Kürzlich, GenmoAI Open-Source-Video-Generierung Modell mochi 1 Vorschau (10B), mit High-Fidelity-Action und leistungsstarke Cue nach Fähigkeit, unterstützt derzeit 480p Auflösung Video-Generierung. Heute ging SiliconCloud, Silicon Flow, mit der Version der Inferenzbeschleunigung von mochi-1-preview (Preis ¥ 2,8/Video) online. Damit entfällt die Implementierungsschwelle für Entwickler, die bei der Entwicklung von Anwendungen lediglich die API aufrufen müssen, was eine effizientere Benutzererfahrung ermöglicht. Die Plattform unterstützt Entwickler auch dabei, Dutzende von großen Modellen frei zu vergleichen und zu testen und die besten Verfahren für ihre generativen KI-Anwendungen auszuwählen. 
Online-Erfahrung
https://cloud.siliconflow.cn/playground/text-to-video/17885302647
API-Dokumentation
https://docs.siliconflow.cn/capabilities/video

Stichwort: Eine Tomate, die mit einem Gesicht spricht

Stichwort: Eine Frau mit heller Haut, die eine blaue Jacke und einen schwarzen Hut mit Schleier trägt, blickt nach unten und nach rechts, dann wieder nach oben, während sie spricht; sie hat braunes Haar, das zu einer Hochsteckfrisur frisiert ist Eine Frau mit heller Hautfarbe, die eine blaue Jacke und einen schwarzen Hut mit Schleier trägt, blickt nach unten und nach rechts, dann wieder nach oben, während sie spricht; sie hat braunes Haar, das zu einer Hochsteckfrisur frisiert ist, hellbraune Augenbrauen und trägt ein weißes Hemd mit Kragen unter ihrer Jacke; die Kamera bleibt auf ihrem Gesicht stehen, während sie spricht; der Hintergrund ist unscharf, zeigt aber Bäume und Menschen in zeitgenössischer Kleidung; die Szene ist in Realaufnahmen festgehalten.

