Seit OpenAI das o1-Modell veröffentlicht hat.Skalierung der Testzeitberechnung(Scaling Reasoning) ist zu einem der heißesten Themen in KI-Kreisen geworden. Vereinfacht ausgedrückt ist es besser, mehr Rechenleistung in der Inferenzphase (d.h. wenn das große Sprachmodell eine Ausgabe generiert) zu verwenden, anstatt sie in der Pre- oder Post-Trainingsphase anzuhäufen. o1 Das Modell teilt ein großes Problem in eine Reihe kleinerer Probleme auf (d.h. Chain-of-Thought), so dass das Modell wie ein Mensch Schritt für Schritt denken kann, indem es verschiedene Möglichkeiten bewertet, eine detailliertere Planung vornimmt, über sich selbst nachdenkt, bevor es eine Antwort gibt, usw. Das Modell kann dann verwendet werden, um verschiedene Möglichkeiten zu bewerten, eine detailliertere Planung vorzunehmen und eine Antwort zu geben. Das Modell kann wie ein Mensch denken, verschiedene Möglichkeiten bewerten, eine detailliertere Planung vornehmen, über sich selbst nachdenken, bevor es eine Antwort gibt, usw. Auf diese Weise muss das Modell nicht neu trainiert werden, und die Leistung kann nur durch zusätzliche Berechnungen während der Argumentation verbessert werden.Anstatt das Modell auswendig lernen zu lassen, sollten Sie es dazu bringen, mehr zu denken.-- Diese Strategie ist besonders effektiv bei komplexen Inferenzaufgaben und führt zu einer deutlichen Verbesserung der Ergebnisse. Die jüngste Veröffentlichung des QwQ-Modells von Alibaba bestätigt diesen technologischen Trend: Verbesserung der Modellfähigkeiten durch Erweiterung der Berechnungen zur Inferenzzeit.
👩🏫 Skalierung bezieht sich in diesem Papier auf die Vergrößerung der Rechenressourcen (z. B. Arithmetik oder Zeit) während des Rechenprozesses. Sie bezieht sich nicht auf horizontale Skalierung (verteiltes Rechnen) oder beschleunigte Verarbeitung (reduzierte Rechenzeit).

Wenn Sie auch das o1-Modell verwendet haben, werden Sie sicherlich feststellen, dass das Denken in mehreren Schritten zeitaufwändiger ist, weil das Modell zur Lösung des Problems Gedankenketten aufbauen muss.
Bei Jina AI konzentrieren wir uns mehr auf Embeddings und Reranker als auf Large Language Models (LLMs). Deshalb haben wir uns natürlich etwas einfallen lassen:Lässt sich das Konzept der "Gedankenketten" auch auf das Embedding-Modell anwenden?
Auch wenn es auf den ersten Blick nicht intuitiv erscheinen mag, wird in diesem Beitrag eine neue Perspektive erforscht und gezeigt, wie die Skalierung der Testzeitberechnung auf die folgenden Bereiche angewendet werden kannjina-clipum ein besseres Verständnis zu ermöglichen für Knifflige Out Of Domain (OOD)-Bilder Die Klassifizierung wird durchgeführt, um sonst unlösbare Aufgaben zu lösen.
Wir haben mit der Pokémon-Erkennung experimentiert, die für Vektormodelle immer noch eine ziemliche Herausforderung darstellt. Ein Modell wie CLIP ist zwar stark im Bild-Text-Abgleich, neigt aber dazu, umzukippen, wenn es auf Daten außerhalb der Domäne (OOD) trifft, die das Modell noch nicht gesehen hat.
Wir haben jedoch festgestellt, dassDie Klassifizierungsgenauigkeit von Out-of-Domain-Daten kann verbessert werden, indem die Zeit für die Modellinferenz erhöht und eine Chain-of-Thinking-ähnliche Mehrziel-Klassifizierungsstrategie eingesetzt wird, die keine Modellabstimmung erfordert.
Fallstudie: Klassifizierung von Pokémon-Bildern
🔗 Google Colab: https://colab.research.google.com/drive/1zP6FZRm2mN1pf7PsID-EtGDc5gP_hm4Z#scrollTo=CJt5zwA9E2jB
Wir haben den TheFusion21/PokemonCards-Datensatz verwendet, der Tausende von Pokemon-Kartenbildern enthält.Dies ist eine Bildklassifizierungsaufgabedas ein beschnittenes Pokémon-Deck (ohne Textbeschreibung) eingibt und den richtigen Pokémon-Namen ausgibt. Dies ist jedoch für das CLIP-Embedding-Modell aus mehreren Gründen schwierig:
- Pokémon-Namen und Aussehen sind relativ neu in dem Modell, und es ist leicht, mit einer direkten Kategorisierung das Blatt zu wenden.
