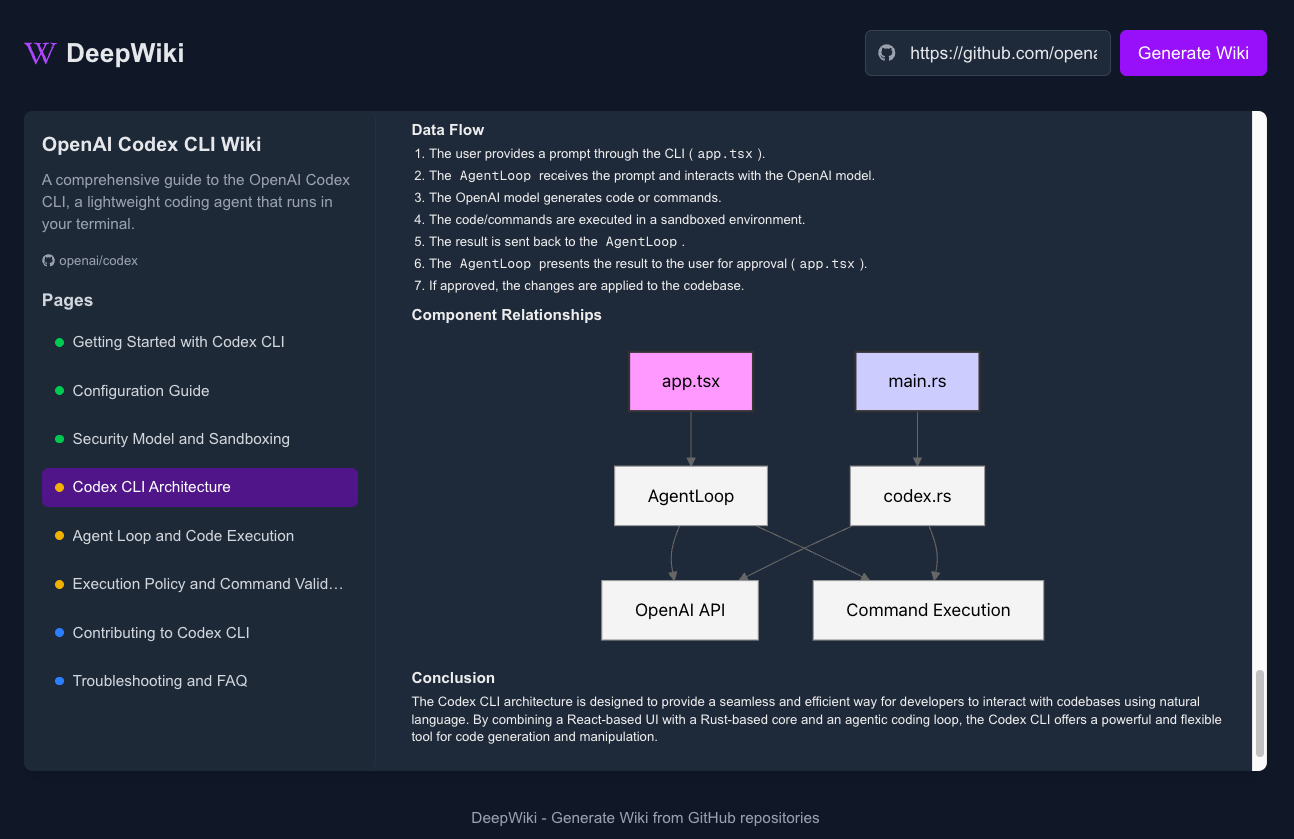
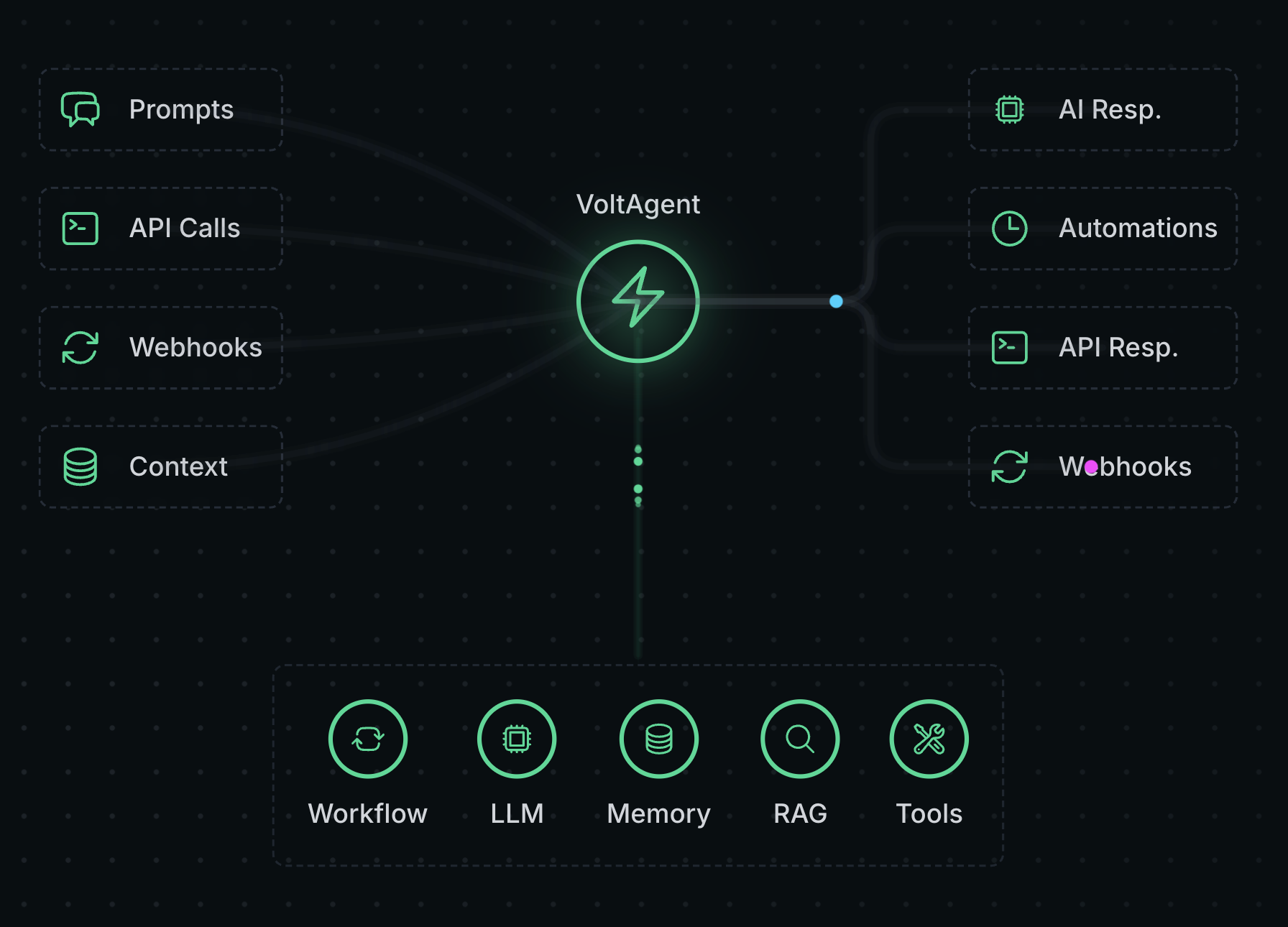
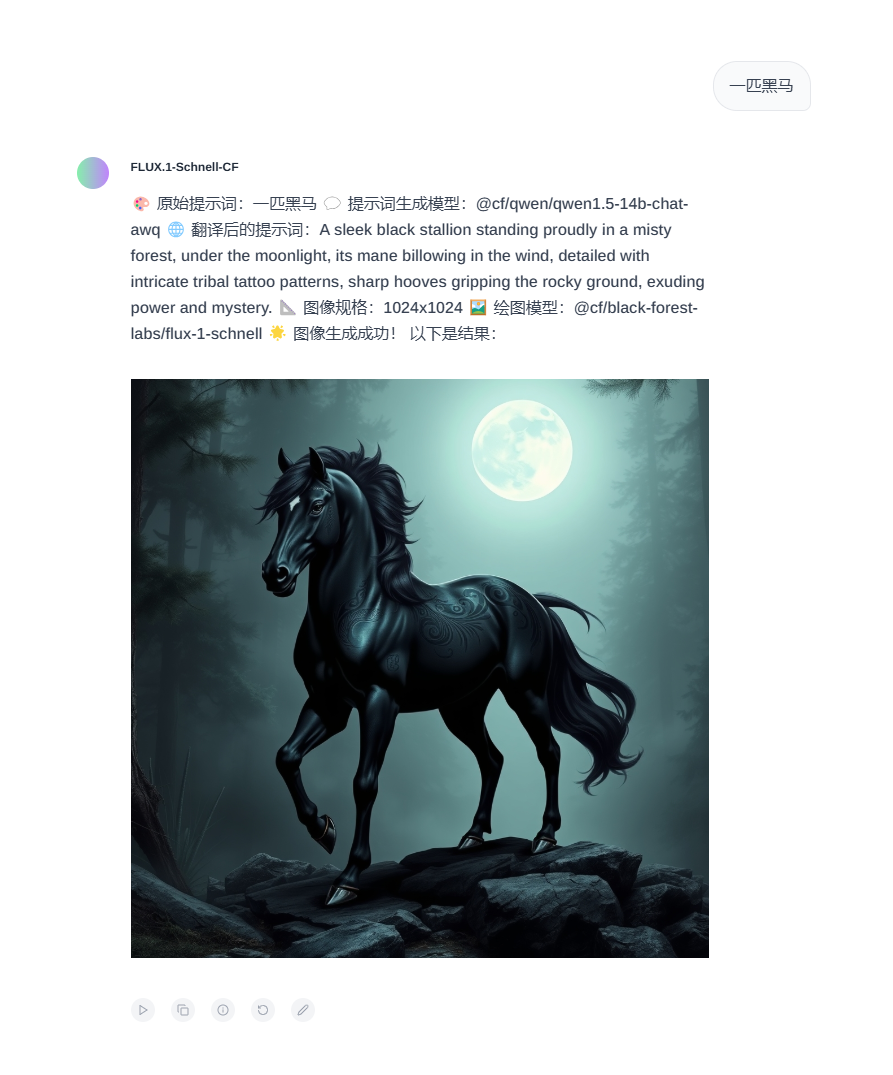
