
V-JEPA 2 - Das leistungsstärkste Großmodell der Welt von Meta AI

Was ist V-JEPA 2
V-JEPA 2 Ja Meta-KI Einführung eines Modells von Weltformat auf der Grundlage von Videodaten mit 1,2 Milliarden Parametern. Das Modell wird auf der Grundlage von selbstüberwachtem Lernen aus über 1 Million Stunden Videomaterial und 1 Million Bildern trainiert, um Objekte, Aktionen und Bewegungen in der physischen Welt zu verstehen und zukünftige Zustände vorherzusagen. Das Modell verwendet eine Encoder-Predictor-Architektur in Kombination mit der Vorhersage von Aktionsbedingungen, um die Planung von Robotern mit Null-Proben zu unterstützen, so dass Roboter Aufgaben in neuen Umgebungen erledigen können. Das Modell ist mit Video-Fragen und -Antworten ausgestattet und unterstützt die Kombination von Sprachmodellen zur Beantwortung von Fragen in Bezug auf Videoinhalte.V-JEPA 2 zeichnet sich durch Aufgaben wie Handlungserkennung, Vorhersage und Video-Fragen und -Antworten aus und bietet leistungsstarke technische Unterstützung für die Robotersteuerung, intelligente Überwachung, Bildung und Gesundheitsfürsorge und ist ein wichtiger Schritt in Richtung fortschrittlicher maschineller Intelligenz.
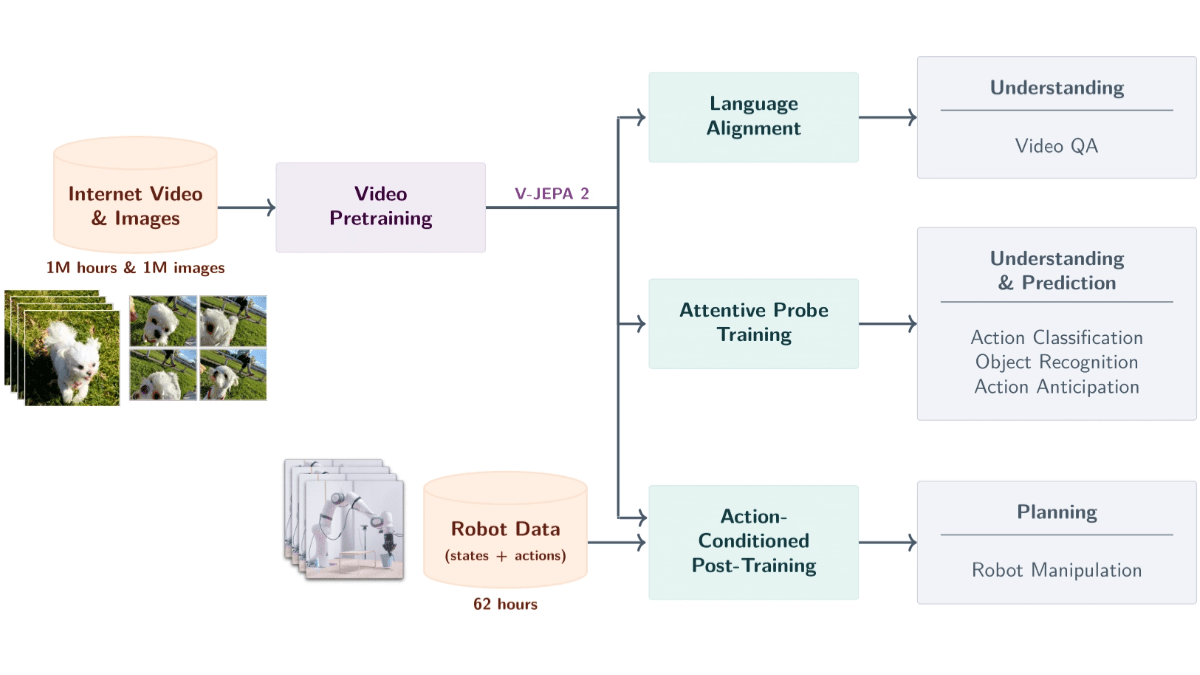
Hauptmerkmale von V-JEPA 2
- Semantisches Video-ParsingErkennung von Objekten, Handlungen und Bewegungen in Videos und genaue Extraktion von semantischen Informationen über die Szene.
- Vorhersage künftiger EreignisseVorhersage zukünftiger Videobilder oder Aktionsergebnisse auf der Grundlage des aktuellen Zustands und der aktuellen Aktionen, wobei sowohl kurzfristige als auch langfristige Vorhersagen möglich sind.
- Roboter-NullprobenplanungPlanung von Aufgaben für Roboter in neuen Umgebungen, wie z.B. das Greifen und Manipulieren von Objekten, auf der Grundlage von Vorhersagefähigkeiten, ohne zusätzliche Trainingsdaten.
- Video Q&A InteraktionKombinieren Sie Sprachmodelle, um Fragen zu beantworten, die sich auf den Inhalt des Videos beziehen und die physikalische Ursache und Wirkung sowie das Verständnis der Szene betreffen.
- Szenenübergreifende Verallgemeinerung: zeigt gute Leistungen bei ungesehenen Umgebungen und Objekten und unterstützt das Lernen mit Nullproben und die Anpassung an neue Szenen.
