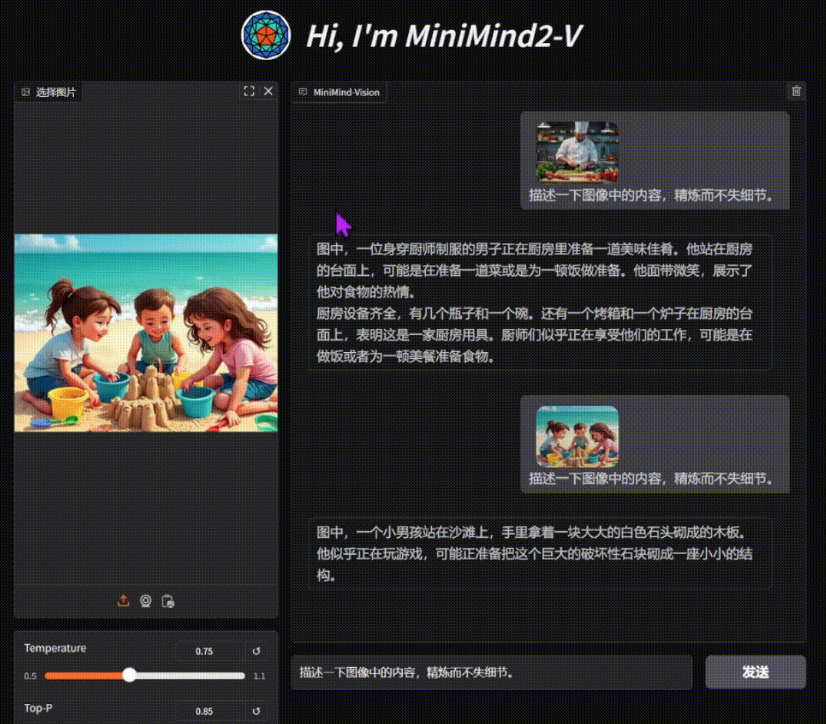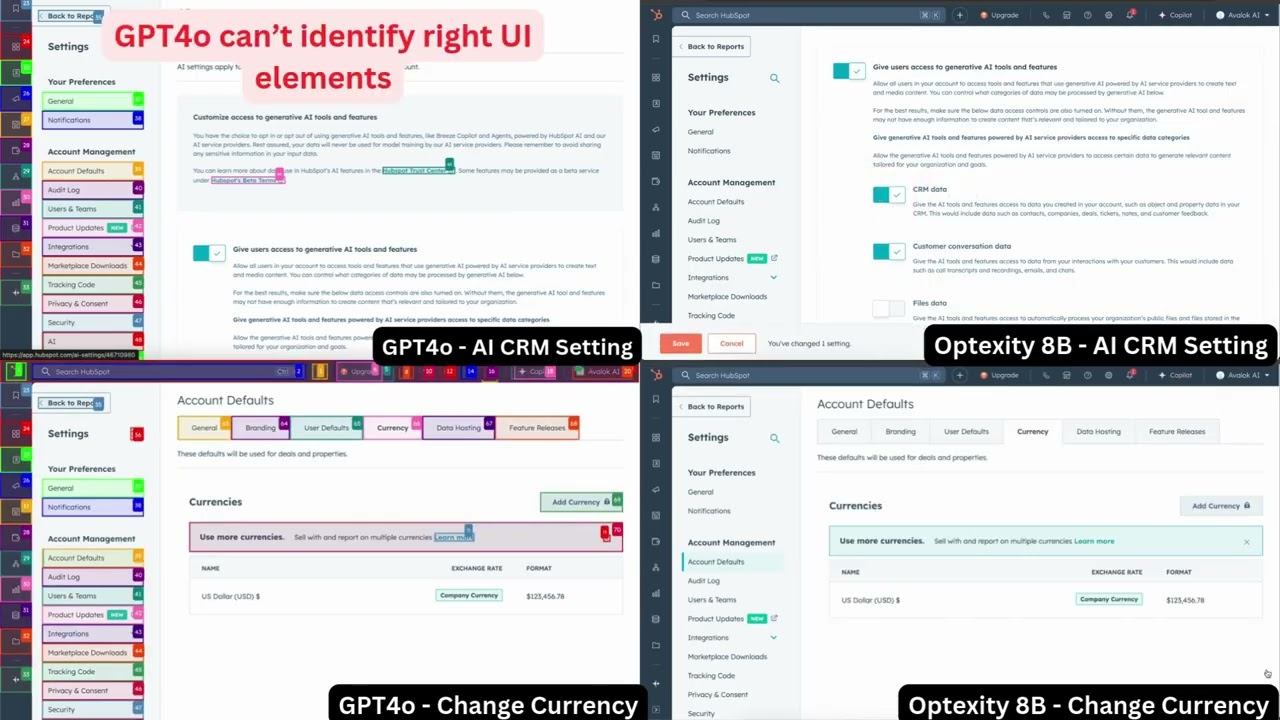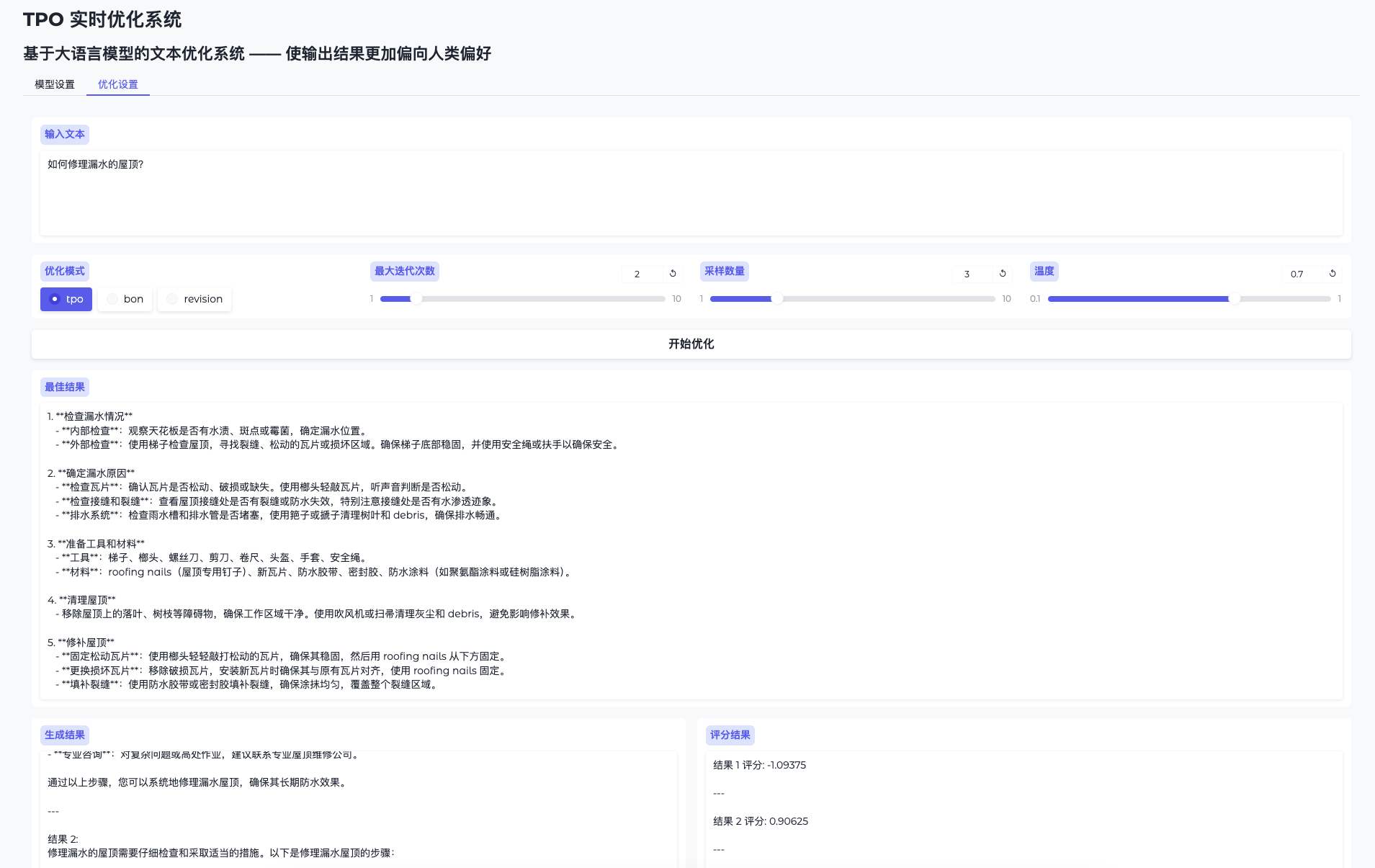
GraphGen: Feinabstimmung von Sprachmodellen mithilfe von Wissensgraphen zur Erzeugung synthetischer Daten
