Wie wir alle wissen, müssen wir, wenn wir ein großes Sprachmodell eine Aufgabe ausführen lassen wollen, eine Eingabeaufforderung (Prompt) eingeben, um die Ausführung zu steuern, die mit natürlicher Sprache beschrieben wird. Einfache Aufgaben können mit natürlicher Sprache klar beschrieben werden, wie z. B.: "Bitte übersetzen Sie das Folgende ins vereinfachte Chinesisch:", "Bitte erstellen Sie eine Zusammenfassung des Folgenden:", usw.
Wenn wir jedoch auf komplexe Aufgaben stoßen, wie z. B. die Anforderung, dass das Modell ein bestimmtes JSON-Format generieren muss, oder wenn die Aufgabe mehrere Zweige hat, jeder Zweig mehrere Teilaufgaben ausführen muss und die Teilaufgaben miteinander verknüpft sind, dann sind natürlichsprachliche Beschreibungen nicht ausreichend.
Diskussionsthema
Hier sind zwei Fragen, die zum Nachdenken anregen sollen, bevor Sie weiter lesen:
- Es gibt mehrere lange Sätze, von denen jeder in kürzere Sätze von höchstens 80 Zeichen aufgeteilt und dann in ein JSON-Format ausgegeben werden muss, das die Entsprechung zwischen den langen und kurzen Sätzen klar beschreibt.
Zum Beispiel:
[
{
"long": "Dies ist ein langer Satz, der in kürzere Sätze aufgeteilt werden muss.", "short": [ [ {
"kurz": [
"Dies ist ein langer Satz", "der aufgeteilt werden muss", "short": [
"This is a long sentence that needs to be split", "short": [ "This is a long sentence", "that needs to be split", "into shorter sentences.