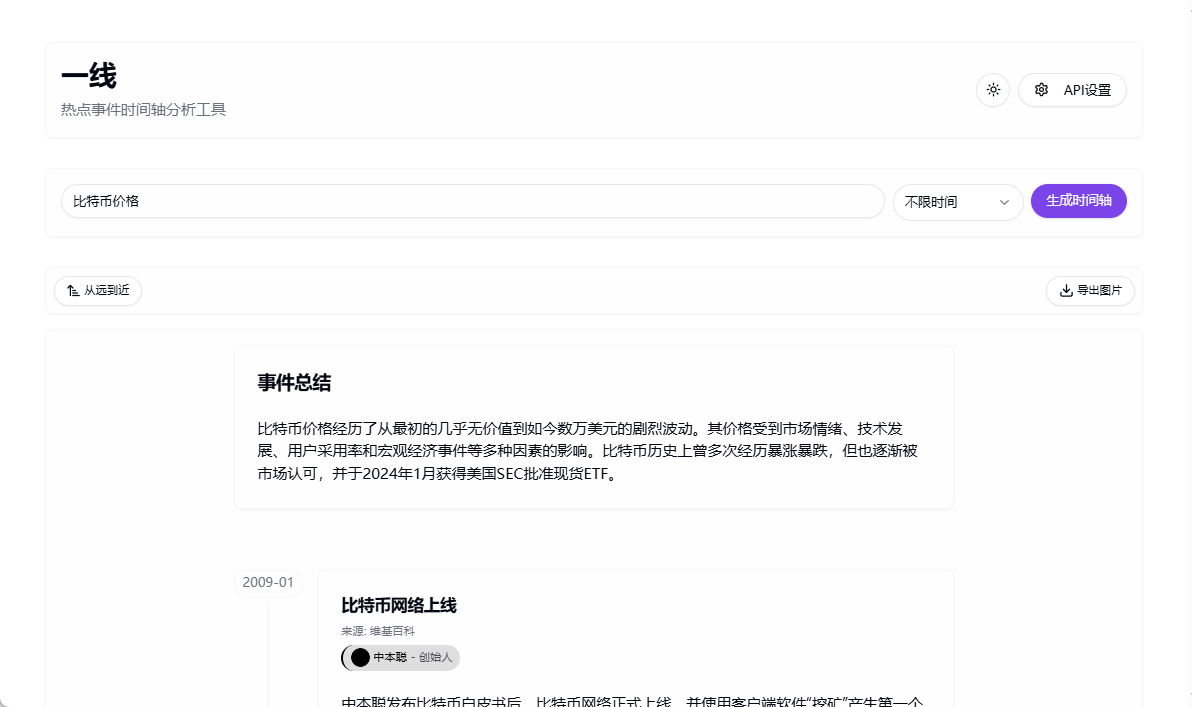
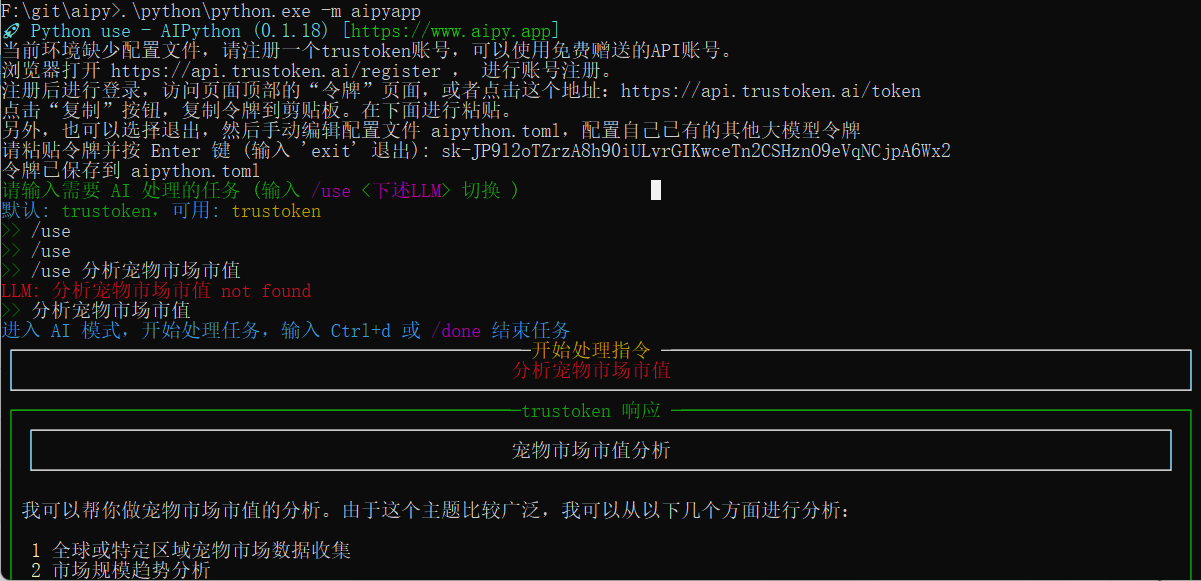
Sim Studio: Open-Source-Workflow-Builder für KI-Agenten
