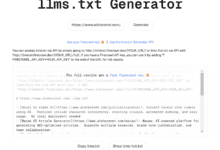
Umfassende Einführung llmstxt-generator ist ein professionelles Tool zur Extraktion und Integration von Webinhalten, das hochwertige Textdatensätze für das Training und die Inferenz in Large Language Modelling (LLM) vorbereitet. Das von Mendable AI entwickelte Tool nutzt die von @firecrawl_dev bereitgestellte Web-Crawling-Technologie und GPT-4-mini ...
Umfassende Einführung Doc2X ist ein leistungsfähiges Dokument Bild Formel Erkennung und Konvertierung Tools, ist verpflichtet, effiziente und intelligente Lösungen für die Dokumentenverarbeitung zu bieten. Egal, ob es sich um eine akademische Forschungsarbeit, ein Lehrbuch, ein Unternehmensdokument oder einen Finanzbericht handelt, Doc2X kann die Tabellen und Formeln im PDF genau erkennen und sie mit einer Taste konvertieren...
Aktivieren Sie Builder intelligenten Programmiermodus, unbegrenzte Nutzung von DeepSeek-R1 und DeepSeek-V3, reibungslosere Erfahrung als die Übersee-Version. Geben Sie einfach die chinesischen Befehle, keine Programmierkenntnisse können auch Null-Schwelle, um ihre eigenen Anwendungen zu schreiben.
Umfassende Einführung ExtractThinker ist ein flexibles Dokument-Intelligence-Tool, das Large Language Models (LLMs) verwendet, um strukturierte Daten aus Dokumenten zu extrahieren und zu klassifizieren und einen nahtlosen ORM-ähnlichen Dokumentenverarbeitungs-Workflow zu bieten. Es unterstützt mehrere Dokumentenlader, einschließlich Tesseract OCR, Azure Form Recog...
Umfassende Einführung HtmlRAG ist ein innovatives Open-Source-Projekt, das sich auf die Verbesserung der Verarbeitung von HTML-Dokumenten in Retrieval Augmented Generation (RAG)-Systemen konzentriert. Das Projekt schlägt einen neuartigen Ansatz vor, dass die Verwendung von HTML-Formatierung in RAG-Systemen effizienter ist als reiner Text. Das Projekt umfasst einen kompletten Datenverarbeitungsfluss von der Cha...
Umfassende Einführung ScrapeGraphAI ist eine innovative Python-Bibliothek für Web-Scraping, die auf geschickte Weise Large Language Modelling (LLM) und Direct Graph Logic kombiniert, um Scraping-Pipelines für Websites und lokale Dokumente zu erstellen. Die Einzigartigkeit dieses Tools liegt in der perfekten Balance aus Einfachheit und Leistung: Der Benutzer beschreibt einfach, was er/sie erwähnen möchte...
Umfassende Einführung Vision Parse ist ein revolutionäres Werkzeug zur Dokumentenverarbeitung, das auf intelligente Weise modernste Technologie für visuelle Sprachmodelle (Vision Language Models) kombiniert, um PDF-Dokumente auf intelligente Weise in hochwertige Inhalte im Markdown-Format zu konvertieren. Das Tool unterstützt eine Vielzahl von erstklassigen visuellen Sprachmodellen, darunter o...
Allgemeine Einführung Outlines ist eine Open-Source-Bibliothek, die von dottxt-ai entwickelt wurde, um die Anwendung von Large Language Models (LLMs) durch strukturierte Textgenerierung zu verbessern. Die Bibliothek unterstützt eine Vielzahl von Modellintegrationen, einschließlich OpenAI, Transformatoren, llama.cpp, usw. Sie bietet einfache, aber leistungsfähige...
Allgemeine Einführung MarkItDown ist ein von Microsoft entwickeltes Python-Tool, mit dem verschiedene Dateien und Office-Dokumente in das Markdown-Format konvertiert werden können. Das Tool unterstützt eine breite Palette von Dateitypen, darunter PDF, PowerPoint, Word, Excel, Bilder (EXIF-Metadaten und OCR), Audio (EXIF-Metadaten und Sprache)...
Umfassende Einführung Chunkr ist eine selbst gehostete API zur Konvertierung von PDF-, PPTX-, DOCX- und Excel-Dateien in Daten, die für die Verwendung in RAG (Retrieval Augmented Generation) und LLM (Large Language Modelling) geeignet sind. Sie wurde von Lumina AI Inc. entwickelt und verwendet fortschrittliche visuelle Modelle für die Aufnahme von Dokumenten...