"This is a long sentence", "that needs to be split", "into shorter sentences."
Dies ist ein langer Satz, der in kürzere Sätze aufgeteilt werden muss].
}, { "short".
}, {
"long": "Ein weiterer langer Satz, der in kürzere Sätze aufgeteilt werden sollte.", "short": [ "that needs to be split", "into shorter sentences." ] }, {
"kurz": [
"Ein weiterer langer Satz", "der aufgeteilt werden sollte", "short": [
"that should be split", "short": [ "Another long sentence", "that should be split", "short".
"into shorter sentences."
]
}
]
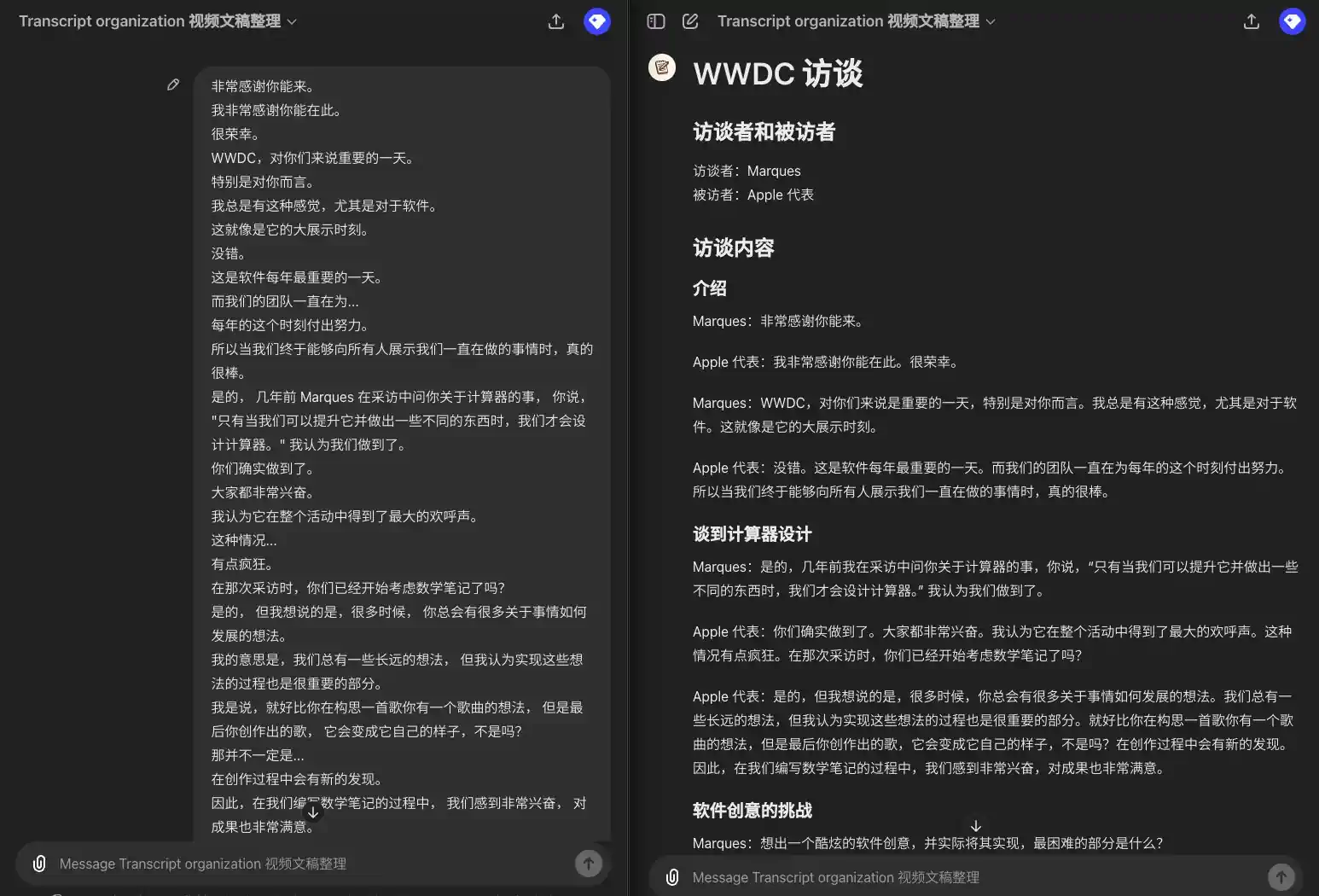
- Ein Originaltext mit Untertiteln, der nur Dialoginformationen enthält, aus denen Sie nun Kapitel und Sprecher extrahieren und die Dialoge nach Kapitel und Absatz auflisten müssen. Wenn es mehrere Sprecher gibt, muss jedem Dialog der jeweilige Sprecher vorangestellt werden, nicht aber, wenn derselbe Sprecher nacheinander spricht. (Dies ist eigentlich ein GPT, das ich selbst verwende, um Videoskripte zu organisieren. Zusammenstellung von Videoskripten GPT)
Beispiel Eingabe:
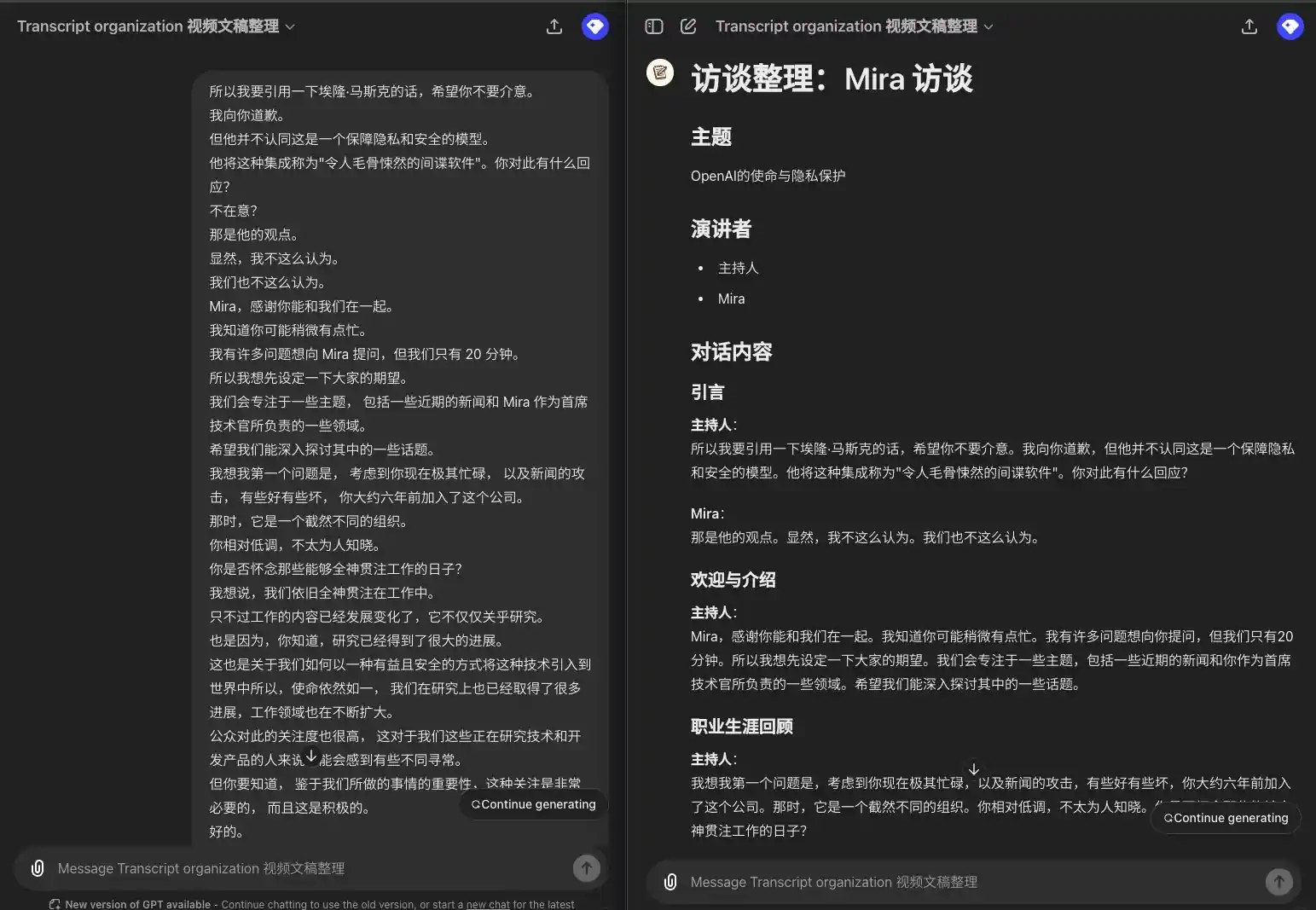
Ich werde jetzt Elon Musk zitieren, und ich hoffe, es macht Ihnen nichts aus. Ich bitte um Entschuldigung. Aber er ist nicht der Meinung, dass dies ein Modell für Datenschutz und Sicherheit ist. Er bezeichnete die Integration als "gruselige Spionagesoftware". Was ist Ihre Antwort darauf? Es ist mir egal? Das ist seine Meinung. Ich sehe das natürlich nicht so. Und wir auch nicht. Mira, danke, dass du