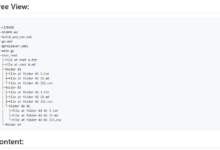
Allgemeine Einführung Markdownify MCP Server ist ein Open-Source-Tool, das auf dem Model Context Protocol basiert, auf GitHub gehostet wird und vom Entwickler Zach Caceres erstellt wurde. Es konzentriert sich auf die Kombination mehrerer Dateitypen (z.B. PDF, Bilder, Audio, Office-Dokumente, etc.) mit...
Allgemeine Einführung CodeWeaver ist ein Kommandozeilen-Tool, mit dem sich Code-Bibliotheken in einzelne, leicht zu navigierende Markdown-Dokumente einbinden lassen. Es erzeugt eine strukturierte Darstellung der Dateihierarchie eines Projekts, indem es Verzeichnisse rekursiv durchsucht und den Inhalt jeder Datei in Codeblöcke einbettet. Das Tool wurde mit dem Ziel entwickelt, die...
Aktivieren Sie Builder intelligenten Programmiermodus, unbegrenzte Nutzung von DeepSeek-R1 und DeepSeek-V3, reibungslosere Erfahrung als die Übersee-Version. Geben Sie einfach die chinesischen Befehle, keine Programmierkenntnisse können auch Null-Schwelle, um ihre eigenen Anwendungen zu schreiben.
Umfassende Einführung Kreuzberg ist eine Bibliothek zur Vereinfachung der Textextraktion aus PDF-Dateien, entwickelt, um eine einfache, problemlose Lösung für die Textextraktion zu bieten. Die Bibliothek eignet sich besonders für RAG-Dienste (Retrieval-Augmented Generation), die eine Textextraktion erfordern, und unterstützt den lokalen Betrieb, die einfache...
Umfassende Einführung Instructor ist eine beliebte Python-Bibliothek, die für die Verarbeitung strukturierter Ausgaben von Large Language Models (LLMs) entwickelt wurde. Sie basiert auf Pydantic und bietet eine einfache, transparente und benutzerfreundliche API für die Verwaltung von Datenvalidierung, Wiederholungen und Streaming-Antworten.
Umfassende Einführung zChunk ist eine neuartige Chunking-Strategie, die von ZeroEntropy entwickelt wurde, um eine Lösung für generisches semantisches Chunking zu bieten. Die Strategie basiert auf dem Llama-70B-Modell und optimiert den Chunking-Prozess eines Dokuments, indem sie die Generierung von Chunks anregt und so sicherstellt, dass ein hohes Signal-Rausch-Verhältnis beim Informationsabruf erhalten bleibt. zChunk ist besonders geeignet für...
Umfassende Einführung Pulse ist eine intelligente Plattform, die sich auf die Verarbeitung von Dokumenten und die Datenextraktion konzentriert. Sie wurde entwickelt, um Unternehmen und Entwickler bei der effizienten Analyse und Verarbeitung eines breiten Spektrums komplexer Dokumente zu unterstützen. Durch seine fortschrittliche Computer Vision und multimodale Verarbeitungstechnologie ist Pulse in der Lage, Dokumente aus Text, Bildern, Tabellen und anderen Formaten präzise zu verarbeiten...
Umfassende Einführung Rowfill ist eine Open-Source-Plattform zur Dokumentenverarbeitung, die für Wissensarbeiter entwickelt wurde. Sie nutzt fortschrittliche KI-Technologien, um Daten aus komplexen Dokumenten, Bildern und PDFs zu extrahieren, zu analysieren und zu verarbeiten. Rowfill unterstützt native Large Language Models (LLMs) und visuelle OpenAI-Modelle, um sicherzustellen, dass Daten...
Allgemeine Einführung PPTX2MD ist ein Open-Source-Tool, das entwickelt wurde, um PowerPoint PPTX-Dateien in das Markdown-Format zu konvertieren. Entwickelt von GitHub-Benutzer ssine, unterstützt das Tool die Beibehaltung von Überschriften, Listen, Textformatierung (wie fett, kursiv, Farben und Hyperlinks), Bilder und Tabellen in einer Vielzahl von Formaten.PPTX2MD...
Allgemeine Einführung Repomix (früher bekannt als Repopack) ist ein Open-Source-Tool, das entwickelt wurde, um eine gesamte Codebasis in eine einzige, KI-freundliche Datei zu packen. Mit diesem Tool können Entwickler ihre Codebasis auf einfache Weise großen Sprachmodellen (wie Claude, ChatGPT und Gemini) zur Analyse und Verarbeitung zur Verfügung stellen...
