
Bilderzeugungsmodell CogView4, angekündigt als Open Source!


Dieses Bild ist eine Verschmelzung von klassischer chinesischer Kunst und modernen Elementen. Es ist inspiriert von Wang Ximengs A Thousand Miles of Rivers and Mountains aus der Nördlichen Song-Dynastie. Das Bild zeigt eine prächtige Landschaftsrolle, bei der die Technik der grünen Landschaft zu sanften Hügeln und ausgedehnten Flüssen, reichen Farbschichten und exquisiten Details führt. Über dieser malerischen Landschaft erscheint auf subtile Weise das Pinselzeichen "CogView4" in einer kräftigen und kraftvollen Schriftart, und die Tinte ist im richtigen Farbton gehalten, als ob es sich um einen improvisierten Pinselstrich eines alten Literaten handelt, der die Landschaft genießt. Der Schriftzug "CogView4" ergänzt die umgebende Landschaft, wobei er weder zu abrupt noch zu harmonisch wirkt, sondern vielmehr ein Gefühl des Dialogs über Zeit und Raum hinweg vermittelt. Das gesamte Bild hat das Flair einer klassischen Landschaft, enthält aber auch Elemente moderner Technologie und stellt eine einzigartige künstlerische Spannung dar, die es den Menschen ermöglicht, die traditionelle Ästhetik zu schätzen und gleichzeitig die Kollision und Verschmelzung moderner Kreativität zu spüren.
Heute haben wir unser neuestes Modell zur Bilderzeugung, CogView4, offiziell veröffentlicht und als Open Source zur Verfügung gestellt.
Das Modell verfügt über starke Fähigkeiten zum komplexen semantischen Abgleich und zur Befehlsverfolgung, unterstützt zweisprachige Eingaben beliebiger Länge, erzeugt Bilder beliebiger Auflösung innerhalb eines bestimmten Bereichs und verfügt über starke Fähigkeiten zur Texterzeugung. Das Modell ist auch das erste Bilderzeugungsmodell, das unter dem Apache 2.0-Protokoll als Open-Source angeboten wird.
I. Bewertung
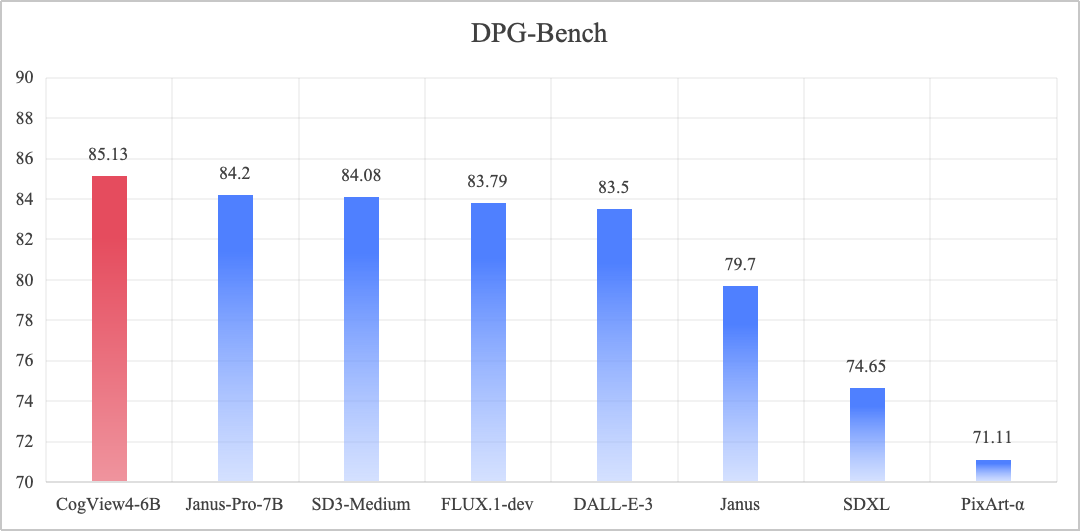
DPG-Bench (Dense Prompt Graph Benchmark) ist ein Benchmark-Test zur Evaluierung von Text-Bild-Generierungsmodellen, der sich auf die Leistung der Modelle in Bezug auf komplexe semantische Ausrichtung und die Fähigkeit, Anweisungen zu folgen, konzentriert.