bei uns bist. Ich weiß, Sie sind wahrscheinlich ein wenig beschäftigt. Ich habe eine Menge Fragen an Mira, aber wir haben nur 20 Minuten Zeit. Daher möchte ich zunächst einige Erwartungen formulieren. Wir werden uns auf eine Reihe von Themen konzentrieren, darunter einige aktuelle Nachrichten und einige von Miras Aufgabenbereichen als CTO. Ich hoffe, dass wir in der Lage sein werden, in einige dieser Themen einzutauchen. Ich denke, meine erste Frage ist, dass Sie angesichts der Tatsache, dass Sie gerade sehr beschäftigt sind, und der Angriffe in den Nachrichten, einige gut, einige schlecht, vor etwa sechs Jahren in das Unternehmen eingetreten sind. Damals war es eine ganz andere Organisation. Sie waren relativ unauffällig und nicht sehr bekannt. Vermissen Sie die Zeiten, in denen Sie sich auf Ihre Arbeit konzentrieren konnten? Ich würde sagen, wir sind immer noch voll in unsere Arbeit eingebunden. Nur hat sich die Arbeit weiterentwickelt, und es geht nicht mehr nur um Forschung. Es geht auch um Forschung, die einen langen Weg zurückgelegt hat. Es geht auch darum, wie wir diese Technologie auf eine Weise in die Welt bringen können, die nützlich und sicher ist. Das Interesse der Öffentlichkeit ist groß, was für diejenigen von uns, die an Technologien arbeiten und Produkte entwickeln, vielleicht etwas ungewöhnlich ist. Aber wissen Sie, angesichts der Bedeutung dessen, was wir tun, ist diese Aufmerksamkeit sehr notwendig, und sie ist positiv.
