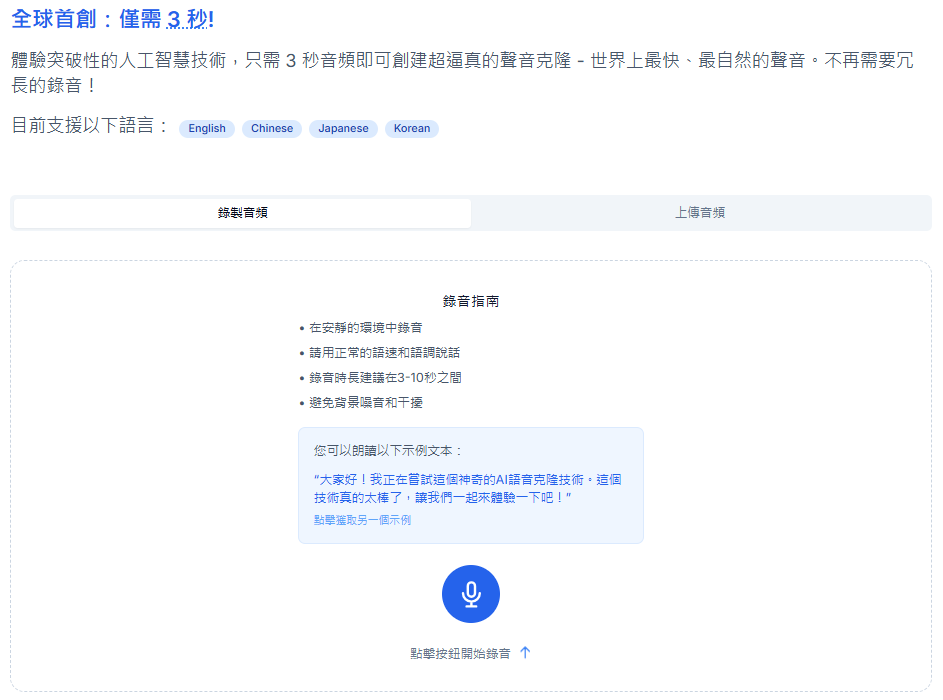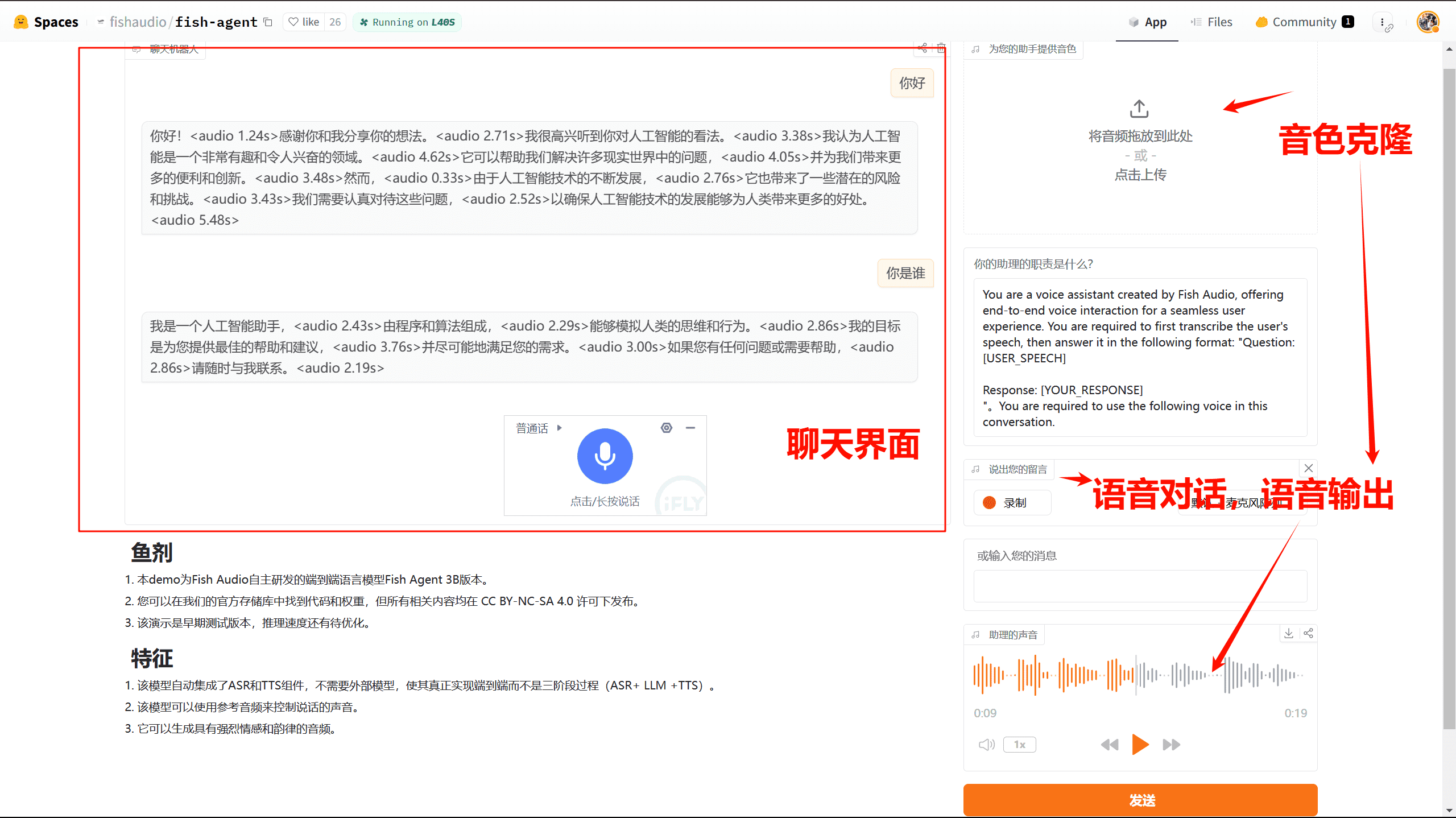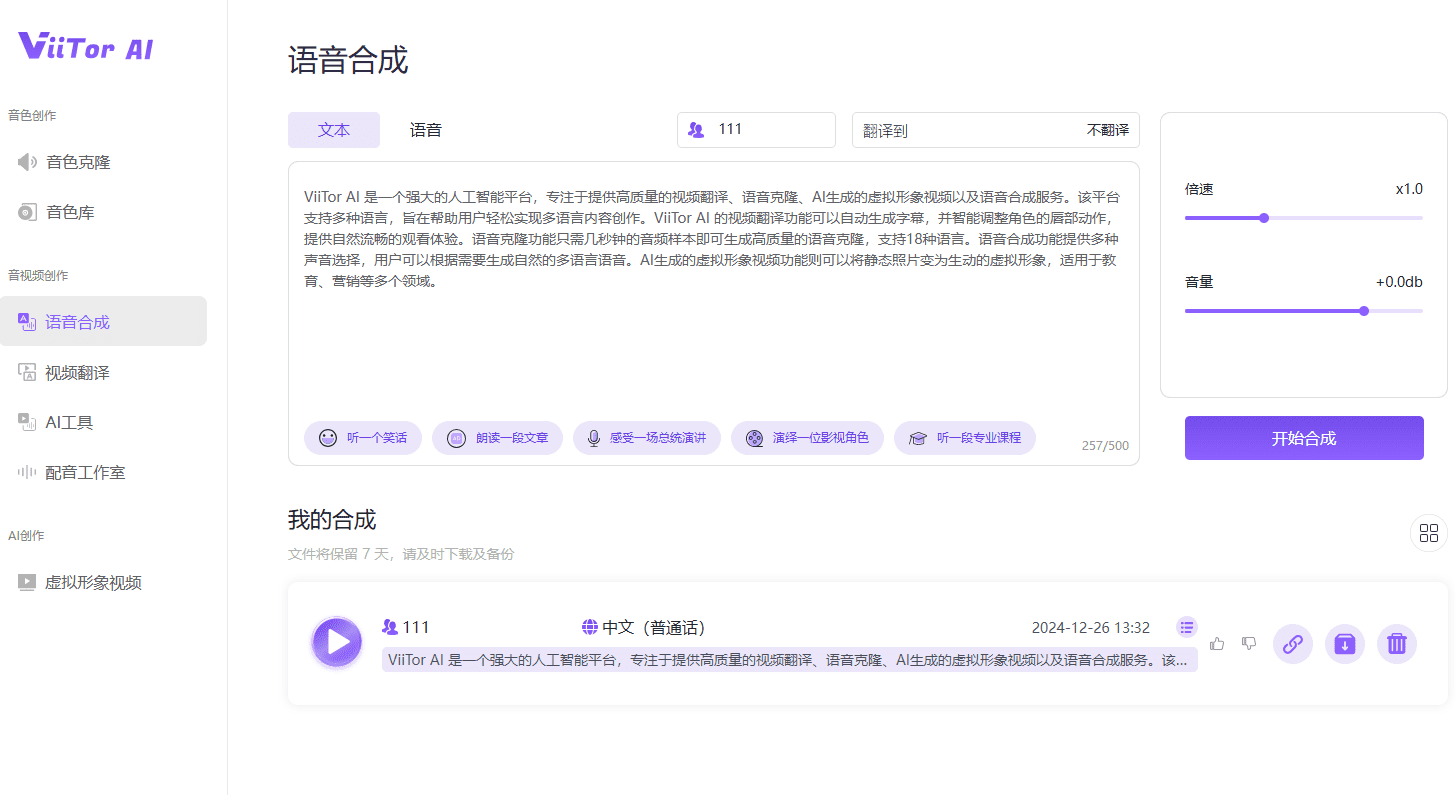