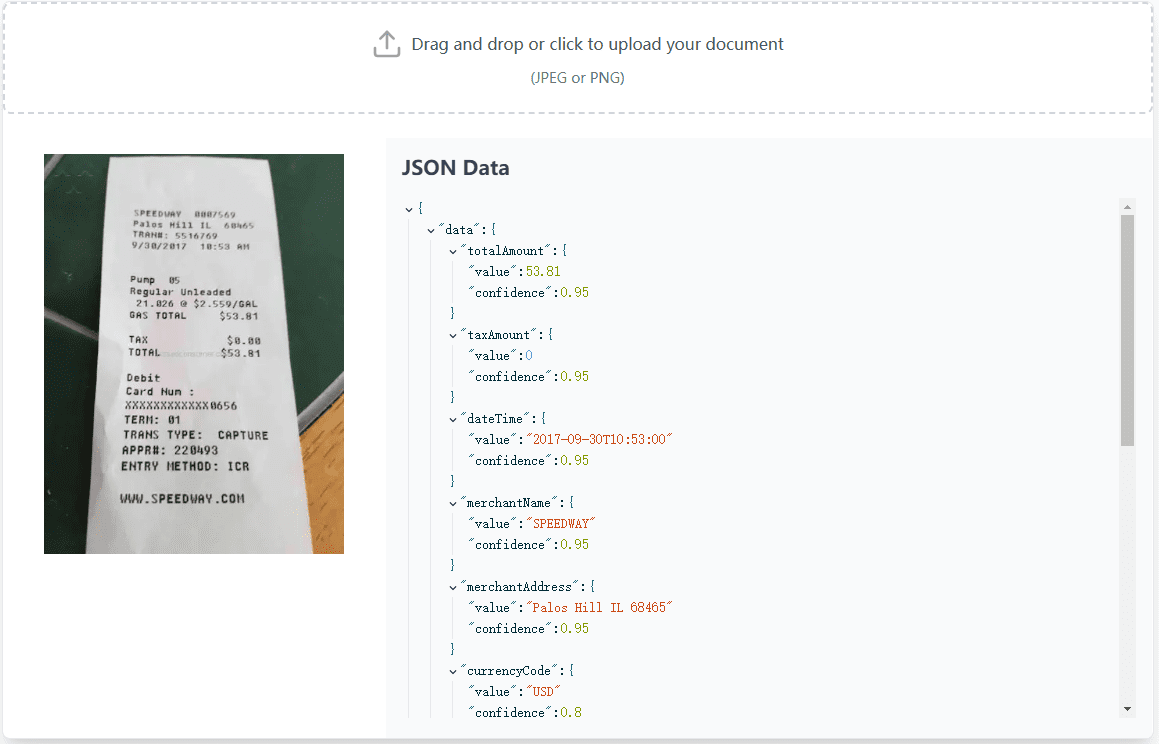
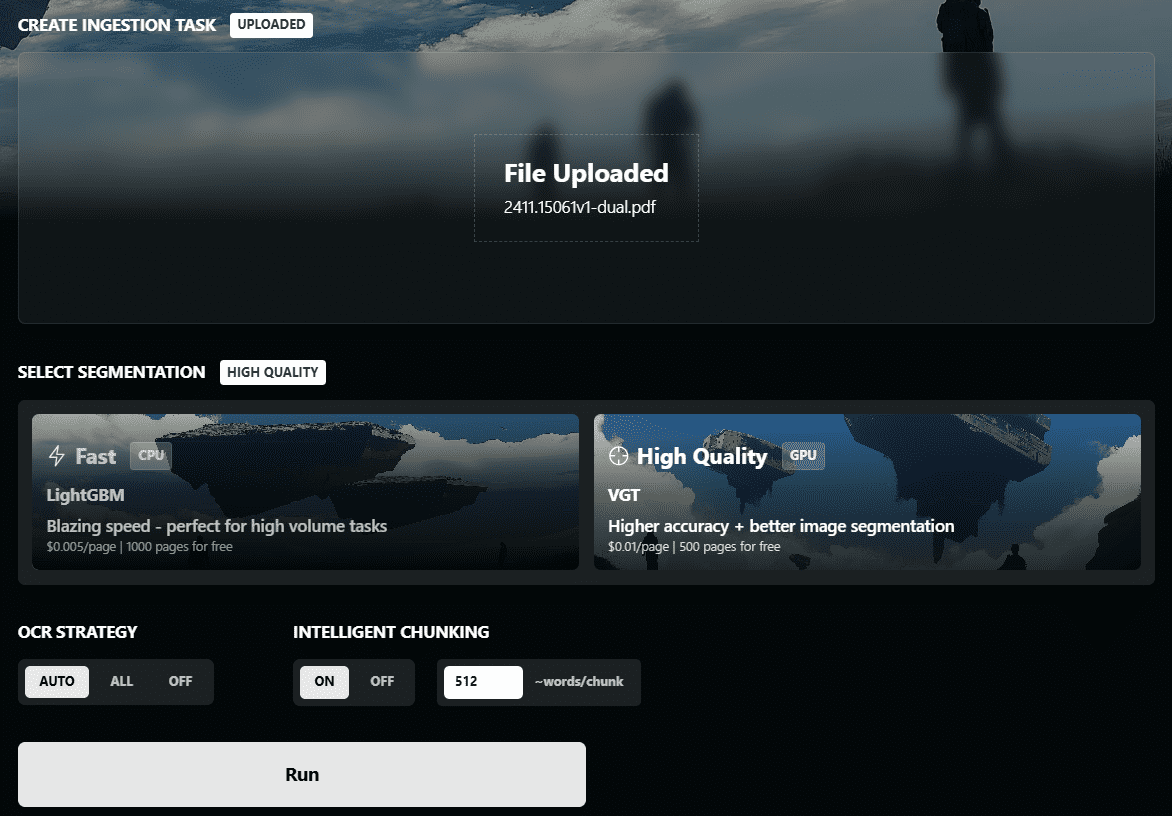
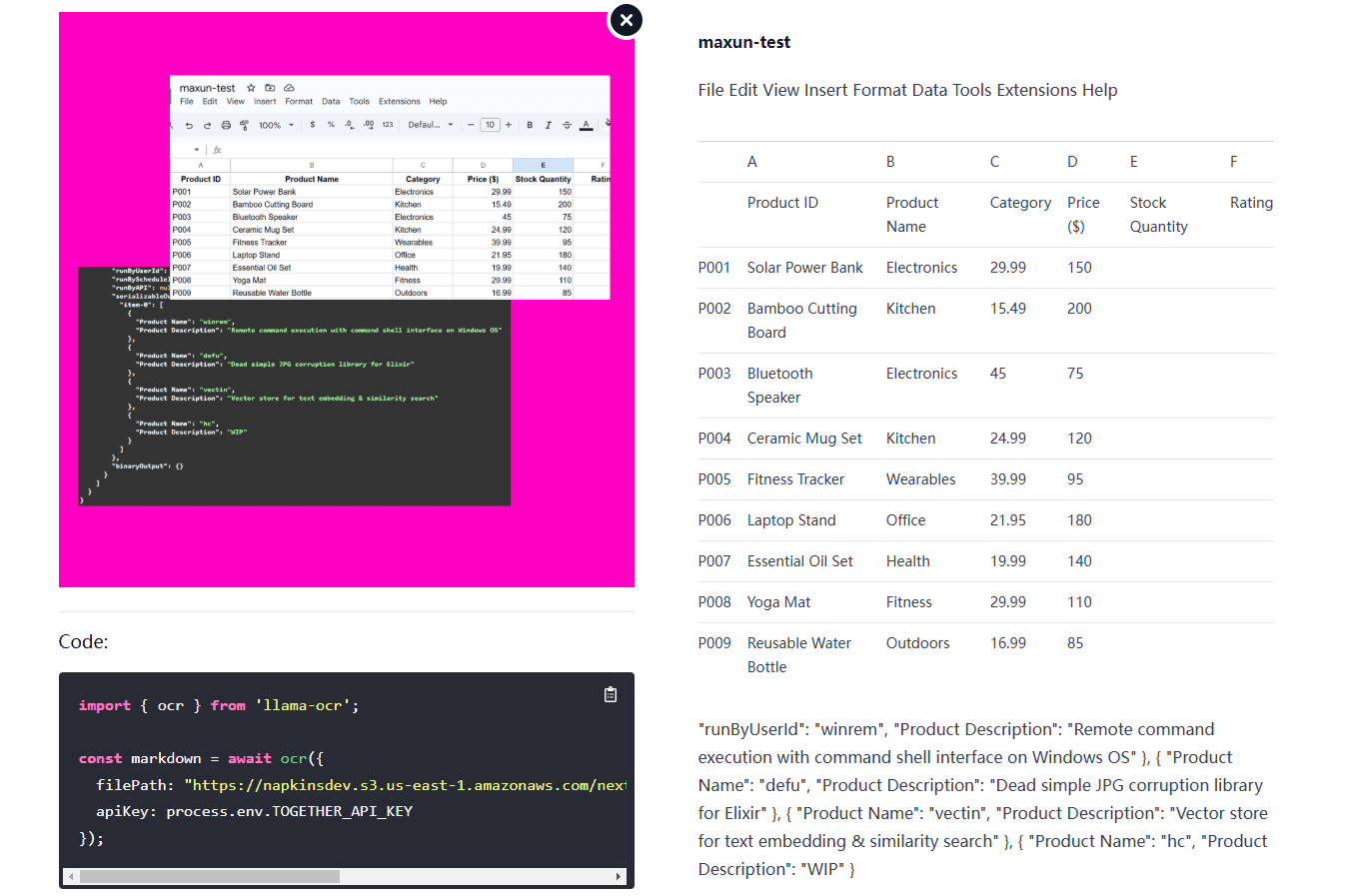
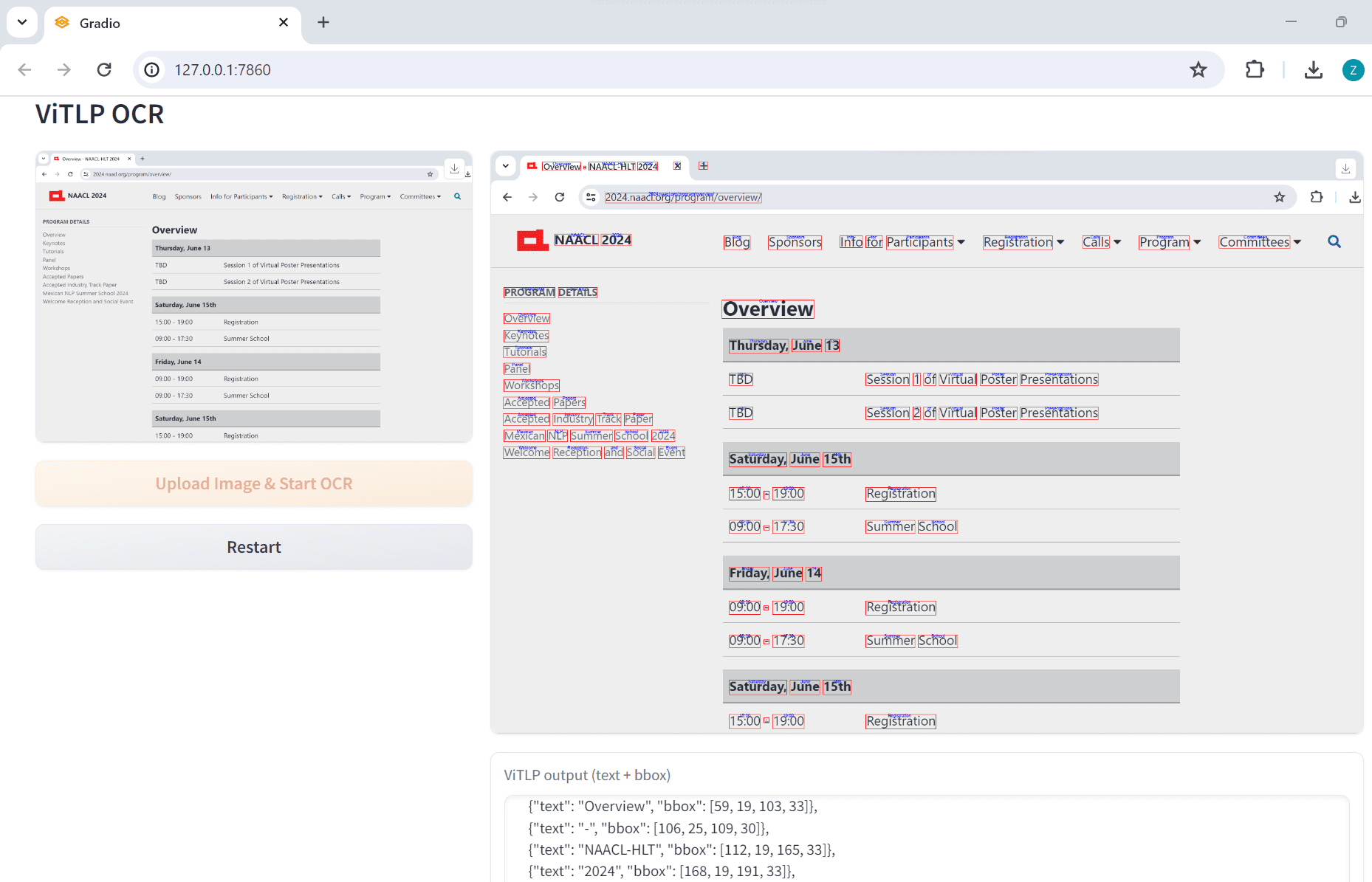
VOP: OCR-Tool zum Extrahieren komplexer Diagramme und mathematischer Formeln
Umfassende Einführung Das Versatile OCR Program ist ein Open-Source-Tool zur optischen Zeichenerkennung (OCR), das für die Arbeit mit komplexen akademischen und Bildungsdokumenten entwickelt wurde. Es kann Text, Tabellen, mathematische Formeln, Diagramme und Schemata aus PDFs, Bildern und anderen Dokumenten extrahieren und...