
SuperCLUE Test: DeepSeek-R1 Plattform-Stabilitäts-Crossover von Drittanbietern, Wählen Sie die richtige Plattform, und die Leistung steigt!
DeepSeek-R1 Stabilitätsbewertungsbericht auf Plattformen von Drittanbietern
Die rasante Entwicklung auf dem Gebiet der künstlichen Intelligenz hat eine Reihe hervorragender Inferenzmodelle hervorgebracht. deepSeek-R1 ist aufgrund seiner herausragenden Leistung und seiner Fähigkeit, komplexe Aufgaben zu bewältigen, schnell in den Mittelpunkt des Interesses der Branche gerückt. Mit der zunehmenden Zahl von Nutzern und der Zunahme externer Cyberangriffe wurde jedoch nach und nach das Stabilitätsproblem von DeepSeek-R1 aufgedeckt. Um dieser Herausforderung zu begegnen, haben mehrere Drittanbieterplattformen ihre eigenen Lösungen für das DeepSeek-R1 Modelloptimierungsdienste und bemühen sich, den Nutzern ein stabileres und effizienteres Erlebnis zu bieten.
Um den Nutzern zu helfen, die Servicequalität der verschiedenen Plattformen vollständig zu verstehen und eine fundierte Wahl auf der Grundlage ihrer Bedürfnisse zu treffen, hat die Organisation eine Umfrage zu einer Reihe von Drittanbieter-Plattformen durchgeführt, die DeepSeek-R1 unterstützen.Bewertung der StabilitätDiese Bewertung wurde auf 12 repräsentativen Plattformen von Drittanbietern durchgeführt. Für diese Evaluierung wurden 12 repräsentative Plattformen von Drittanbietern ausgewählt und 20 originale Orakel-Fragen für Grundschulen entworfen, um die tatsächliche Leistung des DeepSeek-R1-Modells auf jeder Plattform zu untersuchen. Die Bewertungsdimensionen umfassen Schlüsselindikatoren wie Antwortrate, Denkzeit und Genauigkeit. In diesem Bericht werden die ersten Evaluierungsergebnisse der webbasierten Plattformen vorgestellt, die das Stabilitätsniveau der einzelnen Plattformen zum Zeitpunkt der Veröffentlichung widerspiegeln. In der Zukunft wird die Organisation weiterverfolgen und umfassendere Bewertungen auf verschiedenen Plattformen durchführen, einschließlich webbasierter, API- und APP-Versionen und sogar lokal bereitgestellter Versionen.
Zusammenfassung der Erfahrungen mit der DeepSeek-R1 Stabilitätsbewertung
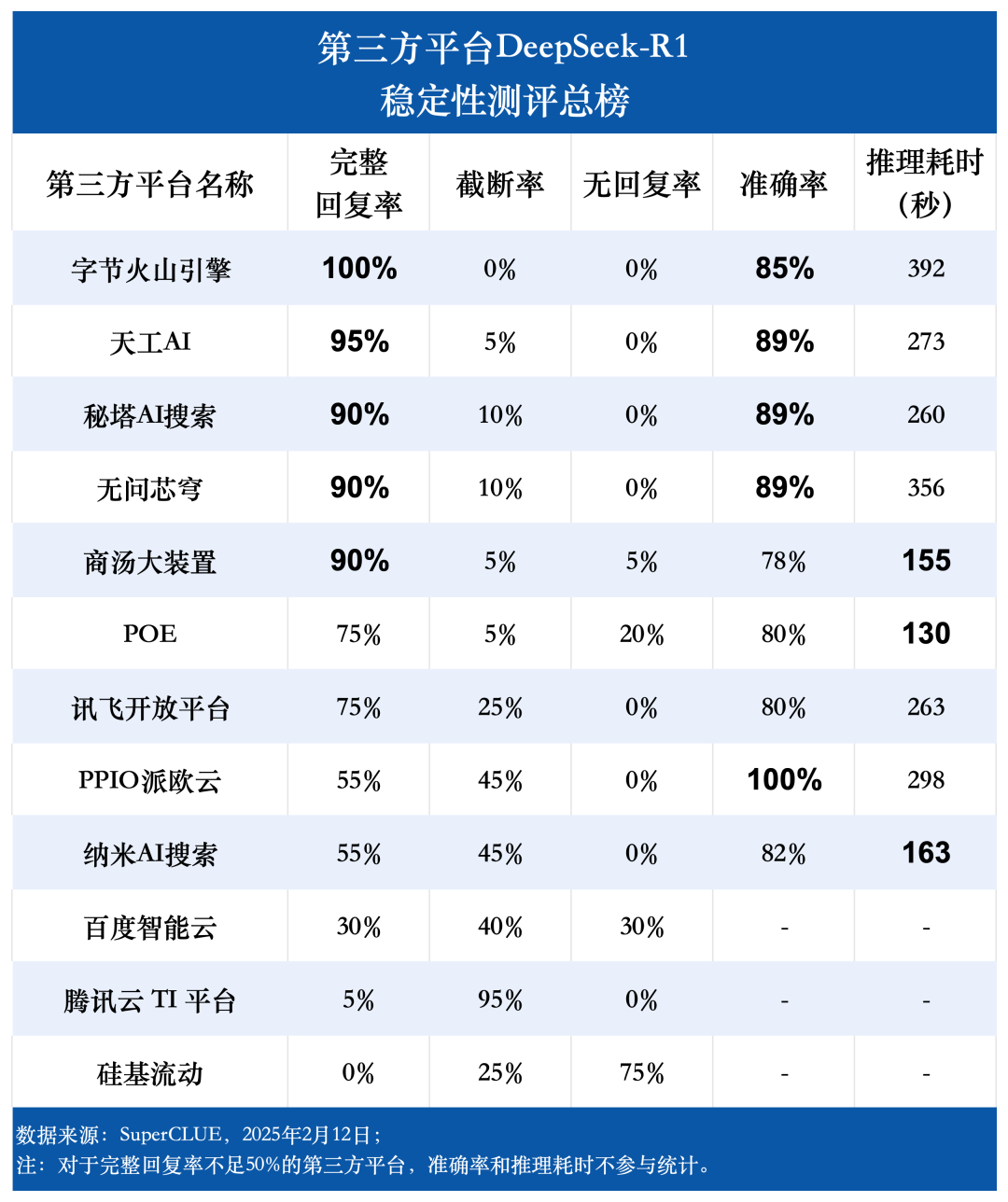
Bewertungspunkt 1: Es besteht ein signifikanter Unterschied in den vollständigen Antwortraten der Drittanbieterplattformen DeepSeek-R1.