- Jedes Pokémon hat seine eigenen optischen MerkmaleDie CLIPs werden besser verstanden, z. B. Formen, Farben und Posen.
- Der Stil der Karten ist jedoch einheitlichAber die unterschiedlichen Hintergründe, Posen und Zeichenstile machen die Sache noch schwieriger.
- Diese Aufgabe erfordertMehrere visuelle Merkmale gleichzeitig berücksichtigenwie die komplexe Gedankenkette im LLM.

Wir haben alle Textinformationen (Titel, Fußzeile, Beschreibung) von den Karten entfernt, damit die Modelle nicht schummeln und ihre Antworten direkt aus dem Text ablesen können, denn die Bezeichnungen für diese Pokémon-Klassen sind ihre Namen, z. B. Absol, Aerodactyl.
Grundlegende Methodik: direkter Vergleich der Ähnlichkeit
Beginnen wir mit der einfachsten Basismethode, der Direkter Vergleich der Ähnlichkeit zwischen Pokémon-Bildern und -Namen.
Erstens ist es besser, alle Textinformationen von den Karten zu entfernen, damit das CLIP-Modell die Antwort nicht direkt aus dem Text erraten muss. Dann verwenden wir jina-klammer-v1 im Gesang antworten jina-klammer-v2 Das Modell kodiert das Bild und den Pokémon-Namen getrennt, um ihre jeweiligen Vektordarstellungen zu erhalten. Schließlich wird die Kosinusähnlichkeit zwischen den Bildvektoren und den Textvektoren berechnet, und der Name mit der höchsten Ähnlichkeit wird als das Pokémon betrachtet, um das es sich auf dem Bild handelt.
Dieser Ansatz ist gleichbedeutend mit einer Eins-zu-Eins-Übereinstimmung zwischen dem Bild und dem Namen, ohne dass andere Kontextinformationen oder Attribute berücksichtigt werden. Der folgende Pseudocode beschreibt den Vorgang kurz.
# Vorverarbeitung cropped_images = [crop_artwork(img) for img in pokemon_cards] # Text entfernen, nur Bilder behalten pokemon_names = ["Absol", "Aerodactyl", ...] # Pokemon-Namen # Einbettungen mit jina-clip-v1 ermitteln image_embeddings = model.encode_image(cropped_images) text_einbettungen = model.encode_text(pokemon_names) # Berechnen der Kosinusähnlichkeit für die Klassifizierung similarities = cosine_similarity(bild_einbettungen, text_einbettungen) predicted_names = [pokemon_names[argmax(sim)] for sim in similarities] # Der Name mit der höchsten Ähnlichkeit wird ausgewählt # Bewerten Sie die Genauigkeit Genauigkeit = mean(predicted_names == ground_truth_names)
Fortgeschrittene: Anwendung von Gedankenketten auf die Bildklassifizierung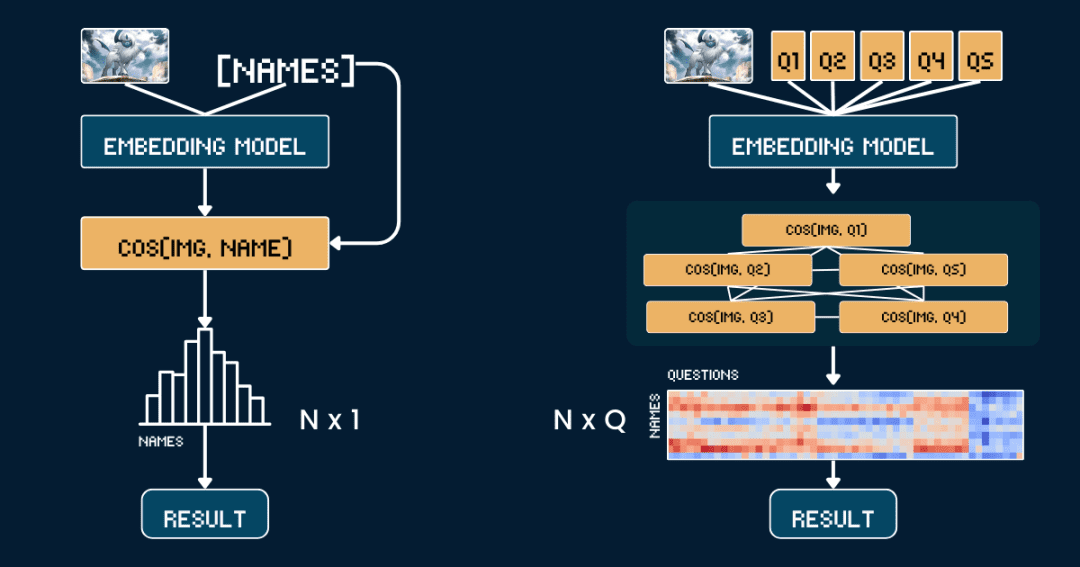
Statt Bilder und Namen direkt zuzuordnen, haben wir diesmal die Pokémon-Erkennung in mehrere Teile aufgeteilt, genau wie beim Spiel "Pokémon Connect".
