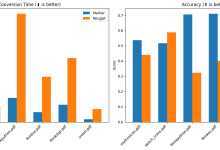
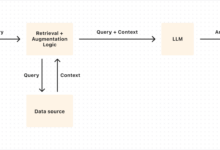
Allgemeine Einführung Chonkie ist eine leichtgewichtige und effiziente RAG (Retrieval-Augmented Generation) Text Chunking-Bibliothek, die Entwicklern helfen soll, Text schnell und einfach zu chunking. Die Bibliothek unterstützt eine Vielzahl von Chunking-Methoden, einschließlich Chunking auf Basis von Token, Wörtern, Sätzen und semantischer Ähnlichkeit...
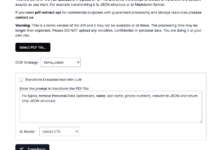
Umfassende Einführung TextIn ist ein professionelles PDF to Markdown-Tool, das Benutzern hilft, PDF-Dokumente effizient in das Markdown-Format zu konvertieren. Das Tool unterstützt eine Vielzahl von Dateiformaten, ist einfach zu bedienen, hat eine hohe Konvertierungsgeschwindigkeit und die Fähigkeit, das ursprüngliche PDF-Format und den Inhalt beizubehalten, um die Effizienz der Dokumentenverarbeitung zu verbessern. Ob es sich um ein ...
Aktivieren Sie Builder intelligenten Programmiermodus, unbegrenzte Nutzung von DeepSeek-R1 und DeepSeek-V3, reibungslosere Erfahrung als die Übersee-Version. Geben Sie einfach die chinesischen Befehle, keine Programmierkenntnisse können auch Null-Schwelle, um ihre eigenen Anwendungen zu schreiben.
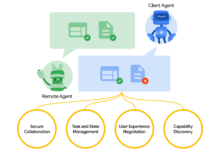
Allgemeine Beschreibung Die Textextraktions-API (text-extract-api) ist ein leistungsfähiges Tool zum Extrahieren und Parsen von Inhalten aus einer Vielzahl von Dokumentformaten (z.B. PDF, Word, PPTX, etc.). Die API nutzt modernste OCR-Technologie (Optical Character Recognition) und Ollama-unterstützte Modelle, um jedes beliebige Dokument oder Bild zu...
Umfassende Einführung Datalab bietet eine Reihe von fortschrittlichen KI-Modellen mit Schwerpunkt auf OCR, Layout-Analyse, PDF zu Markdown und mehr. Diese Modelle sind nicht nur sehr leistungsfähig, sondern auch einfach zu bedienen und quelloffen. Die Marker-Modelle auf der Plattform können PDF schnell und präzise in Markdown konvertieren, einschließlich Tabellen...
Umfassende Einführung MinerU ist ein Open-Source-Tool zur Datenextraktion, das vom OpenDataLab-Team am Shanghai Artificial Intelligence Lab entwickelt wurde und sich auf die effiziente Extraktion von Inhalten aus komplexen PDF-Dokumenten, Webseiten und eBooks konzentriert. Es kann multimodale PDF-Dokumente, die Bilder, Formeln, Tabellen und andere Elemente enthalten, in einfach zu analysierende M...
Allgemeine Einführung Marker ist ein auf Deep Learning basierendes Tool zur Dokumentenverarbeitung, das PDF-Dateien schnell und präzise in das Markdown-Format konvertiert. Es unterstützt eine breite Palette von Dokumenttypen und ist besonders für die Konvertierung von Büchern und wissenschaftlichen Arbeiten optimiert.Marker ist in der Lage, überflüssige Inhalte wie Kopf- und Fußzeilen zu entfernen, Tabellen zu formatieren und...
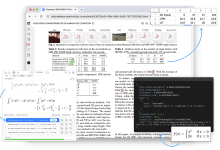
Allgemeine Beschreibung Mathpix ist ein leistungsstarkes, KI-gesteuertes Werkzeug zur Automatisierung von Dokumenten, das für Forscher, Entwickler und Unternehmen entwickelt wurde. Es wandelt PDFs und Bilder schnell und präzise in durchsuchbaren, exportierbaren und maschinenlesbaren Text um. Mathpix bietet eine breite Palette von Funktionen, einschließlich der Erkennung mathematischer Formeln, LaT...
Umfassende Einführung Unstructured-IO bietet eine Reihe von Open-Source-Komponenten für die Verarbeitung und Vorverarbeitung von Bildern und Textdokumenten wie PDF, HTML, Word-Dokumente, usw. Unstructured-IO bietet eine Reihe von Open-Source-Komponenten für die Verarbeitung und Vorverarbeitung von Bildern und Textdokumenten wie PDF, HTML, Word-Dokumente, usw. Sein Hauptziel ist es, Datenverarbeitungs-Workflows zu vereinfachen und zu optimieren, insbesondere für große Sprachmodell (LLM)-Anwendungen zu unterstützen.Unstructured...
Umfassende Einführung Jina AI's Reader-Projekt ist ein Open-Source-Tool (Reader Open-Source-Adresse), kann jede URL, indem Sie das Präfix https://r.jina.ai/转换成适合大型语言模型 (Large Language Models, LLM) Eingabeformat, Unterstützung für dynamische Streaming-Modus und Bild lesen...
Sie können keine AI-Tools finden? Versuchen Sie es hier!
Geben Sie einfach das Schlüsselwort Barrierefreiheit Bing-SucheDer Bereich KI-Tools auf dieser Website bietet eine schnelle und einfache Möglichkeit, alle KI-Tools auf dieser Website zu finden.