Die Bewertungsergebnisse zeigen, dass Byte Volcano Engine (100%), Tiangong AI (95%), Secret Pagoda AI Search, Unquestioning Core Dome und Shangtang Big Device (alle 90%) eine hervorragende Leistung in Bezug auf die vollständige Antwortrate aufweisen und damit eine ausgezeichnete Stabilität demonstrieren. Im Gegensatz dazu wiesen Baidu Intelligent Cloud, Tencent Cloud TI Platform und Silicon Mobility vollständige Antwortraten unter 50% auf, was darauf hindeutet, dass ihre Stabilität verbessert werden könnte. Dieses Ergebnis unterstreicht die Bedeutung der Plattformstabilität für den Auswahlprozess der Nutzer.
Bewertungspunkt 2: Es gibt einen signifikanten Unterschied in der Inferenzzeit des DeepSeek-R1-Modells zwischen den Plattformen, wobei der Unterschied zwischen der längsten und der kürzesten Plattform fast das Dreifache beträgt.
In Bezug auf die Inferenzzeit ist die POE-Plattform mit einer durchschnittlichen Zeit von 130 Sekunden pro Frage am leistungsfähigsten. Es folgen BT Big Device und Nano AI Search mit einer durchschnittlichen Zeit pro Frage von 155 Sekunden bzw. 163 Sekunden. Die Byte Volcano Engine benötigte mit 392 Sekunden die längste durchschnittliche Zeit pro Frage.
Bewertungspunkt 3: Die Gesamtgenauigkeit des DeepSeek-R1-Modells ist über alle Plattformen hinweg hoch, was die starke und zuverlässige Leistung des Modells selbst widerspiegelt.
Die Bewertungsdaten zeigen, dass mit Ausnahme der Plattformen mit einer vollständigen Antwortrate von weniger als 50% die durchschnittliche Genauigkeitsrate der anderen neun Plattformen bei 85,76% liegt, die höchste Genauigkeitsrate erreicht sogar 100%, und die niedrigste Genauigkeitsrate liegt bei 78%, was beweist, dass das DeepSeek-R1-Modell selbst über eine ausgezeichnete Leistung und Zuverlässigkeit verfügt und eine stabile und genaue Unterstützung für alle Arten von Drittanbieteranwendungen bieten kann. Dies beweist, dass das DeepSeek-R1-Modell selbst über eine ausgezeichnete Leistung und Zuverlässigkeit verfügt und eine stabile und hochgenaue Unterstützung für verschiedene Anwendungen von Drittanbietern bieten kann.
Überblick über die Liste
Vollständige Antwortquote + Abbruchquote + keine Antwortquote = 100%
- Vollständige AntwortquoteDas Modell liefert vollständige Antworten ohne Probleme wie Abbruch oder keine Antwort, berücksichtigt aber nicht, ob die Antwort richtig ist oder nicht. Sie wird berechnet als die Anzahl der vollständig beantworteten Fragen geteilt durch die Gesamtzahl der Fragen.
