
Empfohlene 12 kostenlose Software für digitale Mitarbeiter für den lokalen Einsatz

Im Zuge der rasanten Entwicklung der KI sind digitale Menschen (Digital Humans) ausgereift und können schnell und kostengünstig erzeugt werden. Aufgrund des breiten Spektrums an kommerziellen Anwendungsszenarien hat sie viel Aufmerksamkeit erhalten. Ob in der virtuellen Realität (VR), der erweiterten Realität (AR) oder in der Film- und Fernsehproduktion, der Spieleentwicklung und der Markenwerbung - digitale Menschen spielen eine wichtige Rolle.
Im Großen und Ganzen gibt es digitale Menschen mit 3D-Modellierung (einschließlich Motion Capture), digitale Menschen mit statischen 2D-Bildern (einschließlich echter Menschen) und digitale Menschen mit echten Gesichtern, die ausgetauscht werden.
Dieses Papier konzentriert sich auf das persönliche Bild Klonen Bild Klasse digitaler Mensch, gehört zu den statischen 2D-Bild digitaler Mensch, enthält drei grundlegende Funktion Punkte: reales Bild, Stimme Klonen, Mund Synchronisation.
Hinweis 1: Einige Projekte enthalten keine Stimme Generation (Klonen) Teil, das ist nicht der Punkt, bitte können separat eingesetzt werden, hat der Markt viele ausgezeichneteAI-Projekt zum Klonen von Stimmen.
Hinweis 2: Die Qualität der statischen 2D-Figuren variiert derzeit vor allem in der Synchronisation ihrer Münder und der Natürlichkeit ihrer "Videobewegungen". Sie können versuchen, dies separat zu optimierenLippensynchronisationKnotenpunkte.
Hinweis 3: Das Klonen von Gesichtern und Stimmen ist ebenfalls eine schnelle Methode zur Erzeugung einer digitalen Person, die geeignet ist, das Bild und die Stimme von Rednern unverändert zu erhalten, und in den folgenden Programmen nicht enthalten ist. Die fortschrittliche universelle Video-Face-Swapping-Technologie ist riskant, wenn sie populär wird, und wird daher nicht vorgestellt.
AIGCPanel: Open-Source-Klon des digital man-Integrationssystems, Bereitstellung des kostenlosen digital man-Clients mit einem Klick
AigcPanel ist ein One-Stop-KI-System für die Produktion digitaler Menschen für alle Benutzer, das mit dem Technologie-Stack electron+vue3+typescript entwickelt wurde und eine Ein-Klick-Bereitstellung auf dem Windows-System unterstützt. Das System ist so konzipiert, dass es im Kern benutzerfreundlich ist, so dass auch Benutzer mit einer schwachen technischen Grundlage es leicht beherrschen können. Zu den Hauptfunktionen gehören die digitale Videosynthese, die Sprachsynthese, das Klonen von Sprache usw., und es bietet perfekte lokale Modellverwaltungsfunktionen. Das System unterstützt eine mehrsprachige Schnittstelle (einschließlich vereinfachtes Chinesisch und Englisch) und integriert MuseTalk, cosyvoice und andere Ein-Klick-Startpakete für mehrere ausgereifte Modelle. Besonders erwähnenswert ist, dass das System die Technologie zum Abgleich von Videobildern und Stimmtranskription für die Videosynthese unterstützt und umfangreiche Optionen zur Einstellung der Tonparameter für die Sprachsynthese bietet. Als Open-Source-Projekt wird AigcPanel auf der Grundlage des AGPL-3.0-Protokolls veröffentlicht, wobei der Schwerpunkt auf der gesetzeskonformen Nutzung liegt und die Verwendung für illegale und unerlaubte Geschäfte ausdrücklich untersagt wird.