CogView4-6B, das bei den DPG-Bench-Benchmarks den ersten Platz belegt und im Open-Source-Grafikmodell Vincennes SOTA erreicht.
II. willkürliche Länge und willkürliche Auflösung
Das CogView4-Modell implementiert ein hybrides Trainingsparadigma mit Textbeschreibungen beliebiger Länge und Bildern beliebiger Auflösung.
1、Codierung der Bildposition
CogView4 verwendet 2D Rotational Position Encoding (2D RoPE), um die Positionsinformationen eines Bildes zu modellieren und unterstützt Bilderzeugungsaufgaben in verschiedenen Auflösungen durch Interpolation der Positionskodierung.
2. die Modellierung der Diffusionserzeugung
Das Modell wird mit einem Flow-Matching-Schema für die Diffusionserzeugung modelliert, kombiniert mit parametrischer linearer dynamischer Rauschplanung, um den Anforderungen an das Signal-Rausch-Verhältnis von Bildern mit unterschiedlicher Auflösung gerecht zu werden.
3、Architekturentwurf
Was die Architektur des DiT-Modells betrifft, so setzt CogView4 die Share-param-DiT-Architektur seines Vorgängers fort und entwirft unabhängige adaptive LayerNorm-Schichten für Text- und Bildmodalitäten getrennt, um eine effiziente intermodale Anpassung zu erreichen.
4. mehrstufige Ausbildung
CogView4 verwendet eine mehrstufige Trainingsstrategie, die das Training der Basisauflösung, das Training der Schwenkauflösung, die Feinabstimmung hochwertiger Daten und das Training zur Anpassung an menschliche Präferenzen umfasst. Dieser mehrstufige Trainingsansatz deckt nicht nur ein breites Spektrum an Bildverteilungen ab, sondern stellt auch sicher, dass die erzeugten Bilder ästhetisch ansprechend sind und den menschlichen Präferenzen entsprechen.
5. die Optimierung des Ausbildungsrahmens
Aus textueller Sicht durchbricht CogView4 die traditionelle Begrenzung der Token-Länge, indem es höhere Obergrenzen für Token zulässt und die Redundanz von Text-Token während des Trainings deutlich reduziert. Wenn die durchschnittliche Länge der Trainingsbeschriftung im Bereich von 200-300 Token liegt, reduziert CogView4 die Token-Redundanz um etwa 50% im Vergleich zum traditionellen Schema mit festen 512 Token und erreicht eine Effizienzsteigerung von 5%-30% in der progressiven Trainingsphase des Modells.
Aus der Bildperspektive ermöglicht das Training mit gemischten Auflösungen dem Modell, beliebige Auflösungen in einem weiten Bereich zu erzeugen, was die kreative Freiheit deutlich erhöht. Die Zielauflösung muss nur die folgenden Bedingungen erfüllen:
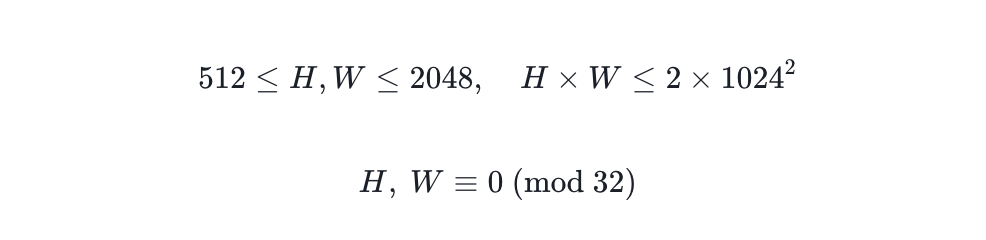
Beides kann den kreativen Spielraum erheblich vergrößern.
Beispiel: Extralange Geschichte (Vier-Panel-Comic)

Prinzessin: ein weiblicher Mensch, schön und elegant, gekleidet in ein prächtiges Prinzessinnenkostüm, gefangen in der Höhle eines Monsters.
Der König: ein männlicher Mensch, majestätisch und wohlwollend, gekleidet in ein prächtiges königliches Gewand und auf dem Thron des Königreichs sitzend.
Flammendrache: ein Monster, das mit flammenähnlichen Schuppen bedeckt ist, Flammen spuckt und riesig groß ist.
