

2023 Old article review: a guide to the RAG system build process and evaluation

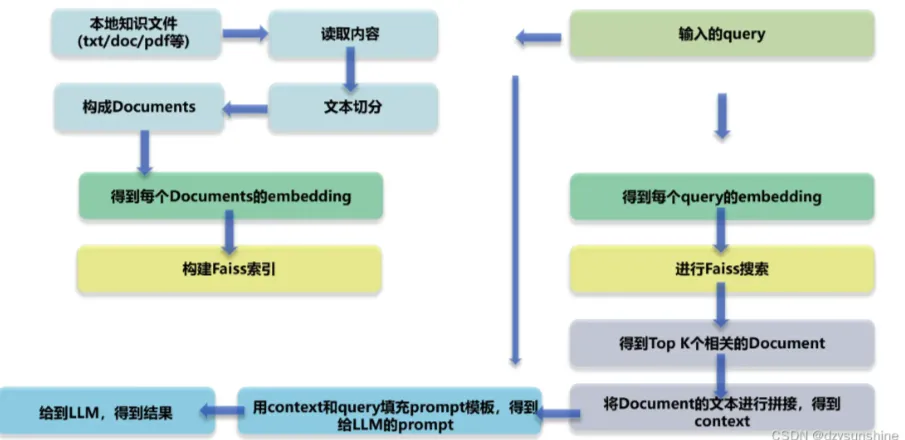
Retrieval Augmented Generation (RAG) is becoming one of the most popular applications of Large Language Models (LLMs) and vector databases.RAG is implemented by retrieving data from vector databases such as WeaviateThe process of augmenting the input to a large language model with the retrieved context.RAG applications are commonly used in chatbots and Q&A systems.
Like any engineered system, performance evaluation is important for RAG The RAG pipeline is divided into three components:
- indexing
- look up
- generating
RAG evaluation is challenging due to the complexity of the interactions between these components and the difficulty of collecting test data. This paper will demonstrate an exciting development in the use of LLM for evaluation and the current state of RAG components.
in a nutshell: We were inspired to work with Ragas The conversation between Jithin James and Shauhul Es, the creators of These conversations, organized by Ragas and new developments in the LLM assessment of RAG systems pioneered by ARES prompted us to reflect on existing metrics and take stock of adjustable RAG parameters. In the course of our research, we further reflected on the possible forms of RAG experimental tracking software and further clarified how RAG systems differ from Agent systems and how they are evaluated.
Our blog posts contain the following five main sections:
- LLM Assessment: Emerging trends in scoring RAG performance using LLM, including zero samples, fewer samples, and fine-tuning the size of the LLM evaluator.
- RAG Indicators: Common metrics used to evaluate generation, search and indexing and how they interact.
- Adjustment parameters for RAG: What are the decisions that affect the significantly different performance of RAG systems?
- scheduling: How do I manage the experiment configuration tracking for the RAG system?
- From RAG to Agent Evaluation: We define a RAG as a three-step process of indexing, retrieval, and generation. This section describes when a RAG system is transformed into an Agent system and how to evaluate their differences.
LLM Assessment
Let's start with the newest and most exciting part of this - LLM evaluation! The history of machine learning has relied heavily on the labor of manually annotating data, such as determining whether a Yelp review is positive or negative, or whether an article is relevant to the query "Who is the head coach of the Boston Celtics?" LLM is increasingly accomplishing data annotation efficiently with less manual effort. This is a key **"new trend "** that is accelerating the growth of RAG applications.
leave it (to sb) Ragas The most common technique pioneered by frameworks such as the Zero Sample LLM Evaluation is the Zero Sample LLM Evaluation. Zero-sample LLM evaluation involves prompting the large language model with templates such as, "Please rate the relevance of these search results on a scale of 1 to 10. The query is {query} and the search results are {search_results}." The following figure shows how LLM can be utilized to evaluate the performance of a RAG system.

There are three major tuning opportunities in zero-sample LLM evaluation: 1. the design metrics, such as precision, recall, or nDCG, 2. the specific language of these cues, and 3. the language model used for the evaluation, e.g., GPT-4, Coral, Llama-2, Mistral, and so on. A major concern at this time is the cost of using the LLM for assessment. For example, evaluating 10 search results using GPT-4 (assuming 500 tokens per result, plus 100 tokens for the query and command, for a total of about 6,000 tokens) would cost about $1000 per Token 0.005, or $3 to evaluate 100 queries.