DUIX: Intelligente digitale Menschen für Echtzeit-Interaktion, die eine plattformübergreifende Bereitstellung mit einem Mausklick unterstützen
DUIX (Dialogue User Interface System) ist eine von Silicon Intelligence entwickelte KI-gesteuerte Plattform für digitale menschliche Interaktion. Mit Open-Source-Funktionen für die digitale menschliche Interaktion können Entwickler einfach groß angelegte Modelle, automatische Spracherkennung (ASR) und Text-to-Speech-Funktionen (TTS) integrieren, um eine Echtzeit-Interaktion mit digitalen Menschen zu erreichen. DUIX unterstützt die Bereitstellung auf mehreren Plattformen wie Android und iOS mit nur einem Klick und macht es jedem Entwickler leicht, intelligente und personalisierte digitale menschliche Agenten zu erstellen, die in verschiedenen Branchen eingesetzt werden können. Mit niedrigen Bereitstellungskosten, geringer Netzwerkabhängigkeit und vielfältigen Funktionen kann die Plattform die Anforderungen verschiedener Branchen wie Video, Medien, Kundenservice, Finanzen, Radio und Fernsehen erfüllen.

EchoMimic: Audiogesteuerte realistische Porträtanimation
EchoMimic ist ein Open-Source-Projekt zur Erzeugung realistischer Porträtanimationen, die durch Audio gesteuert werden. Das von der Abteilung Terminal Technologies der Ant Group entwickelte Projekt nutzt editierbare Markerpunktbedingungen, um dynamische Porträtvideos zu generieren, die Audio- und Gesichtsmarkerpunkte kombinieren. EchoMimic wurde umfassend mit mehreren öffentlichen und proprietären Datensätzen verglichen und hat seine überlegene Leistung sowohl in quantitativen als auch in qualitativen Bewertungen bewiesen.