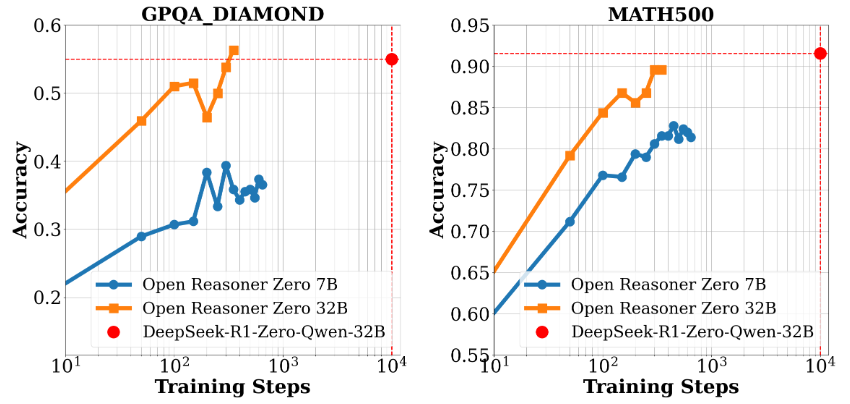
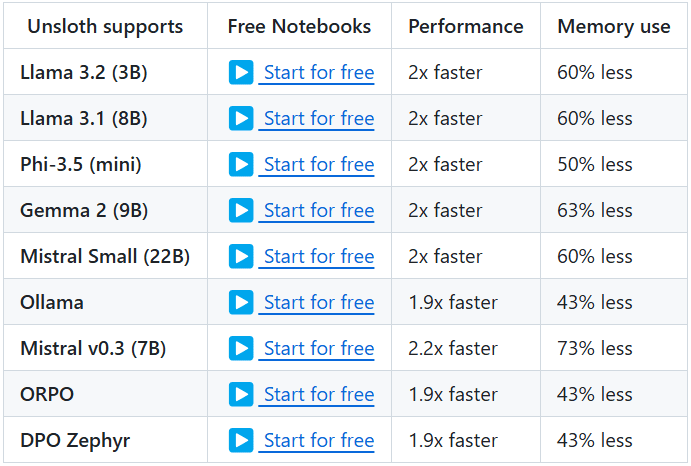
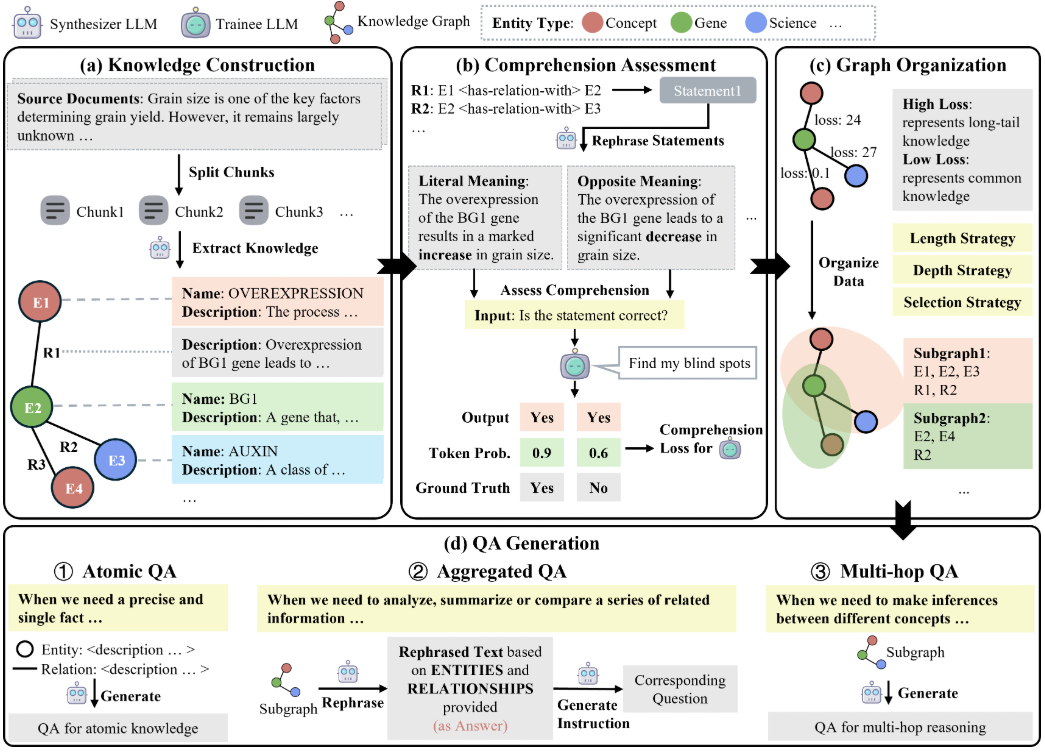
Umfassende Einführung GraphGen ist ein Open-Source-Framework, das von OpenScienceLab, einem KI-Labor in Shanghai, entwickelt wurde und auf GitHub gehostet wird. Es konzentriert sich auf die Optimierung der überwachten Feinabstimmung von Large Language Models (LLMs), indem es die Erzeugung synthetischer Daten durch Wissensgraphen anleitet. Es wurde entwickelt aus ...