Wir haben fünf Gruppen von Schlüsselattributen definiert: Primärfarbe (z. B. "weiß", "blau"), Primärform (z. B. "ein Wolf", "ein geflügeltes Reptil"), Schlüsselmerkmale (z. B. "ein weißes Horn", "große Flügel"), Körpergröße (z. B. "vierbeinige Wolfsform ", "geflügelt und schlank"), und Hintergrundszenen (z. B. "Weltraum", "grüner Wald").
Für jeden Satz von Attributen haben wir ein spezielles Stichwort entworfen, z. B. "Der Körper dieses Pokémon ist hauptsächlich {} farbig", und dann die möglichen Optionen eingetragen.Anschließend berechnen wir mit Hilfe des Modells die Ähnlichkeitswerte für das Bild und jede Option und wandeln die Werte mithilfe der Softmax-Funktion in Wahrscheinlichkeiten um, die ein besseres Maß für die Zuverlässigkeit des Modells darstellen.
Die vollständige Gedankenkette (CoT) besteht aus zwei Teilen:Klassifizierung_Gruppen im Gesang antworten pokemon_regelsErsteres definiert den Fragerahmen: Jedes Attribut (z. B. Farbe, Form) entspricht einer Fragevorlage und einer Reihe von möglichen Antwortoptionen. In der zweiten wird festgehalten, welche Optionen für jedes Pokémon zutreffen sollten.
Die Farbe von Absol sollte zum Beispiel "weiß" und seine Form "Wolf" sein. Wir werden später darüber sprechen, wie man eine vollständige CoT-Struktur aufbaut, und das folgende pokemon_system ist ein konkretes Beispiel für eine CoT:
pokemon_system = {
"klassifizierung_cot": {
"dominante_Farbe": {
"prompt": "Der Körper dieses Pokémon hat hauptsächlich eine Farbe von {}.",
"options": [
"weiß", # Absol, Absol G
"grau", # Aggron
"braun", # Aerodactyl, Weedle, Beedrill δ
"blau", # Azumarill
"grün", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"gelb", # Alakazam, Ampharos
"rot", # Blaine's Moltres
"orange", # Arkanin
"hellblau" # Dratini
]
}
"primary_form": {
"prompt": "Es sieht aus wie {}." ,
"options": [
"ein Wolf", # Absol, Absol G
"ein gepanzerter Dinosaurier", # Aggron
"ein geflügeltes Reptil", # Aerodactyl
"eine kaninchenartige Kreatur", # Azumarill
"eine krötenähnliche Kreatur", # Bulbasaur, Venusaur, Celebi&Venu
"eine Raupenlarve", # Weedle, Caterpie
"ein wespenartiges Insekt", # Beedrill δ
"ein fuchsähnlicher Humanoider", # Alakazam
"ein schafähnlicher Zweibeiner", # Ampharos
"ein hundeähnliches Tier", # Arcanine
"ein flammender Vogel", # Blaine's Moltres
"ein schlangenartiger Drache", # Dratini
]
}
"key_trait": {
"prompt": "Sein bemerkenswertestes Merkmal ist {}." ,
"options": [
"ein einzelnes weißes Horn", # Absol, Absol G
"Metallpanzerplatten", # Aggron
"große Flügel", # Aerodactyl, Beedrill δ
"Kaninchenohren", # Azumarill
"eine grüne Pflanzenknolle", # Bulbasaur, Venusaur, Celebi&Venu
"ein kleiner roter Stachel", # Weedle
"große grüne Augen", # Caterpie
"ein Schnurrbart und Löffel", # Alakazam
"eine leuchtende Schwanzkugel", # Ampharos
"eine feurige Mähne", # Arcanine
"flammende Flügel", # Blaine's Moltres
"ein kleines weißes Horn auf dem Kopf", # Dratini
]
}
"body_shape": {
"prompt": "Die Körperform kann als {} beschrieben werden." ,
"options": [
"wolfsähnlich auf vier Beinen", # Absol, Absol G
"klobig und gepanzert", # Aggron
"geflügelt und schlank", # Aerodactyl, Beedrill δ
"rund und plump", # Azumarill
"stämmig und vierbeinig", # Bulbasaur, Venusaur, Celebi&Venu
"lang und wurmartig", # Weedle, Caterpie
"aufrecht und menschenähnlich", # Alakazam, Ampharos
"pelzig und hundeartig", # Arcanine
"vogelartig mit Flammen", # Blaine's Moltres
"schlangenartig", # Dratini
]
}
"background_scene": {
"prompt": "Der Hintergrund sieht aus wie {}." ,
"options": [
"Weltraum", # Absol G, Beedrill δ
"grüner Wald", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"ein felsiges Schlachtfeld", # Absol, Aggron, Aerodactyl
"ein violetter psychischer Raum", # Alakazam
"ein sonniges Feld", # Ampharos
"Vulkanischer Boden", # Arkanin
"ein roter Himmel mit Glut", # Blaine's Moltres
"ein ruhiger blauer See", # Dratini
]
}
}
"pokemon_rules": {
"Absol": {
"dominante_Farbe": 0,
"primäre_form": 0,
"schlüssel_eigenschaft": 0,
"körper_form": 0,
"hintergrund_szene": 2
}, "Absol G".