As frameworks like Ragas promote zero-sample LLM assessment, people are beginning to question the need for less-sample LLM assessment. Since the zero-sample LLM assessment is "good enough", it may be sufficient to serve as the North Star for RAG system tuning. As shown in the figure below, the RAGAS score consists of four zero-sample LLM prompts for each of the two metrics generated:Faithfulness cap (a poem) Answer Relevancy (Answer Relevancy), as well as two indicators of retrieval:Context Precision (Context Precision) cap (a poem) Context Recall (Context Recall)The
The shift from zero-sample to less-sample LLM evaluation is straightforward. We included some labeled examples of search results with query relevance in the instruction templates, also known as contextual learning. The discovery of this technique is one of the key breakthroughs of GPT-3.
For example, adding 5 manual relevance scores to the example would add 30,000 Token to the prompt. assuming the same costs as above, we evaluate an increase from $3 to $15 for 100 queries. Note that this is a simple estimation example and is not based on a real pricing model of the LLM. A key consideration is that adding less sample examples may require longer contextual models that typically price above the LLM for smaller inputs.
This type of LLM assessment based on zero- or few-sample inferences is already very attractive, but further research has shown that the cost of LLM assessment can be further reduced by training algorithms through knowledge distillation. This refers to the use of LLM to generate training data for an assessment task and fine-tune it into a smaller model.
exist ARES: In an automated framework for evaluating retrieval-enhanced generative systems, Saad-Falcon et al. found that training one's own LLM evaluator can outperform zero-sample cues. Initially, ARES requires three inputs: a collection of passages from the target corpus, 150 or more manual preference validation data points, and 5 undersampled examples of queries in the domain.ARES uses these undersampled examples to generate a large amount of synthetic query data, filtered by the principle of loop-consistency: i.e., when searching with a synthetic query, can it retrieve the document that generated the synthetic query? The ARES then generates a large amount of synthetic query data for ARES to use. ARES then generates the data for the contextual relevance,Authenticity of answers cap (a poem) Relevance of answers Fine-tuning lightweight classifiers.
Author's experimental fine-tuning DeBERTa-v3-largeThe model contains a more economical 437 million parameters, with each classifier head sharing the base language model, adding a total of 3 classification heads. By dividing the synthetic data into training and test sets, evaluation of the ARES system found that the fine-tuned model significantly outperformed the GPT-3.5-turbo-16k with zero and fewer samples.For more details (e.g., innovative use of confidence intervals in prediction-driven inference (PPI) and details of the experiments), see Saad-Falcon et al.Thesis.
In order to better understand the potential impact of LLM in the assessment, we will continue to describe the existing RAG systematic benchmarking methodology and its particular variations in the LLM assessment.
RAG Indicators
We introduce the RAG metrics from the top-level perspective of generation, retrieval, and indexing. We then present the RAG tuning parameters from the bottom-level perspective of building indexes, tuning retrieval methods, and generating options.
Another reason for presenting RAG metrics from a top-level perspective is that errors in indexing are passed on to search and generation, but errors in generation (such as the tiers we define) do not affect errors in indexing. In the current state of RAG evaluation, there is rarely an end-to-end evaluation of the RAG stack, and it is often assumed that the oracle context maybe controlled interference term (CIT)(e.g., the Lost in the Middle experiment) to determine generated truthfulness and answer relevance. Similarly, embeddings are typically evaluated with a violent index that does not take into account the approximate nearest neighbor error. Approximate Nearest Neighbor error is usually measured by finding the optimal point of accuracy for trading off query-per-second and recall, with ANN recall being the true nearest neighbors of the query, rather than the documents marked as "relevant" to the query.
Generating indicators
The overall goal of the RAG application is to generate helpful output, supported by the use of retrieved context. The evaluation must take into account that the output uses context and is not taken directly from the source, avoiding redundant information and preventing incomplete answers. In order to score the output, metrics covering each criterion need to be developed.
Ragas Two scores are introduced to measure the performance of the Large Language Model (LLM) output: plausibility and answer relevance.degree of credibility Evaluate the factual accuracy of the answer based on the context of the search.Relevance of answers Determine the relevance of the answer given the question. Answers can have high credibility scores but low answer relevance scores. For example, a plausible answer may directly replicate the context, but this results in a low answer relevance. Answer relevance scores are penalized when answers lack completeness or contain duplicate information.