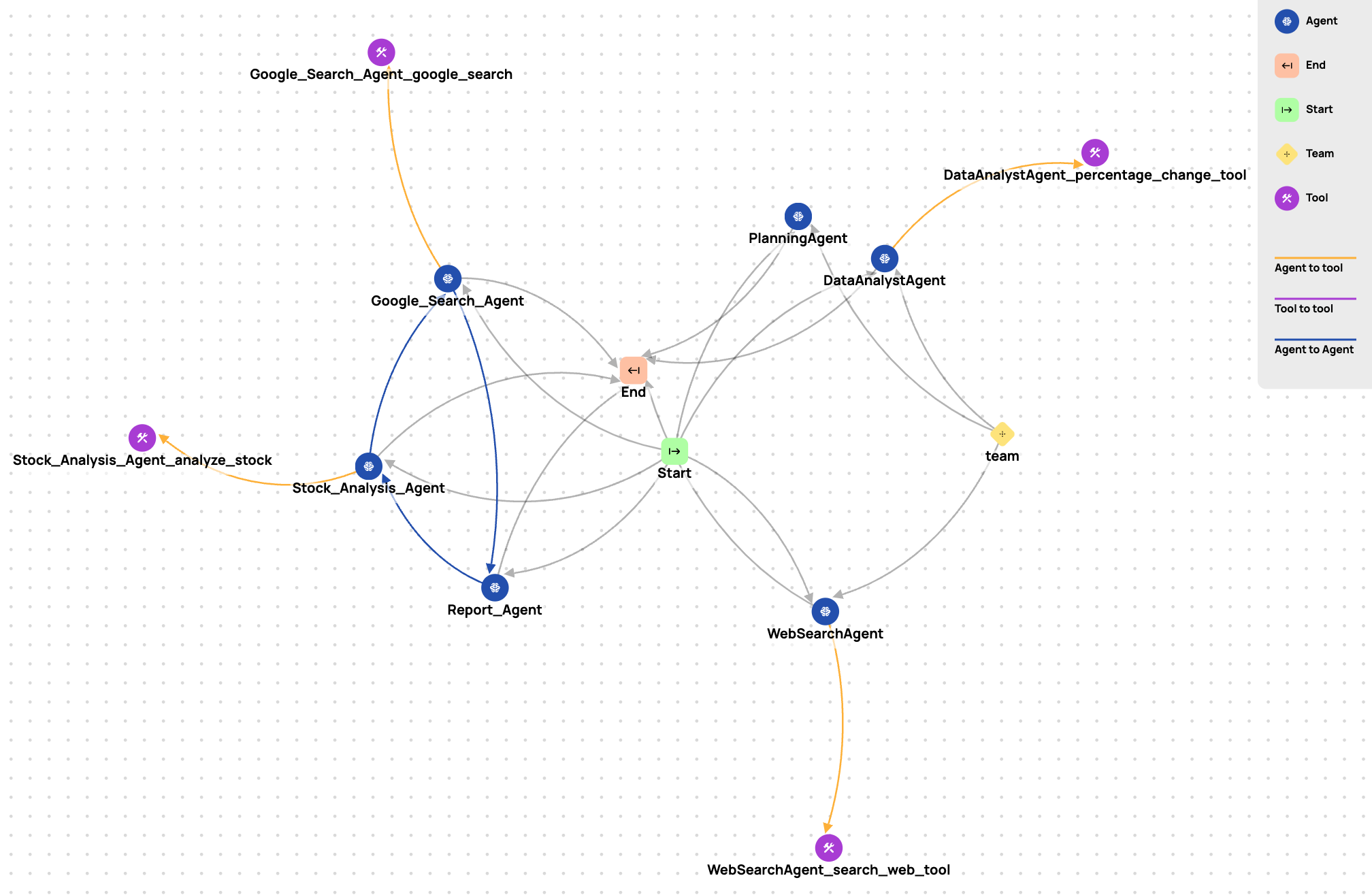
Umfassende Einführung Sim Studio ist eine Open-Source-Plattform für die Erstellung von KI-Agenten-Workflows, die den Nutzern hilft, große Sprachmodell-Workflows (LLM) über eine leichtgewichtige, intuitive visuelle Schnittstelle schnell zu entwerfen, zu testen und einzusetzen. Benutzer können komplexe Workflows ohne tiefgreifende Programmierung durch Ziehen und Ablegen von...