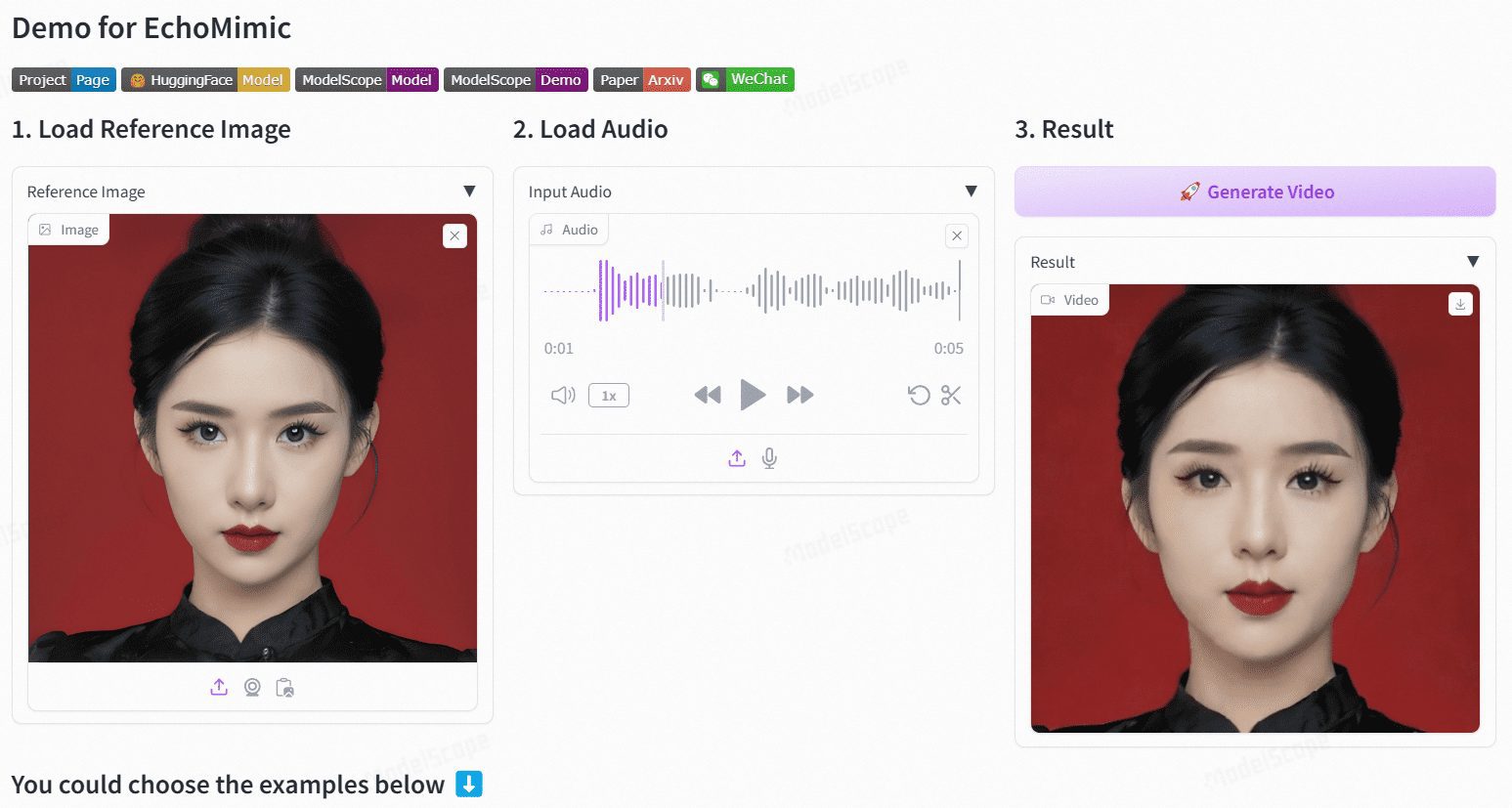
Sonic: Eine neue Open-Source-Lösung für digitale Menschen, audiogestützte Erzeugung digitaler mündlicher Videos mit lebendiger Mimik
Sonic Sonic ist eine innovative Plattform, die sich auf die globale Audiowahrnehmung konzentriert und darauf ausgelegt ist, lebendige Porträtanimationen zu erzeugen, die durch Audio gesteuert werden. Die von einem Forscherteam von Tencent und der Universität Zhejiang entwickelte Plattform nutzt Audioinformationen zur Steuerung von Gesichtsausdrücken und Kopfbewegungen, um natürliche, flüssige Animationsvideos zu erzeugen.Zu den Kerntechnologien von Sonic gehören kontextverbessertes Audio-Lernen, bewegungsentkoppelte Controller und ein zeitbewusstes Modul zur Positionsverschiebung. Diese Technologien ermöglichen es Sonic, stabile und realistische Langform-Videos mit unterschiedlichen Bildstilen und verschiedenen Arten von Audio-Inputs zu erzeugen.
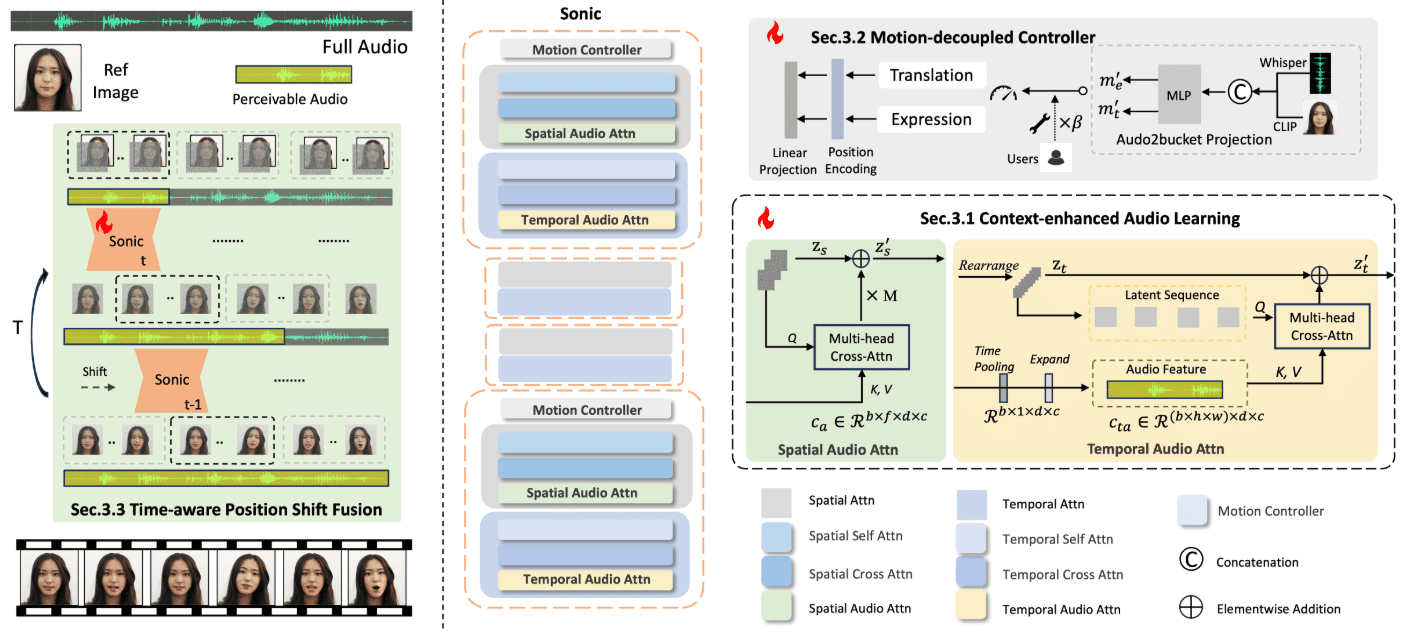
Hallo2: Audio-gesteuerte Erzeugung von lippensynchronen/ausdrucks-synchronen Porträtvideos (mit Windows-Ein-Klick-Installation)
Hallo2 ist ein Open-Source-Projekt, das gemeinsam von der Fudan-Universität und Baidu entwickelt wurde, um hochauflösende Porträtanimationen durch audiogesteuerte Generierung zu erzeugen. Das Projekt nutzt fortschrittliche Generative Adversarial Networks (GAN) und Techniken zur zeitlichen Ausrichtung, um eine 4K-Auflösung und eine Videogeschwindigkeit von bis zu einer Stunde zu erreichen. Hallo2 unterstützt auch Textaufforderungen, um die Vielfalt und Kontrollierbarkeit der generierten Inhalte zu verbessern.
