Step-Audio: ein multimodales Sprachinteraktionssystem, das u. a. Sprache erkennt und mit geklonter Sprache kommuniziert

Allgemeine Einführung
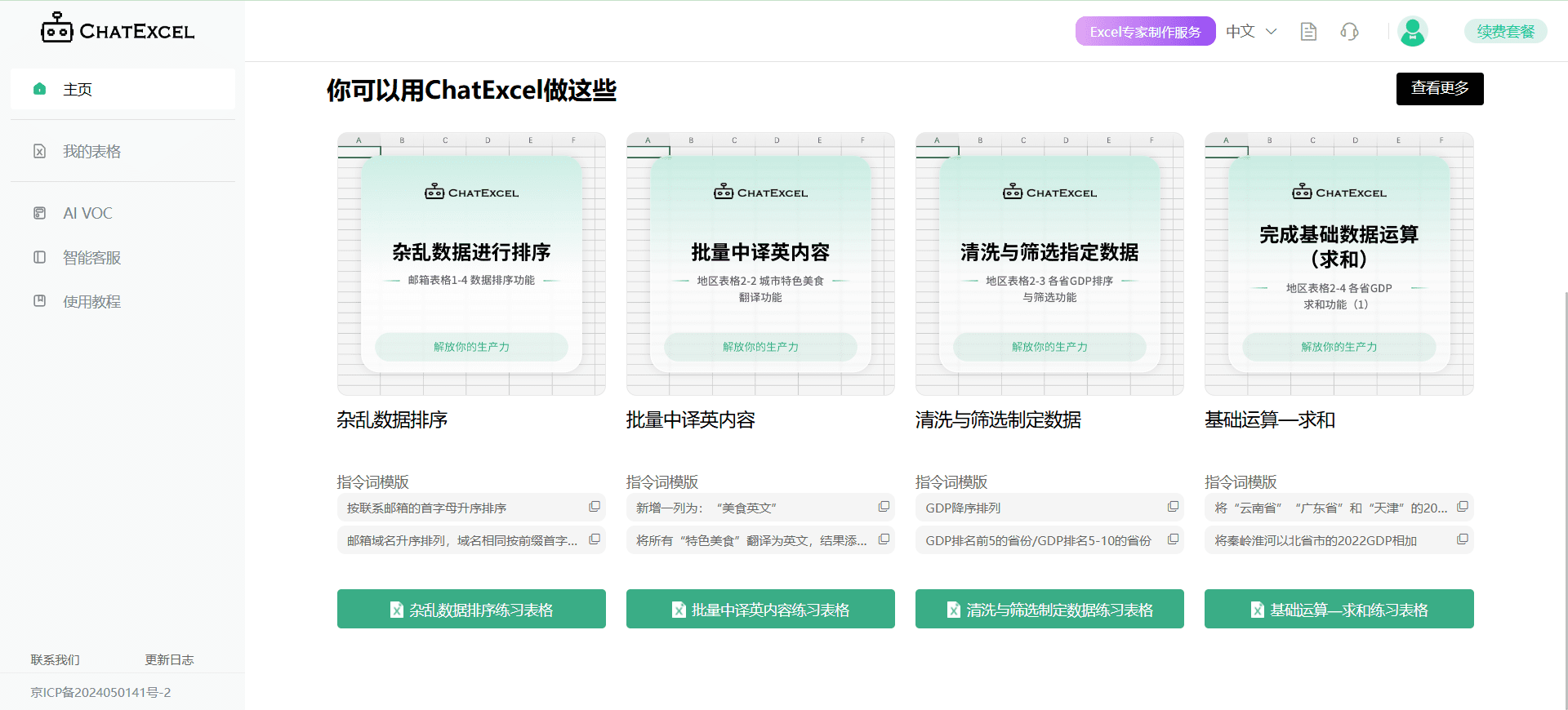
Step-Audio ist ein Open-Source-Framework für intelligente Sprachinteraktion, das sofort einsetzbare Sprachverstehens- und -erzeugungsfunktionen für Produktionsumgebungen bietet. Das Framework unterstützt mehrsprachige Dialoge (z.B. Chinesisch, Englisch, Japanisch), emotionale Sprache (z.B. fröhlich, traurig), regionale Dialekte (z.B. Kantonesisch, Szechuan) und einstellbare Sprechgeschwindigkeit und Reimstile (z.B. Rap). Step-Audio implementiert Spracherkennung, semantisches Verständnis, Dialog, Sprachklonen und Sprachsynthese durch ein multimodales Modell mit 130B-Parametern. Seine generative Daten-Engine macht die Abhängigkeit von der traditionellen manuellen TTS-Datenerfassung überflüssig, indem sie qualitativ hochwertige Audiodaten erzeugt, um das ressourceneffiziente Step-Audio-TTS-3B-Modell zu trainieren und zu veröffentlichen.