Beispielhafte Ausgabe:
### Einführung **Moderator**: Ich werde jetzt Elon Musk zitieren, ich hoffe, es macht Ihnen nichts aus. Ich bitte um Entschuldigung, aber er ist nicht der Meinung, dass dies ein Modell für Datenschutz und Sicherheit ist. Er bezeichnete diese Integration als "gruselige Spionagesoftware". Was ist Ihre Antwort darauf? **Das ist seine Meinung: Das ist seine Meinung. Ich sehe das natürlich nicht so. Wir denken auch nicht so. ### Willkommen und Vorstellung **Gastgeber**: Mira, danke, dass du bei uns bist. Ich weiß, dass Sie wahrscheinlich etwas beschäftigt sind. Ich habe eine Menge Fragen an Sie, aber wir haben nur 20 Minuten Zeit. Deshalb möchte ich zunächst Ihre Erwartungen erfüllen. Wir werden uns auf eine Reihe von Themen konzentrieren, darunter einige aktuelle Nachrichten und einige der Bereiche, für die Sie als CTO verantwortlich sind. Hoffentlich können wir einige dieser Themen vertiefen. ### Karriere-Rückblick **Gastgeber**: Angesichts der Tatsache, dass Sie im Moment sehr beschäftigt sind, und der Angriffe in den Nachrichten, die mal gut, mal schlecht waren, möchte ich Ihnen zunächst eine Frage stellen: Sie sind vor etwa sechs Jahren zu diesem Unternehmen gekommen. Damals war es ein ganz anderes Unternehmen. Sie waren relativ unauffällig und nicht sehr bekannt. Vermissen Sie die Zeit, in der Sie sich voll und ganz Ihrer Arbeit widmen konnten? **Mira**: Ich würde sagen, dass wir immer noch voll in unserer Arbeit aufgehen. Es ist nur so, dass sich die Arbeit weiterentwickelt hat und es nicht nur um Forschung geht. Das liegt auch daran, dass die Forschung große Fortschritte gemacht hat. Es geht auch darum, wie wir diese Technologie auf eine nützliche und sichere Weise in die Welt bringen können. Der Auftrag bleibt also derselbe, und wir haben auch in der Forschung große Fortschritte gemacht, und die Arbeitsbereiche werden erweitert. Es gibt auch ein großes öffentliches Interesse an diesem Thema, was für diejenigen von uns, die an der Technologie arbeiten und das Produkt entwickeln, vielleicht etwas ungewöhnlich ist. Aber man muss sich darüber im Klaren sein, dass diese Aufmerksamkeit in Anbetracht der Bedeutung dessen, was wir tun, sehr notwendig ist, und sie ist positiv.
Die Essenz von Prompt
Vielleicht haben Sie im Internet viele Artikel darüber gelesen, wie man Prompt-Techniken schreibt, und viele Prompt-Vorlagen auswendig gelernt, aber was ist das Wesentliche an Prompt? Warum brauchen wir Prompt?
Prompt ist im Wesentlichen eine Steueranweisung an den LLM, die in natürlicher Sprache beschrieben ist und es dem LLM ermöglicht, unsere Anforderungen zu verstehen und dann die Eingaben in die gewünschten Ausgaben zu verwandeln.