Stichwort: Ein klarer, türkisfarbener Fluss fließt durch einen felsigen Canyon, stürzt über einen kleinen Wasserfall und bildet am Grund ein Wasserbecken. Der Fluss ist der Mittelpunkt der Szene, in dessen klarem Wasser sich die umliegenden Bäume und Felsen spiegeln. Die Canyonwände sind steil und felsig, mit etwas Vegetation darauf. Bei den Bäumen handelt es sich hauptsächlich um Kiefern, deren grüne Nadeln einen Kontrast zu den braunen und grauen Felsen bilden. Die Szene wirkt insgesamt friedlich und ruhig. Der allgemeine Ton der Szene ist friedlich und ruhig.
Verschaffen Sie sich einen Eindruck davon, wie mochi-1-preview auf SiliconCloud nach der Inferenzbeschleunigung aussieht.
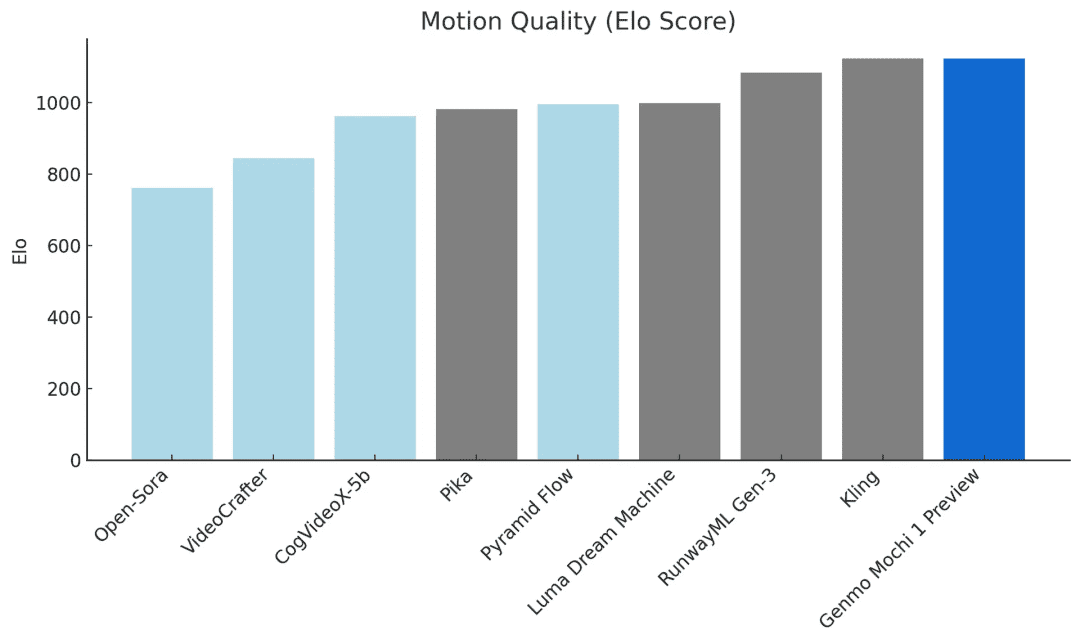
Modellmerkmale und Leistung
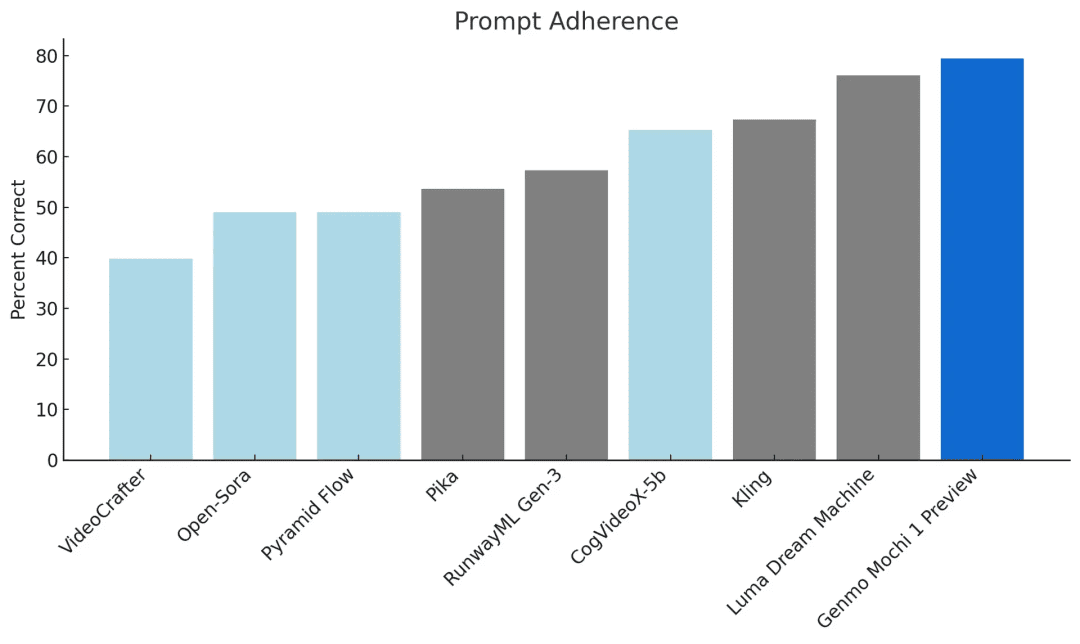
Basierend auf der Asymmetric Diffusion Transformer (AsymmDiT) Architektur ist mochi 1 einfach und modifizierbar. Im Vergleich zu führenden Closed-Source-Modellen ist mochi 1 äußerst wettbewerbsfähig. Cue-Following und Bewegungsqualität sind zwei der kritischsten Fähigkeiten bei Modellen zur Videogenerierung.
Zu beachtende TippsExtrem hohe Übereinstimmung mit Textaufforderungen stellt sicher, dass das generierte Video die gegebenen Anweisungen genau wiedergibt. Dies gibt dem Benutzer detaillierte Kontrolle über Zeichen, Einstellungen und Aktionen.
Qualität der Bewegungmochi 1 erzeugt bis zu 5,4 Sekunden Video mit 30 Bildern pro Sekunde, mit einem hohen Maß an zeitlicher Kohärenz und realistischen Bewegungsmustern. mochi simuliert physikalische Phänomene wie Flüssigkeitsdynamik, Haarsimulation und andere physikalische Phänomene und zeigt konsistente, flüssige menschliche Bewegungen.
Token-Fabrik SiliconCloud
Qwen 2.5 (7B) und 20+ andere Modelle kostenlos!