- TrunkierungsrateDas Modell hatte eine Unterbrechung im Antwortprozess und konnte keine vollständige Antwort geben. Berechnet als die Anzahl der abgebrochenen Fragen geteilt durch die Gesamtzahl der Fragen.
- keine BeantwortungsquoteModelle, die aus besonderen Gründen keine Antworten geben (z. B. keine Antwort/Anfragefehler). Berechnet als die Anzahl der nicht beantworteten Fragen geteilt durch die Gesamtzahl der Fragen.
- GenauigkeitBei Fragen mit vollständigen Antworten auf das Modell, der Anteil der Antworten, die mit der Standardantwort übereinstimmen. Es wird nur die Korrektheit der endgültigen Antwort bewertet, der Lösungsweg wird nicht geprüft.
- Benötigte Zeit für das Denken (Sekunden/Frage)Die durchschnittliche Zeit, die das Modell benötigt, um bei Fragen mit vollständigen Modellantworten auf jede Antwort zu schließen.
Methodik
1. Für jede der Drittanbieter-Plattformen wurde ein standardisierter Test mit 20 OE-Fragen aus der Grundschule durchgeführt, um die Fairness und Vergleichbarkeit der Bewertung zu gewährleisten.2. In Anbetracht der Tatsache, dass der Output-Inhalt von Argumentationsfragen in der Regel lang ist, wird zur Unterstützung der Anpassung des maximalen Outputs Token Bei Plattformen mit max_tokens setzen Sie diesen Parameter