Dunkler Herrscher: Ein riesiges, in Dunkelheit gehülltes Monster, das über große magische Kräfte verfügt.
Szene 1: Xiao Ming begibt sich auf eine Reise
Gestalten Sie eine Szene im Anime-Stil mit einem prächtigen Hof des Königreichs im Hintergrund. Die Hauptfigur der Szene ist Kotomine (ein menschlicher Junge mit einem tapferen Herzen, der ein Schwert hält und ein einfaches Kriegerkostüm trägt), der in einer Pose gezeigt wird, in der er sich auf eine Reise begibt. Die Blumen im Hof und das Schloss in der Ferne sind detailliert dargestellt, und das Licht der Morgensonne vermittelt Mut und Entschlossenheit. Qualität: Meisterwerk, beste Qualität, super detailliert, 4k
Szene 2: Ming besiegt den Flammendrachen
Erstellen Sie eine Szene im Anime-Stil mit einem feurigen Krater im Hintergrund. Die Hauptfigur in der Szene ist Kotomine (ein menschlicher Junge mit einem tapferen Herzen, der ein Schwert in der Hand hält und ein einfaches Kriegerkostüm trägt), der im Moment des Sieges über einen flammenden Drachen steht. Die Felsen und die Lava im Krater sind detailliert dargestellt, und die feurige rote Beleuchtung vermittelt Wildheit und Mut. Qualität: Meisterwerk, beste Qualität, super detailliert, 4k
Szene 3: Ming kämpft gegen den Dunklen Lord!
Erstellen Sie eine Szene im Anime-Stil mit einem schattigen Monsterversteck im Hintergrund. Die Hauptfigur in der Szene ist Ming (ein menschlicher Junge mit einem tapferen Herzen, einem Schwert in der Hand und einem einfachen Kriegerkostüm), der sich mitten in einem erbitterten Kampf mit dem Dunklen Lord befindet. Es enthält Details der Dunkelheit und der magischen Energie des Verstecks, und die düstere Beleuchtung vermittelt Intensität und Spannung. Qualität: Meisterwerk, beste Qualität, super detailliert, 4k
Szene 4: Ming rettet die Prinzessin
Erstellen Sie eine Szene im Anime-Stil mit dem Inneren eines verlassenen Schlosses im Hintergrund. Die Hauptfiguren in der Szene sind Ming (ein menschlicher Junge mit einem tapferen Herzen, der ein Schwert hält und ein einfaches Kriegerkostüm trägt) und die Prinzessin (eine menschliche Frau, schön und elegant, die ein prächtiges Prinzessinnenkostüm trägt), die sich in der herzerwärmenden Szene der Rettung der Prinzessin durch Ming befinden. Die Details der Burgruinen im Inneren und die schummrige Beleuchtung vermitteln Rührung und Erlösung. Qualität: Meisterwerk, beste Qualität, super detailliert, 4k
C. Unterstützung für Chinesisch und Englisch
In der technischen Umsetzung schaltet CogView4 den Text-Encoder von einem rein englischen T5-Encoder auf einen zweisprachigen GLM-4-Encoder um und wird mit zweisprachigen Grafikpaaren trainiert, so dass das CogView4-Modell in der Lage ist, zweisprachige Prompt-Wörter einzugeben.
Bisher ist CogView4 das erste Open-Source-Grafikmodell, das die zweisprachige Eingabe von Stichworten unterstützt und besonders gut chinesische Stichwörter versteht und befolgt sowie chinesische Schriftzeichen auf dem Bildschirm erzeugt. Diese beiden Funktionen eignen sich besser für eine Vielzahl kreativer Anforderungen in der heimischen Werbung, in Kurzvideos und anderen Bereichen.

IV. Apache-Protokoll
Das Modell CogView4-6B unterstützt das Apache2.0-Protokoll und wird später um ControlNet, ComfyUI und andere Öko-Unterstützung erweitert. Ein komplettes Toolkit für die Feinabstimmung wird bald verfügbar sein.
Modell Warehouse:
https://huggingface.co/THUDM/CogView4-6B
https://modelscope.cn/models/ZhipuAI/CogView4-6B
aktualisiert CogView4 Das Modell wird am 13. März auf chatglm.cn freigeschaltet.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel

Keine Kommentare...