Als One-Stop-Big-Model-Cloud-Service-Plattform, ist SiliconCloud verpflichtet, Entwickler mit extrem schnelle Reaktion, erschwinglich, umfassend und seidig glatt Modell-APIs bieten. Instruct, HunyuanVideo, Marco-o1, fish-speech-1.5, QwQ-32B-Preview, Qwen2.5-Coder-32B-Instruct, Qwen2-VL, InternVL2, Qwen2.5-7B/14B/32B/ 72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat und Dutzende von quelloffenen großen Sprachmodellen, Bild-/Videogenerierungsmodellen, Sprachmodellen, Code-/Mathematikmodellen und Vektor- und Umordnungsmodellen. 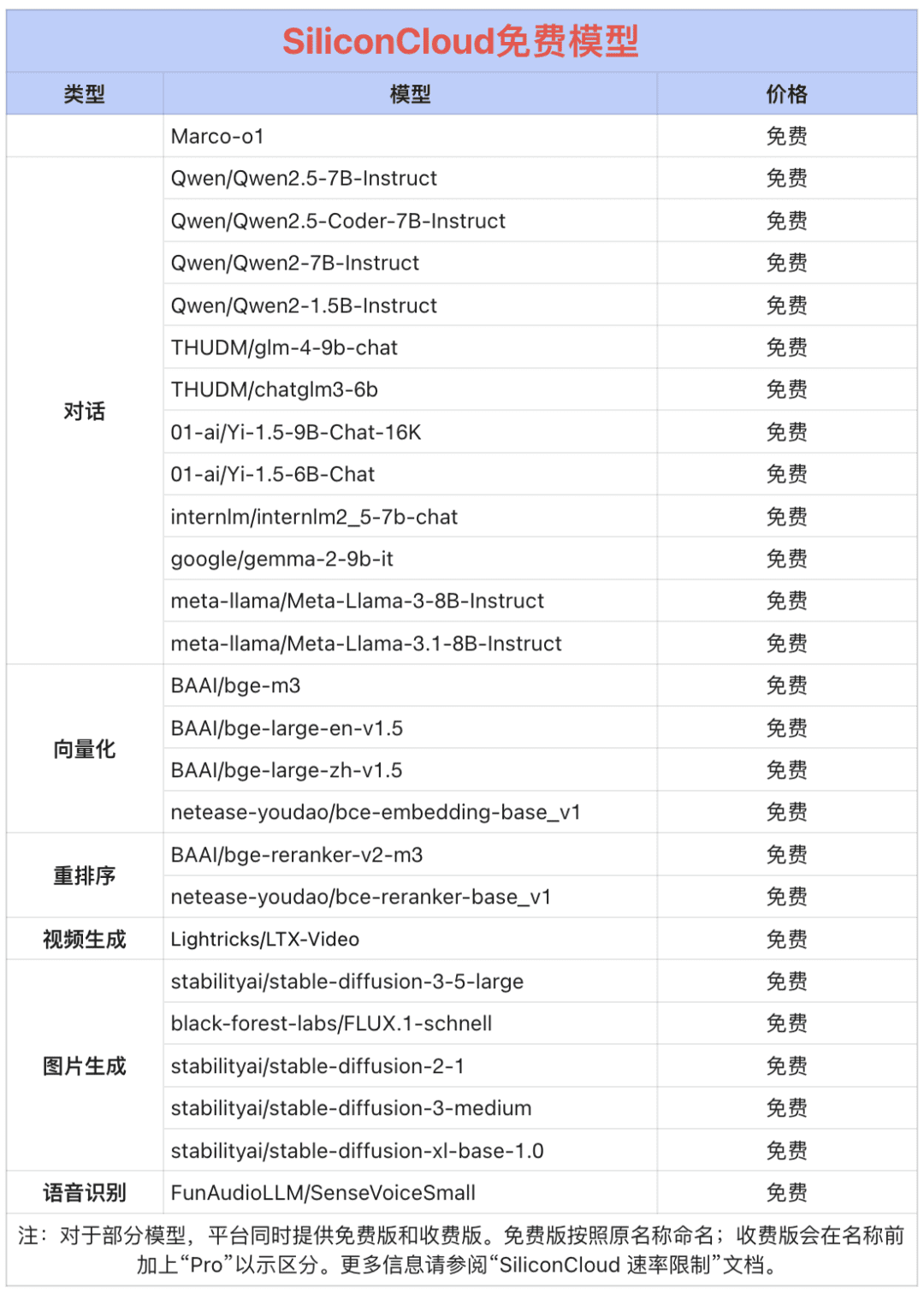
Qwen2.5 (7B), Llama3.1 (8B) und andere große Modell-APIs können kostenlos genutzt werden, so dass sich Entwickler und Produktmanager keine Gedanken über die rechnerischen Kosten der Forschungs- und Entwicklungsphase und die groß angelegte Förderung machen müssen, um "Token Freedom" zu erreichen.