In 2020, Google released MeenaMeena's goal is to demonstrate that it can perform Reasonable and specific of the conversation. To measure the performance of open domain chatbots, they introduced the Sensibleness and Specificity Average (SSA) evaluation metric. The reasonableness of the bot's response needs to make sense in context and be specific (Specificity Average). This ensures that the output is comprehensive and unambiguous.2020 This requires a human to talk to the chatbot and score it manually.
While it is good to avoid vague answers, it is equally important to prevent large language models from appearing figment of one's imagination . Illusion refers to the fact that the answers generated by the Big Language Model are not based on actual facts or the context provided.LlamaIndex utilization FaithfulnessEvaluator metrics to measure this. Scores are based on whether the response is consistent with the retrieved context.
Evaluating the quality of the generated answers depends on a number of metrics. Answers may be factual but not relevant to the given query. In addition, the answer may be vague and lack critical contextual information to support the response. Next, we will go back to the previous layer of the pipeline and discuss retrieval metrics.
Retrieval of indicators
The next layer of the evaluation stack is information retrieval. Evaluating the retrieval history requires humans to annotate which documents are relevant to the query. Thus, to create 1 query annotation, we may need to annotate the relevance of 100 documents. This is already an extremely difficult task for general search queries, and the challenge is further exacerbated when building domain-specific (e.g., legal contracts, medical patient histories, etc.) search engines.
To alleviate annotation costs, heuristics are often used to determine search relevance. The most common of these is click logging, i.e., given a query, clicked titles may be relevant, while unclicked titles are not. This is also known as weak supervision in machine learning.
Once the dataset is ready, the three metrics commonly used in evaluation are: nDCG ,Recall cap (a poem) Precision The NDCG (Normalized Discount Cumulative Gain) measures rankings by multiple relevance tags. For example, a document about vitamin B12 may not be the most relevant result for a query about vitamin D, but is more relevant than a document about the Boston Celtics. Because of the additional complexity of relative ranking, binary relevance labels (1 for relevant and 0 for irrelevant) are often used. Recall measures how many positive samples are captured in the search results, and Precision measures the proportion of search results labeled as relevant.
Thus, the Big Language Model can compute Precision with the following prompt: "How many of the following search results are related to the query {query}? {search_results}". A proxy for Recall can also be obtained from the Big Language Model prompt: "Do these search results contain all the information needed to answer the query {query}? {search_results}". We also encourage readers to check out some of the hints in Ragas here (literary)The
Another metric worth exploring is LLM Wins, where the Big Language Model prompt reads, "Based on the query {query}, which search result set is more relevant? Set A {Set_A} or Set B {Set_B}. Very important! Please limit the output to 'Set A' or 'Set B'".
Now let's go a layer deeper and understand how to compare vector indexes.
Indexed Indicators
Experienced users familiar with Weaviate may know that ANN BenchmarksThe benchmarking test inspired Development of the gRPC API in Weaviate version 1.19The ANN benchmark measures Queries Per Second (QPS) versus Recall and includes consideration of details such as single-thread limitations. While databases are typically evaluated based on latency and storage costs, random vector indexes are more focused on precision measures. This is in contrast to Approximate calculations in SQL select statements Somewhat similar, but we predict that errors caused by approximations will receive more attention as vector indexing becomes more popular.
Precision is measured by Recall. In vector indexing, recall is the ratio of the number of ground truth nearest neighbors returned by the approximate indexing algorithm to the number of nearest neighbors determined by brute force search. This is similar to the information retrieval (Information Retrieval) differs from the typical usage of "recall", which refers to the proportion of relevant documents retrieved out of all relevant documents. Both are usually measured with an associated @K parameter.
In the context of the full RAG stack, there is an interesting question:When do ANN accuracy errors lead to errors in information retrieval (IR)? For example, we may be able to achieve 1,000 QPS with a recall of 80% or 500 QPS with a recall of 95%, what is the impact on the search metrics mentioned above, such as searching for nDCG or Large Language Model (LLM) recall scores?
Summary on RAG indicators
In summary, we show metrics for evaluating indexing, retrieval, and generation:
- generating: fidelity and answer relevance, and the evolution from metrics such as large-scale detection of hallucinations (e.g., Rationality and Specificity Average, Sensibleness and Specificity Average, SSA).
