Step-Audio-AQAA - End-to-End Big Audio Language Model von StepFun

Was ist Step-Audio-AQAA?
Step-Audio-AQAA ist ein End-to-End-Audiosprachmodell für Audio-Query-Audio-Response (AQAA)-Aufgaben des StepFun-Teams. Die Fähigkeit, Audioeingaben direkt zu verarbeiten, um natürliche, genaue Sprachantworten zu erzeugen, ohne auf traditionelle automatische Spracherkennung (ASR) und Text-to-Speech (TTS) Module zurückzugreifen, vereinfacht die Systemarchitektur und eliminiert kaskadierende Fehler.Step-Audio-AQAA's Trainingsprozess beinhaltet multimodales Pre-Training, Supervised Fine-Tuning (SFT), Direct Preference Optimisation (DPO) und Modell-Merging. Durch diese Methoden erbringen die Modelle gute Leistungen bei komplexen Aufgaben wie Sprach-Emotionskontrolle, Rollenspielen und logischem Schlussfolgern. Im StepEval-Audio-360-Benchmark übertrifft Step-Audio-AQAA bestehende LALM-Modelle in mehreren Schlüsseldimensionen und zeigt damit ein großes Potenzial für eine durchgängige Sprachinteraktion.
Step-Audio-AQAA Hauptmerkmale
- Direkte Verarbeitung von AudioeingängenGeneriert Sprachantworten direkt aus der Audioeingabe, ohne auf herkömmliche automatische Spracherkennung (ASR) und Text-to-Speech-Module (TTS) zurückzugreifen.
- Nahtlose SprachinteraktionUnterstützung von Voice-to-Speech-Interaktion: Benutzer können Fragen mit ihrer Stimme stellen, und das Modell antwortet direkt mit ihrer Stimme, was die Natürlichkeit und den reibungslosen Ablauf der Interaktion verbessert.
- Anpassung des emotionalen TonsUnterstützung bei der Anpassung des emotionalen Tons der Sprache auf Satzebene, z. B. um Gefühle wie Freude, Traurigkeit oder Ernsthaftigkeit auszudrücken.
- SprachsteuerungDer Benutzer kann die Geschwindigkeit der Sprachausgabe nach Bedarf anpassen, um sie besser auf die Anforderungen des Szenarios abzustimmen.
- Klang- und TonhöhensteuerungEs kann den Tonfall und die Tonhöhe der Stimme entsprechend den Benutzerbefehlen einstellen und sich so an verschiedene Rollen oder Szenarien anpassen.
- mehrsprachige InteraktionUnterstützt Chinesisch, Englisch, Japanisch und andere Sprachen, um den Sprachbedürfnissen der verschiedenen Benutzer gerecht zu werden.
- Unterstützung von DialektenEinbeziehung chinesischer Dialekte wie Sichuan und Kantonesisch, um die Anwendbarkeit des Modells in bestimmten Regionen zu verbessern.
- sprachgesteuerte EmotionskontrolleKann auf der Grundlage von Kontext und Benutzerbefehlen Sprachantworten mit bestimmten Emotionen erzeugen.
- Rollenspiele (Spiel)Unterstützt das Spielen bestimmter Rollen in einem Dialog, z. B. Kundendienst, Lehrer, Freund usw., und das Erzeugen von Sprachantworten, die den Eigenschaften der Rolle entsprechen.
- Quiz zum logischen Denken und WissenKann komplexe Aufgaben zum logischen Denken und Wissensabfragen bewältigen und genaue Sprachantworten geben.
- Hohe Qualität der SprachausgabeGenerieren Sie mit Hilfe eines neuronalen Vocoders naturgetreue, natürliche und weiche Sprachwellenformen, um das Benutzererlebnis zu verbessern.
- phonetische KohärenzKohärenz und Konsistenz der Sprache in langen Sätzen oder Absätzen beibehalten, Sprechpausen oder abrupte Wechsel vermeiden.
- Verschachtelte Text- und SprachausgabeUnterstützt verschachtelte Text- und Sprachausgabe, so dass die Benutzer je nach Bedarf zwischen Sprach- und Textantworten wählen können.
- Multimodale Eingabe VerstehenKann gemischte Eingaben, die Sprache und Text enthalten, verstehen und entsprechende Sprachreaktionen erzeugen.