auf den Höchstwert und belassen die übrigen Parameter auf den Standardeinstellungen der Plattform.3. Statistische Methode des Zeitverbrauchs für die Inferenz: Bei Plattformen mit einer Funktion für die Inferenzzeitmessung werden die von der Plattform bereitgestellten statistischen Ergebnisse verwendet; bei Plattformen ohne diese Funktion wird die Zeitmessung manuell vorgenommen.
Ergebnisse der Bewertung
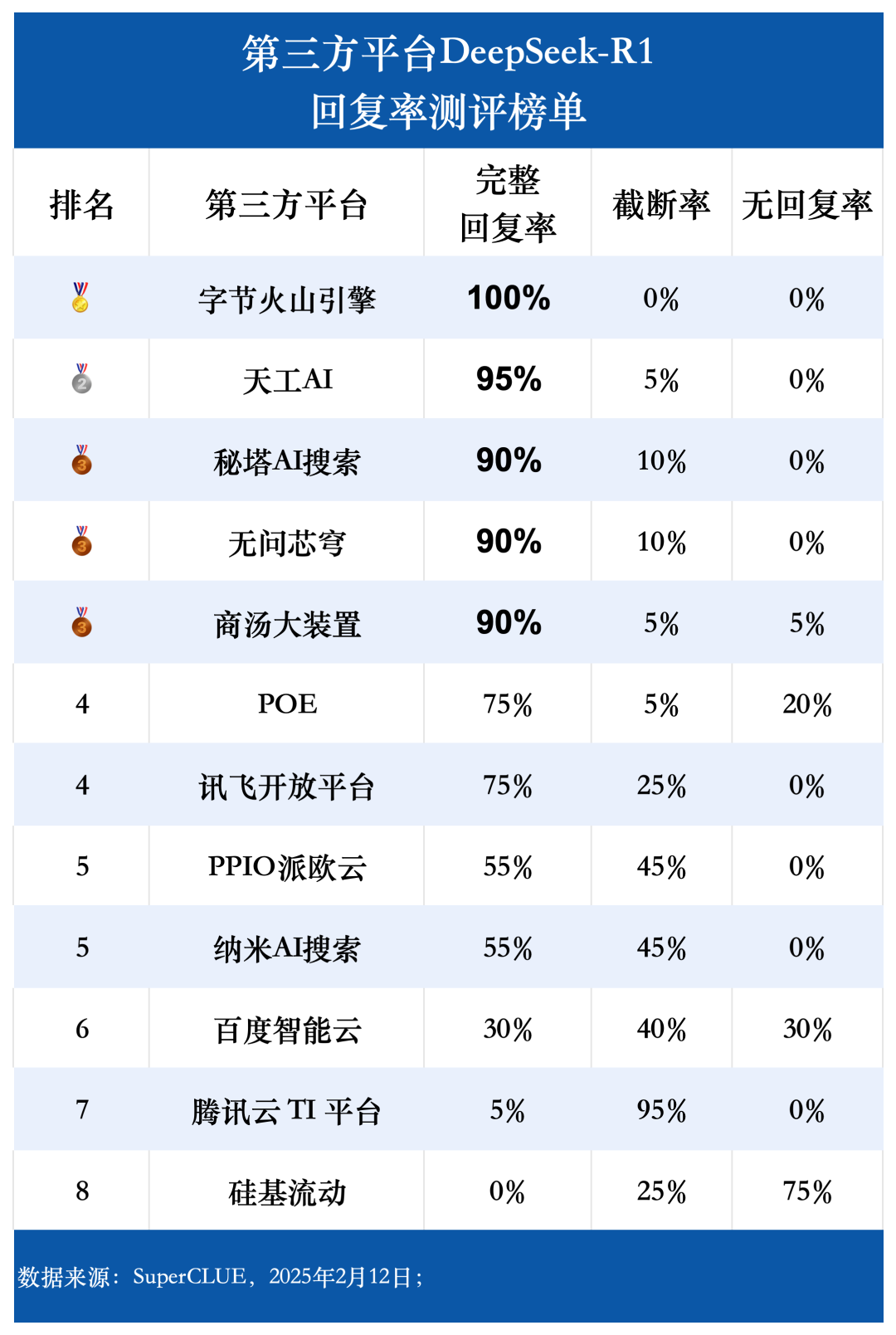
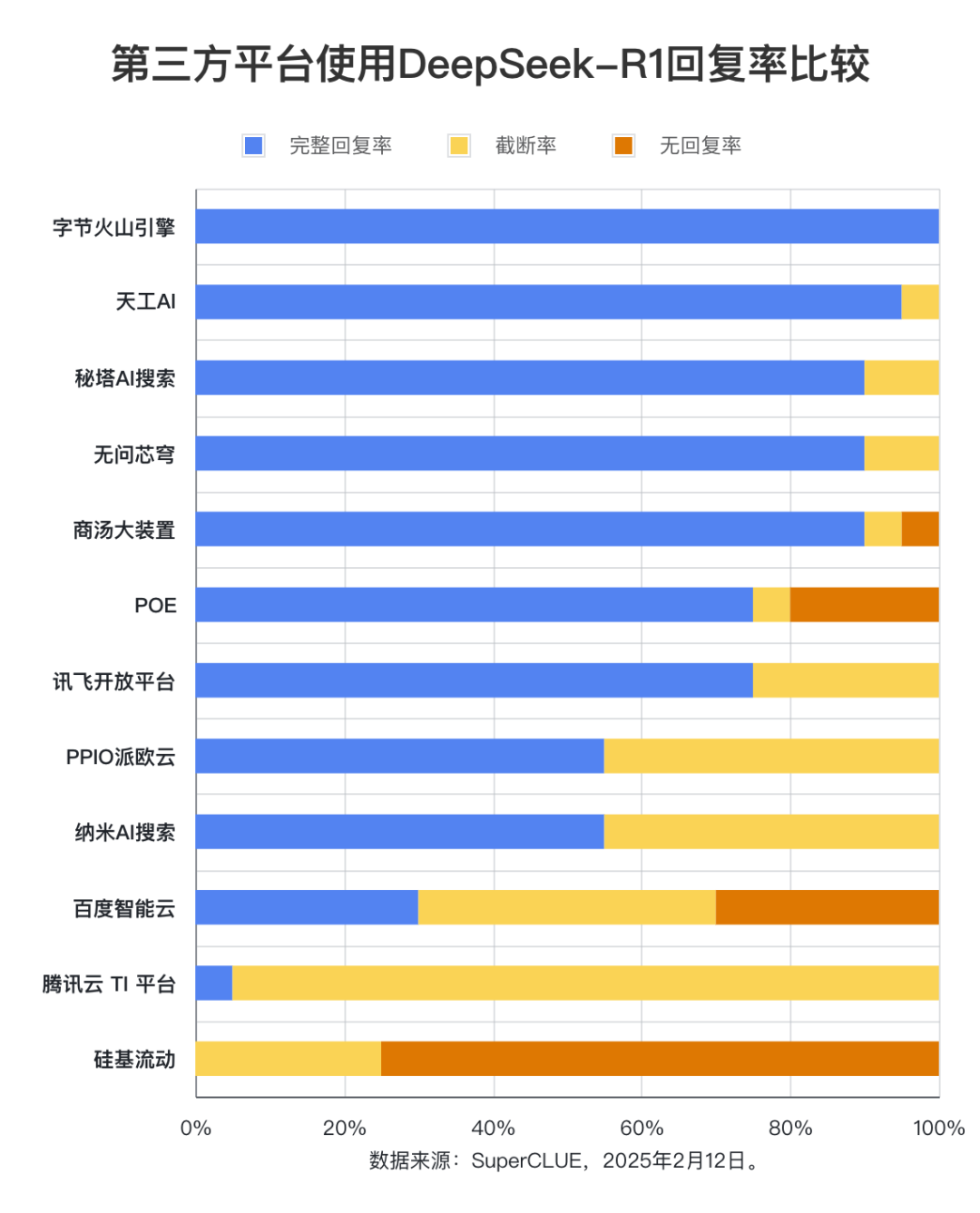
(1) Vollständige Antwortquote
Die Auswertungsdaten zeigen, dass die vollständige Antwortrate von Byte Volcano Engine, Tiangong AI, Secret Tower AI Search, Unquestionable Core Dome und Shangtang Big Device alle mehr als 90% erreichen. Unter ihnen hat die Byte Volcano Engine die beste Leistung mit einer vollständigen Antwortrate von 100%. Im Gegensatz dazu ist die vollständige Antwortrate von Baidu Intelligent Cloud, Tencent Cloud TI Plattform und Silizium-basierter Mobilität deutlich niedriger, mit einer Rate von weniger als 50%. In Bezug auf die Abbruchrate hat die Tencent Cloud TI Plattform eine Rate von bis zu 95%. Silizium-basierte Mobilität hat die häufigsten Fälle von Nicht-Antworten oder Anfragefehlern im Test, mit einer Rate von 75%. Die Antwortrate erreichte 75%.