Die häufig verwendete "few-shot"-Technik besteht zum Beispiel darin, den LLM unsere Anforderungen anhand von Beispielen verstehen zu lassen und sich dann auf die Beispiele zu beziehen, um unsere gewünschten Ergebnisse auszugeben. CoT (Chain of Thought) z.B. bedeutet, die Aufgabe künstlich zu zerlegen und den Ausführungsprozess zu begrenzen, so dass der LLM dem von uns spezifizierten Prozess und den Schritten folgen kann, ohne zu diffus zu sein oder die wichtigsten Schritte zu überspringen und somit bessere Ergebnisse zu erzielen.
Es ist wie in der Schule: Wenn der Lehrer über mathematische Theoreme sprach, musste er uns Beispiele geben, anhand derer wir die Bedeutung der Theoreme verstehen konnten; wenn wir Experimente durchführten, musste er uns die Schritte der Experimente erklären, und selbst wenn wir die Prinzipien der Experimente nicht verstanden, aber die Experimente gemäß den Schritten durchführen konnten, konnten wir immer noch mehr oder weniger die gleichen Ergebnisse erzielen.
Woran liegt es, dass die Ergebnisse von Prompt manchmal nicht optimal sind?
Dies liegt daran, dass der LLM unsere Anforderungen nicht genau verstehen kann, was einerseits durch die Fähigkeit des LLM, Anweisungen zu verstehen und zu befolgen, und andererseits durch die Klarheit und Genauigkeit unserer Prompt-Beschreibung begrenzt ist.
Wie man die Ausgabe des LLM genau kontrolliert und seine Ausführungslogik mit Hilfe von Pseudocode definiert
Da Prompt im Wesentlichen eine Steueranweisung für den LLM ist, können wir Prompt schreiben, ohne uns auf traditionelle Beschreibungen in natürlicher Sprache zu beschränken, sondern können auch Pseudocode verwenden, um die Ausgabe des LLM genau zu steuern und seine Ausführungslogik zu definieren.
Was ist Pseudocode?
Pseudocode ist eine formale Beschreibungsmethode zur Beschreibung von Algorithmen, eine Art Beschreibungsmethode zwischen natürlicher Sprache und Programmiersprache zur Beschreibung von Algorithmusschritten und -prozessen. In verschiedenen Algorithmus-Büchern und -Aufsätzen sehen wir oft die Beschreibung von Pseudocode, auch wenn man nicht in eine Sprache einsteigen muss, sondern auch durch den Pseudocode die Ausführung des Algorithmusablaufs verstehen kann.
Wie gut versteht der LLM also Pseudocode? Tatsächlich ist das Verständnis des LLM für Pseudocode ziemlich stark. Der LLM wurde mit einer großen Menge an Qualitätscode geschult und kann die Bedeutung von Pseudocode leicht verstehen.
Wie schreibt man Pseudocode Prompt?
Pseudocode ist Programmierern sehr vertraut, und auch Nicht-Programmierer können einfachen Pseudocode schreiben, indem sie sich einige Grundregeln merken. Ein paar Beispiele:
- Variablen, die zum Speichern von Daten verwendet werden, z. B. um Eingaben oder Zwischenergebnisse mit bestimmten Symbolen darzustellen
- Typ, zur Definition des Datentyps, z. B. Strings, Zahlen, Arrays usw.
- Funktion, die die Ausführungslogik für eine bestimmte Teilaufgabe definiert
- Kontrollfluss, der dazu dient, den Ausführungsprozess des Programms zu steuern, wie Schleifen, bedingte Entscheidungen usw.
- if-else-Anweisung: Wenn Bedingung A erfüllt ist, wird Aufgabe A ausgeführt, andernfalls wird Aufgabe B ausgeführt.
- Eine for-Schleife, die für jedes Element im Array eine Aufgabe ausführt.
- while-Schleife, wenn die Bedingung A erfüllt ist, wird die Aufgabe B kontinuierlich ausgeführt.
Schreiben wir nun den Pseudocode Prompt, wobei wir die beiden vorherigen Reflexionsfragen als Beispiel verwenden.