"Absol G": {
"dominant_colour": 0, "primary_form": 0, "background_scene": 2 }, "Absol G": {
"primäre_form": 0,
"primäre_form": 0, "key_trait": 0,
"körper_form": 0,
"hintergrund_szene": 0
}, ...
// ...
}
}
Kurz gesagt, anstatt nur einmal die Ähnlichkeiten zu vergleichen, führen wir nun mehrere Vergleiche durch, wobei wir die Wahrscheinlichkeiten der einzelnen Attribute kombinieren, um ein vernünftigeres Urteil fällen zu können.
# Klassifizierungsprozess
def classify_pokemon(image).
# Erzeugen aller Prompts
all_prompts = []
for group in classification_cot.
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Abrufen der Vektoren und ihrer Ähnlichkeit
image_embedding = model.encode_image(image)
text_einbettungen = model.encode_text(alle_prompts)
similarities = cosine_similarity(bild_einbettung, text_einbettungen)
# Ähnlichkeiten in Wahrscheinlichkeiten für jede Attributgruppe umwandeln
Wahrscheinlichkeiten = {}
for group_name, group_sims in group_similarities: probabilities[group_name] = {}
probabilities[group_name] = softmax(group_sims)
# Berechne die Punktzahl für jedes Pokémon auf der Grundlage der übereinstimmenden Attribute
scores = {}
for pokemon, rules in pokemon_rules.items():
scores = 0
for group, target_idx in rules.items(): score += probabilities[group][target_idx]: {}
score += wahrscheinlichkeiten[gruppe][ziel_idx]
scores[pokemon] = score
return max(scores, key=scores.get) # Gibt das Pokemon mit der höchsten Punktzahl zurück
Komplexitätsanalyse der beiden Methoden
Analysieren wir nun die Komplexität: Nehmen wir an, wir wollen unter N Pokémon-Namen den Namen finden, der am besten zu dem gegebenen Bild passt:
Die Basismethode erfordert die Berechnung von N Textvektoren (einen für jeden Namen) und 1 Bildvektor, gefolgt von N Ähnlichkeitsberechnungen (Bildvektoren werden mit jedem Textvektor verglichen).Daher hängt die Komplexität der Benchmark-Methode hauptsächlich von der Anzahl der Berechnungen N der Textvektoren ab.
Stattdessen muss unsere CoT-Methode Q Textvektoren berechnen, wobei Q die Gesamtzahl aller Frage-Options-Kombinationen ist, und 1 Bildvektor. Danach müssen Q Ähnlichkeitsberechnungen (Vergleich der Bildvektoren mit den Textvektoren für jede Frage-Antwort-Kombination) durchgeführt werden.Daher hängt die Komplexität der Methode hauptsächlich von Q ab.
In diesem Beispiel sind N = 13 und Q = 52 (5 Gruppen von Attributen mit durchschnittlich etwa 10 Optionen pro Gruppe). Beide Methoden müssen Bildvektoren berechnen und Klassifizierungsschritte durchführen, und wir runden diese gemeinsamen Operationen bei dem Vergleich ab.
Im Extremfall, wenn Q = N ist, degeneriert unsere Methode effektiv zu einer Benchmark-Methode. Der Schlüssel zur effektiven Erweiterung der Inferenzzeitberechnung ist also:
-
Entwerfen Sie das Problem, um den Wert von Q zu erhöhen. -
Vergewissern Sie sich, dass jede Frage nützliche Hinweise enthält, die uns helfen, sie einzugrenzen. -
Um den Informationsgewinn zu maximieren, ist es am besten, wenn sich die Informationen zwischen den Fragen nicht wiederholen.
