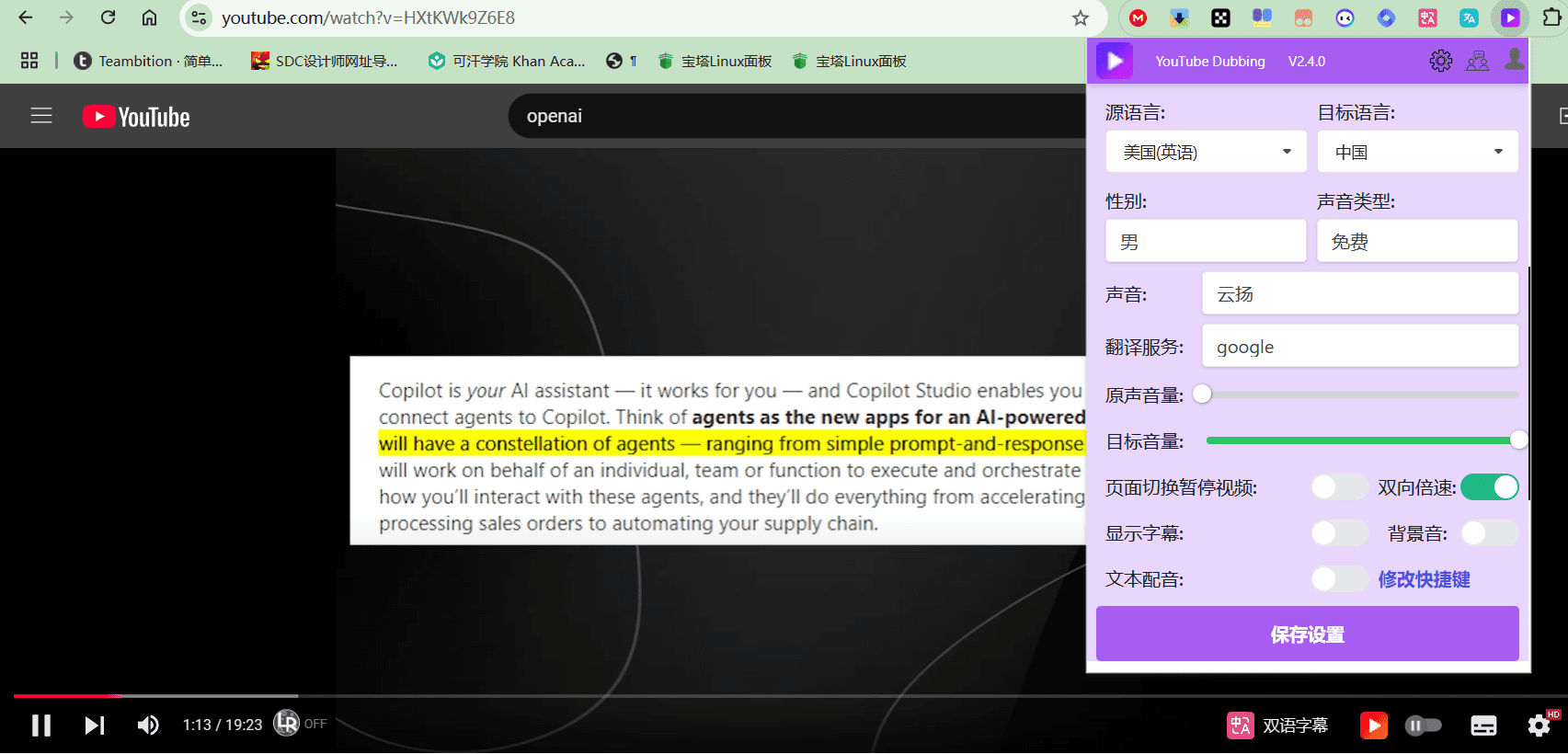
Voice Changer: Ein Echtzeit-Stimmenwechsler, der deine Lieblings-Anime-Charaktere singen lässt!

Allgemeine Einführung
Voice Changer ist ein quelloffenes Echtzeit-Stimmenumwandlungstool, das eine Vielzahl von KI-Stimmenmodellen wie MMVC, so-vits-svc, RVC, DDSP-SVC und Beatrice unterstützt und mit einer Vielzahl von Plattformen kompatibel ist, darunter Windows, Mac, Linux und Google Colab. Das Tool ist mit mehreren Plattformen kompatibel, darunter Windows, Mac, Linux und Google Colab, und ermöglicht es Benutzern, Stimmen in Echtzeit über eine einfache Schnittstelle für eine Vielzahl von Szenarien wie Spiele und Live-Streaming zu konvertieren.