Pseudocode zur Ausgabe eines bestimmten JSON-Formats
Das gewünschte JSON-Format kann mit Hilfe eines Pseudocodes ähnlich der TypeScript-Typdefinition eindeutig beschrieben werden:
Bitte teilen Sie die Sätze in kurze Abschnitte auf, nicht mehr als 1 Zeile (weniger als 80 Zeichen, ~10 englische Wörter) pro Abschnitt. Bitte halten Sie jedes Segment sinnvoll, z. B. trennen Sie von Interpunktionen, "und", "das", "wo", "was", "wann", "wer", "welches" oder "oder" usw., wenn möglich, aber Behalten Sie diese Satzzeichen oder Wörter zum Trennen bei. Fügen Sie keine Wörter oder Satzzeichen hinzu oder entfernen Sie keine. Die Eingabe ist ein Array von Zeichenketten. Die Ausgabe sollte ein gültiges json-Array von Objekten sein, jedes Objekt enthält einen Satz und seine Segmente. Array
Organisieren von Untertitel-Skripten mit Pseudocode
Die Aufgabe, untertitelte Texte zusammenzustellen, ist relativ komplex. Wenn man sich vorstellt, ein Programm zu schreiben, um diese Aufgabe zu erfüllen, kann es viele Schritte geben, wie z. B. das Extrahieren von Kapiteln, dann das Extrahieren von Sprechern und schließlich das Zusammenstellen von Dialogen nach Kapiteln und Sprechern. Mit Hilfe von Pseudocode können wir diese Aufgabe in mehrere Teilaufgaben zerlegen, für die es nicht einmal notwendig ist, speziellen Code zu schreiben, sondern nur die Ausführungslogik der Teilaufgaben klar zu beschreiben. Dann führen wir diese Teilaufgaben Schritt für Schritt aus und integrieren schließlich die Ergebnisausgabe.
Wir können einige Variablen zum Speichern verwenden, wie z. B. Thema, undLautsprecher, undKapitel, undParagraphen usw.
Bei der Ausgabe können wir auch For-Schleifen verwenden, um durch Kapitel und Absätze zu iterieren, und If-else-Anweisungen, um festzustellen, ob wir den Namen des Sprechers ausgeben müssen.
Ihre Aufgabe ist es, Videotranskripte neu zu organisieren, damit sie lesbar sind, und Sprecher für Dialoge mit mehreren Personen zu erkennen. Hier sind die Pseudocodes, wie man es macht Hier sind die Pseudo-Codes, wie man es macht
def extract_subject(transcript): # Sucht das Thema im Transkript und gibt es als String zurück.
# Findet das Thema im Transkript und gibt es als String zurück.
def extract_chapters(transcript): # Findet die Kapitel im Transkript und gibt sie als Liste von Strings zurück.
# Findet die Kapitel im Transkript und gibt sie als eine Liste von Strings zurück. def extract_chapters(transcript).
def extract_speakers(transcript): # Findet die Sprecher im Transkript und gibt sie als Liste von Strings zurück.
# Findet die Sprecher im Transkript und gibt sie als Liste von Strings zurück. def extract_speakers(transcript): # Findet die Sprecher im Transkript und gibt sie als Liste von Strings zurück.
def find_paragraphs_and_speakers_in_chapter(chapter): # Findet die Absätze und gibt sie als Liste von Strings zurück. def extract_speakers(transcript).
# Findet die Absätze und Sprecher in einem Kapitel und gibt sie als Liste von Tupeln zurück. def find_paragraphs_and_speakers_in_chapter(chapter).
# Jedes Tupel enthält den Sprecher und seine Absätze. # Findet die Absätze und Sprecher in einem Kapitel und gibt sie als Liste von Tupeln zurück.
def format_transcript(transcript): # Extrahiert das Thema, den Text und die Wörter.