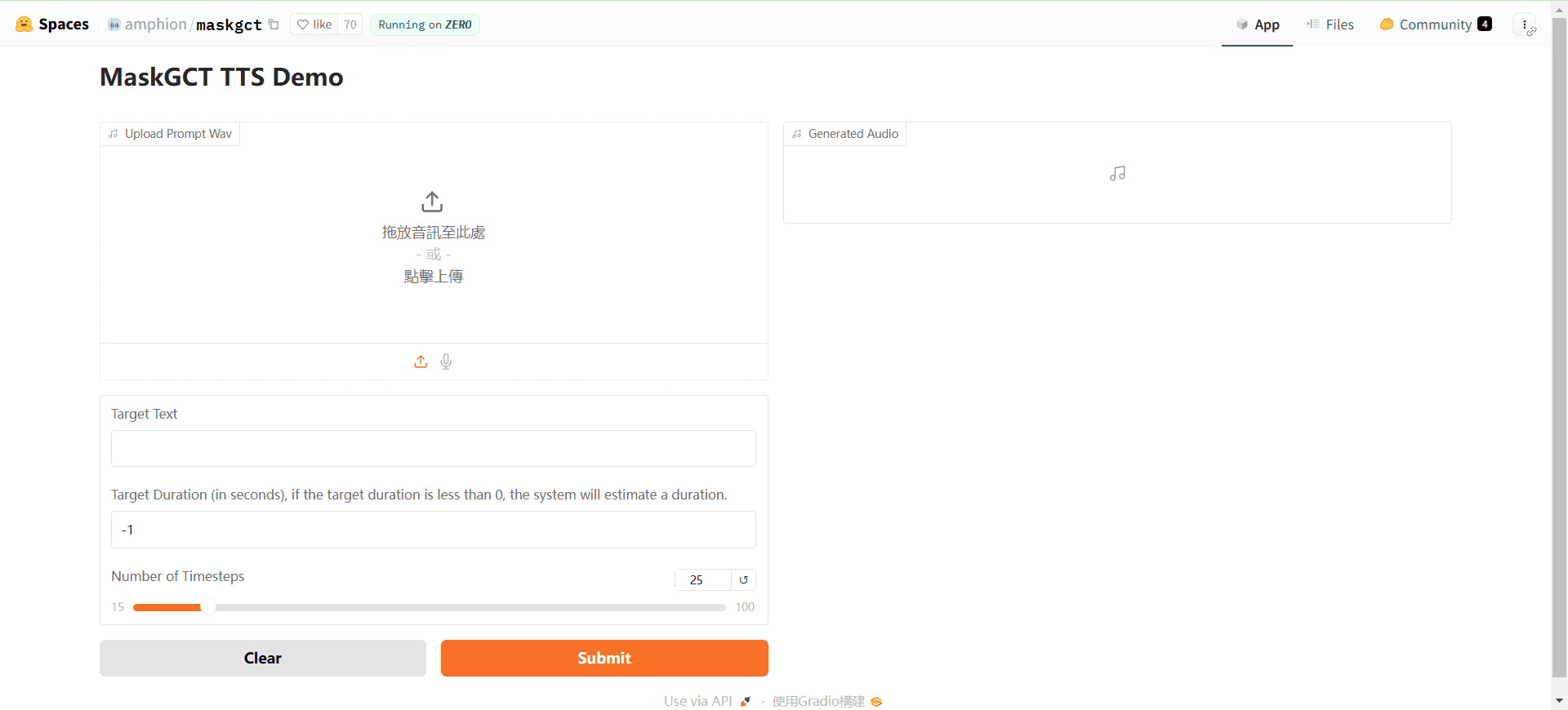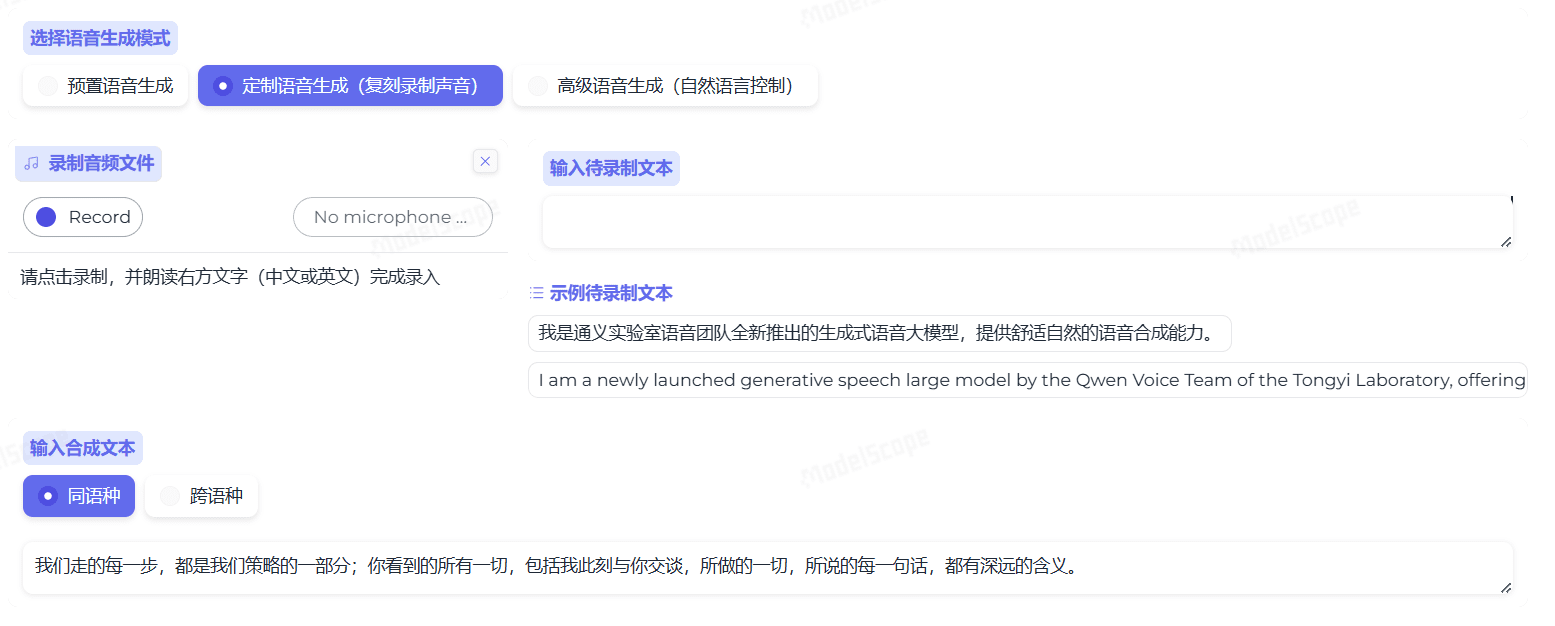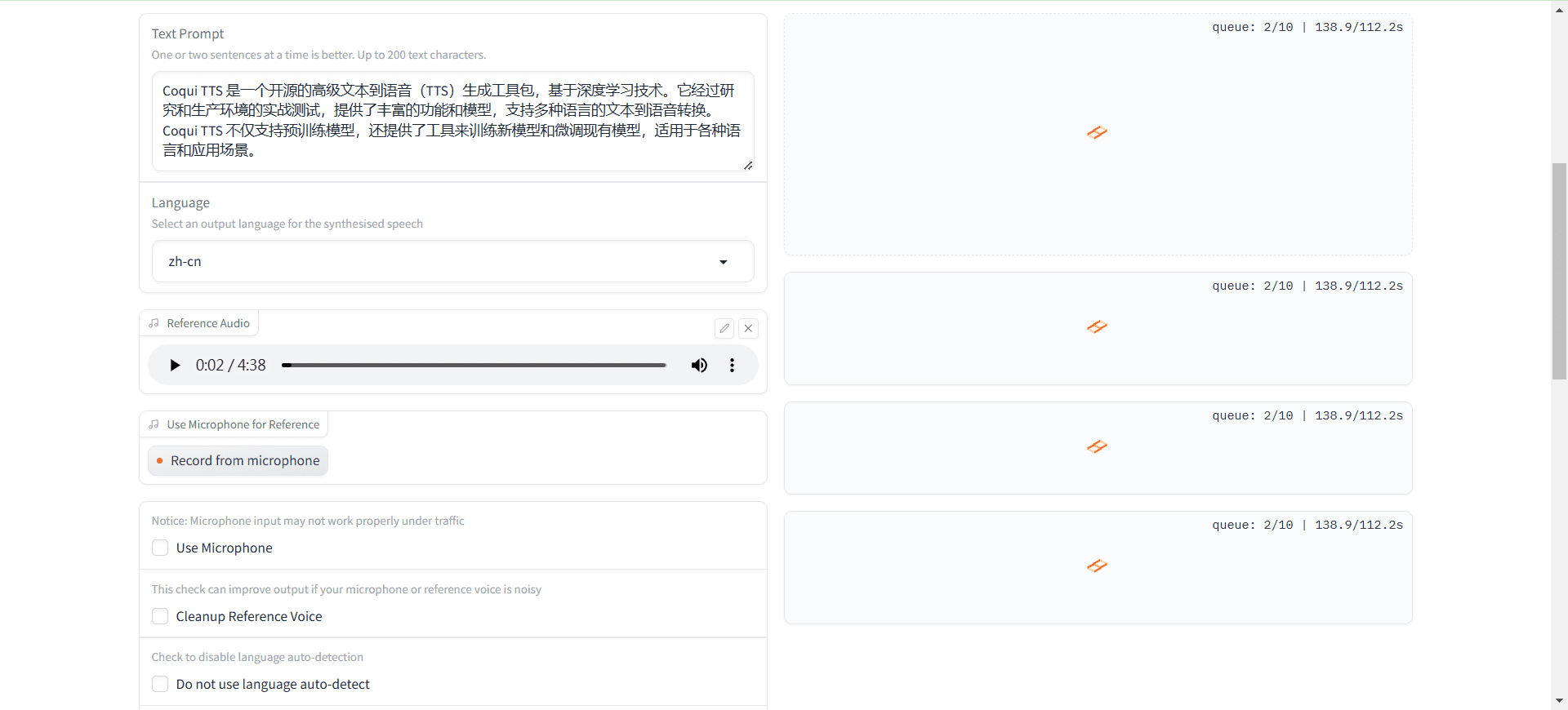