Ähnliche Artikel:
so-vits-svcundEine Branchenempfehlung, die die Interaktion verbessert
Dieses Projekt unterscheidet sich grundlegend von Vits, das TTS ist, und dieses Projekt ist SVC; dieses Projekt implementiert kein TTS, und Vits implementiert kein SVC, und die Modelle der beiden Projekte haben überhaupt nichts gemeinsam.
Funktionsliste
- Unterstützt mehrere AI-Sprachmodelle
- Sprachumwandlung in Echtzeit
- Plattformübergreifende Kompatibilität (Windows, Mac, Linux, Google Colab)
- Leicht zu bedienende Benutzeroberfläche
- Unterstützung für die Bereitstellung von Docker- und Anaconda-Umgebungen
- Vorkompilierte Binärdateien bereitstellen
- Unterstützt GPU-Beschleunigung
Hilfe verwenden
Einbauverfahren
- Installation von vorkompilierten Binärdateien::
- Wir bieten Windows- und Mac-Versionen an. Eine Mac-Version erhalten Sie unter Gesicht umarmen Herunterladen.
- Herunterladen für Windows-Benutzer
vcclient_win_std_xxx.zipvielleichtvcclient_win_cuda_xxx.zip(für NVIDIA-GPUs). - Download für Mac-Benutzer
vcclient_mac_xxx.zip. - Entpacken Sie die heruntergeladene Datei und führen Sie die darin enthaltene ausführbare Datei aus.
- Docker-Bereitstellung::
- Stellen Sie sicher, dass Docker installiert ist.
- Klonen des Projektlagers:
git clone https://github.com/w-okada/voice-changer.git - Rufen Sie den Projektkatalog auf:
cd voice-changer - Erstellen Sie das Docker-Image:
docker build -t voice-changer . - Starten Sie den Docker-Container:
docker run -it --rm -p 5000:5000 voice-changer
- Bereitstellung der Anaconda-Umgebung::
- Installieren Sie Anaconda und erstellen Sie eine neue Umgebung:
conda create -n voice-changer python=3.8 - Aktivieren Sie die Umwelt:
conda activate voice-changer - Installieren Sie die Abhängigkeit:
pip install -r requirements.txt - Führen Sie die Anwendung aus:
python app.py
- Installieren Sie Anaconda und erstellen Sie eine neue Umgebung:
Verwendungsprozess
- eine Anwendung starten::
- Nachdem Sie die vorkompilierte Binärdatei ausgeführt oder die Anwendung über Docker/Anaconda gestartet haben, öffnen Sie einen Browser, um auf die
http://localhost:5000.
- Nachdem Sie die vorkompilierte Binärdatei ausgeführt oder die Anwendung über Docker/Anaconda gestartet haben, öffnen Sie einen Browser, um auf die
- Auswählen eines Sprachmodells::
- Wählen Sie das gewünschte AI-Sprachmodell (z.B. MMVC, so-vits-svc, etc.) in der Schnittstelle aus.
- Konfigurieren von Eingabe- und Ausgabegeräten::
- Konfigurieren Sie das Mikrofon als Eingangsgerät und die Lautsprecher oder Kopfhörer als Ausgangsgerät.
- Sprachumwandlung starten::
- Klicken Sie auf die Schaltfläche "Start", um die Sprachumwandlung in Echtzeit zu starten.
- Wenn Sie sprechen, wird Ihre Stimme umgewandelt und in Echtzeit über das Ausgabegerät wiedergegeben.
- Anpassung der Einstellungen::
- Passen Sie die Umwandlungsparameter wie Neigung, Geschwindigkeit usw. nach Bedarf an, um die besten Ergebnisse zu erzielen.
allgemeine Probleme
- TonverzögerungStellen Sie sicher, dass Sie eine leistungsstarke CPU oder GPU verwenden, um die Latenz zu verringern.
- Probleme mit der Tonqualität: Probieren Sie verschiedene Voice-Modelle aus oder passen Sie die Parametereinstellungen an.
- KonnektivitätsproblemÜberprüfen Sie die Netzwerkverbindung oder starten Sie die Anwendung neu.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...