Funktionsliste
- Echtzeit-Spracherkennung (ASR): wandelt Sprache in Text um und unterstützt eine hochpräzise Erkennung.
- Text-to-Speech-Synthese (TTS): Wandelt Text in natürliche Sprache um und unterstützt eine breite Palette von Emotionen und Intonationen.
- Mehrsprachige Unterstützung: Unterstützt Sprachen wie Chinesisch, Englisch, Japanisch und Dialekte wie Kantonesisch und Szechuan.
- Emotions- und Intonationskontrolle: Anpassung der Emotionen (z. B. fröhlich, traurig) und des Reimstils (z. B. RAP, Summen) der Sprachausgabe.
- Voice Cloning: Generieren Sie eine ähnliche Stimme auf der Grundlage der eingegebenen Stimme und unterstützen Sie die individuelle Gestaltung Ihrer Stimme.
- Dialogmanagement: Bewahren Sie die Kontinuität des Dialogs und verbessern Sie das Benutzererlebnis mit dem Context Manager.
- Open-Source-Toolchain: bietet vollständigen Code und Modellgewichte, die Entwickler direkt verwenden oder doppelt entwickeln können.
Hilfe verwenden
Step-Audio ist ein leistungsstarkes Open-Source-Framework für multimodale Sprachinteraktion, mit dem Entwickler Echtzeit-Sprachanwendungen erstellen können. Nachfolgend finden Sie eine detaillierte Schritt-für-Schritt-Anleitung zur Installation und Verwendung von Step-Audio sowie zu seinen Funktionen, um sicherzustellen, dass Sie einfach loslegen und das volle Potenzial nutzen können.
Einbauverfahren
Um Step-Audio zu verwenden, müssen Sie die Software in einer Umgebung mit einer NVIDIA GPU installieren. Nachfolgend finden Sie die detaillierten Schritte:
- Vorbereitung der Umwelt::
- Stellen Sie sicher, dass Sie Python 3.10 auf Ihrem System installiert haben.
- Installieren Sie Anaconda oder Miniconda, um die virtuelle Umgebung zu verwalten.
- Vergewissern Sie sich, dass der NVIDIA-GPU-Treiber und die CUDA-Unterstützung installiert sind. Für die beste Generierungsqualität werden 4xA800/H800-GPUs (80 GB RAM) empfohlen.
- Klon-Lager::
- Öffnen Sie ein Terminal und führen Sie den folgenden Befehl aus, um das Step-Audio-Repository zu klonen:
git clone https://github.com/stepfun-ai/Step-Audio.git cd Step-Audio
- Öffnen Sie ein Terminal und führen Sie den folgenden Befehl aus, um das Step-Audio-Repository zu klonen:
- Erstellen einer virtuellen Umgebung::
- Erstellen und aktivieren Sie eine virtuelle Python-Umgebung:
conda create -n stepaudio python=3.10 conda activate stepaudio
- Erstellen und aktivieren Sie eine virtuelle Python-Umgebung:
- Installation von Abhängigkeiten::
- Installieren Sie die erforderlichen Bibliotheken und Tools:
pip install -r requirements.txt git lfs install - Klonen zusätzlicher Modellgewichte:
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat git clone https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B
- Installieren Sie die erforderlichen Bibliotheken und Tools:
- Überprüfen der Installation::
- Ausführen eines einfachen Testskripts (wie im Beispielcode)
run_example.py), um sicherzustellen, dass alle Komponenten ordnungsgemäß funktionieren.
- Ausführen eines einfachen Testskripts (wie im Beispielcode)
Sobald die Installation abgeschlossen ist, können Sie die verschiedenen Funktionen von Step-Audio nutzen. Im Folgenden finden Sie eine detaillierte Anleitung zur Bedienung der Haupt- und Sonderfunktionen.
Hauptfunktionen
1. die Spracherkennung in Echtzeit (ASR)
Die Spracherkennungsfunktion von Step-Audio wandelt die Spracheingabe des Benutzers in Text um und eignet sich daher für den Aufbau von Sprachassistenten oder Echtzeit-Transkriptionssystemen.
- Verfahren::
- Stellen Sie sicher, dass das Mikrofon angeschlossen und konfiguriert ist.
- Verwenden Sie das mitgelieferte
stream_audio.pySkript zum Starten von Live-Audio-Streaming:python stream_audio.py --model Step-Audio-Chat - Wenn Sie sprechen, wandelt das System Sprache in Echtzeit in Text um und gibt das Ergebnis auf dem Terminal aus. Sie können das Protokoll überprüfen, um die Erkennungsgenauigkeit zu bestätigen.
- Ausgewählte FunktionenUnterstützt die Erkennung mehrerer Sprachen und Dialekte, z. B. gemischte chinesische und englische Eingaben oder lokalisierte Sprache wie Kantonesisch und Sichuan.