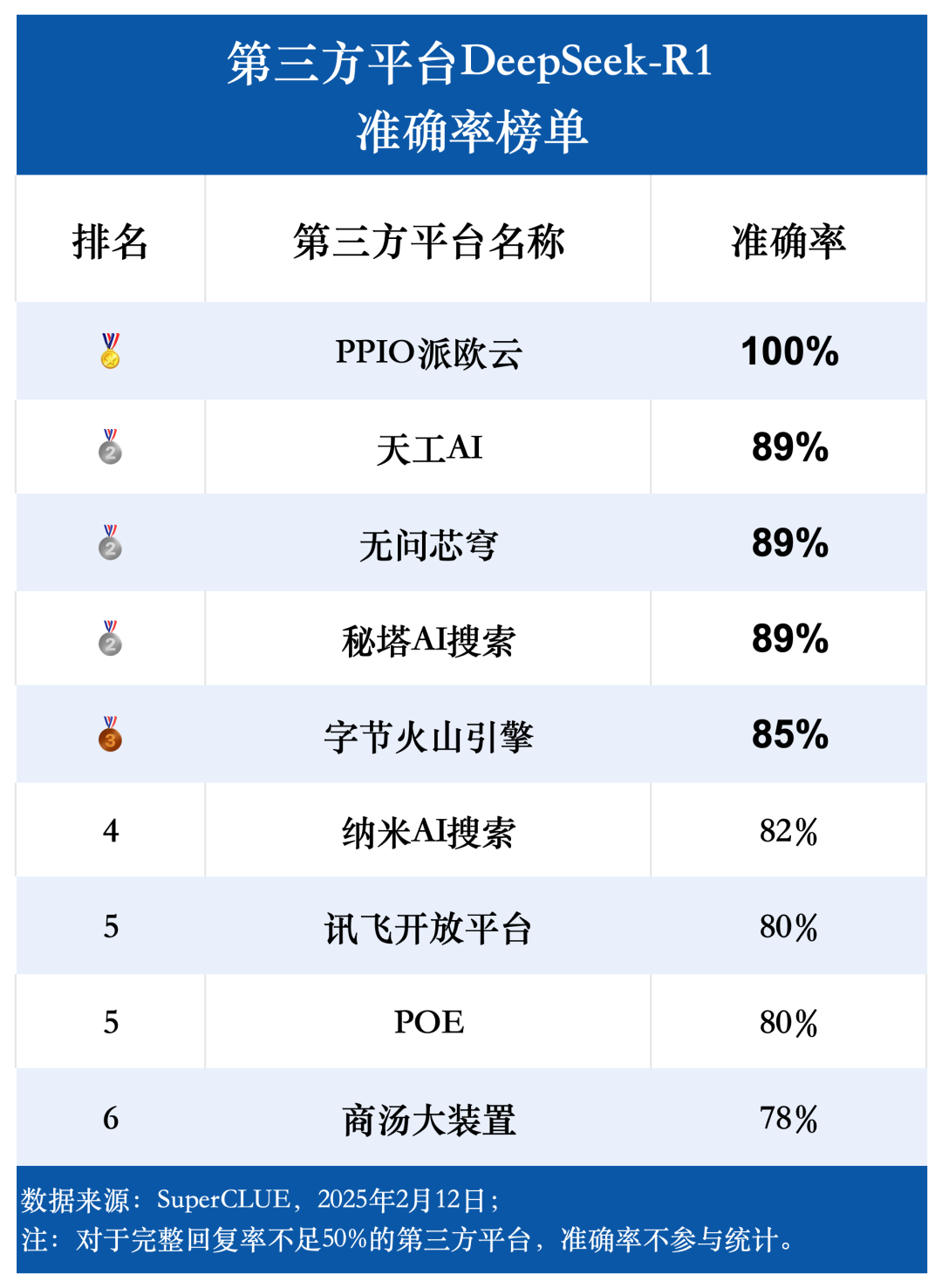
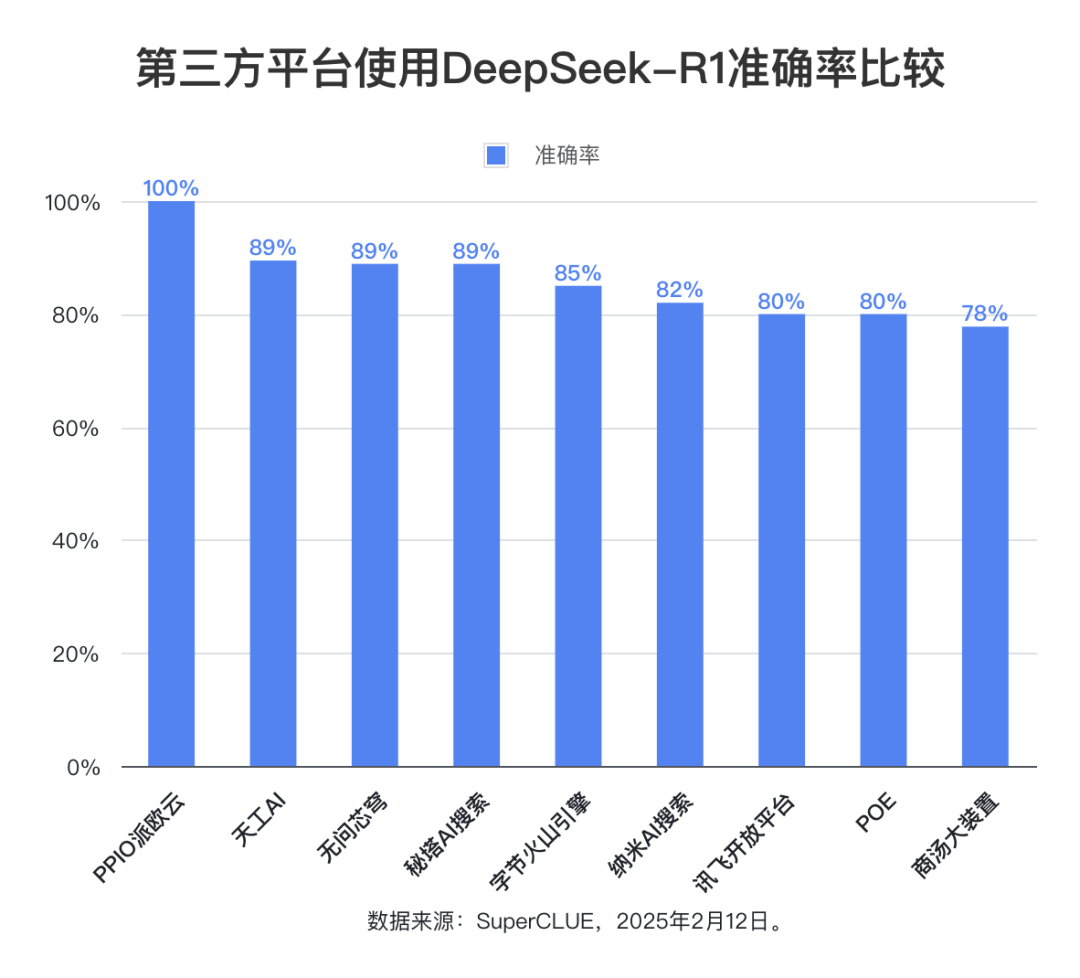
(2) Genauigkeit
Der statistische Bereich der Genauigkeitsrate ist auf die Fragen beschränkt, für die das Modell eine vollständige Antwort gibt, was den Anteil der Fragen widerspiegelt, die vom Modell richtig beantwortet werden. Die Bewertungsergebnisse zeigen, dass die durchschnittliche Genauigkeitsrate von neun Drittanbieterplattformen, die das DeepSeek-R1-Modell verwenden, 85,76% erreicht, was die hohe Qualität und Zuverlässigkeit des DeepSeek-R1-Modells selbst und seine Fähigkeit, stabile und genaue Unterstützung für verschiedene Anwendungsszenarien zu bieten, weiter bestätigt.