VideoChat: sprachinteraktive digitale Person in Echtzeit mit benutzerdefinierten Bild- und Tonklonen, die End-to-End-Sprachlösungen und kaskadierende Lösungen unterstützen
VideoChat ist ein digitales Echtzeit-Sprachinteraktionsprojekt, das auf Open-Source-Technologie basiert und End-to-End-Sprachschemata (GLM-4-Voice - THG) und Kaskadenschemata (ASR-LLM-TTS-THG) unterstützt. Das Projekt ermöglicht es den Benutzern, das Bild und die Klangfarbe des digitalen Menschen anzupassen, und unterstützt das Klonen von Klangfarben und Lippensynchronisation, Video-Streaming-Ausgabe und eine Latenzzeit für das erste Paket von nur 3 Sekunden. Die Benutzer können die Funktionalität durch Online-Demos erleben oder sie mit Hilfe der ausführlichen technischen Dokumentation lokal einsetzen und verwenden.
TalkingAvatar: KI-Avatar-Videoplattform zur Erstellung und Bearbeitung von KI-Avataren, basierend auf dem nativen arithmetischen Windows-Client
TalkingAvatar ist eine führende KI-Avatar-Plattform, die eine komplette KI-Lösung für digitale Personen anbietet. Sie bietet Nutzern eine revolutionäre Möglichkeit, Videoinhalte zu erstellen, zu bearbeiten und zu personalisieren. Mit fortschrittlicher KI-Technologie können Nutzer Videos einfach umschreiben, Stimmen klonen, Lippen synchronisieren und individuelle Videos erstellen. Egal, ob es darum geht, ein bestehendes Video neu zu vertonen oder eine neue Geschichte von Grund auf zu kreieren, TalkingAvatar hat die Lösung für Sie.