Allgemeine Einführung GitIngest ist ein Open-Source-Tool, das entwickelt wurde, um GitHub-Code-Repositories in Text umzuwandeln, der für Large Language Model (LLM)-Hinweise geeignet ist. Mit einem einfachen Vorgang können Benutzer den Inhalt jedes GitHub-Repositorys in einen für LLM geeigneten Text extrahieren und formatieren. Das Tool bietet eine Ein-Klick-Analyse...
Allgemeine Einführung E2M (Everything to Markdown) ist eine Open-Source-Python-Bibliothek zur Konvertierung einer breiten Palette von Dateiformaten in das Markdown-Format. Das Tool unterstützt eine breite Palette von Dateitypen, einschließlich doc, docx, epub, html, htm, url, pdf, ppt, pptx, mp3 und m4a.E2M verwendet...
Umfassende Einführung Docling ist ein leistungsfähiges Tool zum Parsen und Exportieren von Dokumenten, das eine Vielzahl von Dokumentenformaten unterstützt, darunter PDF, DOCX, PPTX, XLSX, Image, HTML, AsciiDoc und Markdown, und diese Dokumente in die Formate HTML, Markdown und JSON parsen und exportieren kann.
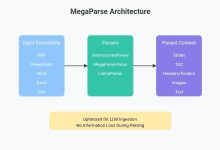
Allgemeine Einführung MegaParse ist ein leistungsfähiges und vielseitiges Tool zum Parsen von Dokumenten, das zur Optimierung der Datenverarbeitung für das Large Language Model (LLM) entwickelt wurde. Ob Sie mit Text, PDF, PowerPoint-Präsentationen oder Word-Dokumenten arbeiten, MegaParse macht es Ihnen leicht und stellt sicher, dass der Parsing-Prozess nicht...
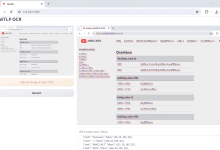
Umfassende Einführung ViTLP (Visually Guided Generative Text-Layout Pre-training for Document Intelligence) ist ein Open-Source-Projekt, das darauf abzielt, die Verarbeitung von Dokumentenintelligenz durch visuell geführte generative Text-Layout Pre-training Modelle zu verbessern. Das Projekt wurde von Veason-silverbul entwickelt...
Allgemeine Einführung Trieve ist eine allumfassende Infrastruktur, die von Devflow, Inc. entwickelt wurde und für Suche, Empfehlungen, RAG (Retrieval Augmented Generation) und Analysen konzipiert ist. Die Plattform wird über eine API bereitgestellt, unterstützt Self-Hosting und ist für Umgebungen wie AWS, GCP, Kubernetes und Docker Compose verfügbar....
Umfassende Einführung pdf2htmlEX ist ein Open-Source-Tool entwickelt, um PDF-Dateien in HTML-Format zu konvertieren, durch die Analyse der Inhalte von PDF-Dateien und HTML + CSS verwenden, um genau seine visuelle Wirkung wiederherzustellen, können PDF-Dokumente in einem Browser direkt auf der Webseite angezeigt werden. Das Werkzeug ist besonders geeignet für eine große Anzahl von ...
Umfassende Einführung Maxun ist eine quelloffene No-Code-Webdatenextraktionsplattform, mit der Benutzer in wenigen Minuten Roboter trainieren können, um Webdaten automatisch zu crawlen und in APIs oder Tabellenkalkulationen zu konvertieren. Die Plattform unterstützt Paging und Scrolling, kann sich an Änderungen im Website-Layout anpassen, bietet leistungsstarke Daten-Crawling-Funktionen für...
Allgemeine Einführung OmniParse ist eine leistungsstarke Datenparsing- und Optimierungsplattform, die entwickelt wurde, um beliebige unstrukturierte Daten in strukturierte, verwertbare Daten zu verwandeln, die für das GenAI-Framework (Generative Artificial Intelligence) optimiert sind. Ob Sie mit Dokumenten, Tabellen, Bildern, Videos, Audiodateien oder Webinhalten arbeiten,...
Allgemeine Einführung Parsio ist ein KI-basiertes Tool zur Extraktion von Dokumenten und E-Mails, das automatisch strukturierte Daten aus PDFs, E-Mails und anderen Dokumenten extrahiert. Die Plattform bietet einen leistungsstarken PDF-Parser und OCR-Funktionen und unterstützt eine breite Palette von Dokumenttypen, darunter Rechnungen, Visitenkarten und Ausweise...
Sie können keine AI-Tools finden? Versuchen Sie es hier!
Geben Sie einfach das Schlüsselwort Barrierefreiheit Bing-SucheDer Bereich KI-Tools auf dieser Website bietet eine schnelle und einfache Möglichkeit, alle KI-Tools auf dieser Website zu finden.