# extrahiert das Thema, die Sprecher und die Kapitel und gibt sie aus
subject = extract_subject(Mitschrift)
print("Thema:", Thema)
Sprecher = extract_speakers(Transkript)
print("Sprecher:", Sprecher)
Kapitel = extract_chapters(Transkript)
print("Kapitel:", kapitel)
# formatiert das Transkript
formatiertes_transkript = f "# {Thema}\n\n"
for chapter in chapters.
formatted_transcript += f "## {Kapitel}\n\n" for chapter in chapters.
paragraphs_and_speakers = find_paragraphs_and_speakers_in_chapter(chapter)
for speaker, paragraphs in paragraphs_and_speakers.
# wenn es mehrere Sprecher gibt, den Namen des Sprechers vor jedem Absatz ausgeben
if speakers.size() > 1.
formatted_transcript += f"{Sprecher}:"
formatted_transcript += f"{Sprecher}:"
for paragraph in paragraphs: formatted_transcript += f"{Sprecher}:
formatted_transcript += f" {Absatz}\n\n"
formatted_transcript += "\n\n"
return formatted_transcript
print(format_transcript($user_input))
Mal sehen, wie es sich entwickelt:
Zusammenstellung von WWDC-Zugangsprotokollen
Mehrere Redner, Show Redner
1 Lautsprecher, kein Lautsprecher abgebildet
Sie können auch einfach das GPT verwenden, das ich mit dieser Eingabeaufforderung erstellt habe:Abschriftorganisation GPT
ChatGPT zeichnen mehrere Bilder auf einmal mit Pseudo-Code
Außerdem habe ich kürzlich von einem taiwanesischen Netizen, Sensei Yin Xiangzhi, eine sehr interessante Verwendung des Begriffs gelernt, nämlichChatGPT kann mit Pseudocode mehrere Bilder auf einmal zeichnen.
Wenn Sie nun Folgendes machen wollen ChatGPT Wenn Sie mehr als ein Bild auf einmal generieren möchten, können Sie Pseudocode verwenden, um die Aufgabe der Generierung mehrerer Bilder in mehrere Teilaufgaben aufzuteilen und dann mehrere Teilaufgaben auf einmal auszuführen und schließlich die Ergebnisausgabe zu integrieren.