Ergebnisse
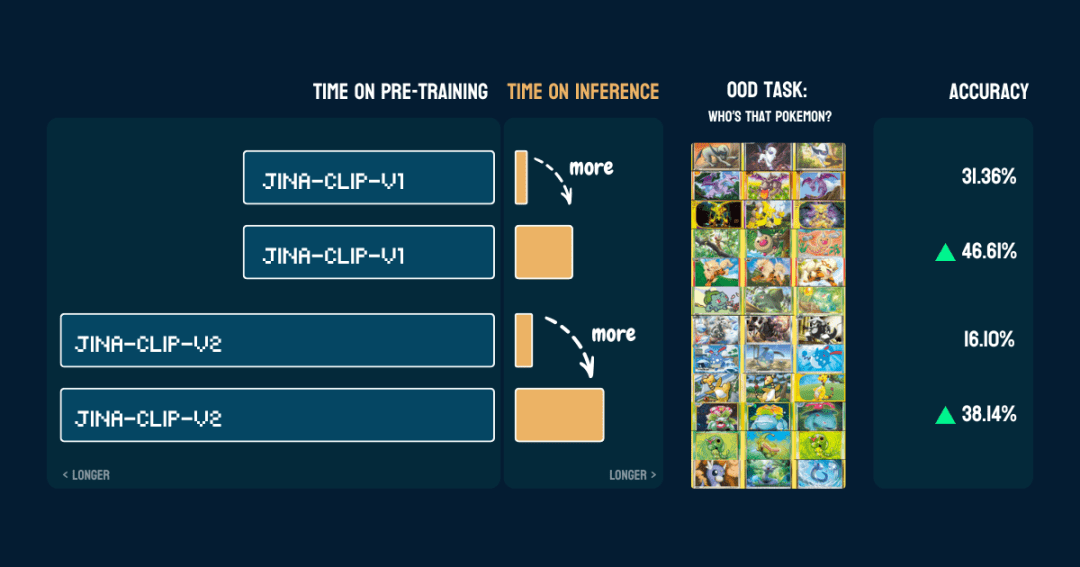
Wir haben es an 117 Testbildern mit 13 verschiedenen Pokémon getestet. Die Ergebnisse der Genauigkeit sind wie folgt:

Es zeigt auch, dass einmalpokemon_systemEs ist richtig gebaut.Derselbe CoT kann direkt auf ein anderes Modell angewendet werden, ohne den Code zu ändern und ohne Feinabstimmung oder zusätzliches Training.
Interessant.jina-klammer-v1Die Basisgenauigkeit des Modells bei der Pokémon-Klassifizierung ist dann höher (31,36%), da es auf dem LAION-400M-Datensatz mit Pokémon-Daten trainiert wurde. Während jina-klammer-v2Das Modell wurde mit dem DFN-2B trainiert, einem qualitativ hochwertigeren Datensatz, aus dem aber auch mehr Daten herausgefiltert und wahrscheinlich auch Pokémon-bezogene Inhalte entfernt wurden, so dass die Basisgenauigkeit geringer ist (16,10%).
Moment, wie funktioniert diese Methode?
👩🏫 Lassen Sie uns noch einmal zusammenfassen, was wir getan haben.
Wir begannen mit fixen, vortrainierten Vektormodellen, die mit OOD-Problemen (Out-of-Distribution) bei Null-Stichproben nicht zurechtkamen. Aber als wir einen Klassifikationsbaum erstellten, konnten sie es plötzlich. Was ist das Geheimnis dahinter? Ist es so etwas wie die schwache Integration von Lernern beim traditionellen maschinellen Lernen? Es ist erwähnenswert, dass unser Vektormodell nicht aufgrund des integrierten Lernens an sich, sondern aufgrund des im Klassifikationsbaum enthaltenen externen Domänenwissens von "schlecht" auf "gut" verbessert werden kann. Man kann Tausende von Fragen wiederholt mit null Stichproben klassifizieren, aber wenn die Antworten nicht zum Endergebnis beitragen, ist das sinnlos. Es ist wie ein Spiel mit zwanzig Fragen, bei dem man die Lösung mit jeder Frage immer weiter eingrenzen muss. Es ist also dieses externe Wissen oder dieser Denkprozess, der der Schlüssel ist. - Wie in unserem Beispiel liegt der Schlüssel darin, wie das Pokemon-System aufgebaut ist.Dieses Fachwissen kann von Menschen oder von großen Sprachmodellen stammen.
pokemon_systemQualität der.Es gibt viele Möglichkeiten, dieses CoT-System aufzubauen, von manuell bis vollautomatisch, jede mit ihren eigenen Vor- und Nachteilen.1. manuelle Konstruktion
2) LLM-unterstützte Konstruktion
Ich brauche ein Pokémon-Kategorisierungssystem. Für die folgenden Pokémon: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...]. erstellen Sie ein Klassifizierungssystem, das Folgendes enthält:
1. eine Klassifizierungsgruppe, die auf den folgenden visuellen Attributen basiert:
- Die Grundfarbe des Pokémon
- Die Form des Pokémon
- Das markanteste Merkmal des Pokémon
- Die Gesamtgröße des Pokémon
- Die Hintergrundumgebung, in der das Pokémon normalerweise auftritt
2. für jede Klassifizierungsgruppe:
- Erstellen Sie eine natürlichsprachliche Hinweisvorlage mit "{}" für Optionen
- Listen Sie alle möglichen Optionen auf
- Stellen Sie sicher, dass die Optionen sich gegenseitig ausschließen und umfassend sind.