- look up: New opportunities for contextual precision vs. contextual recall in LLM scoring, and an overview of human labeling for measuring recall, precision, and nDCG.
- indexing: Recall is measured by the number of ground truth nearest neighbors returned by the vector search algorithm. We believe that the key issue here is:When do ANN errors creep into IR errors?
All components can usually be traded off between performance and latency or cost. By using a more expensive language model, we can get higher quality generation; by filtering results with a reorderer, we can get higher quality retrieval; by using more memory, we can get higher recall indexing. How to manage these tradeoffs to improve performance may become clearer as we continue to investigate the "knobs of RAG". As a final note, we have chosen to present the metrics from a top-down perspective from generation to search and indexing because the evaluation time is closer to the user experience. We will also present the tuning knobs from a bottom-up perspective from indexing to search and generation, as this is more similar to the experience of a RAG application developer.
RAG Adjustment Parameters
Now that we've discussed metrics for comparing RAG systems, let's dive into the key decisions that can significantly impact performance.
Index Adjustment Parameters
The most important indexing tuning parameter when designing a RAG system is the vector compression setting. weaviate 1.18 introduced Product Quantization (PQ) in March 2023. pQ is a vector compression algorithm that groups consecutive segments of a vector, clusters the values in its set, and then reduces the precision by the prime. For example, a contiguous fragment of four 32-bit floating-point numbers takes 16 bytes to represent, while a fragment of length 4 with eight centers of mass takes only 1 byte, achieving a memory compression ratio of 16:1. Recent advances in PQ reordering significantly reduce the recall loss caused by compression, but should be considered with caution at very high levels of compression.
Next is the routing index used. For datasets with less than 10K vectors, a RAG application may be satisfied with brute force indexing. However, as the number of vectors increases, the latency of brute force indexing is much higher than indexing based on Proximity Graph algorithms such as HNSW. As described in the RAG metrics, HNSW performance is typically measured by the Pareto optimal point, which trades off the query-per-second versus the recall. This is done by adjusting the size of the search queue used for inference. ef to make it happen. The larger ef will perform more distance comparisons during the search process, which slows it down significantly, but produces more accurate results. The next parameters include those used in constructing the index, such as efConstruction (the size of the queue when inserting data into the graph) and maxConnections (number of edges per node, to be stored with each vector).
Another new direction we are exploring is the effect of distributional bias on the center of mass of the PQ, and with hybrid clustering and graph indexing algorithms such as DiskANN maybe IVFOADC+G+P) interactions. Using the recall metrics may be sufficient to determine if we need to refit the center of mass, but the question remains: which subset of vectors to use for refitting. If we use the most recent 100K vectors that cause recall to drop, we may be overfitting to a new distribution, so we may need to sample a mixture of data distribution timelines. This topic is closely related to our point about continuous optimization of deep learning models, which can be discussed further in the section on "Tuning Optimization".
Data chunking is an important step before inserting data into Weaviate. Chunking converts long documents into smaller parts. This enhances retrieval because each chunk contains important information and helps to stay within the Token limits of the Large Language Model (LLM). There are multiple strategies for parsing documents. The figure above shows an example of chunking a research paper based on its title. For example, chunk 1 is the abstract, chunk 2 is the introduction, and so on. There are also ways to combine chunks and create overlaps. This includes a sliding window that takes a Token from the previous chunk and uses it as the start of the next chunk. A slight overlap of blocks improves the search as the retriever is able to understand the previous context/block. The following image shows a high-level schematic of chunked text.

look up
There are four main adjustable parameters in the search: the embedding model, the hybrid search weights, whether to use AutoCut and the reordering model.
Most RAG developers are likely to immediately reconcile the embedding model used, e.g., OpenAI, Cohere, Voyager, Jina AI, Sentence Transformers, and many other options! Developers also need to consider the dimensionality of the model and its impact on PQ compression.
The next key decision is how to adjust the aggregation weights for sparse and dense retrieval methods in hybrid search. The weights are based on the parameter alphaThealpha 0 is pure bm25 Search.alpha to 1 is a pure vector search. Therefore, setting alpha Depends on your data and application.