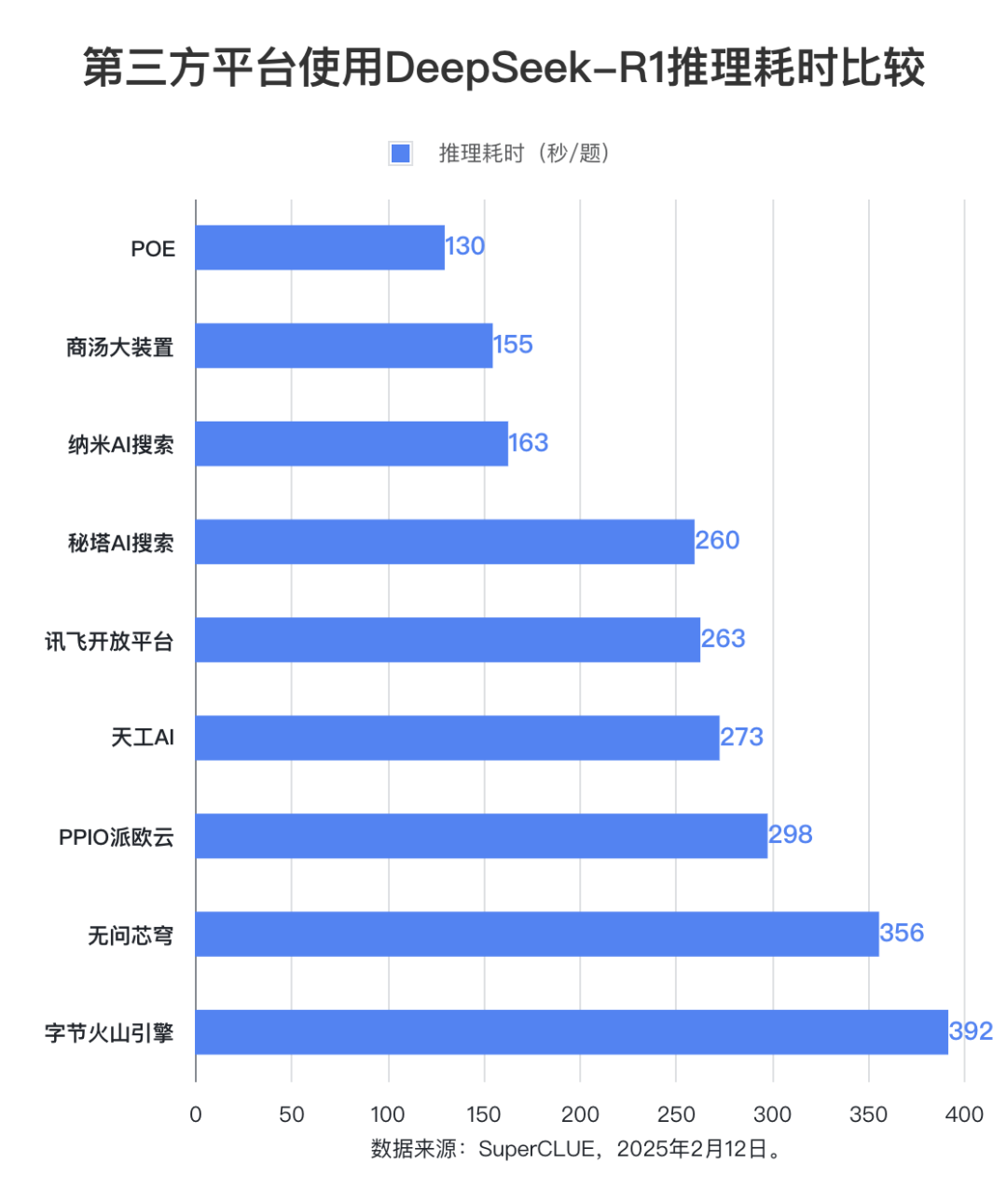
(3) Zeitaufwändige Argumentation
Was die durchschnittliche Schlussfolgerungszeit pro Frage betrifft, so schneidet die POE-Plattform mit 130 Sekunden am besten ab. Die Schlussfolgerungszeit von Shangtang Big Device und Nano AI Search ist ebenfalls relativ kurz, beide liegen unter 200 Sekunden. Die Schlussfolgerungszeit von No Question Vault und Byte Volcano Engine ist relativ lang und liegt bei über 350 Sekunden. Andere Plattformen benötigen zwischen 250 und 300 Sekunden.

Beispiele
Titel: Ein Frosch klettert um 6.00 Uhr morgens einen 10 Meter hohen Brunnen hinauf. Alle 2 Meter, die er klettert, rutscht er 0,5 Meter ab, weil die Wände rutschen. Die Zeit, die er braucht, um 0,5 Meter zu rutschen, ist die Hälfte der Zeit, die er braucht, um 2 Meter den Brunnen hinaufzuklettern. 2,5 Meter vom Brunnenmund entfernt um 6.12 Uhr. Wie viele Minuten hat der Frosch gebraucht, um vom Boden des Brunnens zum Brunnenmund zu klettern?