Allgemeine Einführung Yek ist ein schnelles Rust-basiertes Werkzeug zum Lesen von Textdateien aus Repositories oder Verzeichnissen, zum Chunking und zur Serialisierung für die Verwendung in Large Language Models (LLMs). Das Werkzeug verwendet standardmäßig die .gitignore-Regel, um nicht benötigte Dateien zu überspringen, und nutzt die Git-Historie, um wichtige Dateien zu ermitteln...
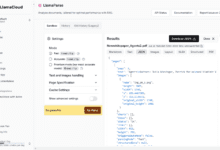
Allgemeine Einführung LlamaParse ist ein leistungsfähiges Dokument-Parsing-Tool, das komplexe Dokumente wie PDF-, PowerPoint-, Word-Dokumente und Tabellenkalkulationen verarbeiten und in strukturierte Daten umwandeln kann.LlamaParse bietet mehrere Möglichkeiten, es zu verwenden, einschließlich einer eigenständigen REST-API, Python-Pakete, TypeScr...
Umfassende Einführung UnDatas.IO ist eine Plattform, die sich auf das Parsing und die Verarbeitung unstrukturierter Daten konzentriert. Sie nutzt fortschrittliche Technologien zur automatischen Erkennung von Dokumentenlayouts und zur Klassifizierung von Tabellen, Bildern, Formeln und Text, wodurch der Datenverarbeitungsprozess erheblich vereinfacht wird. Die Plattform spart nicht nur viel Zeit bei der Datensortierung, sondern hilft auch...
Umfassende Einführung Zerox ist ein Open-Source-Projekt entwickelt, um PDF, DOCX, Bilder und andere Dokumente in Markdown-Format durch visuelle Modelle zu konvertieren. Das Projekt wird von getomni-ai Team entwickelt, bietet eine einfache und effiziente OCR (Optical Character Recognition) Lösung.Zerox unterstützt Node und Python Programmiersprachen, ...
Allgemeine Einführung SemHash ist ein leichtgewichtiges und flexibles Werkzeug für die Dataset-Deduplizierung durch semantische Ähnlichkeit. Es kombiniert die schnelle Einbettungsgenerierung von Model2Vec mit der effizienten ANN (Approximate Nearest Neighbour)-Ähnlichkeitssuche von Vicinity.SemHash unterstützt die Deduplizierung einzelner Datensätze (z.B. Bereinigung von...
Allgemeine Einführung Parseur ist eine führende KI-Datenextraktionssoftware, die Benutzern hilft, automatisch Textdaten aus PDFs, E-Mails und anderen Dokumenten zu extrahieren. Mit Parseur können Anwender auf einfache Weise unstrukturierte Daten in strukturierte Daten umwandeln und diese an verschiedene Anwendungen senden. Die Software ist weit verbreitet ...
Umfassende Einführung Weco AI Functions ist eine leistungsstarke Plattform, die Benutzern hilft, schnell AI-Funktionen zu erstellen und einzusetzen. Durch die einfache Beschreibung von Aufgaben können Benutzer strukturierte Ausgabemuster mit A/B-Tests und Beobachtungen erzeugen. Die Plattform unterstützt codefreies Prototyping, so dass auch nicht-technische Benutzer...
Umfassende Einführung NV Ingest (NVIDIA Ingest) ist eine Reihe von Microservices für den frühen Zugriff, die für das Parsen von Hunderttausenden von komplexen, unübersichtlichen unstrukturierten PDFs und anderen Unternehmensdokumenten entwickelt wurden. Sie kann diese Dokumente in Metadaten und Text umwandeln, um sie in Retrievalsysteme einzubetten....
Allgemeine Einführung Trellis ist eine Datenplattform, die sich auf die Umwandlung komplexer unstrukturierter Datenquellen in ein strukturiertes SQL-Format konzentriert. Dank seiner leistungsstarken KI-Engine kann Trellis eine Vielzahl von Datenquellen wie Finanzdokumente, Sprachanrufe und E-Mails verarbeiten und in SQL umwandeln, das von Daten- und Betriebsteams verwendet werden kann...
Umfassende Einführung Ollama OCR ist ein leistungsstarkes Toolkit für die optische Zeichenerkennung (OCR), das das hochmoderne visuelle Sprachmodell der Ollama-Plattform nutzt, um Text aus Bildern zu extrahieren. Das Projekt ist sowohl als Python-Paket als auch als benutzerfreundliche Streamlit-Webanwendungsschnittstelle verfügbar. Es unterstützt mehrere ...
Sie können keine AI-Tools finden? Versuchen Sie es hier!
Geben Sie einfach das Schlüsselwort Barrierefreiheit Bing-SucheDer Bereich KI-Tools auf dieser Website bietet eine schnelle und einfache Möglichkeit, alle KI-Tools auf dieser Website zu finden.