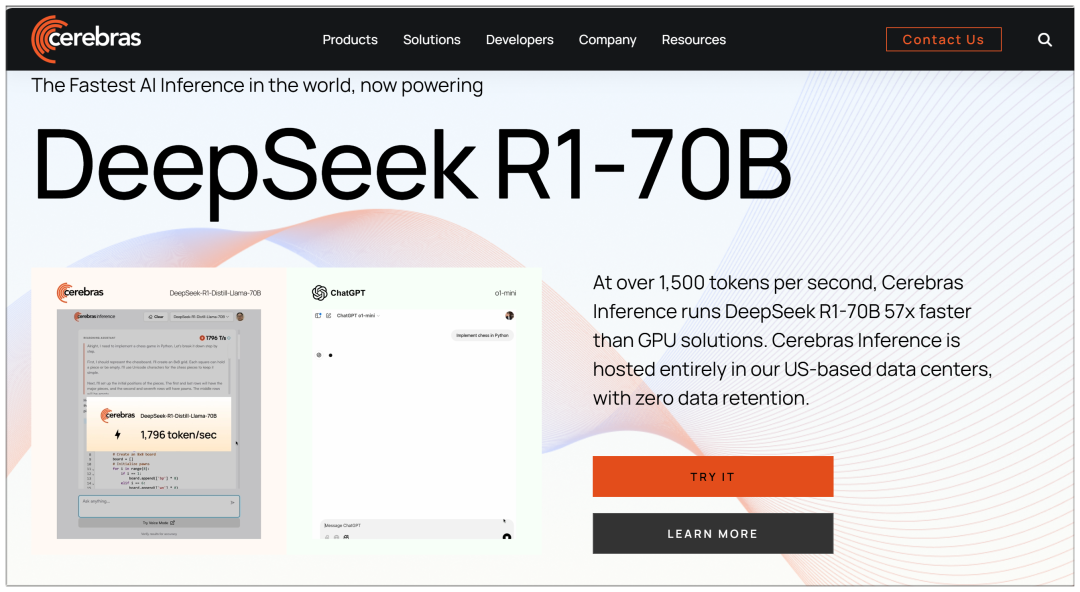
IV. Cerebras
Cerebras: the world's fastest AI inference, high-performance computing platform available today
Website: https://cerebras.ai
Unlike several large platforms, Cerebras uses a 70b model, claiming to be "57 times faster than GPU solutions."
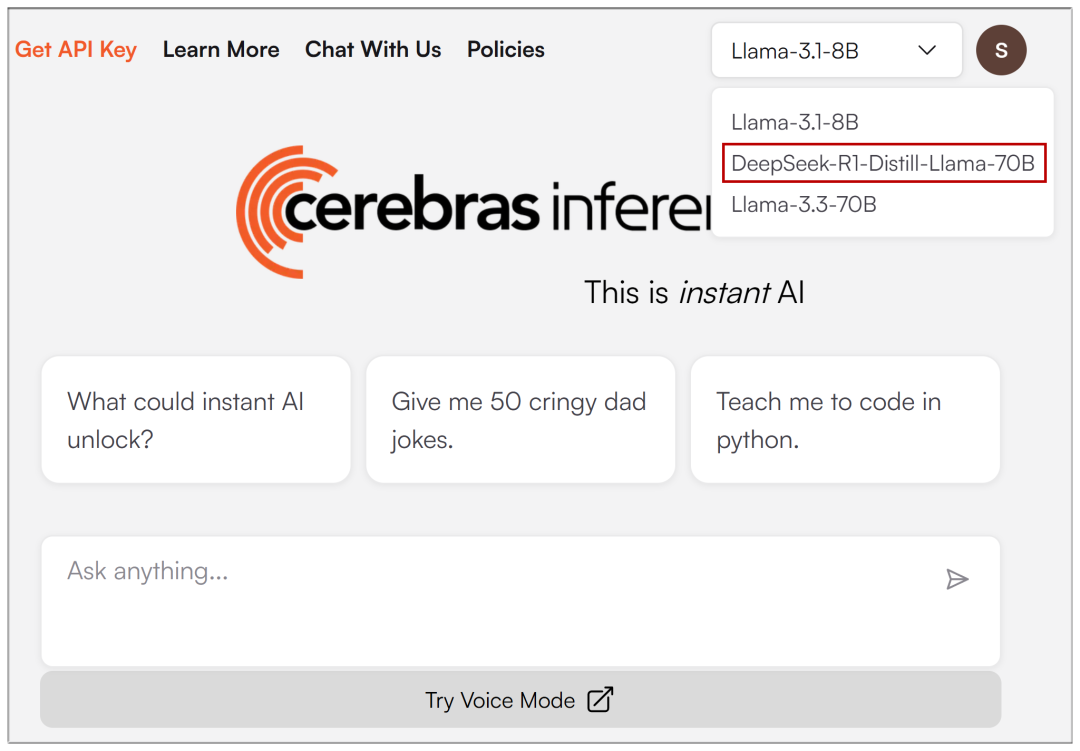
Once the email registration is entered, the drop-down menu at the top allows you to select DeepSeek-R1:
The real-world speeds are indeed faster, though not as exaggerated as claimed:
V. Groq
Groq: AI big model inference acceleration solution provider, high-speed free big model interface
Website: https://groq.com/groqcloud-makes-deepseek-r1-distill-llama-70b-available

The model is also optional after the email registration is entered:

It's also fast, but again, 70b feels a little more retarded than the Cerebras?
Note that the chat interface can be accessed directly while logged in:
https://console.groq.com/playground?model=deepseek-r1-distill-llama-70b
Complete list of DeepSeek V3 and R1:
AMD
AMD Instinct™ GPUs Power DeepSeek-V3: Revolutionizing AI Development with SGLang (AMD Instinct™ GPUs Power DeepSeek-V3: Revolutionizing AI Development with SGLang)
NVIDIA
DeepSeek-R1 NVIDIA model card (DeepSeek-R1 NVIDIA model card)
Microsoft Azure
Running DeepSeek-R1 on a single NDv5 MI300X VM (Running DeepSeek-R1 on a single NDv5 MI300X VM)
Baseten
https://www.baseten.co/library/deepseek-v3/
Novita AI
Novita AI uses SGLang running DeepSeek-V3 for OpenRouter (Novita AI using SGLang to run DeepSeek-V3 for OpenRouter)
ByteDance Volcengine
The full-size DeepSeek model lands on the Volcano Engine!
DataCrunch
Deploy DeepSeek-R1 671B on 8x NVIDIA H200 with SGLang (Deployment of DeepSeek-R1 671B on 8x NVIDIA H200 using SGLang)
Hyperbolic
https://x.com/zjasper666/status/1872657228676895185
Vultr
How to Deploy Deepseek V3 Large Language Model (LLM) Using SGLang (How to deploy with SGLang) Deepseek V3 Large Language Model (LLM))
RunPod
What's New for Serverless LLM Usage in RunPod in 2025? (What are the new features used by Serverless LLM in RunPod 2025?)
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles




No comments...