Before the formal discussion, it is necessary to clarify the concept of AI crawler (also known as LLM crawler), which can be roughly divided into two categories: roughly can be divided into two categories, one is the conventional crawler tool, except that its results are directly used in the context of the LLM, which strictly speaking has nothing to do with the AI; the other is a new type of crawling program driven by the LLM, where the user specifies the data collection through natural language. The other is a new type of crawler solution driven by LLM, in which the user specifies the target for data collection through natural language, and then LLM analyzes the structure of the web page, develops a crawling strategy, performs interactions to obtain dynamic data, and ultimately returns structured target content.
LLM-driven crawler program
On the general AI-driven web crawler ideas and practice methods, you can read this article in detail, the author from the idea to the solution, and then to the tuning and analysis of the results, very detailed, full of dry goods, I strive to briefly introduce this process to you quickly. The entire process exhaustive simulation of human steps:
- First crawl the entire HTML code of the web page.
- AI is then utilized to generate a series of related terms, for example, when looking for prices, AI will generate related keywords (prices, fee,, cost, etc.).
- Search the HTML structure based on these keywords to locate a list of relevant nodes.
- Use AI to analyze the list of nodes and determine the most relevant ones.
- The application AI determines whether an interaction with the node is required (usually a click action).
- Repeat the above steps until the final result is obtained.
Skyvern
Skyvern is a browser automation tool based on a multimodal model designed to increase the efficiency and adaptability of workflow automation. Unlike traditional automation approaches, which often rely on site-specific scripts, DOM parsing, and XPath paths that tend to fail when site layouts change, Skyvern generates interaction plans by analyzing visual elements in the browser window in real-time, in conjunction with the LLM, allowing it to run on unknown sites without custom code and be much more resilient to site layout changes. Browser-based workflows are automated by incorporating browser automation libraries such as Playwright, consisting of the following key agents:
- Interactable Element Agent: responsible for parsing the HTML structure of a web page and extracting interactive elements.
- Navigation Agent: Responsible for planning the navigation path required to complete a task, such as clicking buttons, entering text, etc.
- Data Extraction Agent: Responsible for extracting data from web pages, able to read tables and text, and output data into a user-defined structured format.
- Password Agent: Responsible for populating a website's password form, capable of reading usernames and passwords from a password manager and filling out the form while protecting the user's privacy.
- 2FA Agent: Responsible for populating the 2FA form, it can intercept 2FA requests from websites and either get the 2FA code through a user-defined API or wait for the user to manually enter it.
- Dynamic Auto-complete Agent: Responsible for filling out dynamic auto-complete forms, capable of selecting appropriate options and adjusting input based on user input and form feedback.

ScrapegraphAI
ScrapeGraphAI automates the construction of crawling pipelines through big talk models and graph logic, reducing the need for manual coding. A layman simply specifies the required information and ScrapeGraphAI automatically handles single or multi-page crawling tasks to efficiently crawl web pages. It supports a wide range of document formats such as XML, HTML, JSON, and Markdown, and ScrapeGraphAI offers several types of crawling, including:
- SmartScraperGraph: Single-page crawling can be achieved with just a user prompt and input source.
- SearchGraph: A multi-page crawler that extracts information from the top search results.
- SpeechGraph: A one-page grabber that converts website content into audio files.
- ScriptCreatorGraph: Creates a single page grabber of Python scripts for the extracted data.
- SmartScraperMultiGraph: Multi-page crawling through a single prompt and a range of sources.
- ScriptCreatorMultiGraph: A multi-page crawler that extracts information from multiple pages and sources, and creates the corresponding Python scripts.
ScrapeGraphAI simplifies the process of web page scraping by allowing ordinary people to automate scraping tasks without in-depth programming knowledge, simply by providing information requirements, supporting scraping from a single page to multiple pages for data extraction tasks of varying sizes, and providing a pipeline of different uses for different scraping needs, including information extraction, audio generation, and script creation.
Conventional crawler tools
Such tools do this by cleansing and converting regular online web content into Markdown format for better understanding and processing by the Big Model (the Big Model's responses are of higher quality when the data is in a structured and Markdown format), and the converted content serves as the context for the LLMs to enable the models to answer questions in conjunction with online resources.
Crawl4AI
Crawl4AI is an open source web crawler and data extraction framework designed specifically for AI applications, allowing multiple URLs to be crawled at the same time, dramatically reducing the time required for large-scale data collection.Key features of Crawl4AI that make it a great performer in the web crawler space include:
- Multiple output formats: Supports multiple output formats such as JSON, Minimal HTML and Markdown.
- Dynamic Content Support: Through custom JavaScript code, Crawl4AI can simulate user behavior such as clicking the "Next" button to load more dynamic content. This approach allows Crawl4AI to handle common dynamic content loading mechanisms such as paging and infinite scrolling.
- Multiple chunking strategies: Supports a variety of chunking strategies such as topics, regular expressions, and sentences, enabling users to customize data to their specific needs.
- media extraction: Employing powerful methods such as XPath and regular expressions that enable users to pinpoint and extract the data they need, it is capable of extracting a wide range of media types, including images, audio and video, and is particularly useful for applications that rely on multimedia content.
- Custom Hooks: Users can define custom hooks, such as those that are executed at the beginning of a crawler's execution.
on_execution_startedhook. This can be used to ensure that all necessary JavaScript has been executed and dynamic content has been loaded onto the page before crawling begins. - good stabilityCrawling dynamic content can fail due to network issues or JavaScript execution errors, and Crawl4AI's error handling and retry mechanism ensures that even when these issues are encountered, a retry is possible to ensure the integrity and accuracy of the data.
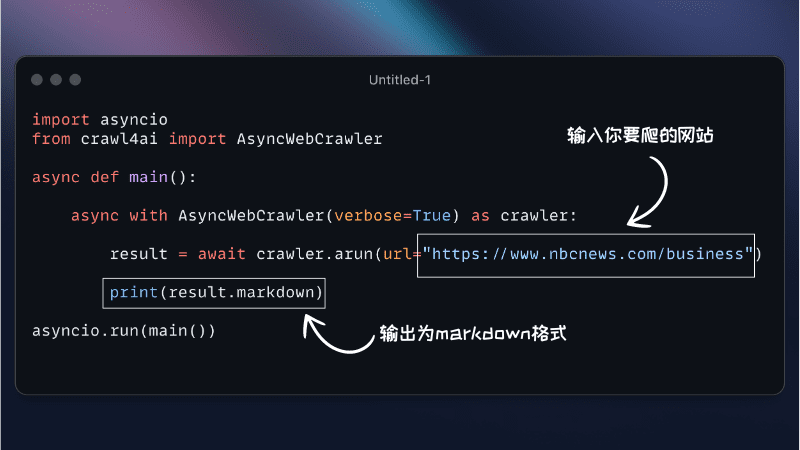
Reader
Web Content Crawling Tool Developed by Jina AI Reader API In addition, users can clean up and format page content by simply typing in the URL and outputting it in plain text or Markdown format. The goal is to convert any web page into an input format suitable for understanding by large models, i.e., to convert rich text content to plain text, e.g., to convert an image to descriptive text.