3. Erstellen Sie Regeln, die jedes Pokémon einer Option in jeder Attributgruppe zuordnen, und verwenden Sie Indizes, um auf die Optionen zu verweisen
Bitte geben Sie die Ergebnisse im Python-Wörterbuchformat mit zwei Hauptteilen aus:
- "classification_groups": enthält Hinweise und Optionen für jedes Attribut
- "pokemon_rules": ordnet jedes Pokémon dem entsprechenden Eigenschaftsindex zu
Beispiel-Format:
{
"klassifizierung_gruppen": {
"dominante_Farbe": {
"prompt": "Der Körper dieses Pokemon hat hauptsächlich {} Farben.", "options": ["weiß", "grau", .
"options": ["weiß", "grau", ...]
}, ...
...
}, "pokemon_rules".
"pokemon_rules": {
"Absol": {
"dominante_Farbe": 0, #-Index von "weiß"
...
}, ...
...
}
}
LLM erstellt schnell einen ersten Entwurf, erfordert aber auch manuelle Überprüfung und Korrekturen.
Ein zuverlässigerer Ansatz wäre Kombinierte LLM-Generierung und manuelle Validierung. Der LLM kann zunächst eine erste Version erstellen, dann die Attributgruppierungen, Optionen und Regeln manuell überprüfen und ändern und die Änderungen dann an den LLM zurückgeben, damit dieser sie weiter verfeinert, bis er zufrieden ist. Dieser Ansatz stellt ein Gleichgewicht zwischen Effizienz und Genauigkeit her.
3. automatisierte Builds mit DSPy
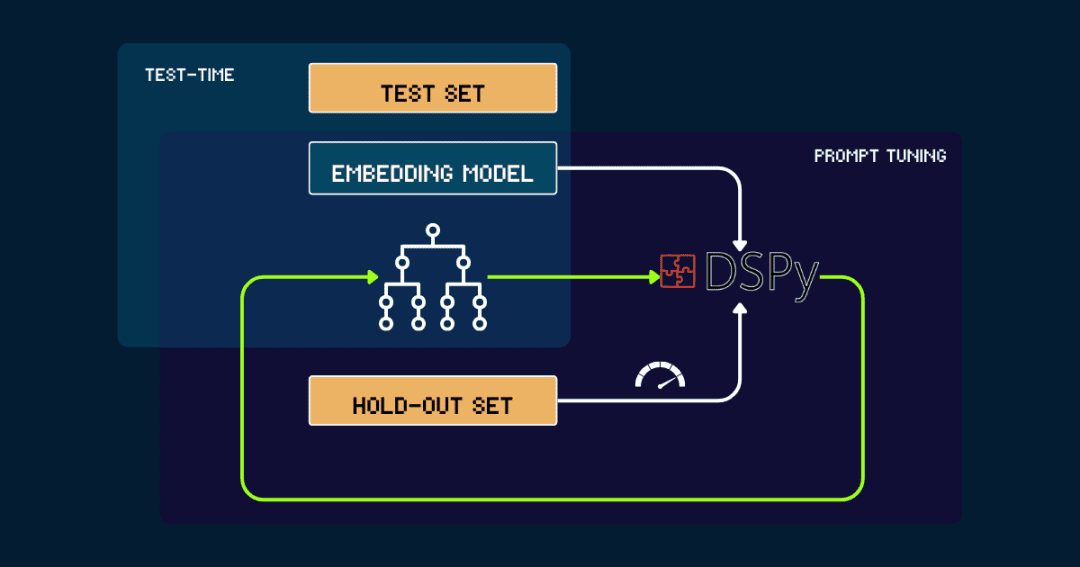
Für vollautomatische Builds pokemon_systemdie mit DSPy iterativ optimiert werden können.
Beginnen wir mit einer einfachen pokemon_system Start, entweder manuell erstellt oder von LLM generiert. Es wird dann mit den Daten aus der Auslassungsmenge ausgewertet, wobei die Genauigkeit als Feedback an DSPy gemeldet wird. pokemon_systemDieser Zyklus wird so lange wiederholt, bis die Leistung konvergiert und keine signifikante Verbesserung mehr zu verzeichnen ist.