Hier ist ein Pseudocode zum Zeichnen eines Diagramms. Bitte folgen Sie der Logik des Pseudocodes und zeichnen Sie das Diagramm mit DALL-E:
images_prompts = [
{
Stil: "Kawaii",
prompt: "Zeichne einen süßen Hund",
aspectRatio: "Breit"
},
{
style: "Realistisch", prompt: "Zeichne einen realistischen Hund", aspectRatio: "Breit" }, {
prompt: "Zeichne einen realistischen Hund", aspectRatio: "Quadratisch
aspectRatio: "Quadratisch"
}
]
images_prompts.forEach((image_prompt) => {
print("Bild erzeugen mit Stil: " + image_prompt.style + " und Prompt: " + image_prompt.prompt + " und Seitenverhältnis: " + image_prompt.aspectRatio)
image_generation(image_prompt.style, image_prompt.prompt, image_prompt.aspectRatio);
})
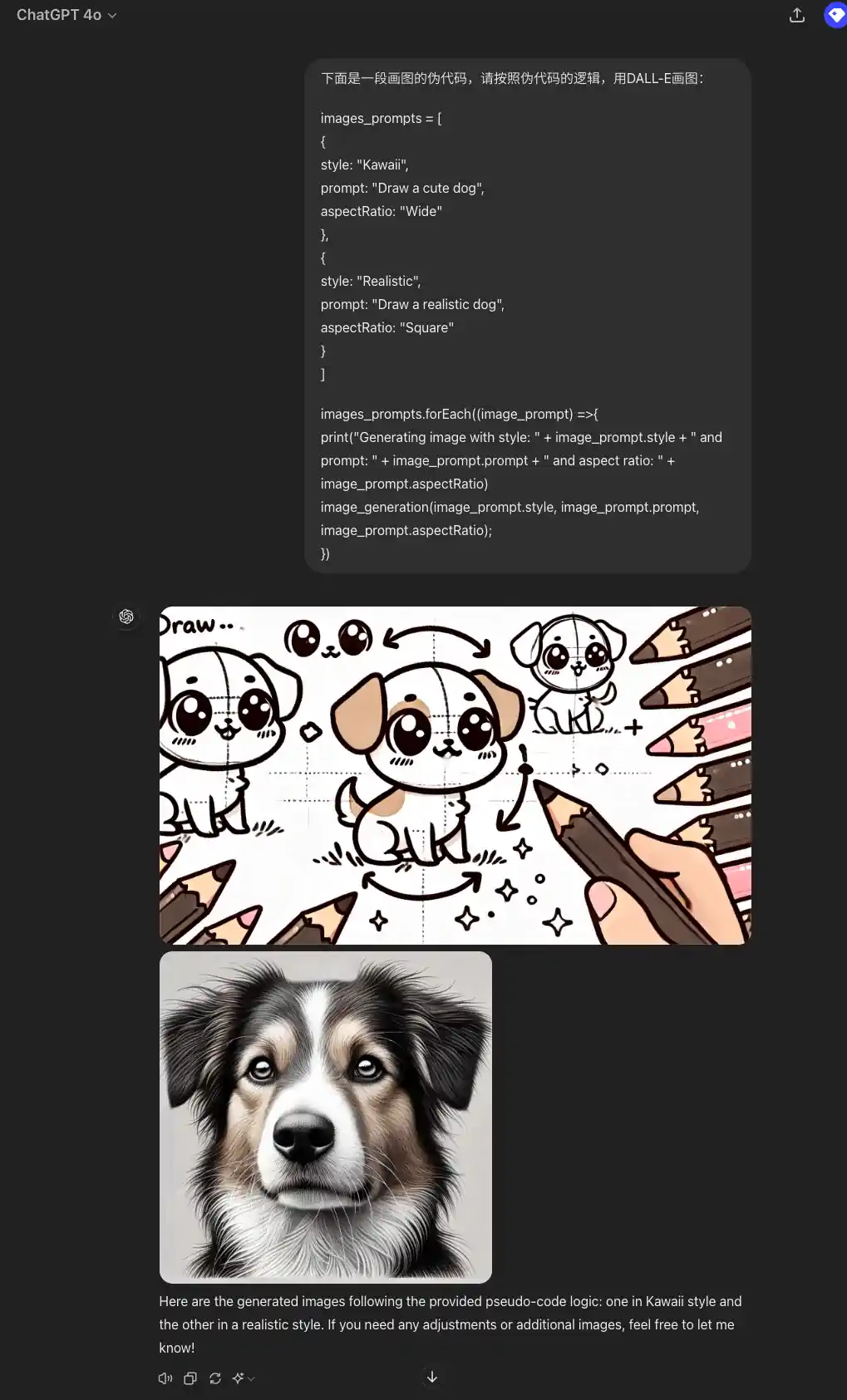
Zusammenfassungen
Anhand des obigen Beispiels können wir sehen, dass wir mit Hilfe von Pseudocode das Ausgabeergebnis des LLM genauer kontrollieren und seine Ausführungslogik definieren können, anstatt uns nur auf die Beschreibung in natürlicher Sprache zu beschränken. Wenn wir auf komplexe Aufgaben oder Aufgaben mit mehreren Zweigen stoßen, bei denen jeder Zweig mehrere Teilaufgaben ausführen muss und die Teilaufgaben miteinander verbunden sind, dann wird die Verwendung von Pseudocode zur Beschreibung der Eingabeaufforderung klarer und genauer sein.
Wenn wir einen Prompt schreiben, denken wir daran, dass ein Prompt im Wesentlichen eine in natürlicher Sprache beschriebene Steueranweisung an den LLM ist, die es dem LLM ermöglicht, zu verstehen, was wir wollen, und dann die Eingaben in die von uns erwarteten Ausgaben zu verwandeln. Was die Form der Beschreibung der Eingabeaufforderung betrifft, so kann sie in vielen Formen flexibel sein, wie z.B. few-shot, CoT, Pseudocode, etc.
Weitere Beispiele:
Generierung von "Pseudocode"-Meta-Prompts zur präzisen Steuerung der Ausgabeformatierung