Standardantwort: 15,2 Minuten (d. h. 15 Minuten 12 Sekunden)
Referenzantwort (vom Modell: Gemini-2.0-Flash-Exp):

Analyse der Ursachen
1. Die Begrenzung der maximalen Ausgabelänge des Modells ist einer der wichtigsten Faktoren, die zu einer Unterbrechung der Antworten führen. Statistiken zeigen, dass einige Plattformen keine flexible Anpassung des max_tokens-Parameters bieten (z. B. Baidu Intelligent Cloud, Tencent Cloud TI-Plattform usw.). Dies macht das Modell anfälliger für Trunkierung, wenn längere Antworten erzeugt werden. Die Daten zeigen, dass die durchschnittliche Abbruchrate von Plattformen, die den max_tokens-Parameter nicht einstellen können, 39% beträgt, während die Abbruchrate von Plattformen, die den Parameter einstellen können, 16.43% beträgt. Insbesondere in dieser Bewertung führen die Komplexität der Fragen der Grundschulolympiade und die Langwierigkeit der Lösung der Fragen zu einem erheblichen Anstieg der Länge des Inhalts, der vom Modell generiert werden muss, und das Problem der Token-Begrenzung wird weiter verstärkt. Das Problem der Token-Begrenzung wird dadurch noch verstärkt.

2. Die Auslastung der Plattform ist ebenfalls ein potenzieller Faktor, der die Stabilität der Modelldienste beeinträchtigt.
In Anbetracht der unterschiedlichen Nutzerzahlen der verschiedenen Plattformen besteht bei Plattformen mit einer größeren Nutzerzahl ein höheres Risiko der Instabilität aufgrund überlasteter Server. Die mangelnde Stabilität der Plattformdienste kann sich indirekt auf die Vollständigkeit und die Ableitungsgeschwindigkeit der modellgenerierten Antworten auswirken.
Schlussfolgerungen und Empfehlungen
1. Es gibt erhebliche Unterschiede in der Stabilitätsleistung verschiedener Plattformen von Drittanbietern, wenn das DeepSeek-R1-Modell eingesetzt und ausgeführt wird. Den Benutzern wird empfohlen, bei der Auswahl einer PlattformIntegrierte Bewertung die technische Architektur, die Ressourcenplanungsmöglichkeiten und die Benutzerbelastung jeder Plattform undIntegration der eigenen Bedürfnisse(z. B. Antwortrate, Rechenzeitverbrauch und andere Indikatoren) zu gewichten. Nutzer, die eine höhere Stabilität anstreben, können Plattformen mit relativ wenigen Nutzern, aber ausgewogenerer Ressourcenzuweisung den Vorzug geben, um das Risiko von Leistungsschwankungen aufgrund hoher Gleichzeitigkeit zu verringern.
2. Die Bewertungsdaten zeigen, dass Plattformen wie Byte Volcano Engine, Tiangong AI, Secret Tower AI Search, No Questions Asked Core Dome und Shangtang Big DeviceVollständige Ansprechraten von 90% und mehr wurden erreichtEs wird vorgeschlagen, dass diese Plattformen die Integrität und Zuverlässigkeit der Modellausgabe gut gewährleisten. Für Anwendungsszenarien, die eine hohe Antwortrate gewährleisten müssen, wird empfohlen, die oben genannten Plattformen für die technische Unterstützung zu bevorzugen.
3. existierenaufwändige BegründungAspekte.POE-Plattformen und große Anlagen in Shangtang Aufgrund ihrer offensichtlichen Vorteile und ihrer geringen Latenz eignet sie sich besser für Anwendungsszenarien mit hohen Echtzeitanforderungen. Den Nutzern wird empfohlen, bei der Auswahl einer Plattform die Empfindlichkeit des Zeitbedarfs für die Inferenz entsprechend den spezifischen Geschäftsanforderungen zu priorisieren, um ein optimales Gleichgewicht zwischen Leistung und Kosten zu erreichen.
Im Anhang finden Sie die DeepSeek-R1-Erfahrungsseite für jede Plattform:
Byte Volcano Engine:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/chat
Siliziumbasierte Strömung: https://cloud.siliconflow.cn/playground/chat/17885302724
Baidu Smart Cloud: https://console.bce.baidu.com/qianfan/ais/console/onlineTest/LLM/DeepSeek-R1
Geheime Turm-KI-Suche: https://metaso.cn/
Keine Fragen zur Kernkuppel: https://cloud.infini-ai.com/genstudio/experience
PPIO Paio Cloud:https://ppinfra.com/llm
Nano AI Suche: https://bot.n.cn/chat?src=AIsearch
Shang Tangs großartiges Gerät: https://console.sensecore.cn/aistudio/experience/conversation
Skyworks AI: https://www.tiangong.cn/
POE:https://poe.com/
Tencent Cloud TI-Plattform: https://console.cloud.tencent.com/tione/v2/aimarket/detail/deepseek_series?regionId=1&detailTab=deep_seek_v1
Cyberoam Open Platform:https://training.xfyun.cn/experience/text2text?type=public&modelServiceId=2501631186799621
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel




Keine Kommentare...