SadTalker: Fotos zum Sprechen bringen | Mouth Sync Audio | Synthesised Mouth Sync Video | Free Digital People
SadTalker ist ein Open-Source-Tool, das ein einzelnes Porträtfoto mit einer Audiodatei kombiniert, um realistische Videos mit sprechenden Köpfen für eine Vielzahl von Szenarien zu erstellen, z. B. für personalisierte Nachrichten, Bildungsinhalte und mehr. Der revolutionäre Einsatz von 3D-Modellierungstechnologien wie ExpNet und PoseVAE zeichnet sich durch die Erfassung von subtilen Gesichtsausdrücken und Kopfbewegungen aus. Benutzer können die SadTalker-Technologie sowohl für persönliche als auch für kommerzielle Projekte wie Nachrichten, Unterricht oder Marketing verwenden.

AniPortrait: Audio-gesteuerte Bild- oder Videobewegung zur Erzeugung realistischer digitaler Videos mit menschlicher Sprache
AniPortrait ist ein innovatives Framework zur Erzeugung realistischer Porträtanimationen auf der Grundlage von Audio. AniPortrait wurde von Huawei, Zechun Yang und Zhisheng Wang vom Tencent Game Know Yourself Lab entwickelt und ist in der Lage, hochwertige Animationen aus Audio- und Referenzporträtbildern zu erzeugen.Video für die Nachstellung von Gesichtern bereitstellen. Durch den Einsatz fortschrittlicher 3D-Zwischendarstellungen und 2D-Gesichtsanimationstechniken ist das Framework in der Lage, natürliche und sanfte Animationseffekte für eine Vielzahl von Anwendungsszenarien wie Film- und Fernsehproduktionen, virtuelle Moderatoren und digitale Menschen zu erzeugen.

MuseV+Muse Talk: Komplettes digitales menschliches Videogenerierungs-Framework | Portrait zu Video | Pose zu Video | Lippensynchronisation
MuseV ist ein öffentliches Projekt auf GitHub, das auf die Erzeugung von Avatar-Videos von unbegrenzter Länge und hoher Wiedergabetreue abzielt. Es basiert auf der Diffusionstechnologie und bietet verschiedene Funktionen wie Image2Video, Text2Image2Video, Video2Video und mehr. Details der Modellstruktur, Anwendungsfälle, Schnellstartanleitung, Inferenzskripte und Danksagungen werden bereitgestellt.

DreamTalk: Erzeugen Sie ausdrucksstarke Sprechvideos mit einem einzigen Avatarbild!
DreamTalk ist ein diffusionsmodellgesteuertes System zur Erzeugung ausdrucksstarker Sprecherköpfe, das gemeinsam von der Tsinghua-Universität, der Alibaba-Gruppe und der Huazhong-Universität für Wissenschaft und Technologie entwickelt wurde. Es besteht aus drei Hauptkomponenten: einem Netzwerk zur Rauschunterdrückung, einem Lippenexperten und einem Stilprädiktor. Es ist in der Lage, vielfältige und realistische Sprecherköpfe auf der Grundlage von Audioeingaben zu erzeugen. Das System ist in der Lage, mehrsprachige und verrauschte Audiodaten zu verarbeiten und liefert qualitativ hochwertige Gesichtsbewegungen und eine genaue Mundsynchronisation.

Translation Starter: Open-Source-Tool für die Synchronisation von Videoinhalten | Sprachkonvertierung | Lippensynchronisation
Translation Starter ist ein Open-Source-Projekt, das von Sync Labs entwickelt wurde, um Entwicklern zu helfen, schnell mehrsprachige Unterstützung für Videoinhalte zu integrieren. Es bietet die notwendigen APIs und Dokumentationen für Entwickler, um Anwendungen zu erstellen, die Videoübersetzung mit Lippensynchronisation erfordern. Es basiert auf leistungsstarken KI-Technologien wie der Perfect Lip Sync von Sync Labs, der Whisper Translation Technology von Open AI und der Sound Synthesis von Eleven Labs.

© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...