2. die Text-zu-Sprache-Synthese (TTS)
Mit der TTS-Funktion können Sie jeden Text in natürliche Sprache umwandeln, wobei eine breite Palette von Emotionen, Sprechgeschwindigkeiten und Stilen unterstützt wird.
- Verfahren::
- Bereiten Sie den zu synthetisierenden Text vor, z.B. speichern als
input.txt. - ausnutzen
text_to_speech.pySkripte zur Erzeugung von Sprache:python text_to_speech.py --model Step-Audio-TTS-3B --input input.txt --output output.wav --emotion happy --speed 1.0 - Parameter Beschreibung:
--emotionLegen Sie die Emotion fest (z. B. glücklich, traurig, neutral).--speedEinstellen der Sprechgeschwindigkeit (0,5 für langsam, 1,0 für normal, 2,0 für schnell).--output: Gibt den Pfad der Ausgabe-Audiodatei an.
- Bereiten Sie den zu synthetisierenden Text vor, z.B. speichern als
- Ausgewählte FunktionenUnterstützt die Erzeugung von z.B. RAP- und Brummton-Sprachstilen:
python text_to_speech.py --model Step-Audio-TTS-3B --input rap_lyrics.txt --style rap --output rap_output.wav
这将生成一段带有 RAP 节奏的音频,非常适合音乐或娱乐应用。
#### 3. 多语言与情感控制
Step-Audio 支持多种语言和情感控制,适合国际化应用开发。
- **操作步骤**:
- 选择目标语言和情感,例如生成日语悲伤语气语音:
python generate_speech.py --language japanese --emotion sad --text "私は悲しいです" --output sad_jp.wav
- 方言支持:如果需要粤语输出,可以指定:
python generate_speech.py --dialect Kantonesisch --text "Ich hänge so an dir" --output Kantonesisch.wav
- **特色功能**:通过指令可以无缝切换语言和方言,适合构建跨文化语音交互系统。
#### 4. 语音克隆
语音克隆允许用户上传一段语音样本,生成相似的声音,适用于个性化语音设计。
- **操作步骤**:
- 准备一个音频样本(如 `sample.wav`),确保音频清晰。
- 使用 `voice_clone.py` 进行克隆:
python voice_clone.py --input sample.wav --output cloned_voice.wav --model Step-Audio-Chat
- 生成的 `cloned_voice.wav` 将模仿输入样本的音色和风格。
- **特色功能**:支持高保真克隆,适用于虚拟主播或定制语音助手。
#### 5. 对话管理与上下文保持
Step-Audio 内置上下文管理器,确保对话的连续性和逻辑性。
- **操作步骤**:
- 启动对话系统:
python chat_system.py --model Schritt-Audio-Chat
- Geben Sie Text oder Sprache ein, und das System generiert eine kontextabhängige Antwort. Beispiel:
- Benutzer: "Wie ist das Wetter heute?"
- SYSTEM: "Bitte sagen Sie mir, wo Sie sich befinden, und ich werde es überprüfen."
- Benutzer: "Ich bin in Peking."
- SYSTEM: "In Peking ist es heute sonnig, die Temperatur beträgt 15°C."
- Ausgewählte FunktionenUnterstützt mehrere Dialogrunden, speichert kontextbezogene Informationen und eignet sich für Kundendienst-Bots oder intelligente Assistenten.
caveat
- Hardware-VoraussetzungVergewissern Sie sich, dass der Grafikprozessor über genügend Speicher verfügt. 80 GB oder mehr werden für eine optimale Leistung empfohlen.
- NetzanschlussEinige der Modellgewichte müssen von Hugging Face heruntergeladen werden, um ein stabiles Netzwerk zu gewährleisten.
- FehlererkennungWenn Sie auf Installations- oder Laufzeitfehler stoßen, überprüfen Sie die Protokolldateien oder schauen Sie auf der GitHub Issues-Seite nach, um Hilfe zu erhalten.
Wenn Sie diese Schritte befolgen, können Sie die Leistungsfähigkeit von Step-Audio voll ausschöpfen, ganz gleich, ob Sie Echtzeit-Sprachanwendungen entwickeln, personalisierte Sprachinhalte erstellen oder ein mehrsprachiges Dialogsystem aufbauen. Der Open-Source-Charakter von Step-Audio ermöglicht es Ihnen außerdem, den Code zu modifizieren und das Modell nach Bedarf zu optimieren, um Ihre spezifischen Projektanforderungen zu erfüllen.
© urheberrechtliche Erklärung
Artikel Copyright AI-Austauschkreis Alle, bitte nicht ohne Erlaubnis vervielfältigen.
Ähnliche Artikel


Keine Kommentare...