Das Vektormodell ist während des gesamten Prozesses festgelegt. Mit DSPy ist es möglich, den besten Pokemon_system (CoT) Entwurf automatisch zu finden und ihn nur einmal pro Aufgabe abzustimmen.
Warum Skalierung der Testzeitberechnung bei Vektormodellen?
Es ist zu teuer, weil die Kosten für die ständige Vergrößerung der vortrainierten Modelle zu hoch sind.
Jina Embeddings Kollektion, vonjina-einbettungen-v1, undv2, undv3 bis (eine Zeit) jina-klammer-v1, undv2Und jina-ColBERT-v1, undv2Jede Aktualisierung erfordert größere Modelle, mehr vortrainierte Daten und steigende Kosten.
Nehmen Siejina-einbettungen-v1Bei einer Veröffentlichung im Juni 2023 mit 110 Millionen Parametern wird die Schulung 5.000 bis 10.000 Dollar kosten. Bis zu dem Zeitpunkt jina-einbettungen-v3Die Leistung hat sich zwar stark verbessert, aber immer noch hauptsächlich dadurch, dass Geld in die Ressourcen gesteckt wird. Die Ausbildungskosten für Spitzenmodelle sind von Tausenden von Dollar auf Zehntausende von Dollar gestiegen, und große Unternehmen müssen sogar Hunderte von Millionen Dollar ausgeben. Je mehr in die Vorschulung investiert wird, desto besser sind zwar die Modellergebnisse, aber die Kosten sind zu hoch, das Kosten-Nutzen-Verhältnis wird immer geringer, und bei der Entwicklung des endgültigen Modells muss die Nachhaltigkeit berücksichtigt werden.
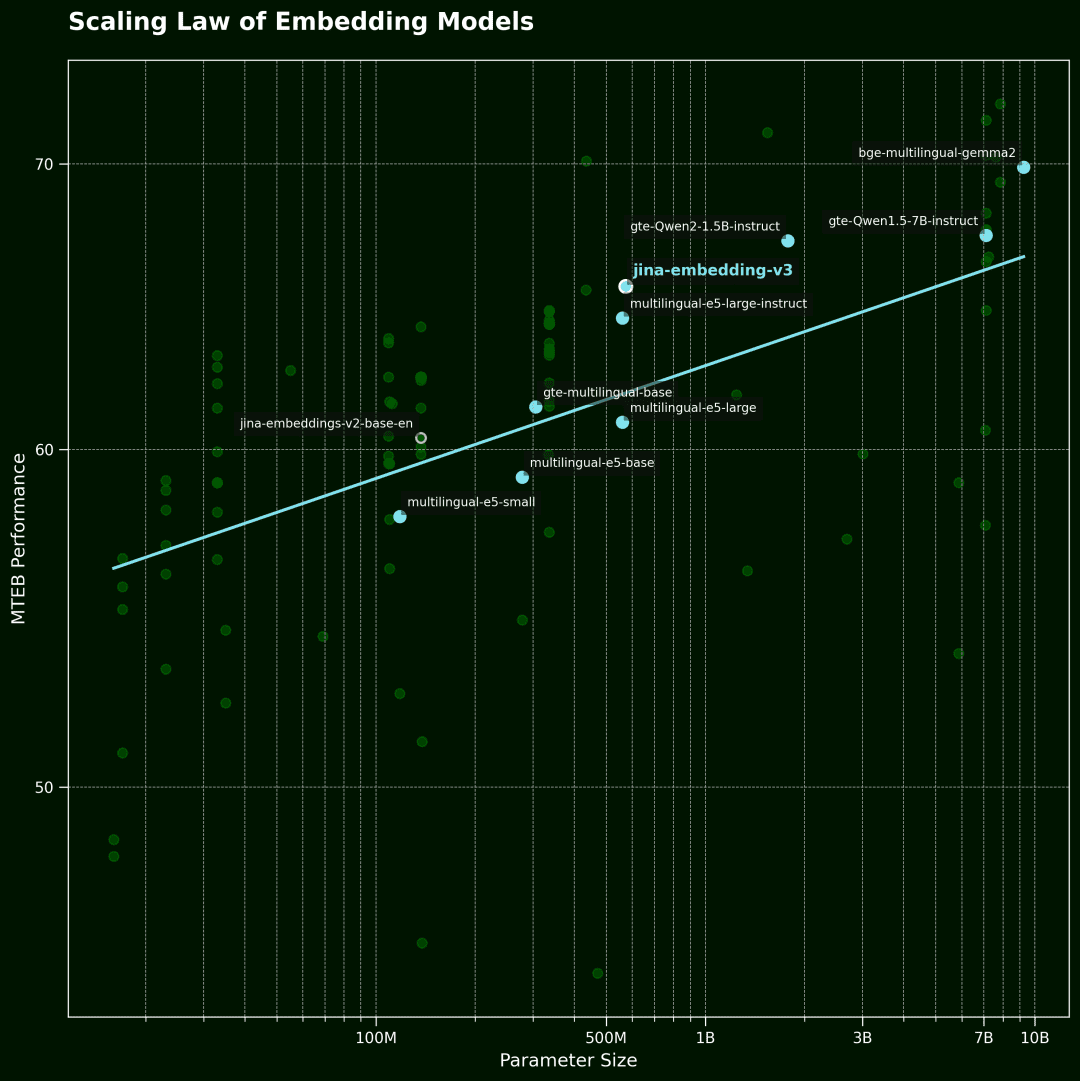
Skalierungsgesetz für Vektormodelle
Diese Abbildung zeigt dann das Vektormodell Scaling Law.Die horizontale Achse ist die Anzahl der Modellparameter und die vertikale Achse ist die durchschnittliche Leistung des MTEB. Jeder Punkt steht für ein Vektormodell. Die Trendlinie stellt den Durchschnitt aller Modelle dar, und die blauen Punkte sind mehrsprachige Modelle.