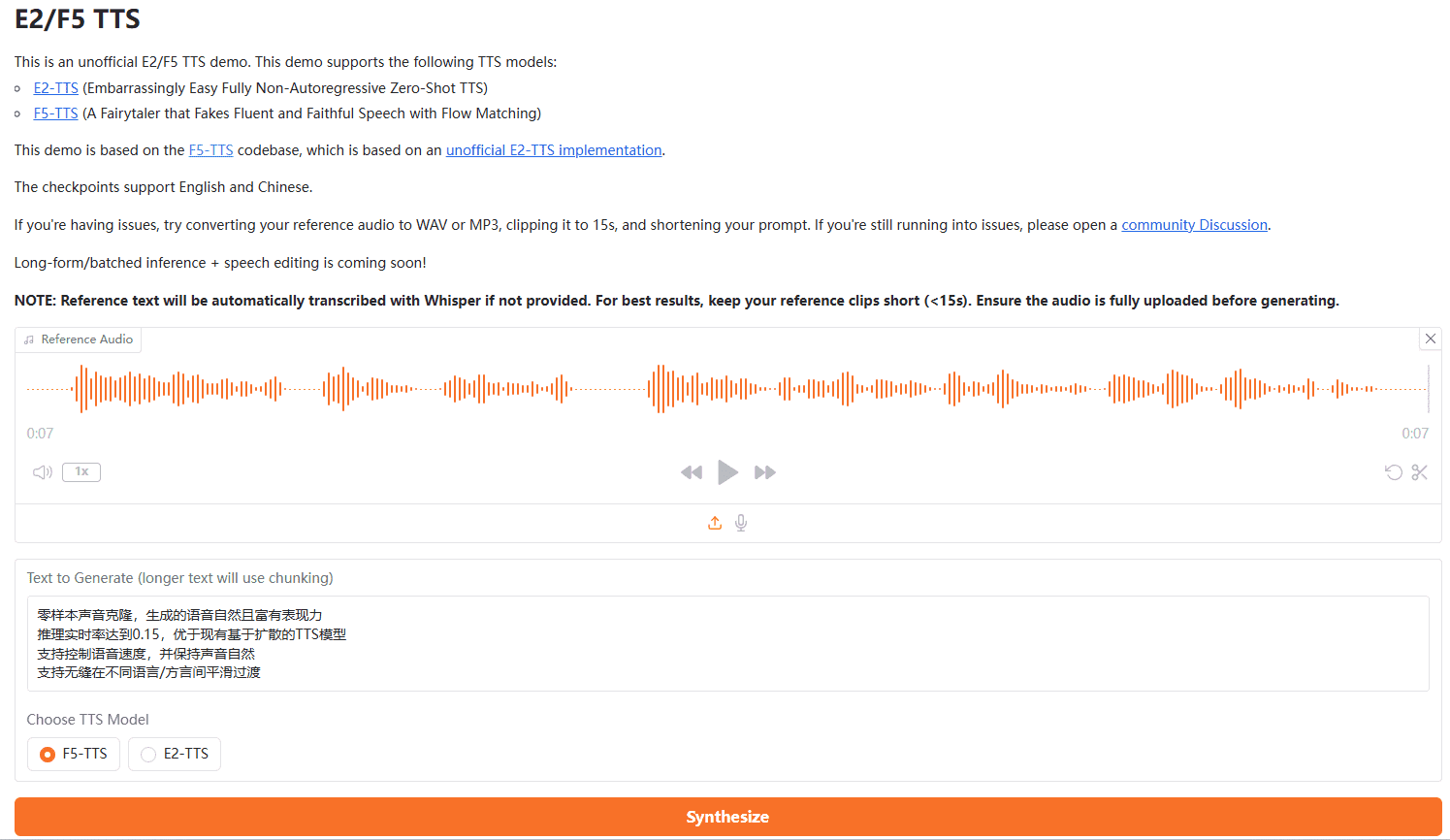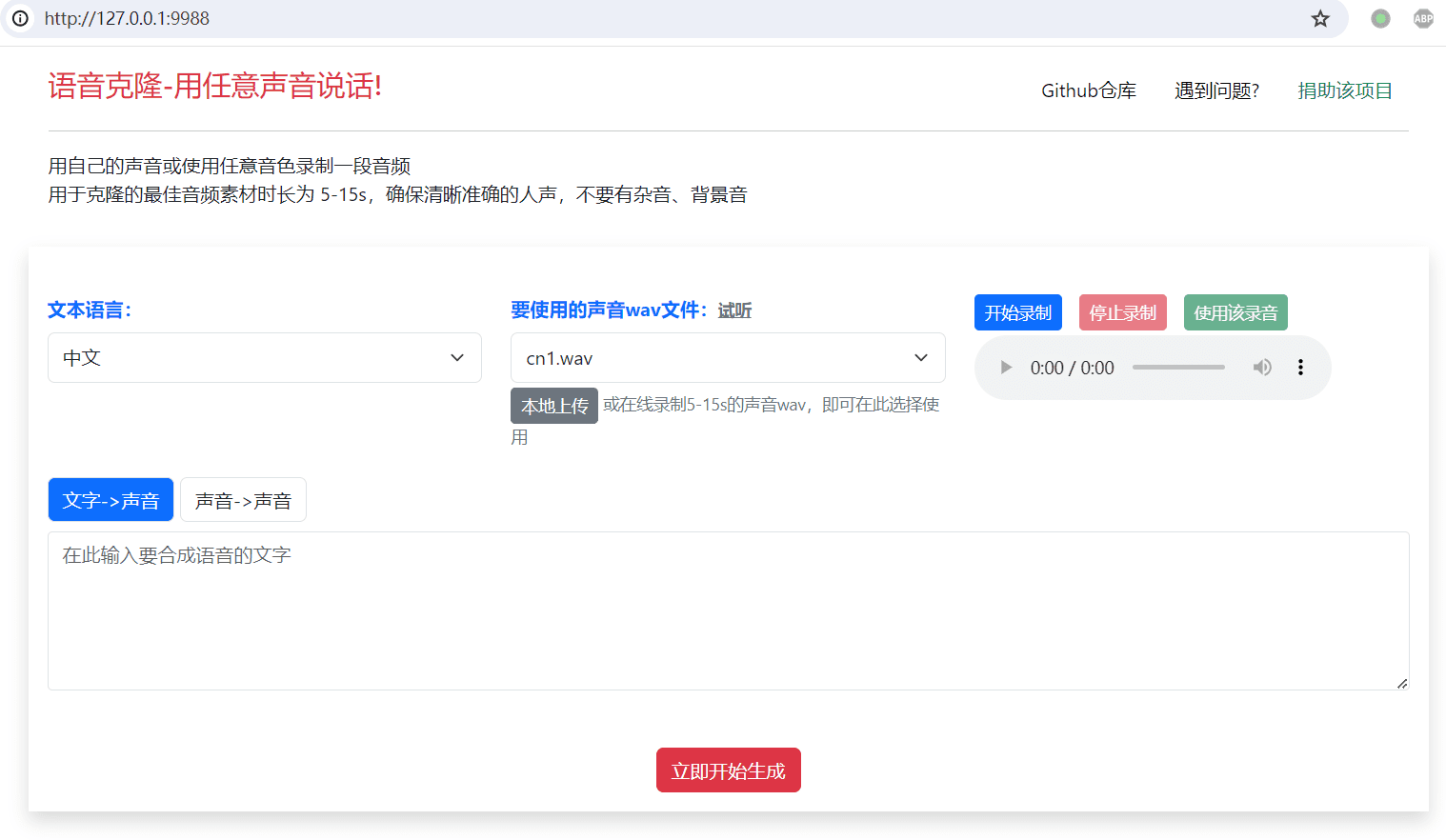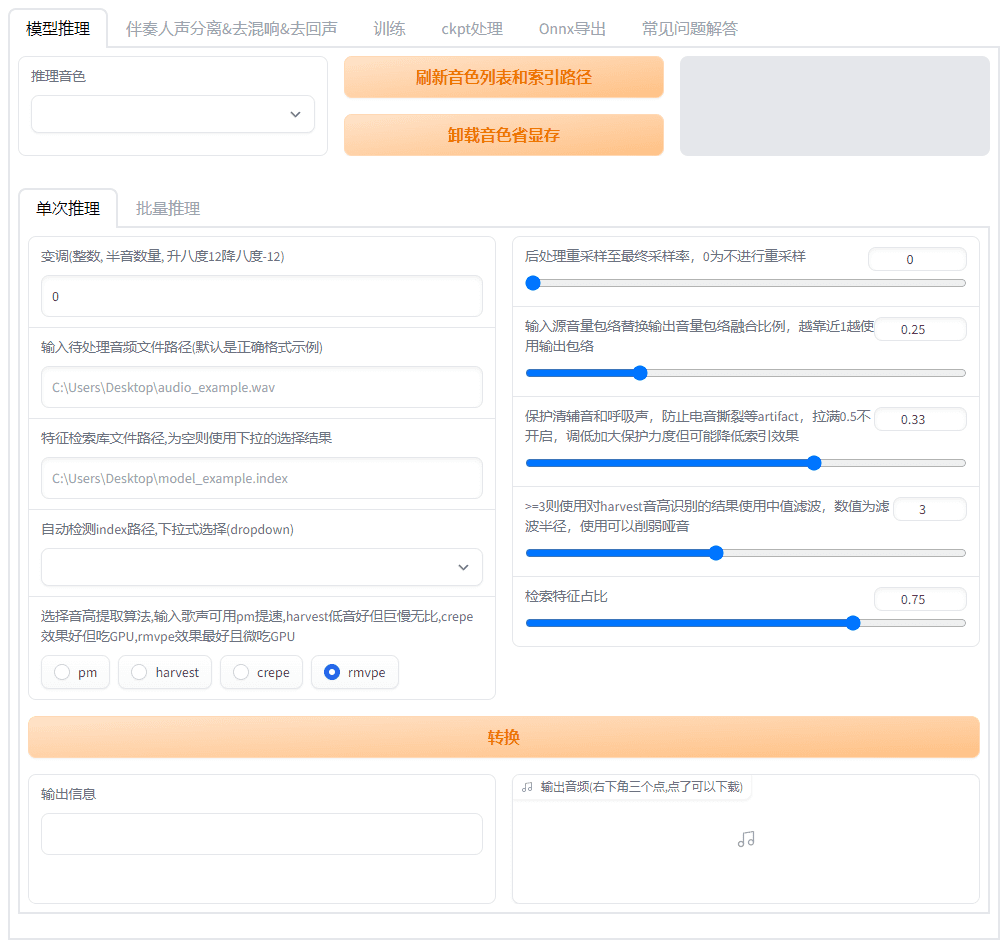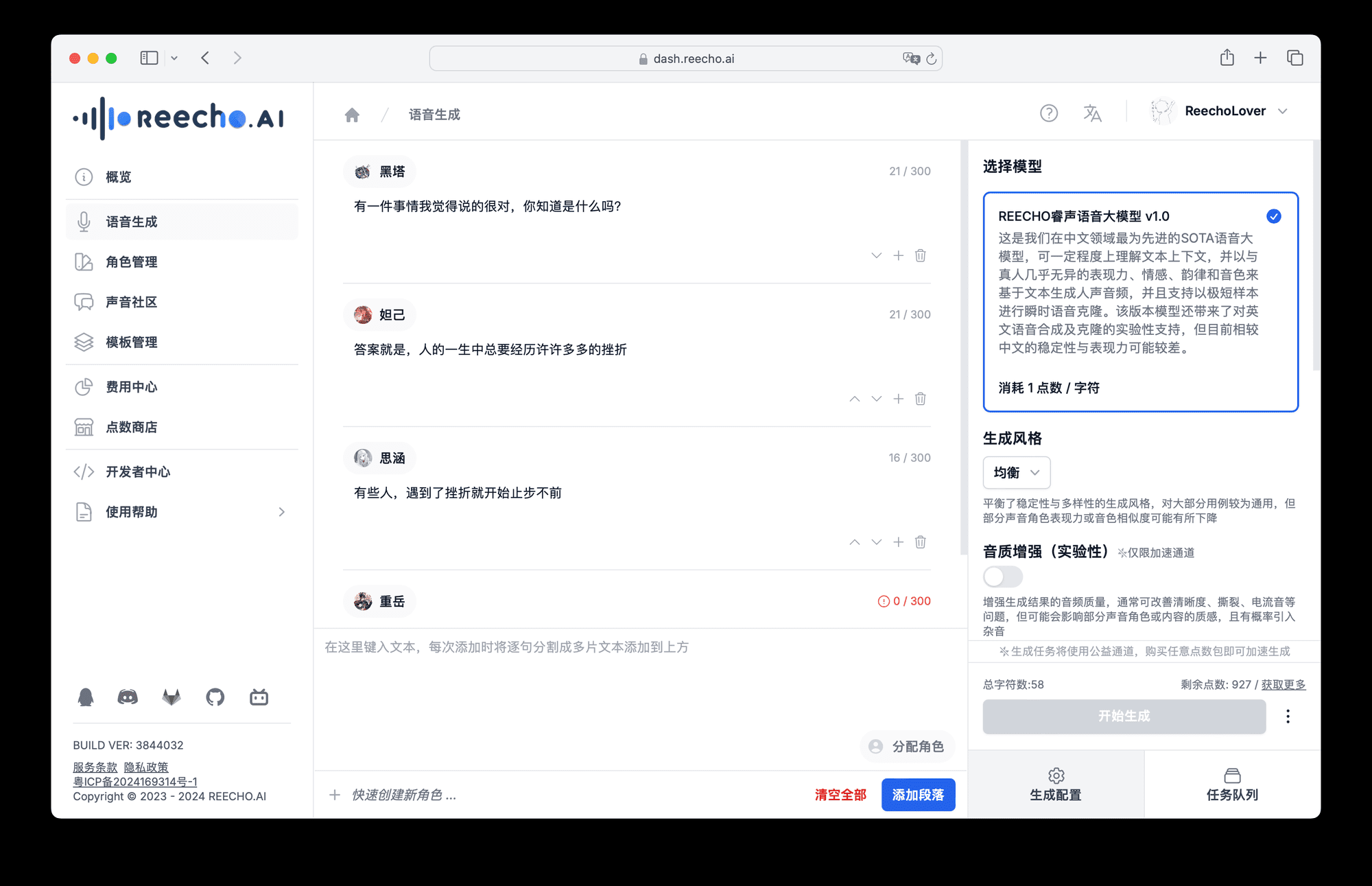