Another emerging development is the effectiveness of zero-sample reordering models.Weaviate currently offers 2 Cohere's reordering model::rerank-english-v2.0 cap (a poem) rerank-multilingual-v2.0. As the name suggests, these models differ primarily because of the training data used and the resulting multilingual capabilities. In the future, we expect to provide more options in terms of model capabilities, which involves an inherent trade-off between performance and latency that may make sense for some applications but not for others. In tuning the parameters in the retrieval, it is a challenge to discover what kind of capability reorderer is needed and how many retrieval results need to be reordered. This is also one of the easiest entry points for fine-tuning a custom model in a RAG stack, which we discuss further in "Regulatory Optimization".
Another interesting tuning parameter is multi-indexed searches. Similar to our discussion of chunking, this involves structural changes to the database. The overall question is:When should I use a separate collection instead of a filter? should transfer blogs cap (a poem) documentation into two collections, or store them jointly in a collection with a source attribute Document In the category?

Using filters gives us a quick way to test the utility of these labels, as we can add multiple labels to each block and then ablate to analyze how the classifier utilizes these labels. There are a number of interesting ideas, such as explicitly labeling the source of the context in the context entered into the LLM, e.g., "The following are search results from the blog {search_results}. Here are search results from documents {documentation}". As LLM is able to handle longer inputs, we expect that context fusion between multiple data sources will become more common, so another relevant hyperparameter emerges: how many documents are retrieved from each index or filter.
generating
The first thing to focus on regarding generation is which Large Language Model (LLM) to choose. For example, you can choose models from OpenAI, Cohere, Facebook, and many open source options. Many LLM frameworks (e.g. LangChain,LlamaIndex cap (a poem) Weaviate's Generator Module) offers easy integration with a variety of models, which is a big plus. The choice of model may depend on factors such as whether you want your data to remain private, cost, resources, and so on.
A common, LLM-specific regulation parameter is temperature. The temperature setting controls the randomness of the output. A temperature of 0 means that the response is more predictable and less variable; a temperature of 1 allows the model to introduce randomness and creativity into the response. Therefore, if you run the generative model multiple times with temperature set to 1, the response may be different each time you re-run it.
Long Context Models (LCMs) are an emerging direction when choosing an LLM for your application. Does adding more search results as input improve response quality? Research on the Lost in the Middle experiment raises some red flags. In "Lost in the Middle" In it, researchers at Stanford, UC Berkeley, and Samaya AI conducted controlled experiments showing that if relevant information is placed in the middle of a search result, rather than at the beginning or end, the language model may not be able to incorporate it when generating a response. Another paper by researchers at Google DeepMind, Toyota and Purdue University noted:"Large language models are easily distracted by irrelevant context.". While this direction is full of potential, as of this writing, long context RAG is still in its early stages. Fortunately, metrics such as Ragas scores can help us quickly test new systems!
Similar to the recent breakthroughs in LLM evaluation that we discussed earlier, the generative aspect of tuning is divided into three stages: 1. Prompt Tuning, 2. Few-Shot Examples, and 3. Fine-Tuning. Prompt tuning involves adapting specific linguistic expressions, such as "Please answer the question based on the search results provided." versus "Please answer the question. Important, please follow the instructions below closely. Your answer to the question must be based on the search results provided, only!!!" The difference between.
As mentioned earlier, a sample less example refers to the collection of a number of manually-written question, context, and answer pairs to guide the generation of a language model. Recent studies (e.g. "Context Vector") further demonstrates the importance of bootstrapping the potential space in this way. In the Weaviate Gorilla project, we used GPT-3.5-turbo to generate Weaviate queries, and when we added natural language to the query translation of the lesser sample examples, performance improved significantly.
Finally, LLM fine-tuning for RAG applications is receiving increased attention. Here are a couple of approaches to consider. Returning again to our discussion of LLM evaluation, we may want to generate training data using a more robust LLM to build a smaller, more economical model owned by ourselves. Another idea is to provide human annotation of response quality, so that the LLM can be fine-tuned with command following. if you are interested in model fine-tuning, check out Brev's contribution on how to use the HuggingFace PEFT library at tutorialsThe
Summary of RAG tuning options
In summary, we have described the main tuning options available in the RAG system:
- Indexing: at the highest level, we need to consider when to use only brute force search and when to introduce ANN indexing. This is especially interesting when tuning multi-tenant use cases with new vs. forceful users. In ANN indexing, we have hyperparameters for PQ (fragmentation, center of mass, and training limits). hNSW includes (ef, efConstruction, and maxConnections).