Projektadresse von Step-Audio-AQAA
- HuggingFace-Modellbibliothek:: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- arXiv Technisches Papier:: https://arxiv.org/pdf/2506.08967
Technische Grundlagen von Step-Audio-AQAA
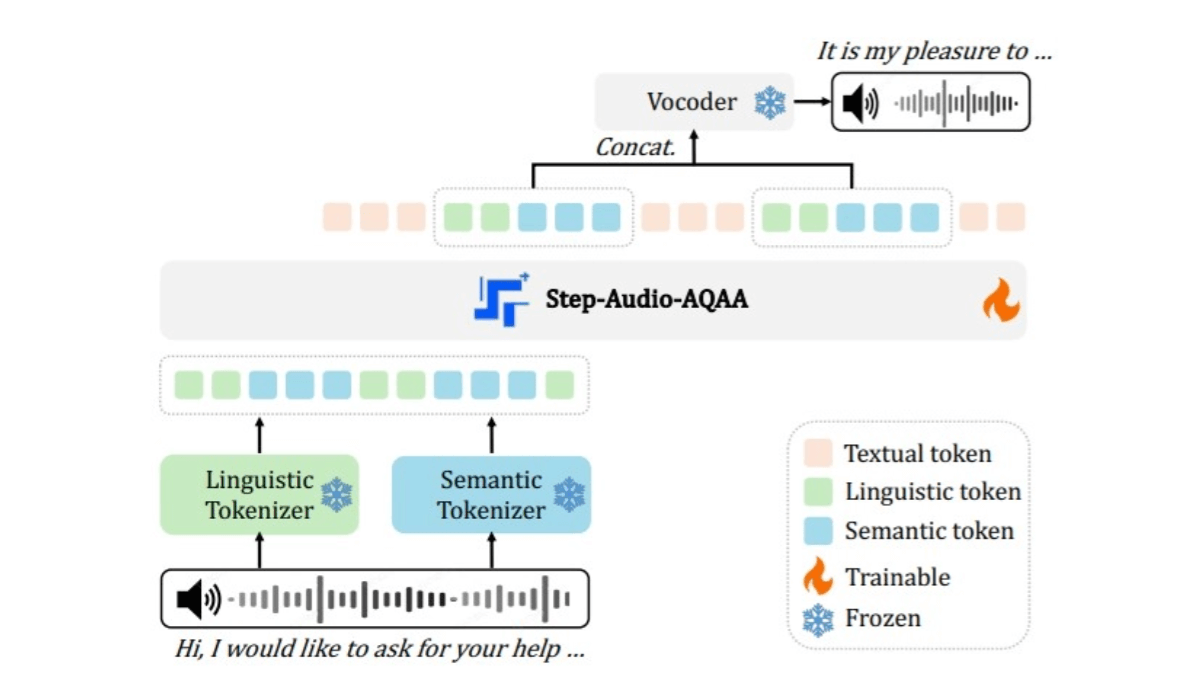
- Dual Codebook Audio SplitterKonvertiert das Eingangsaudiosignal in eine strukturierte Abfolge von Token. Es besteht aus zwei Lexika: ein linguistisches Lexikon extrahiert Phoneme und linguistische Attribute der Sprache, abgetastet bei 16,7 Hz mit einer Codebuchgröße von 1024, und ein semantisches Lexikon erfasst akustische Merkmale der Sprache, wie Emotion und Intonation, abgetastet bei 25 Hz mit einer Codebuchgröße von 4096, was eine bessere Möglichkeit ist, die Komplexität der Informationen in der Sprache zu erfassen.
- Backbone LLMMit Hilfe eines vortrainierten multimodalen LLM (Step-Omni) mit 130 Milliarden Parametern decken die vortrainierten Daten drei Modalitäten ab: Text, Sprache und Bild. Bicode-Text-Audio-Token werden in einen einheitlichen Vektorraum eingebettet, und zwar mittels mehrerer Transformator Blöcke für tiefes semantisches Verständnis und Merkmalsextraktion.
- neuronaler VocoderSynthetisiert die generierten Audio-Token in natürliche, hochwertige Sprachwellenformen. Die U-Net-Architektur, kombiniert mit der ResNet-1D-Schicht und dem Transformer-Block, wandelt diskrete Audiomarken effizient in kontinuierliche Sprachwellenformen um.
Die wichtigsten Vorteile von Step-Audio-AQAA
- End-to-End-Audio-InteraktionStep-Audio-AQAA generiert natürliche, flüssige Sprachantworten direkt aus dem Audio-Rohmaterial und macht herkömmliche automatische Spracherkennung (ASR) und Text-to-Speech-Module (TTS) überflüssig. Das End-to-End-Design vermeidet die Verzerrung der Ergebnisse, die durch Fehler in ASR oder TTS in herkömmlichen Lösungen verursacht werden.
- Unterstützung mehrerer SprachenDas Modell unterstützt mehrere Sprachen, darunter Chinesisch (einschließlich Sichuanisch und Kantonesisch), Englisch, Japanisch usw., was den Sprachbedürfnissen verschiedener Benutzer gerecht wird.
- Feinkörnige Steuerung der SprachfunktionenStep-Audio-AQAA ermöglicht eine feinkörnige Steuerung von Sprachmerkmalen, wie z.B. emotionale Intonation, Sprechgeschwindigkeit, usw., um reaktionsschnellere Sprachreaktionen zu erzeugen. Es ist besonders gut bei der Steuerung von Emotionen.
Für wen ist Step-Audio-AQAA gedacht?
- Benutzer von intelligenten SprachassistentenBenutzer, die Geräte mit Sprachinteraktion (z. B. intelligente Lautsprecher, intelligente Assistenten) für alltägliche Vorgänge (z. B. Abrufen von Informationen, Einstellen von Erinnerungen, Abspielen von Musik usw.) verwenden möchten.
- SpielebegeisterterSpieler, die gerne mit NPCs im Spiel interagieren, um ein intensiveres Spielerlebnis zu erhalten.
- Benutzer im BildungswesenSchüler und Eltern, die durch Sprachinteraktion lernen wollen (z. B. Sprachenlernen, Wissensquiz usw.).
- Ältere Menschen und KinderSprachliche Interaktion ist bequemer und natürlicher für Benutzer, die mit der Texteingabe nicht vertraut sind.
- HörbucherstellerKreative, die qualitativ hochwertige Sprachinhalte erstellen müssen, wie z. B. Hörbücher, Hörspiele usw.
- VideoproduzentKreative, die bei der Produktion von Videoinhalten (z. B. Kurzvideos, Live-Streams) Sprachinteraktions- oder Spracherzeugungsfunktionen benötigen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...