Firecrawl
Firecrawl is designed to be more elegant and powerful than Reader, and is more of a full-fledged product. It provides a simplified API interface for whole-site crawling and data extraction. firecrawl is able to convert website content into Markdown, formatted data, screenshots, condensed HTML, hyperlinks, and metadata to better support the use of LLM. In addition, Firecrawl has the ability to handle complex tasks such as proxy setup, anti-crawler mechanisms, handling of dynamic content such as JavaScript rendering, output parsing and task coordination. Developers can customize the behavior of the crawler, such as excluding specific tags, crawling pages that require authentication, setting the maximum crawling depth, etc. Firecrawl supports parsing of data from a wide range of media types, including PDF, DOCX documents and images. Its reliability ensures effective access to the required data in a variety of complex environments. Users can interact with web pages by simulating clicking, scrolling, typing, etc. The latest version also supports batch processing of large numbers of URLs.
- Support for multiple programming languages SDK: Python, Node, Go, Rust
- Compatible with several AI development frameworks: [Langchain (Python)](https://python.langchain.com/docs/integrations/document_loaders/firecrawl/ "Langchain (Python " Langchain (Python)")"), [Langchain (JS)](https://js.langchain.com/docs/integrations/document_loaders/web_loaders/firecrawl "Langchain ( JS "Langchain (JS)")"), LlamaIndex, Crew.ai, Composio, PraisonAI, Superinterface, Vectorize
- Low-code AI platform support: Dify, Langflow, Flowise AI, Cargo, Pipedream
- Automation tool support: Zapier, Pabbly Connect
Markdowner
If the first two tools don't pay enough, or are too resource-intensive to deploy on your own, consider Markdowner, a tool that converts website content to Markdown format, which is not as versatile as Firecrawl, but is sufficient for everyday needs. The tool supports automated crawling, LLM filtering, detailed Markdown schema, and text and JSON response formats. markdowner provides an API interface that allows users to access it via GET requests and customize the response type and content via URL parameters. Technically, Markdowner utilizes the Cloudflare Workers and Turndown libraries for web content transformation.
(sth. or sb) else
Similar crawlers include webscraper, code-html-to-markdown (which is particularly good at dealing with code blocks), MarkdownDown, gpt-api, and web.scraper.workers.dev (Always-used tool that supports content filtering and access to paid content with minor modifications), these tools, after self-deployment, can be used as plug-ins for large models to access online content, and belong to the data preprocessing phase as important tools.
put at the end
Conventional crawler tools do not have much to explore, nor the introduction of any new technology, except that LLM spawned a new generation of crawler tools, significantly improving the developer's experience, only an API that can be flexibly customized to crawl the required content, greatly improving the convenience. It is worth noting that the LLM-driven crawler program is actually part of the Claude For example, Microsoft's UFO project (human-operated simulation of Windows computers), Smart Spectrum's AutoGLM, and Tencent's AppAgent (human-operated simulation of cell phones) are examples of research directions that may cover browser-operated functionality. Therefore, LLM-driven crawler tools may only be a temporary solution for now, and will be replaced by such more comprehensive projects in the future.

![Agent AI: Exploring the Frontier World of Multimodal Interaction [Fei-Fei Li - Classic Must Read] - Chief AI Sharing Circle](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)