Die Daten wurden aus den 100 besten Vektormodellen des MTEB-Rankings ausgewählt. Um die Qualität der Daten zu gewährleisten, haben wir Modelle herausgefiltert, die keine Angaben zur Modellgröße gemacht haben, sowie einige ungültige Einreichungen.
Andererseits sind die Vektormodelle heute sehr leistungsfähig: mehrsprachig, multitaskingfähig, multimodal, mit ausgezeichneten Fähigkeiten zum Lernen von Nullproben und zum Befolgen von Anweisungen.Diese Vielseitigkeit eröffnet eine Vielzahl von phantasievollen Möglichkeiten für algorithmische Verbesserungen und Erweiterungen der Berechnung zum Zeitpunkt der Inferenz.
Die Schlüsselfrage ist:Wie viel sind die Nutzer bereit, für eine Suchanfrage zu zahlen, die sie wirklich interessiert?? Wenn die Inferenz eines festen, vorab trainierten Modells einfach etwas länger dauert, kann dies die Qualität der Ergebnisse drastisch verbessern.
Unserer Meinung nach.Die erweiterte Inferenzzeitberechnung birgt großes ungenutztes Potenzial im Bereich der Vektormodellierungwas wahrscheinlich ein wichtiger Durchbruch für die zukünftige Forschung sein wird.Anstatt ein größeres Modell anzustreben, ist es besser, mehr Aufwand in die Inferenzphase zu stecken und intelligentere Berechnungsmethoden zu erforschen, um die Leistung zu verbessern. -- Dies kann ein wirtschaftlicherer und effektiverer Weg sein.
ein Urteil fällen
existieren jina-klammer-v1/v2 Bei der experimentellen Durchführung wurden folgende Schlüsselphänomene beobachtet:
-
wir Auf Daten, die vom Modell nicht gesehen werden und außerhalb des Bereichs liegen (OOD)(math.) GattungEs wurde eine bessere Erkennungsgenauigkeit erzielt, ohne dass eine Feinabstimmung oder ein zusätzliches Training des Modells erforderlich war. -
Die Bedienung des Systems erfolgt über das Iterative Verfeinerung der Ähnlichkeitssuche und der KlassifizierungskriterienDadurch wird eine feinere Differenzierung möglich. -
durch Einführung Dynamische Anpassung des Hinweises und iterative Argumentation(analog zu einer "Gedankenkette"), wandeln wir den Denkprozess des Vektormodells von einer einzelnen Abfrage in eine komplexere Gedankenkette um.
Dies ist nur der Anfang, denn das Potenzial der Skalierung von Test-Time Compute geht weit darüber hinaus!gibt es noch viel Raum, der erforscht werden muss. So können wir beispielsweise effizientere Algorithmen entwickeln, um den Antwortraum einzugrenzen, indem wir iterativ die effizienteste Strategie auswählen, ähnlich wie bei der Strategie für optimale Lösungen im Spiel "Zwanzig Fragen". Durch die Ausweitung der Berechnung mit Hilfe von Schlussfolgerungen können wir die Vektormodelle über die bestehenden Engpässe hinaus vorantreiben, komplexe und feinkörnige Aufgaben lösen, die früher unerreichbar schienen, und diese Modelle in breitere Anwendungen einführen.

![Agenten-KI: Erkundung der Grenzwelt der multimodalen Interaktion [Fei-Fei Li - Classic Must Read] - Chief AI Sharing Circle](https://www.aisharenet.com/wp-content/uploads/2025/01/6dbf9ac2da09ee1-220x150.png)