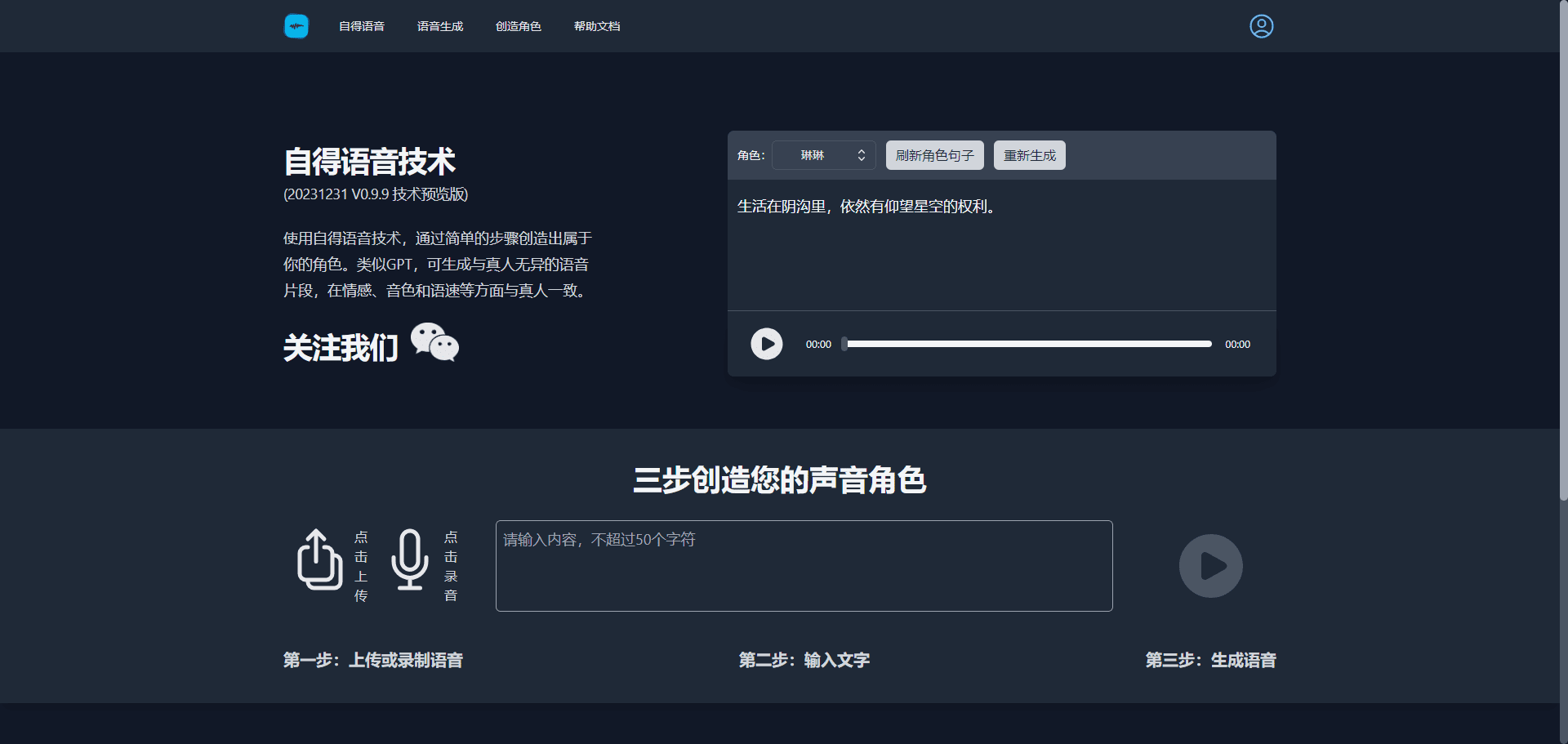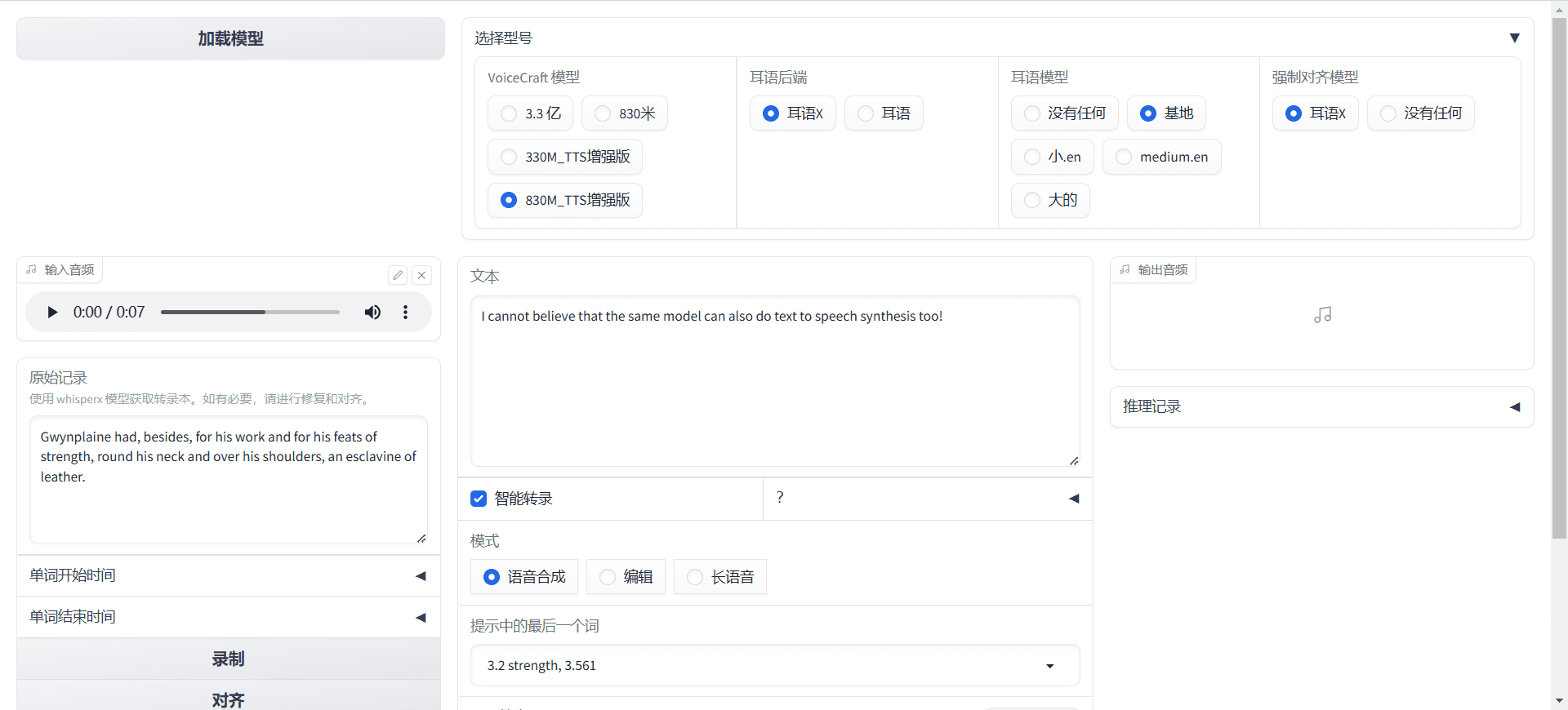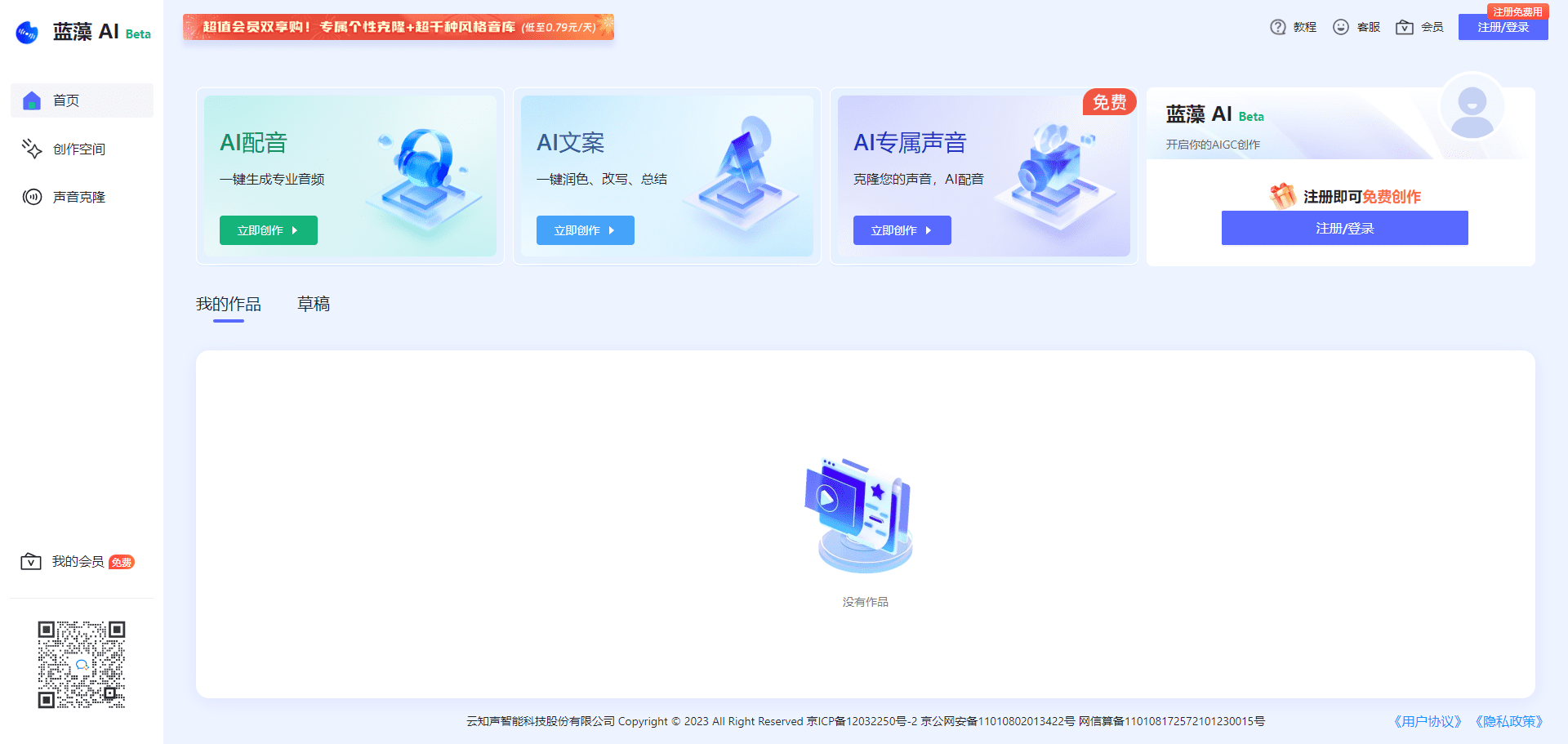