- Retrieval: selecting an embedding model, adjusting hybrid search weights, selecting a reorderer, and partitioning a collection into multiple indexes.
- Generate: select an LLM and decide when to transition from cue tuning to sample less examples or fine tuning.
Having understood the RAG metrics and how to improve their performance through tuning, let's discuss possible implementations of experimental tracking.
scheduling
Given recent advances in the field of Large Language Model (LLM) evaluation and an overview of some of the tunable parameters, combining all of this with an experiment tracking framework is an exciting opportunity. For example, a simple orchestrator with an intuitive API could be used for the user to perform the following: 1. request a full test of 5 LLMs, 2 embedded models, and 5 indexing configurations; 2. run the experiments; and 3. return a high-quality report to the user.Weights & Biases has carved out a remarkable experimental tracking path for training deep learning models. We expect interest to grow rapidly for RAG experimental support with the tunable parameters and metrics outlined in this paper.
We are following two directions of development in this area. On the one hand, existing zero-sample LLMs (e.g., GPT-4, Command, Claude, as well as the open-source options Llama-2 and Mistral) are not as good as they could be with the oracle context performed quite well at the time. So there is a huge opportunity to Focus on the search part . This requires finding tradeoffs among multiple configurations of ANN errors, embedded models, hybrid search weighting, and reordering of PQ or HNSW, as described earlier in this paper.
Weaviate 1.22 introduces asynchronous indexing and corresponding node state APIs, which we hope that through partnerships focused on RAG evaluation and tuning orchestration, they can utilize to determine when the indexes have finished building and then run tests. This is particularly exciting when considering tuning orchestration interfaces with each tenant based on these node states, where some tenants may rely on brute force search while others need to find the right embedding model and HNSW configuration for their data.
In addition, we may wish to speed up testing by parallelizing resource allocation. For example, evaluating 4 embedding models at the same time. As mentioned earlier, another interesting part is the adjustment of chunking or other symbolic metadata that may come from the data importer. As an example, the Weaviate Verba dataset contains 3 folders of Weaviate's Blogs,Documentation cap (a poem) Video Transcription. If we wish to compare chunk sizes of 100 and 300, there is no need to re-call the web crawler. We may need another format, whether it's data stored in an S3 storage bucket or something else, that has relevant metadata, but provides a more economical way to experiment.
On the other hand, we have model fine-tuning and gradient-based continuous learning rather than data insertion or updating. The most common models used in RAG are embedded models, reordered models, and of course LLMs. keeping machine learning models up-to-date with new data has been a longstanding focus of continuous learning frameworks and MLops orchestrations that manage the retraining, testing, and deployment of new models. Starting with continuous learning LLM, one of the biggest selling points of the RAG system is the ability to extend the "cutoff" date of the LLM knowledge base to keep it in sync with your data. can LLM do this directly? We don't think it's clear how well continuous training interacts with just keeping information up to date through the RAG. Some studies (e.g., MEMIT) have experimented with causal mediation analyses of weight attribution, updating facts such as "LeBron James plays basketball" to "LeBron James plays soccer". " and so on. This is a fairly advanced technique, and another opportunity may be to simply label the chunks used in training (e.g., "LeBron James plays basketball") and retrain them using retrieval-enhanced training data containing the new information. This is an important area that we are watching closely.
As mentioned earlier, we are also considering how to integrate this type of continuous tuning directly into Weaviate using PQ prime centers. The PQ center of gravity of the first K vectors entering Weaviate for the first time may be affected by significant changes in the data distribution. Continuous training of machine learning models suffers from the infamous "catastrophic forgetting" problem, where training on the latest batch of data impairs performance on earlier batches. This is one of the considerations we took into account when designing the PQ center-of-mass refitting.
From RAG to Agent Evaluation
Throughout the article, we focus on the RAG Instead of Agent Assessment. In our opinion.RAG defined as the process of indexing, retrieval, and generation, and the Agents The scope of the program is more open. The diagram below illustrates how we see the main components, such as planning, memorization, and tools, which together provide significant capabilities to your system, but also make it more difficult to evaluate.
 A common next step for RAG applications is to add an advanced query engine. For readers who are new to this concept, check out our LlamaIndex and Weaviate series which provides Python code examples on how to get started. There are many different advanced query engines, such as sub-question query engines, SQL routers, self-correcting query engines, and more. We are also considering possible forms of the promptToQuery API or search query extractor in the Weaviate module. Each query engine has its own advantages in the information retrieval process, so let's dive into a few of them and how we can evaluate them.