Offizielle Adresse der Website von V-JEPA 2
- Projekt-Website::https://ai.meta.com/blog/v-jepa-2
- GitHub-Repository::https://github.com/facebookresearch/vjepa2
- Technische Papiere::https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
Wie verwende ich V-JEPA 2?
- Zugang zu Modellressourcen: Laden Sie die vortrainierten Modelldateien und den zugehörigen Code aus dem GitHub-Repository herunter. Die Modelldateien werden im .pth- oder .ckpt-Format bereitgestellt.
- Einrichten der Entwicklungsumgebung::
- Installation von PythonStellen Sie sicher, dass Python installiert ist (Python 3.8 oder höher wird empfohlen).
- Installation von abhängigen BibliothekenVerwenden Sie pip, um Abhängigkeiten zu installieren, die für das Projekt erforderlich sind. Normalerweise stellen Projekte eine requirements.txt-Datei zur Verfügung, um Abhängigkeiten mit den folgenden Befehlen zu installieren:
pip install -r requirements.txt- Installation von Deep-Learning-FrameworksV-JEPA 2 basiert auf PyTorch und erfordert die Installation von PyTorch, abhängig von der System- und GP-Konfiguration. Die Installationsbefehle finden Sie auf der PyTorch-Website.
- Modelle laden::
- Laden von vortrainierten ModellenLaden von vortrainierten Modelldateien mit PyTorch.
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- Vorbereiten der Dateneingabe::
- Vorverarbeitung von VideodatenV-JEPA 2 benötigt Videodaten als Eingabe. Die Videodaten werden in das vom Modell benötigte Format (normalerweise Tensor) umgewandelt. Im Folgenden finden Sie ein einfaches Beispiel für die Vorverarbeitung:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- Vorhersage mit Modellen::
- DurchführungsprojektionenEingabe der vorverarbeiteten Videodaten in das Modell, um die Vorhersageergebnisse zu erhalten. Im Folgenden finden Sie einen Beispielcode:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- Analyse und Anwendung der Prognoseergebnisse::
- Analyse der PrognoseergebnisseParsing: Analysiert die Ausgabe des Modells entsprechend den Anforderungen der Aufgabe.
- Anwendung auf reale SzenarienAnwendung von Vorhersagen auf reale Aufgaben wie Robotersteuerung, Videoquiz oder Anomalieerkennung.
Die wichtigsten Vorteile von V-JEPA 2
- Ausgeprägtes Verständnis für die physische WeltV-JEPA 2 ist in der Lage, Handlungen und Bewegungen von Objekten auf der Grundlage von Videoeingaben genau zu erkennen, semantische Informationen über die Szene zu erfassen und grundlegende Unterstützung für komplexe Aufgaben zu bieten.
- Effiziente Vorhersage zukünftiger ZuständeAuf der Grundlage des aktuellen Zustands und der Aktionen kann das Modell zukünftige Videobilder oder Aktionsergebnisse vorhersagen und unterstützt sowohl kurzfristige als auch langfristige Vorhersagen, was Anwendungen wie Roboterplanung und intelligente Überwachung fördert.
- Null-Proben-Lernen und GeneralisierungsfähigkeitenV-JEPA 2 zeigt gute Leistungen bei ungesehenen Umgebungen und Objekten, unterstützt Null-Proben-Lernen und Anpassung und benötigt keine zusätzlichen Trainingsdaten, um neue Aufgaben zu lösen.
- Video-Fragen und Antworten in Kombination mit SprachmodellierungIn Kombination mit einem Sprachmodell ist V-JEPA 2 in der Lage, Fragen zu Videoinhalten zu beantworten, die physikalische Kausalität und das Verstehen von Szenen abdecken und damit die Anwendungsmöglichkeiten in Bereichen wie Bildung und Gesundheitswesen erweitern.
- Effizientes Training basierend auf selbstüberwachtem LernenLearning generic visual representations from large-scale video data based on self-supervised learning without manually labelling the data, reducing cost and improving generalisation.
- Mehrstufiges Training und Vorhersage der BewegungsbedingungenV-JEPA 2 basiert auf einem mehrstufigen Trainingsprozess, bei dem zunächst der Encoder und dann der Bewegungsprädiktor trainiert werden, wobei visuelle und Bewegungsinformationen zur Unterstützung einer präzisen prädiktiven Steuerung kombiniert werden.
Personen, für die V-JEPA 2 bestimmt ist
- Forscher im Bereich der künstlichen IntelligenzAkademische Forschung und technologische Innovation mit der Spitzentechnologie von V-JEPA 2 zur Förderung der maschinellen Intelligenz.
- Robotik-IngenieurEntwicklung von Robotersystemen, die an neue Umgebungen und komplexe Aufgaben angepasst sind, mit Hilfe von Modell-Null-Proben-Planungsfähigkeiten.
- Entwickler für Computer VisionVerbesserung der Effizienz der Videoanalyse mit V-JEPA 2, die in der intelligenten Sicherheit, der industriellen Automatisierung und anderen Bereichen eingesetzt wird.
- Experte für die Verarbeitung natürlicher Sprache (NLP)Kombination von visueller und linguistischer Modellierung zur Entwicklung intelligenter Interaktionssysteme wie virtuelle Assistenten und intelligenter Kundenservice.
- ErzieherinEntwicklung immersiver Lehrmittel auf der Grundlage von Videoquiz-Funktionen zur Verbesserung des Lehrens und Lernens.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...