Conch Speech (MiniMax Audio): KI-Tool zur Erzeugung natürlicher Sprache
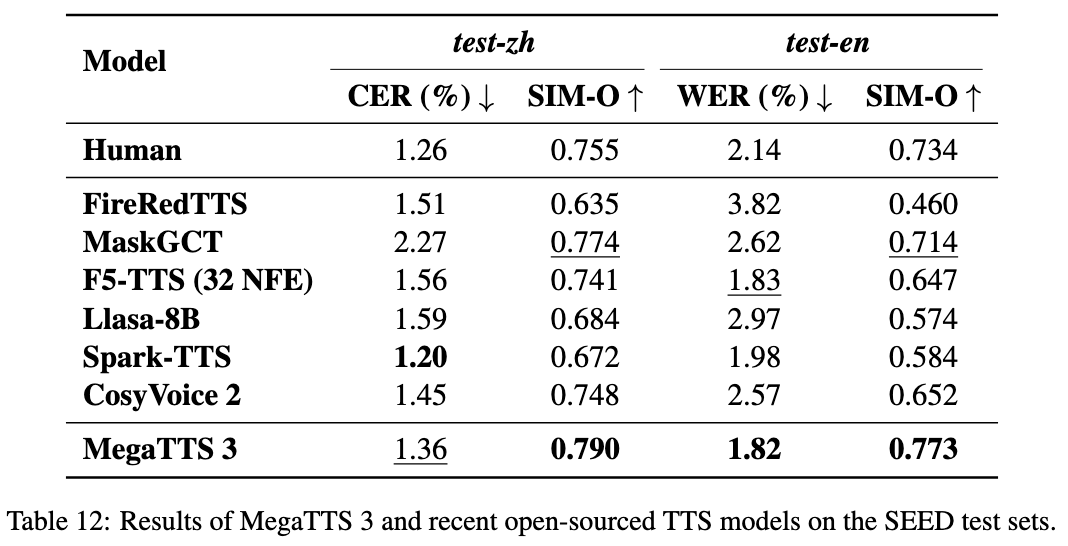