A common next step for RAG applications is to add an advanced query engine. For readers who are new to this concept, check out our LlamaIndex and Weaviate series which provides Python code examples on how to get started. There are many different advanced query engines, such as sub-question query engines, SQL routers, self-correcting query engines, and more. We are also considering possible forms of the promptToQuery API or search query extractor in the Weaviate module. Each query engine has its own advantages in the information retrieval process, so let's dive into a few of them and how we can evaluate them.
 The multi-hop query engine (also known asSub-Issue Query Engine) is perfect for breaking down complex problems into sub-problems. In the diagram above, we have the query "What is Ref2Vec in Weaviate?" To answer this question, you need to know what Ref2Vec and Weaviate are, respectively. To answer this question, you need to know what Ref2Vec and Weaviate are, respectively. Therefore, your database needs to be called twice for both questions to retrieve the relevant context. The two answers are then combined to produce a single output. Performance evaluation of a multi-hop query engine can be accomplished by looking at the subproblems. It is important that LLM creates relevant subquestions, answers each question accurately, and combines the two answers to provide factually accurate and relevant output. In addition, if you are asking complex questions, it is best to use a multi-hop query engine.
The multi-hop query engine (also known asSub-Issue Query Engine) is perfect for breaking down complex problems into sub-problems. In the diagram above, we have the query "What is Ref2Vec in Weaviate?" To answer this question, you need to know what Ref2Vec and Weaviate are, respectively. To answer this question, you need to know what Ref2Vec and Weaviate are, respectively. Therefore, your database needs to be called twice for both questions to retrieve the relevant context. The two answers are then combined to produce a single output. Performance evaluation of a multi-hop query engine can be accomplished by looking at the subproblems. It is important that LLM creates relevant subquestions, answers each question accurately, and combines the two answers to provide factually accurate and relevant output. In addition, if you are asking complex questions, it is best to use a multi-hop query engine.
Multi-hop problems depend first and foremost on the accuracy of the sub-questions. We could conceivably use a similar LLM evaluation here, with the following prompt: "Given the question: {query}. A system decided to break it into the sub questions {sub_question_1} and {sub_question_2}. Does this decomposition of the question make sense?" We then perform two separate RAG evaluations for each sub-question and evaluate whether the LLM is able to combine the answers to each question to answer the original question.
As another example of the evolution of complexity from RAGs to Agents, let's consider routing query engines. The figure below illustrates how an Agent can route a query to a SQL or vector database query. This scenario is very similar to our discussion of multi-index routing, and we can use a similar approach to evaluate the generated results, hinting at the need for stating SQL and vector databases, and then asking the LLM router if it made the right decision. We could also use the RAGAS context relevance score for SQL query results.
 To summarize the discussion of "From RAG to Agent Evaluation", we believe that it is currently impossible to tell what the common patterns of Agent usage are. We have intentionally shown multi-hop query engines and query routers because these are relatively easy to understand. Once we add more open-ended evaluations related to planning loops, tool usage, and how to evaluate the ability of a model to format tool API requests, as well as meta-internal memory management hints such as those in MemGPT, it will be difficult to provide a common abstraction around how to evaluate Agents.
To summarize the discussion of "From RAG to Agent Evaluation", we believe that it is currently impossible to tell what the common patterns of Agent usage are. We have intentionally shown multi-hop query engines and query routers because these are relatively easy to understand. Once we add more open-ended evaluations related to planning loops, tool usage, and how to evaluate the ability of a model to format tool API requests, as well as meta-internal memory management hints such as those in MemGPT, it will be difficult to provide a common abstraction around how to evaluate Agents.
reach a verdict
Thank you very much for reading our overview of RAG evaluation! As a quick recap, we first introduced the new trend of using LLMs for evaluation, which provides significant cost and time savings for iterative RAG systems. Next, we presented more background on the traditional metrics used for evaluating RAG stacks, from generation to search to indexing. For builders wishing to improve the performance of these metrics, we then show some tunable parameters for indexing, searching, and generating. We present the challenges of experimental tracking of these systems, and describe our views on the differences between RAG evaluation and Agent evaluation. We hope you find this paper useful!
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...