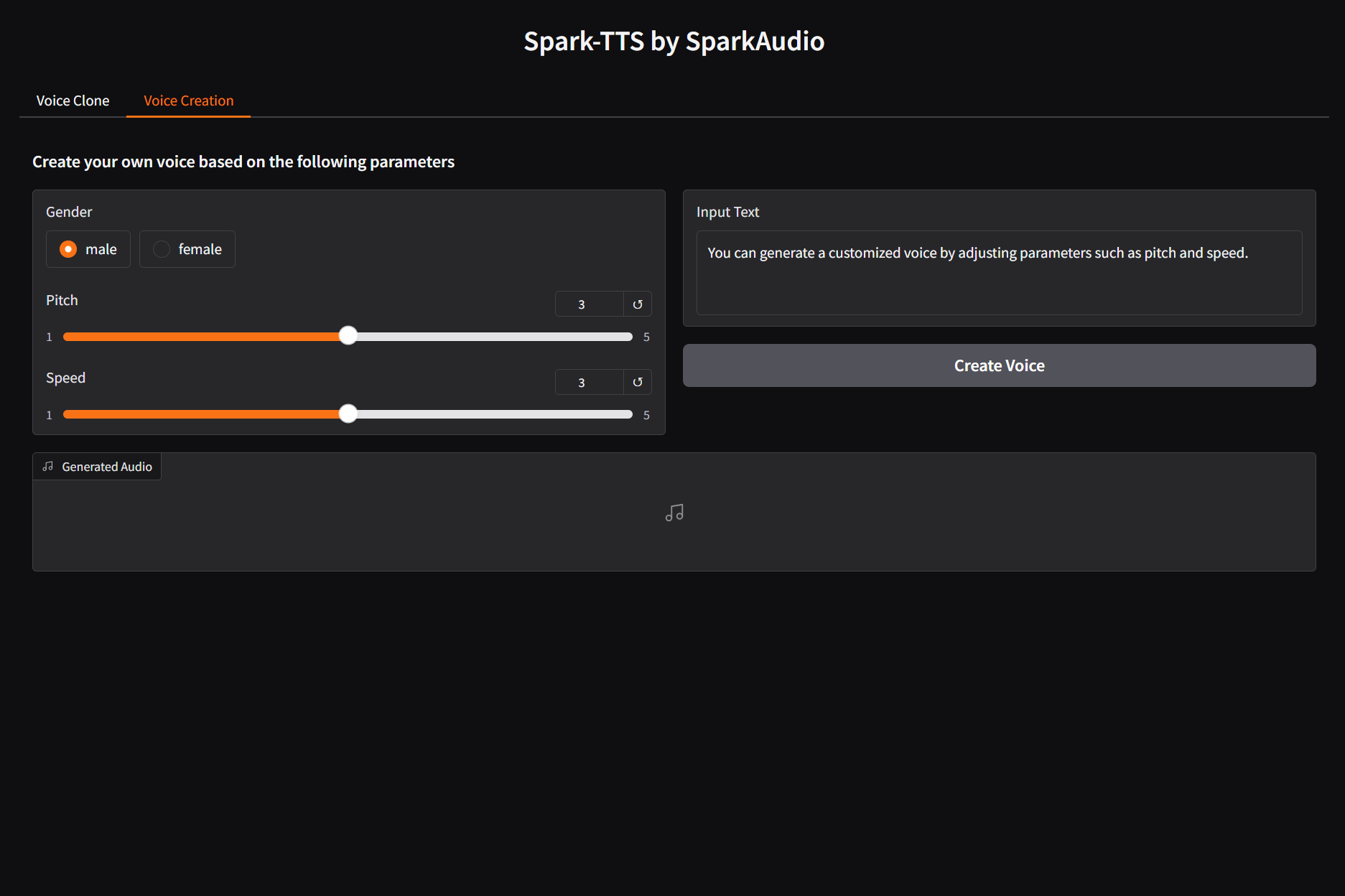
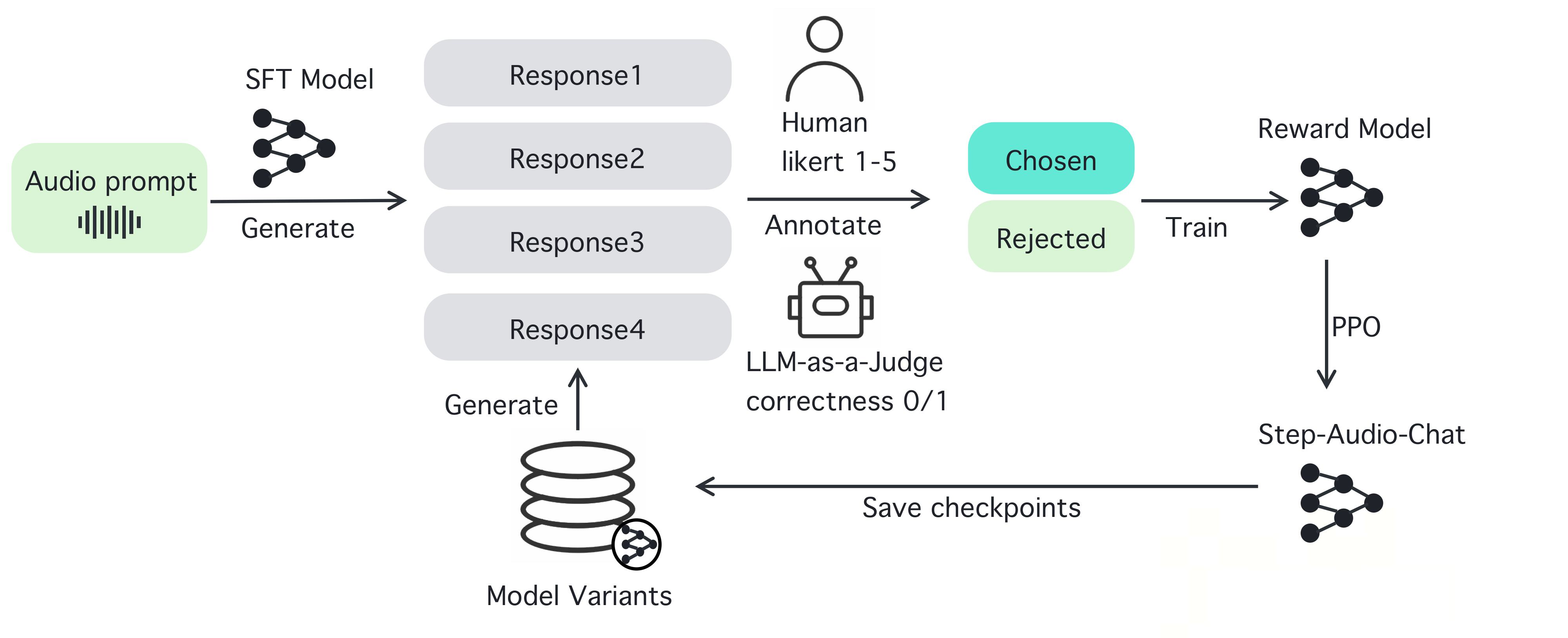
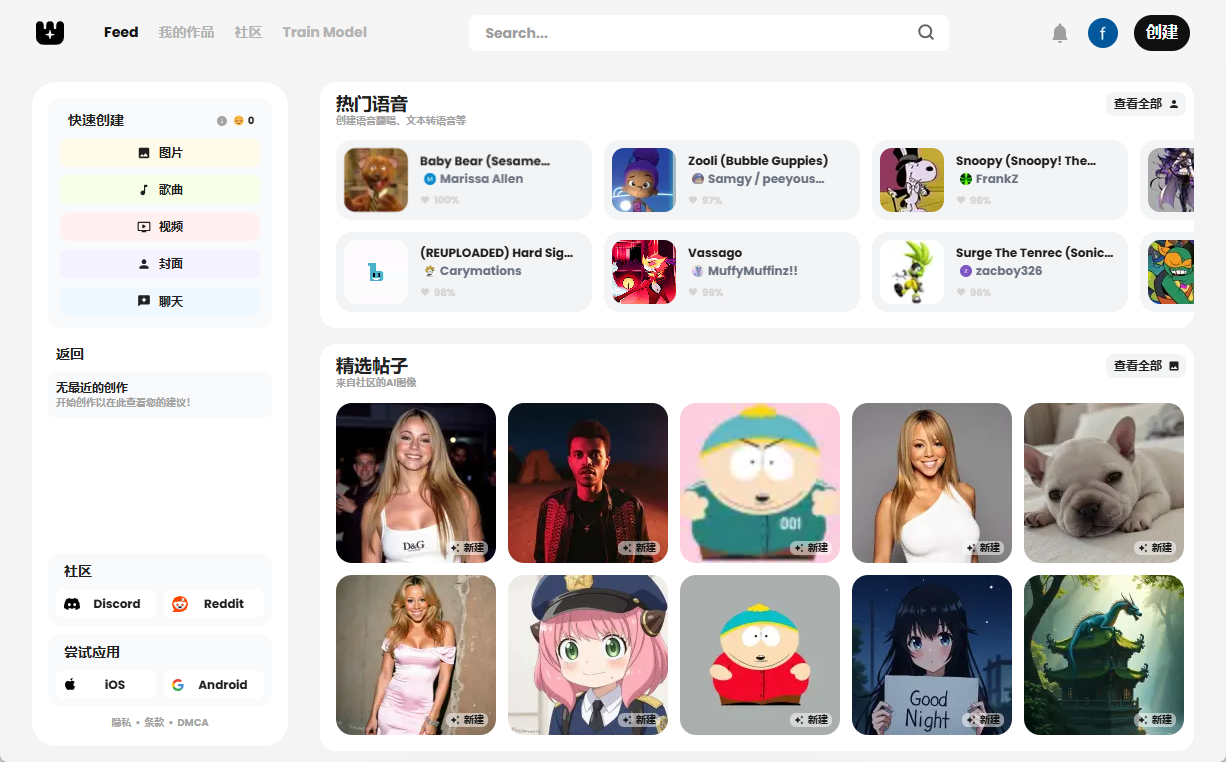
Umfassende Einführung MiniMax Audio ist ein KI-Sprachgenerierungstool von MiniMax, dessen Hauptfunktion die schnelle Umwandlung von Text in natürliche Sprache mit hoher Ähnlichkeit ist. Es basiert auf dem Modell Speech-02, mit einer Sprachsynthese-Ähnlichkeit von bis zu 99...